目录
[1.1 Go算法的独特优势](#1.1 Go算法的独特优势)
[1.2 Go标准库中的算法工具](#1.2 Go标准库中的算法工具)
[2.1 Goroutine与Channel模式](#2.1 Goroutine与Channel模式)
[2.2 并发安全数据结构](#2.2 并发安全数据结构)
[3.1 高效排序实现](#3.1 高效排序实现)
[3.2 搜索与查找算法](#3.2 搜索与查找算法)
[4.1 图数据结构与算法](#4.1 图数据结构与算法)
[4.2 网络算法与协议](#4.2 网络算法与协议)
[5.1 基准测试与性能分析](#5.1 基准测试与性能分析)

如果您喜欢此文章,请收藏、点赞、评论,谢谢,祝您快乐每一天。
一、Go语言算法设计的核心哲学
1.1 Go算法的独特优势
Go语言算法设计融合了系统级语言的性能与高级语言的简洁:
- 内置并发原语:goroutine、channel、select
- 零开销抽象:接口、组合优于继承
- 内存管理透明:GC自动管理,栈分配优化
- 编译期优化:逃逸分析、内联优化
1.2 Go标准库中的算法工具
// 1. sort包:通用排序算法
import "sort"
type Person struct {
Name string
Age int
}
// 实现sort.Interface接口
type ByAge \[\]Person
func (a ByAge) Len() int { return len(a) }
func (a ByAge) Swap(i, j int) { ai, aj = aj, ai }
func (a ByAge) Less(i, j int) bool { return ai.Age < aj.Age }
people := \[\]Person{
{"Alice", 25},
{"Bob", 30},
{"Charlie", 20},
}
sort.Sort(ByAge(people))
// 2. 使用sort.Slice(Go 1.8+)
sort.Slice(people, func(i, j int) bool {
return peoplei.Age > peoplej.Age // 降序
})
// 3. 查找算法
index := sort.Search(len(people), func(i int) bool {
return peoplei.Age >= 25 // 二分查找
})
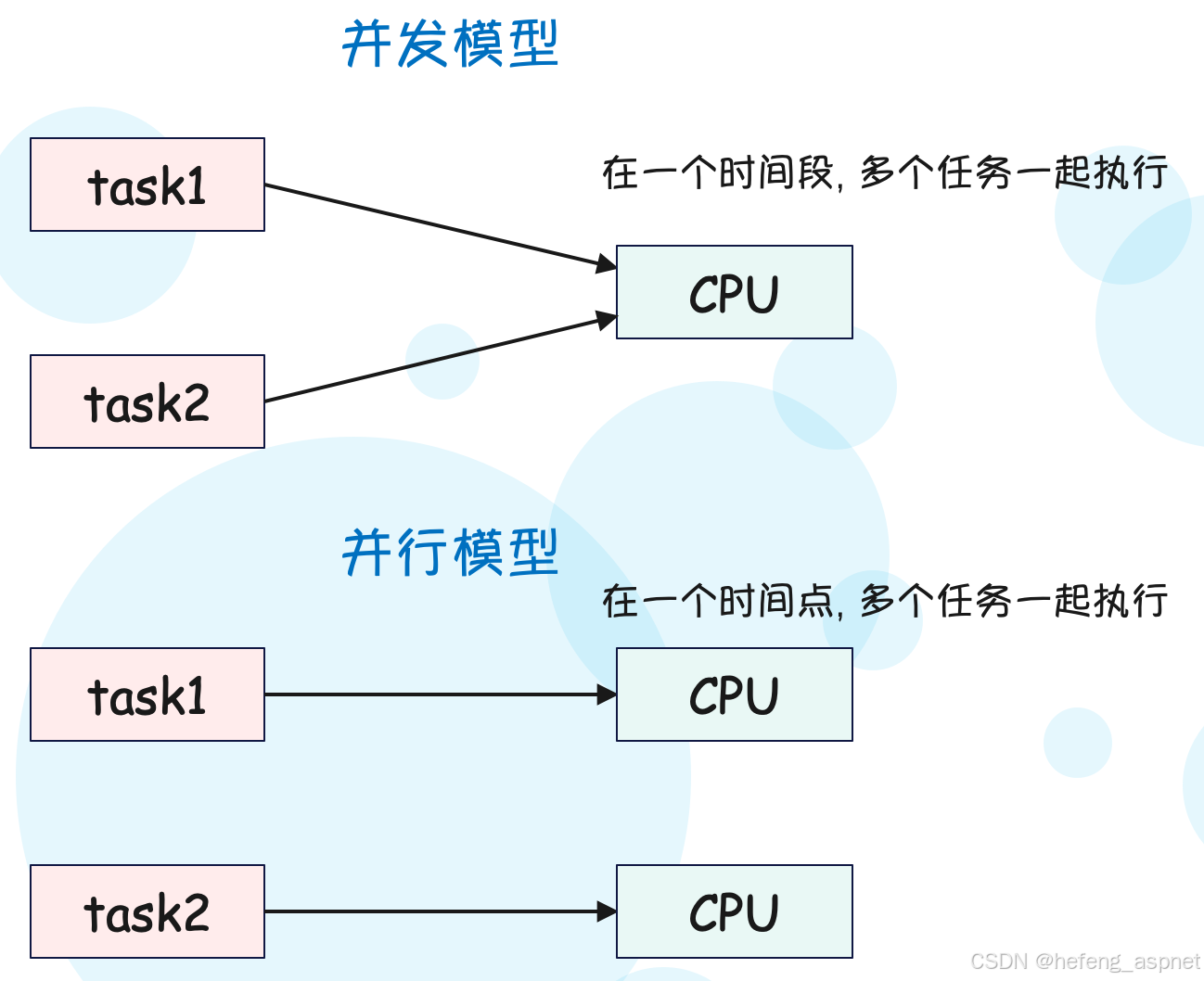
二、并发与并行算法
2.1 Goroutine与Channel模式
// 1. Worker Pool模式
func workerPool(tasks <-chan Task, results chan<- Result, workerCount int) {
var wg sync.WaitGroup
for i := 0; i < workerCount; i++ {
wg.Add(1)
go func(workerID int) {
defer wg.Done()
for task := range tasks {
results <- processTask(task, workerID)
}
}(i)
}
wg.Wait()
close(results)
}
// 2. Fan-out/Fan-in模式
func fanOutFanIn(input <-chan int) <-chan int {
// Fan-out:多个goroutine处理输入
workers := make(\[\]<-chan int, 10)
for i := 0; i < 10; i++ {
workersi = process(input)
}
// Fan-in:合并结果
return merge(workers...)
}
func merge(channels ...<-chan int) <-chan int {
var wg sync.WaitGroup
out := make(chan int)
// 为每个输入channel启动goroutine
output := func(c <-chan int) {
defer wg.Done()
for n := range c {
out <- n
}
}
wg.Add(len(channels))
for _, c := range channels {
go output(c)
}
// 等待所有goroutine完成
go func() {
wg.Wait()
close(out)
}()
return out
}
// 3. Pipeline模式
func pipeline() {
// 生成数据
generator := func(done <-chan struct{}, nums ...int) <-chan int {
out := make(chan int)
go func() {
defer close(out)
for _, n := range nums {
select {
case out <- n:
case <-done:
return
}
}
}()
return out
}
// 处理阶段
square := func(done <-chan struct{}, in <-chan int) <-chan int {
out := make(chan int)
go func() {
defer close(out)
for n := range in {
