在Kafka的分布式架构中,重平衡(Rebalance)和副本(Replica)是两个核心概念,却常常被混淆。前者关乎消费端的负载均衡与可用性,后者决定服务端的数据可靠性与容灾能力。很多开发者在运维过程中会遇到"消费停顿""消息滞后"等问题,根源往往是没理清重平衡的触发逻辑,以及它与副本机制的底层关联。本文将从概念区分、触发条件、执行流程入手,层层拆解重平衡与副本的深度绑定关系,并给出生产环境可落地的优化方案,助力大家搭建高可用的Kafka读写架构。
一、先厘清核心概念:别再混淆"重平衡"与"分区重分配"
在聊重平衡之前,必须先明确一个关键区分:重平衡是消费端的操作,而分区重分配是服务端(Broker)的操作,二者维度不同,但通过"副本"紧密关联。
1. 重平衡(Rebalance):消费组的"负载再分配"机制
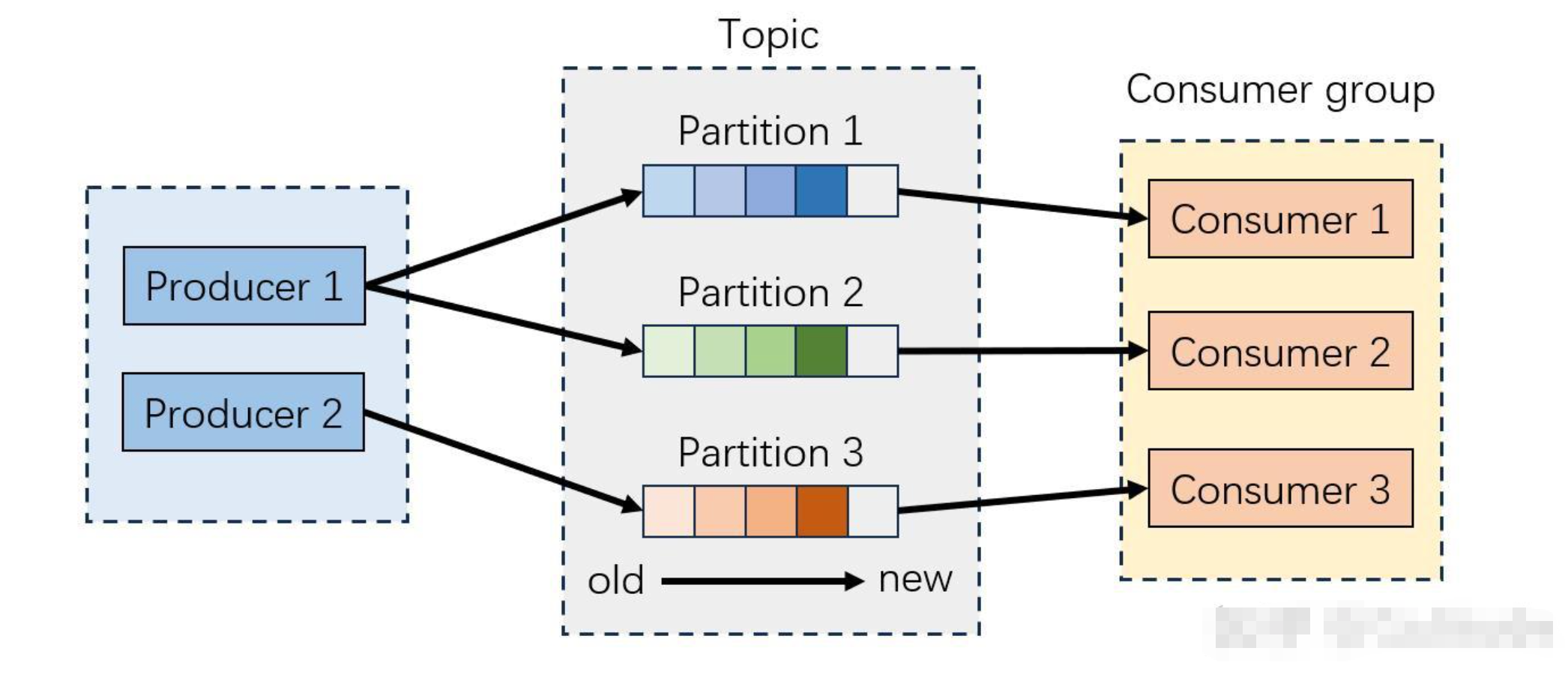
Kafka的消费组(Consumer Group)是实现消息并行消费的核心:多个消费者组成一个消费组,共同承接一个或多个Topic的消费任务。重平衡的本质,就是当消费组的"消费能力"或"消费对象"发生变化时,重新分配Topic分区与消费者的映射关系,确保"一个分区同一时间仅被一个消费者消费""所有分区都有消费者承接"的核心规则。
打个通俗的比方:消费组就像一支快递配送队,消费者是配送员,Topic的分区是快递片区。重平衡就相当于配送队的"片区重划分",当有配送员入职/离职,或新增了快递片区时,经理会重新分配每个人负责的片区,保证配送效率和无遗漏。
2. 分区重分配(Partition Reassignment):Broker端的"副本调度"操作
与重平衡不同,分区重分配是服务端层面的操作,核心是调整Topic分区副本在Broker集群中的分布。我们知道,Kafka的分区数据会冗余存储在多个Broker上(即副本),分区重分配就是将这些副本从一个Broker迁移到另一个Broker,目的是均衡集群负载、修复副本异常,或适配Broker扩容/缩容需求。
3. 副本(Replica):重平衡的"物理依赖载体"
副本是分区数据的冗余备份,分为Leader副本(主副本)和Follower副本(从副本):Leader副本是分区唯一的读写入口,所有生产/消费请求都必须经过它;Follower副本仅负责同步Leader的数据,作为容灾备用。而重平衡最终分配的是"分区",但消费者实际连接的是分区的Leader副本,这也是二者最核心的关联点,副本的稳定性直接决定重平衡的成败与效率。
二、重平衡的触发条件:哪些场景会引发消费停顿?
重平衡的核心代价是"消费停顿",重平衡期间,消费组内所有消费者都会停止消费,直到分配完成。生产环境中,我们要杜绝非必要的重平衡,首先得明确它的触发场景,主要分为主动触发和被动触发两大类。
1. 主动触发:人为操作或业务调整导致
-
消费组扩容/缩容:为提升消费能力新增消费者,或因资源紧张下线部分消费者,都会打破原有分区分配平衡,触发重平衡。这是最常见的主动触发场景。
