文章目录
- 模型对比
- [PANNs: 相当于音频分类领域的imagenet](#PANNs: 相当于音频分类领域的imagenet)
- [beats: Audio Pre-Training with Acoustic Tokenizers](#beats: Audio Pre-Training with Acoustic Tokenizers)
- [hubert vs beats 不同点的对比](#hubert vs beats 不同点的对比)
模型对比
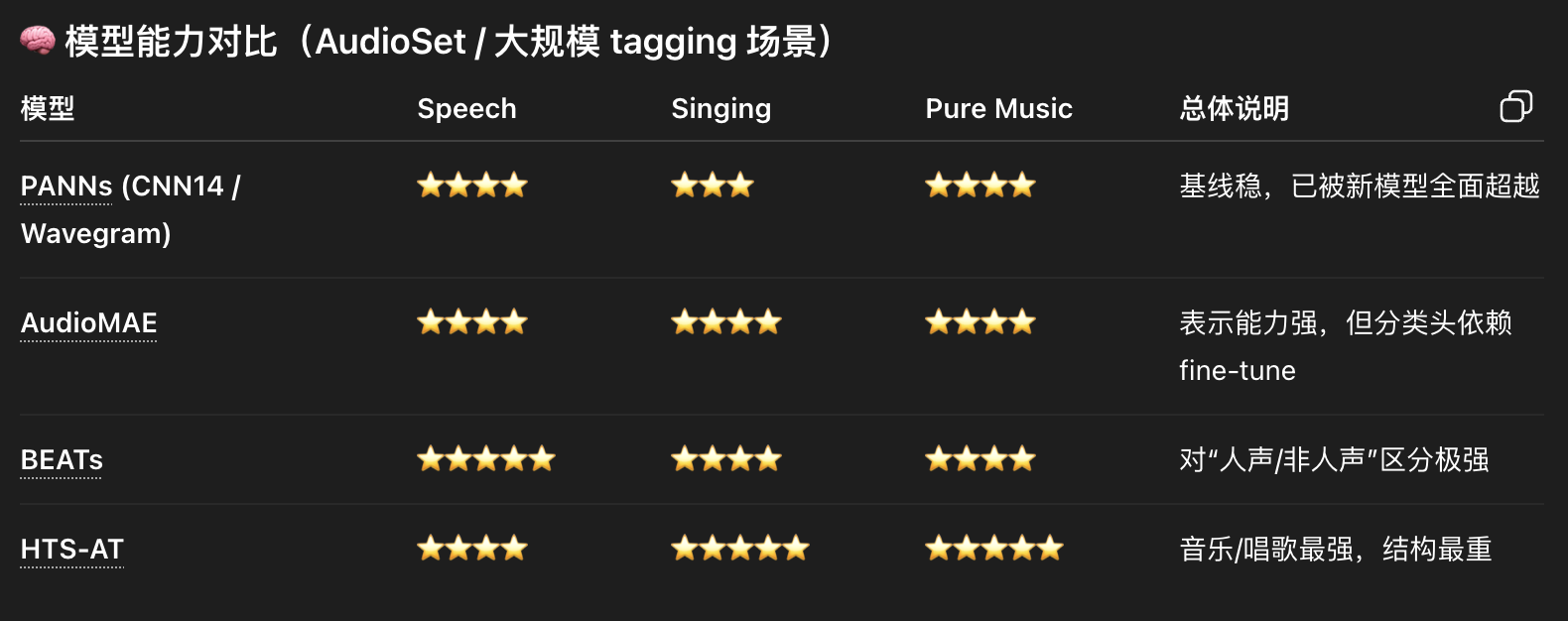
- audioset 是一个多级标签的音频分类数据集,一共有527个标签。一般用mAP (mean average precision)评估分类的准确度。模型可以同时打多个标签(符合真实场景)
- mAP 衡量的是:模型在"不同置信度阈值下,能否把真正相关的标签排在前面"
- 普通的acc: 只要全预测 0,accuracy 也很高
PANNs: 相当于音频分类领域的imagenet
- 创新点:
- balanced sampling:不是"样本均衡",而是"类别均衡" , ≈ mAP +4~6 个点
- Mixup(混合样本增强):log-mel 上混合多种音频,更加模拟真实环境
- SpecAugment(时频遮挡),不依赖某一个瞬时帧,不死记某个固定频段,对各种来源的网络数据提升鲁棒性;
- 大 embedding(2048 维):提隐藏空间表示能力beats: Audio Pre-Training with Acoustic Tokenizers
- paper
- beats 两个模块:
- SSL encoder : train 阶段输入mel patch,mask部分,预测token id;后续使用只输出embedding,用于下游任务
- tokenizer: train / infer 阶段输入mel patch,预测token id;
- 迭代优化
- 线训练SSL encoder,然后作为teacher 训练tokenizer,tokenizer迭代几个轮次之后,token id的结果作为ssl encoder的预测目标

- 线训练SSL encoder,然后作为teacher 训练tokenizer,tokenizer迭代几个轮次之后,token id的结果作为ssl encoder的预测目标
- beats 模型优化2-3 个iter 即可,训练过深反而会语义坍缩
- 因为token 初始化是随机的,因为前1-2 iter token的约束比较弱,encoder 自行探索出数据主导的结构,同时tokenizer的蒸馏效率比较高(学到的信息比较多)
- 第2-3轮,encoder 已经把主要的语义学习到了,tokenizer 再蒸馏的时候学习的是encoder的细节偏好,而不是新的语义特征
- 后续轮次:encoder的信息更新很少,token本身就是一种高度压缩,信息有损的表示,所以是一个有偏的估计,tokenizer 去拟合encoder,拟合的误差会被带回encoder,而且没有偏差纠正引入,所以微小偏差会通过闭环被 encoder 再次放大。
hubert vs beats 不同点的对比
- beats 能用于通用音频任务(speech/singing/music 分类等)。hubert 主要用于asr 识别
- 即使没有beats的tokenizer,两者也不一样
- hubert
- token init 方式:MFCC +kmeans,硬聚类,假设每个token 是一个phone,丢掉了长时相关性;在asr 任务中,phoneme ≈ 声学簇,这个先验假设是成立的;
- 后续训练: m a x I ( Z e n c ; Z t o k e n ) maxI(Z_{enc};Z_{token}) maxI(Zenc;Ztoken),预测的token 去逼近
- Beats
- token init是刻意弱假设 的:随机投影、随机 codebook、没有试图表达"正确语义"。

- token init是刻意弱假设 的:随机投影、随机 codebook、没有试图表达"正确语义"。