欢迎来到我的博客,代码的世界里,每一行都是一个故事

🎏:你只管努力,剩下的交给时间
🏠 :小破站
从Oracle到金仓:多模融合数据库如何实现一库替代五库
-
- 不止于兼容:平滑替代主流关系数据库的基石
-
- [1. 原生多语法兼容与协议兼容](#1. 原生多语法兼容与协议兼容)
- [2. 全流程自动化迁移方案](#2. 全流程自动化迁移方案)
- 不止于关系:多模融合架构解锁全场景价值
-
- [1. 时序+多模:驾驭PB级数据的实时洞察](#1. 时序+多模:驾驭PB级数据的实时洞察)
- [2. GIS+关系:赋能空间智能决策](#2. GIS+关系:赋能空间智能决策)
- [3. 文档+协议:无缝接替NoSQL生态](#3. 文档+协议:无缝接替NoSQL生态)
- [4. 向量+AI:构筑大模型应用的全栈底座](#4. 向量+AI:构筑大模型应用的全栈底座)
- 一库全替代:融合架构带来的根本性优势
- 实践证明:全行业、全场景的成功落地
- 总结
- 感谢
关键词: 金仓数据库,KingbaseES,融合数据库,国产数据库替代,Oracle替代,MySQL替代,SQL Server替代,GIS数据库,时序数据库,文档数据库,向量数据库,数据库国产化
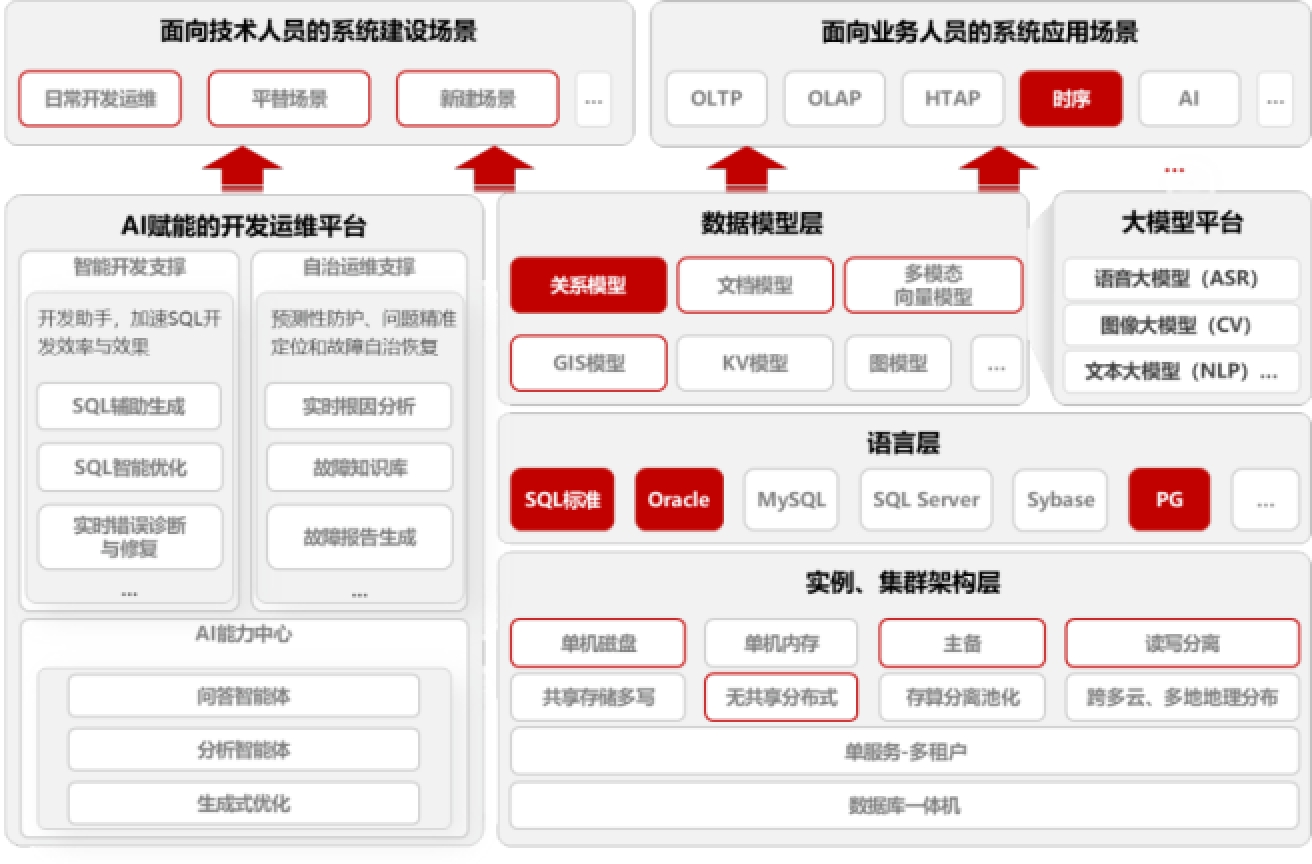
在数字经济蓬勃发展的当下,企业面对着日益多样化的数据形态与海量的数据处理需求。工业物联网中设备的时序数据、政务平台中的地理空间信息、金融风控中的关系图谱、AI应用中的高维向量......数据类型"百花齐放",传统解决方案往往需要引入多种针对性的数据库产品(如Oracle、MySQL、TimescaleDB/InfluxDB、MongoDB、Elasticsearch、Milvus等),形成复杂、割裂、高成本的技术栈体系。
面对这一挑战,金仓数据库KingbaseES(KES)以其创新的"多模融合架构",提出并践行了**"一个数据库全替代"**的先进理念。它不只着眼于对Oracle、MySQL、SQL Server等主流关系型数据库的平滑迁移替代,更进一步将时序、GIS、文档、向量、KV等多样化数据模型的处理能力深度融合于一个统一的数据库内核之中,为企业提供了一站式、高性能、高兼容的数据底座解决方案。
不止于兼容:平滑替代主流关系数据库的基石
"全替代"的第一步是实现对存量生态的无缝承接。金仓数据库以此为核心竞争力,为企业迁移降低门槛、扫清障碍。
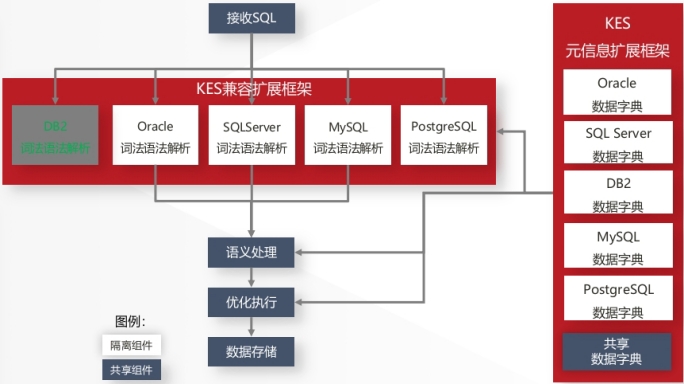
1. 原生多语法兼容与协议兼容
金仓数据库内置了业界领先的可插拔式兼容扩展框架。如同一个智能适配器,它能让应用原有的SQL(包括复杂的PL/SQL、T-SQL)、函数、视图、触发器、存储过程等在金仓数据库中无需修改代码即可运行,实现了对Oracle、MySQL、SQL Server、PostgreSQL、DB2 等多种数据库语法与语义的高度兼容(常用语法兼容趋近100%)。
Oracle兼容模式配置与示例:
sql
-- 查看当前兼容模式
SHOW ora_input_emptystr_isnull;
SHOW database_mode;
-- 启用Oracle兼容特性
SET ora_input_emptystr_isnull = ON; -- 空字符串视为NULL(Oracle行为)
-- Oracle风格的PL/SQL存储过程在KES中直接运行
CREATE OR REPLACE PROCEDURE calc_employee_bonus(
p_emp_id IN NUMBER,
p_bonus OUT NUMBER
) AS