-
Topic分区数量增加:Kafka不支持减少分区,只能新增分区。新增分区后,消费组需要重新分配,让新分区被消费者承接,避免无人消费。
-
消费组订阅规则变更:若消费组内某个消费者修改了订阅的Topic列表(比如从仅订阅topic-order改为订阅topic-order+topic-pay),整个消费组需要重新分配所有订阅Topic的分区。
2. 被动触发:异常场景导致的自动调整
这类触发场景是生产环境需要重点规避的,多由配置不合理或组件异常导致:
-
消费者心跳/会话超时:消费者会定期向协调器(Coordinator,Broker上的进程,负责管理消费组)发送心跳(默认3秒),若心跳中断超过会话超时时间(默认45秒),协调器会判定该消费者"死亡",将其移出消费组并触发重平衡。
-
消费者消费阻塞:若消费者长时间未提交消费偏移量(Offset),超过max.poll.interval.ms(默认5分钟),协调器会认为消费者处于阻塞状态,将其移出消费组,触发重平衡。
-
Broker端副本异常:当分区Leader副本宕机、发生Leader切换,或执行分区重分配时,会导致分区元数据变更,消费者连接失效,间接触发重平衡。
三、重平衡的完整执行流程:消费停顿的3个阶段
重平衡的执行全程由协调器(Coordinator)和消费组长(Group Leader)协同管控,一个消费组对应一个协调器,消费组长由组内第一个消费者担任(若组长失联会重新选举)。整个过程分为3个阶段,全程消费组处于停止消费状态。
阶段1:准备阶段,感知变化,进入重平衡状态
当消费组内出现消费者上下线、分区数量变化等触发条件时,协调器会第一时间感知到变化,将消费组状态标记为"Rebalancing"(重平衡中),并向组内所有存活消费者发送重平衡通知。收到通知的消费者会立即停止消费,同步自身当前的消费状态(如已消费的Offset)到协调器,等待后续分配。
阶段2:分配阶段,选举组长,执行分区分配算法
首先由协调器选举消费组长,组长的核心职责是执行分区分配算法。协调器会将"组内存活消费者列表""订阅的所有Topic及分区列表"发送给组长,组长根据预设的分配策略(常用的有range、round-robin、sticky三种),将所有分区公平分配给存活消费者,生成"消费者-分区"映射表。之后组长将映射表同步给协调器,再由协调器分发给每个消费者。
这里需要注意:生产环境推荐使用sticky(粘性分配)策略(Kafka 2.3+默认),该策略会尽量保留重平衡前的分区分配关系,减少分区迁移量,从而缩短重平衡时间。
阶段3:恢复阶段,加载分配结果,重启消费
每个消费者收到自己负责的分区列表后,会通过Kafka元数据服务获取每个分区的Leader副本所在Broker地址,建立连接(消费者永远只连接Leader副本)。之后从上次提交的Offset位置开始拉取消息并消费,消费组状态恢复为"Stable"(稳定状态),重平衡正式完成。