select {
case out <- n * n:
case <-done:
return
}
}
}()
return out
}
done := make(chan struct{})
defer close(done)
nums := generator(done, 1, 2, 3, 4)
squared := square(done, nums)
for n := range squared {
fmt.Println(n)
}
}
2.2 并发安全数据结构
// 1. 使用sync.Map(并发安全map)
var m sync.Map
// 存储
m.Store("key", "value")
// 加载
if value, ok := m.Load("key"); ok {
fmt.Println(value)
}
// 原子操作
m.LoadOrStore("key", "default")
// 2. 自定义并发安全数据结构
type SafeMap struct {
sync.RWMutex
data mapstringinterface{}
}
func NewSafeMap() *SafeMap {
return &SafeMap{
data: make(mapstringinterface{}),
}
}
func (sm *SafeMap) Get(key string) (interface{}, bool) {
sm.RLock()
defer sm.RUnlock()
value, ok := sm.datakey
return value, ok
}
func (sm *SafeMap) Set(key string, value interface{}) {
sm.Lock()
defer sm.Unlock()
sm.datakey = value
}
// 3. 无锁数据结构(atomic包)
type AtomicCounter struct {
value int64
}
func (c *AtomicCounter) Increment() int64 {
return atomic.AddInt64(&c.value, 1)
}
func (c *AtomicCounter) Value() int64 {
return atomic.LoadInt64(&c.value)
}
// 4. 环形缓冲区(Ring Buffer)
type RingBuffer struct {
buffer \[\]interface{}
head int64
tail int64
size int64
mask int64
}
func NewRingBuffer(size int) *RingBuffer {
size = nextPowerOfTwo(size)
return &RingBuffer{
buffer: make(\[\]interface{}, size),
size: int64(size),
mask: int64(size - 1),
}
}
func (rb *RingBuffer) Push(item interface{}) bool {
head := atomic.LoadInt64(&rb.head)
tail := atomic.LoadInt64(&rb.tail)
if head-tail >= rb.size {
return false // 缓冲区满
}
rb.bufferhead\&rb.mask = item
atomic.StoreInt64(&rb.head, head+1)
return true
}
func (rb *RingBuffer) Pop() (interface{}, bool) {
head := atomic.LoadInt64(&rb.head)
tail := atomic.LoadInt64(&rb.tail)
if tail >= head {
return nil, false // 缓冲区空
}
item := rb.buffertail\&rb.mask
atomic.StoreInt64(&rb.tail, tail+1)
return item, true
}
三、排序与搜索算法
3.1 高效排序实现
// 1. 快速排序(原地排序)
func quickSort(arr \[\]int) {
if len(arr) <= 1 {
return
}
pivot := arrlen(arr)/2
left, right := 0, len(arr)-1
for left <= right {
for arrleft < pivot {
left++
}
for arrright > pivot {
right--
}
if left <= right {
arrleft, arrright = arrright, arrleft
left++
right--
}
}
quickSort(arr:right+1)
quickSort(arrleft:)
}
// 2. 归并排序(稳定排序)
func mergeSort(arr \[\]int) \[\]int {
if len(arr) <= 1 {
return arr
}
mid := len(arr) / 2
left := mergeSort(arr:mid)
right := mergeSort(arrmid:)
return merge(left, right)
}
func merge(left, right \[\]int) \[\]int {