v_salary NUMBER;
v_performance VARCHAR2(20);
BEGIN
SELECT salary, performance_level
INTO v_salary, v_performance
FROM employees
WHERE employee_id = p_emp_id;
-- Oracle风格的CASE表达式
p_bonus := CASE v_performance
WHEN 'A' THEN v_salary * 0.3
WHEN 'B' THEN v_salary * 0.2
WHEN 'C' THEN v_salary * 0.1
ELSE 0
END;
DBMS_OUTPUT.PUT_LINE('员工' || p_emp_id || '的奖金为:' || p_bonus);
EXCEPTION
WHEN NO_DATA_FOUND THEN
p_bonus := 0;
DBMS_OUTPUT.PUT_LINE('未找到员工信息');
END;
/
-- 调用存储过程
DECLARE
v_bonus NUMBER;
BEGIN
calc_employee_bonus(1001, v_bonus);
END;
/MySQL兼容模式示例:
sql
-- 切换到MySQL兼容模式
SET database_mode = 'mysql';
-- MySQL风格的AUTO_INCREMENT
CREATE TABLE orders (
id INT AUTO_INCREMENT PRIMARY KEY,
order_no VARCHAR(50) NOT NULL,
customer_id INT,
amount DECIMAL(10,2),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- MySQL风格的INSERT ... ON DUPLICATE KEY UPDATE
INSERT INTO orders (order_no, customer_id, amount)
VALUES ('ORD-2026-001', 1001, 999.00)
ON DUPLICATE KEY UPDATE amount = VALUES(amount);
-- MySQL风格的LIMIT语法
SELECT * FROM orders ORDER BY created_at DESC LIMIT 10, 20;
-- MySQL风格的GROUP_CONCAT函数
SELECT customer_id, GROUP_CONCAT(order_no SEPARATOR ', ') AS order_list
FROM orders
GROUP BY customer_id;更进一步,KES支持MySQL等数据库的原生协议兼容,应用无需更换驱动,仅修改连接串即可接入,最大程度保留了用户现有的开发生态与使用习惯。
Java应用连接示例(无需更换驱动):
java
// 原MySQL连接配置
// String url = "jdbc:mysql://192.168.1.100:3306/mydb";
// 迁移到KES,仅需修改连接地址,驱动保持不变
String url = "jdbc:mysql://192.168.1.200:54321/mydb";
String user = "system";
String password = "kingbase";
Connection conn = DriverManager.getConnection(url, user, password);2. 全流程自动化迁移方案
