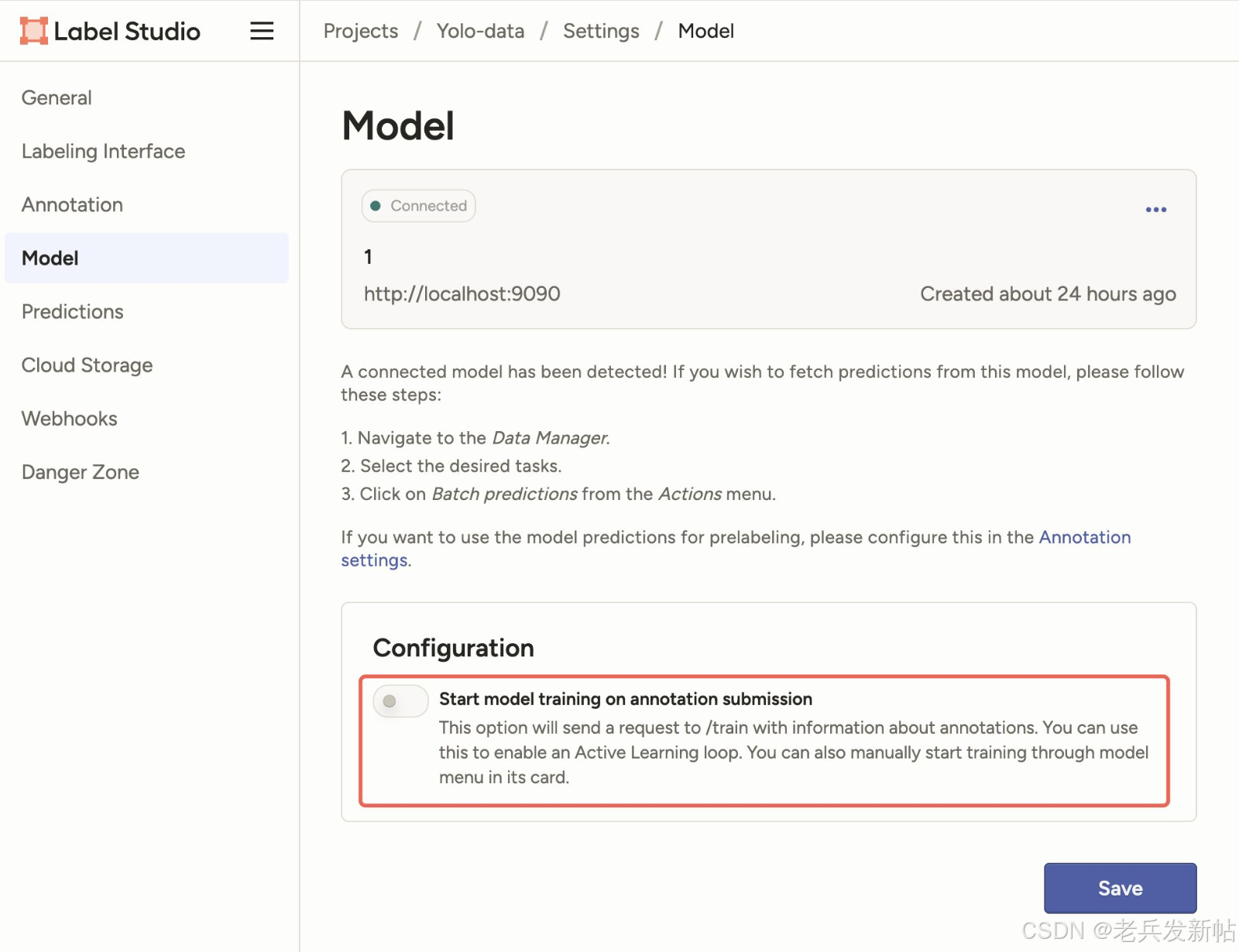
红框内的"Start model training on annotation submission"是一个核心功能开关,用于开启"主动学习"循环。
它的含义和工作原理如下:
🔧 功能解释
这是一个触发器。当您勾选此选项并保存后,意味着您告诉Label Studio:
"今后,每当标注员提交一个标注结果,请自动向我的机器学习后端发送一个信号,告诉它:'有新的训练数据了,你可以用这个新数据来重新训练或更新模型了。'"
🔄 它是如何工作的?(主动学习循环)
- 初始状态:您有一个基础的模型和一个未标注的数据集。
- 开启此开关:您在Label Studio的模型设置中勾选此选项。
- 标注与触发:标注员完成一张图片的标注并点击"提交"。
- 自动信号 :Label Studio不会 自己训练模型,而是立即向您指定的模型后端地址发送一个HTTP POST请求到
/train接口,并将这个新标注的数据信息传递过去。 - 后端响应 :您的机器学习后端(比如一个用PyTorch写的服务)在收到
/train请求后,才会启动训练流程,用新数据更新模型。 - 模型更新 :新模型训练好后,会自动同步回Label Studio,为后续的数据进行更准确的预标注。这样就形成了一个"标注 → 训练 → 预标注 → 再标注"的增强循环。
💡 关键点总结
| 您需要知道的 | 说明 |
|---|---|
| 它做什么 | 它是一个自动触发器,将"标注完成"这个动作,转化为"开始训练"的指令。 |
| 它不做什么 | 它本身不执行训练 。训练任务发生在您自己部署的、能够处理 /train 请求的机器学习后端服务器上。 |
| 典型用途 | 实现主动学习:模型先用少量数据训练,然后对大量未标注数据做预标注;人工只修正错误;修正后的数据立即触发模型再训练,如此循环,让模型在标注过程中快速变"聪明"。 |
| 手动替代 | 如果不开启此选项,您也可以通过在模型卡片的菜单中点击"Start training"来手动触发训练。 |
⚙️ 如何配置使用?