result := make(\[\]int, 0, len(left)+len(right))
i, j := 0, 0
for i < len(left) && j < len(right) {
if lefti <= rightj {
result = append(result, lefti)
i++
} else {
result = append(result, rightj)
j++
}
}
result = append(result, lefti:...)
result = append(result, rightj:...)
return result
}
// 3. 堆排序
type Heap struct {
items \[\]int
}
func (h *Heap) Push(item int) {
h.items = append(h.items, item)
h.up(len(h.items) - 1)
}
func (h *Heap) Pop() int {
n := len(h.items) - 1
h.items0, h.itemsn = h.itemsn, h.items0
h.down(0, n)
item := h.itemsn
h.items = h.items:n
return item
}
func (h *Heap) up(i int) {
for {
parent := (i - 1) / 2
if i == 0 || h.itemsparent >= h.itemsi {
break
}
h.itemsparent, h.itemsi = h.itemsi, h.itemsparent
i = parent
}
}
func (h *Heap) down(i, n int) {
for {
child := 2*i + 1
if child >= n {
break
}
if child+1 < n && h.itemschild < h.itemschild+1 {
child++
}
if h.itemsi >= h.itemschild {
break
}
h.itemsi, h.itemschild = h.itemschild, h.itemsi
i = child
}
}
3.2 搜索与查找算法
// 1. 二分查找
func binarySearch(arr \[\]int, target int) int {
left, right := 0, len(arr)-1
for left <= right {
mid := left + (right-left)/2
if arrmid == target {
return mid
} else if arrmid < target {
left = mid + 1
} else {
right = mid - 1
}
}
return -1
}
// 2. 插值查找(均匀分布数据)
func interpolationSearch(arr \[\]int, target int) int {
left, right := 0, len(arr)-1
for left <= right && target >= arrleft && target <= arrright {
if left == right {
if arrleft == target {
return left
}
return -1
}
// 插值公式
pos := left + ((target-arrleft)*(right-left))/(arrright-arrleft)
if arrpos == target {
return pos
} else if arrpos < target {
left = pos + 1
} else {
right = pos - 1
}
}
return -1
}
// 3. Bloom Filter(布隆过滤器)
type BloomFilter struct {
bitset \[\]bool
hashes \[\]func(\[\]byte) uint32
}
func NewBloomFilter(size int) *BloomFilter {
return &BloomFilter{
bitset: make(\[\]bool, size),
hashes: \[\]func(\[\]byte) uint32{
fnvHash,
murmurHash,
},
}
}
func (bf *BloomFilter) Add(item \[\]byte) {
for _, hash := range bf.hashes {
index := hash(item) % uint32(len(bf.bitset))
bf.bitsetindex = true
}
}
func (bf *BloomFilter) Contains(item \[\]byte) bool {
for _, hash := range bf.hashes {
index := hash(item) % uint32(len(bf.bitset))
if !bf.bitsetindex {
return false
}
}
return true
}
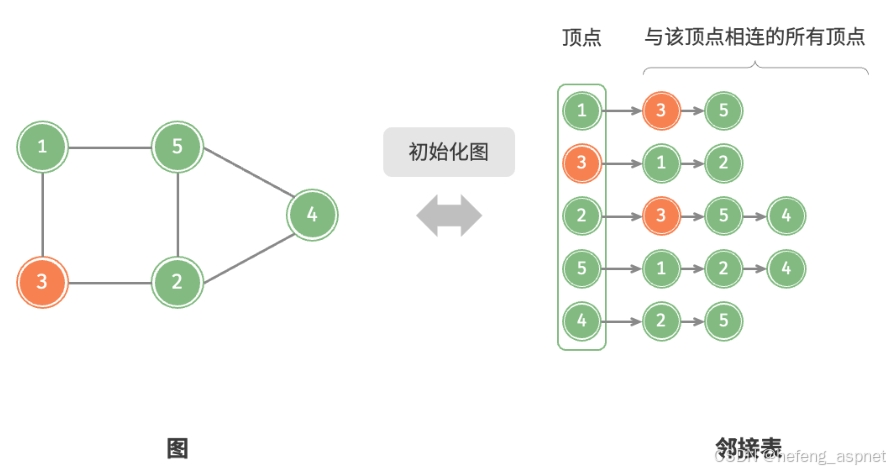
四、图算法与网络分析
4.1 图数据结构与算法
// 1. 图的邻接表表示
type Graph struct {
vertices mapint\[\]int