重平衡的停顿时间,取决于消费组规模、分区数量和分配算法复杂度,大规模消费组(如百级消费者、千级分区)的重平衡,可能导致秒级甚至十秒级消费停顿,这在核心业务场景中是难以接受的,因此必须通过优化减少重平衡的触发频率和停顿时间。
四、核心关联:重平衡与副本的深度绑定关系
重平衡是消费端操作,副本是服务端机制,二者看似独立,实则深度绑定,副本的稳定性直接决定重平衡是否触发、触发后的恢复效率,而Broker端的副本调整(如分区重分配)又会直接引发消费端重平衡。具体关联体现在5个方面:
1. 重平衡的本质:消费者与Leader副本的绑定
重平衡分配的是"分区ID",但消费者最终实际交互的是分区的Leader副本。协调器在分发分区分配结果时,会同步每个分区的Leader副本所在Broker地址,消费者收到后会直接连接该Broker的Leader副本进行读写。如果某个分区的Leader副本不可用(如Broker宕机),消费者无法建立连接,重平衡就会失败或反复触发。
2. Leader副本切换:重平衡的"间接触发器"
当Broker宕机、执行优先副本选举或分区重分配时,会发生Leader副本切换。切换过程中,分区元数据(Leader地址)会临时失效,消费者与旧Leader的连接会断开。若断开时间超过会话超时时间,协调器会判定消费者失联,触发重平衡;即使切换很快,消费者感知到元数据更新后,也可能因连接重建导致短暂的消费停顿,极端情况下会引发多次重平衡。
3. 副本同步异常:增加重平衡的触发概率
Follower副本负责同步Leader的数据,若因网络抖动、资源紧张导致同步超时,会被移出ISR队列(同步副本队列)。此时若Leader副本宕机,可能因无可用Follower副本晋升为新Leader,导致分区不可用。消费者连接不可用的分区后,会持续抛出异常,若异常时间过长,会被判定为消费阻塞,触发重平衡。
4. 副本因子配置:决定重平衡的恢复效率
副本因子(Replication Factor)越大,分区的容灾能力越强。生产环境推荐副本因子=3,即1个Leader副本+2个Follower副本,此时Leader宕机后,能从ISR队列中秒级选举新Leader,分区不可用时间极短,消费者只需重新连接新Leader,无需触发重平衡;若副本因子=1(无备份),Leader宕机后分区直接不可用,消费者会持续超时,最终触发重平衡,且重平衡后仍无法消费该分区。
5. 分区重分配:重平衡的"直接诱因"
Broker端执行分区重分配时,会经历"数据复制→Leader切换→旧副本删除"的流程,期间会发生多次Leader切换和元数据更新。消费端感知到这些变化后,会立即触发重平衡,甚至在整个分区重分配过程中,消费端会反复触发重平衡,导致持续的消费停顿。这也是为什么生产环境执行分区重分配时,必须选择业务低峰期。
总结来说,二者的关联可以概括为:副本稳定→Leader可用→消费者连接正常→减少重平衡;副本异常→Leader切换/分区不可用→消费者超时→触发重平衡。
五、生产环境优化:如何减少非必要重平衡?