要使用此功能,您必须:
- 已经配置好一个机器学习后端 (即一个能够接收
/train请求并执行训练脚本的Web服务)。 - 在该后端的代码中,正确实现了处理
/train这个API接口的逻辑。
简而言之,这个红框选项是连接"人工标注"和"模型迭代"的自动化桥梁,是提升AI项目效率的核心工具之一。
如果您想了解如何搭建一个能与Label Studio配合、接收/train请求的机器学习后端,我可以为您提供更多详细信息。
Label Studio ML Backend 的代码框架中已经定义并部分实现了这个训练接口(/train),但它只是一个"骨架"。** 真正的训练逻辑需要您根据自己项目的模型和需求来具体编写。
下面这个流程图清晰地展示了训练接口的完整工作流程,以及您需要自行实现的核心部分:
markup
```mermaid
flowchart TD
A[Label Studio界面<br>标注完成并提交] --> B[HTTP POST 请求<br>发送至 ML Backend 的 /train 接口]
B --> C{框架自动处理<br>解析请求, 准备数据}
C --> D[调用 train() 函数<br>这是需要您实现的核心]
D --> E[您编写的训练逻辑<br>(加载数据, 更新模型, 保存权重等)]
E --> F[框架自动处理<br>返回成功响应]
F --> G[Label Studio 界面<br>显示训练任务状态]### 🔧 接口详情与实现方法
ML Backend 是一个基于 Python Flask 的 Web 服务器。当您在 Label Studio 界面勾选 **"Start model training on annotation submission"** 后,每次标注提交都会触发以下调用:
- **请求端点**: `POST http://<your-ml-backend-address>/train`
- **触发条件**: 标注任务被提交或更新。
- **请求数据**: 包含项目 ID、已标注任务的 ID 列表等。
#### 框架中已存在的部分
当您使用 `label-studio-ml` 包创建后端时,框架已经处理了网络通信和路由。您需要关注的核心文件是 `my_machine_learning_backend.py`(或您自定义的文件),其中包含一个继承自 `LabelStudioMLBase` 的类。
**框架已经为您准备好了"接收器"和"调度器",但"工人"(训练逻辑)需要您来雇佣和指挥。**
#### 需要您实现的核心部分
您必须在您的 ML 后端类中实现 `train()` 方法。这个方法的框架如下:
```python
from label_studio_ml.api import LabelStudioMLBase
class MyBackend(LabelStudioMLBase):
def train(self, completions, project, **kwargs):
"""
核心训练函数, 需要您自己实现
Args:
completions: 新提交的标注数据
project: 项目信息
**kwargs: 其他参数
Returns:
dict: 必须返回一个字典, 包含训练结果信息, 如新的模型版本号
"""
# 1. 从completions中解析出训练数据(图片路径、标注框等)
training_data = self._parse_completions(completions)
# 2. 【您需要实现】加载当前的模型状态
# 例如: self.model = torch.load('current_model.pth')
# 3. 【您需要实现】核心训练逻辑
# 使用新的 training_data 来更新您的模型
# 例如:
# for epoch in range(epochs):
# for images, targets in dataloader:
# ... # 训练循环
# 4. 【您需要实现】保存训练好的新模型
# 例如: torch.save(self.model.state_dict(), 'new_model.pth')
new_model_version = 'model_v2.pth'
# 5. 返回训练结果, 其中'model_version'可用于后续预测
return {
'model_version': new_model_version, # 告知Label Studio新模型的版本
'details': 'Training completed successfully!'
}
def _parse_completions(self, completions):
# 一个辅助函数, 用于从Label Studio的标注格式中解析出模型需要的训练格式
# 例如, 将JSON格式的标注转换为YOLO格式的txt文件
# 【这部分通常也需要大量自定义工作】
pass💡 更简单的替代方案
对于许多场景,不建议使用这个自动触发训练,因为它可能很低效。更常见的做法是:
- 手动触发训练:在 Label Studio 中导出完整的数据集,然后在独立的 Jupyter Notebook 或训练脚本中进行大规模的、一次性的模型训练。
- 使用 Webhook:配置 Label Studio 的 Webhook,当有足够多的新标注时,触发一个外部 CI/CD 流水线(例如 Jenkins、GitHub Actions)来启动训练任务。这种方法更可控,资源利用也更高效。
💎 总结
/train接口已定义:ML Backend 框架接收训练请求的"管道"是通的。- 训练逻辑需自写 :您必须自己实现
train()方法,包括数据解析、模型加载、训练循环和模型保存等所有核心机器学习代码。 - 慎重使用 :对于生产环境,频繁的增量训练可能并非最佳选择,考虑使用手动训练 或Webhook触发外部训练的方案通常更稳健。