directed bool
}
func NewGraph(directed bool) *Graph {
return &Graph{
vertices: make(mapint\[\]int),
directed: directed,
}
}
func (g *Graph) AddEdge(u, v int) {
g.verticesu = append(g.verticesu, v)
if !g.directed {
g.verticesv = append(g.verticesv, u)
}
}
// 2. BFS(广度优先搜索)
func (g *Graph) BFS(start int) \[\]int {
visited := make(mapintbool)
queue := \[\]int{start}
result := \[\]int{}
for len(queue) > 0 {
vertex := queue0
queue = queue1:
if !visitedvertex {
visitedvertex = true
result = append(result, vertex)
for _, neighbor := range g.verticesvertex {
if !visitedneighbor {
queue = append(queue, neighbor)
}
}
}
}
return result
}
// 3. DFS(深度优先搜索)
func (g *Graph) DFS(start int) \[\]int {
visited := make(mapintbool)
result := \[\]int{}
var dfs func(int)
dfs = func(vertex int) {
visitedvertex = true
result = append(result, vertex)
for _, neighbor := range g.verticesvertex {
if !visitedneighbor {
dfs(neighbor)
}
}
}
dfs(start)
return result
}
// 4. Dijkstra算法(最短路径)
type WeightedGraph struct {
vertices mapint\[\]Edge
}
type Edge struct {
to int
weight float64
}
func (wg *WeightedGraph) Dijkstra(start int) mapintfloat64 {
distances := make(mapintfloat64)
for vertex := range wg.vertices {
distancesvertex = math.Inf(1)
}
distancesstart = 0
pq := make(PriorityQueue, 0)
heap.Push(&pq, &Item{value: start, priority: 0})
for pq.Len() > 0 {
item := heap.Pop(&pq).(*Item)
u := item.value
for _, edge := range wg.verticesu {
v := edge.to
alt := distancesu + edge.weight
if alt < distancesv {
distancesv = alt
heap.Push(&pq, &Item{value: v, priority: alt})
}
}
}
return distances
}
4.2 网络算法与协议
// 1. 一致性哈希算法
type ConsistentHash struct {
replicas int
keys \[\]int
hashMap mapintstring
}
func NewConsistentHash(replicas int) *ConsistentHash {
return &ConsistentHash{
replicas: replicas,
hashMap: make(mapintstring),
}
}
func (ch *ConsistentHash) AddNode(node string) {
for i := 0; i < ch.replicas; i++ {
hash := int(crc32.ChecksumIEEE(\[\]byte(fmt.Sprintf("%s:%d", node, i))))
ch.keys = append(ch.keys, hash)
ch.hashMaphash = node
}
sort.Ints(ch.keys)
}
func (ch *ConsistentHash) GetNode(key string) string {
if len(ch.keys) == 0 {
return ""
}
hash := int(crc32.ChecksumIEEE(\[\]byte(key)))
idx := sort.Search(len(ch.keys), func(i int) bool {
return ch.keysi >= hash
})
if idx == len(ch.keys) {
idx = 0
}
return ch.hashMapch.keys\[idx]
}
// 2. 令牌桶算法(限流)
type TokenBucket struct {
capacity int
tokens int
lastRefill time.Time