重平衡的核心痛点是消费停顿,优化的核心目标是"杜绝非必要重平衡,缩短必要重平衡的停顿时间"。结合前文的关联分析,可从消费端配置、代码优化、副本稳定性三个维度入手,落地以下优化策略:
1. 优化消费者核心配置,规避超时触发
通过调整超时配置,匹配实际消费能力,避免因误判导致的重平衡。生产环境推荐配置如下(需满足session.timeout.ms是heartbeat.interval.ms的3-5倍):
-
heartbeat.interval.ms:1000ms(提高心跳频率,快速感知存活状态)
-
session.timeout.ms:10000ms(缩短会话超时,快速剔除真正宕机的消费者)
-
max.poll.interval.ms:600000ms(延长消费超时,避免因处理大消息被判定为阻塞)
-
fetch.max.records:1000-2000条(按消费能力调整,提升消费效率)
2. 优化消费者代码,避免消费阻塞
代码层面的问题是导致消费阻塞的主要原因,需重点注意两点:一是避免在消费线程中执行耗时操作(如数据库批量写入、远程接口调用),建议将耗时操作放入异步线程池,消费线程仅负责拉取和提交Offset;二是保证消费组内所有消费者的订阅规则一致,避免因订阅差异触发重平衡。
3. 保障副本稳定性,减少间接触发
从Broker端优化副本机制,提升Leader可用性,间接减少重平衡:一是配置生产环境黄金副本组合(replication.factor=3 + acks=all + min.insync.replicas=2 + unclean.leader.election.enable=false),保证副本同步稳定;二是调大replica.lag.time.max.ms(如60秒),避免Follower因短暂抖动被移出ISR队列;三是执行分区重分配时,通过--throttle参数限制迁移速度,减少Leader切换次数。
4. 优化重平衡本身,缩短停顿时间
除了上述优化,还可通过选择粘性分配策略、控制消费组规模(避免消费者过多或分区过多)、避免频繁扩缩容等方式,缩短重平衡的执行时间,降低对业务的影响。
5.重平衡和重分配区别
| 对比维度 | 重平衡(Rebalance) | 分区重分配(Partition Reassignment) |
|---|---|---|
| 操作层面 | 消费端(Consumer Group) | Broker端(服务端) |
| 操作对象 | 消费组内的「消费者-分区」分配关系 | Topic的「分区副本-Broker」分布关系 |
| 执行主体 | 消费组协调器(Coordinator)+ 消费组长 | Kafka控制器(Controller) |
| 核心目标 | 公平分配消费负载,保证消费无遗漏 | 均衡Broker负载,提升数据可靠性/容灾能力 |
| 核心代价 | 消费组停顿消费,可能导致消费滞后 | 占用Broker的网络/CPU/磁盘资源,可能影响生产/消费性能 |
| 触发核心原因 | 消费者数量/分区数变化、消费者超时、订阅规则变化 | Broker扩容/缩容、负载不均衡、副本因子调整、Broker宕机 |
| 与副本的关系 | 依赖Leader副本的可用性,副本异常间接触发 | 直接调整副本的分布,切换Leader副本 |
六、总结
重平衡是Kafka消费端实现负载均衡的核心机制,但其"消费停顿"的代价需要重点规避;副本是服务端保障数据可靠性的基础,也是重平衡的物理依赖载体。二者通过Leader副本深度绑定,副本的稳定性直接决定重平衡的触发频率和恢复效率,而Broker端的副本调整又会直接引发消费端重平衡。
在生产环境中,搭建高可用的Kafka架构,不仅需要合理配置副本机制(如副本因子=3),保障Leader副本的稳定与快速切换,还需要优化消费端配置和代码,杜绝非必要的重平衡。只有协同优化服务端和消费端,才能在保证数据可靠性的同时,实现高效、无停顿的消息消费,为业务提供稳定的支撑。