refillRate time.Duration
mu sync.Mutex
}
func NewTokenBucket(capacity int, refillRate time.Duration) *TokenBucket {
return &TokenBucket{
capacity: capacity,
tokens: capacity,
lastRefill: time.Now(),
refillRate: refillRate,
}
}
func (tb *TokenBucket) refill() {
now := time.Now()
elapsed := now.Sub(tb.lastRefill)
tokensToAdd := int(elapsed / tb.refillRate)
if tokensToAdd > 0 {
tb.tokens = min(tb.capacity, tb.tokens+tokensToAdd)
tb.lastRefill = now
}
}
func (tb *TokenBucket) Take() bool {
tb.mu.Lock()
defer tb.mu.Unlock()
tb.refill()
if tb.tokens > 0 {
tb.tokens--
return true
}
return false
}
// 3. 滑动窗口算法(限流)
type SlidingWindow struct {
windowSize time.Duration
maxRequests int
requests \[\]time.Time
mu sync.Mutex
}
func NewSlidingWindow(windowSize time.Duration, maxRequests int) *SlidingWindow {
return &SlidingWindow{
windowSize: windowSize,
maxRequests: maxRequests,
}
}
func (sw *SlidingWindow) Allow() bool {
sw.mu.Lock()
defer sw.mu.Unlock()
now := time.Now()
cutoff := now.Add(-sw.windowSize)
// 移除过期请求
i := 0
for i < len(sw.requests) && sw.requestsi.Before(cutoff) {
i++
}
sw.requests = sw.requestsi:
if len(sw.requests) >= sw.maxRequests {
return false
}
sw.requests = append(sw.requests, now)
return true
}
五、测试与性能优化
5.1 基准测试与性能分析
// 1. 基准测试
func BenchmarkQuickSort(b *testing.B) {
for i := 0; i < b.N; i++ {
arr := generateRandomArray(1000)
quickSort(arr)
}
}
func BenchmarkMergeSort(b *testing.B) {
for i := 0; i < b.N; i++ {
arr := generateRandomArray(1000)
_ = mergeSort(arr)
}
}
// 2. 内存分配分析
func processData(data \[\]byte) \[\]byte {
// 避免不必要的内存分配
result := make(\[\]byte, 0, len(data)*2)
for _, b := range data {
result = append(result, b)
result = append(result, b) // 复制一份
}
return result
}
// 3. 使用sync.Pool减少GC压力
var bufferPool = sync.Pool{
New: func() interface{} {
return bytes.NewBuffer(make(\[\]byte, 0, 1024))
},
}
func processWithPool(data \[\]byte) \[\]byte {
buf := bufferPool.Get().(*bytes.Buffer)
defer bufferPool.Put(buf)
buf.Reset()
buf.Write(data)
buf.WriteString(" processed")
return buf.Bytes()
}
// 4. 逃逸分析优化
func processNoEscape(data \[\]byte) \[\]byte {
// 在栈上分配结果
result := make(\[\]byte, len(data))
copy(result, data)
return result
}
func processEscape(data \[\]byte) \[\]byte {
// 可能逃逸到堆
result := make(\[\]byte, len(data))
for i := range data {
resulti = datai + 1
}
// 将结果传递给另一个函数,可能导致逃逸
return processFurther(result)
}
如果您喜欢此文章,请收藏、点赞、评论,谢谢,祝您快乐每一天。