金仓提供包括KDMS(结构迁移与评估)、KDTS(全量数据迁移)、KFS(异构实时同步)在内的完整工具链。这套组合方案支持"准在线"迁移,能在极短的业务停机窗口内,完成TB级数据的安全、高效同步与一致性校验,并支持双轨运行与快速回退,将迁移风险与业务影响降至最低。
迁移工具链使用流程:
bash
# 1. 使用KDMS进行迁移评估
kdms assess --source oracle://user:pass@192.168.1.100:1521/orcl \
--target kingbase://system:kingbase@192.168.1.200:54321/mydb \
--output /tmp/assess_report.html
# 2. 结构迁移(DDL转换)
kdms migrate --source oracle://user:pass@192.168.1.100:1521/orcl \
--target kingbase://system:kingbase@192.168.1.200:54321/mydb \
--mode structure \
--convert-syntax auto
# 3. 使用KDTS进行全量数据迁移
kdts transfer --source oracle://user:pass@192.168.1.100:1521/orcl \
--target kingbase://system:kingbase@192.168.1.200:54321/mydb \
--tables "SCHEMA1.*" \
--parallel 8 \
--batch-size 10000
# 4. 数据一致性校验
kdts verify --source oracle://user:pass@192.168.1.100:1521/orcl \
--target kingbase://system:kingbase@192.168.1.200:54321/mydb \
--tables "SCHEMA1.*" \
--output /tmp/verify_report.html
# 5. 使用KFS进行增量同步(双轨运行期间)
kfs sync --source oracle://user:pass@192.168.1.100:1521/orcl \
--target kingbase://system:kingbase@192.168.1.200:54321/mydb \
--mode cdc \
--start-scn 12345678金仓原厂团队凭借每年服务近2000个系统上线的丰富经验,确保了这一过程的平稳可靠。
不止于关系:多模融合架构解锁全场景价值
兼容是通往未来的桥梁,融合创新才是引领未来的引擎。金仓数据库的核心突破在于打破了关系模型与其它数据模型之间的壁垒,实现了"时序+X"、"文档+X"、"向量+X"等多模数据的统一存储、管理与联合查询。
1. 时序+多模:驾驭PB级数据的实时洞察
针对时序数据"写多读少、按时间有序、海量爆发"的特性,金仓时序引擎并非简单复用关系模型,而是进行了深度优化:
创建时序表与数据写入:
sql
-- 启用时序扩展
CREATE EXTENSION IF NOT EXISTS kdb_timeseries;
-- 创建设备监控时序表(自动按时间分区)
CREATE TABLE device_metrics (
device_id VARCHAR(50) NOT NULL,
metric_time TIMESTAMPTZ NOT NULL,
temperature FLOAT,
humidity FLOAT,
pressure FLOAT,
voltage FLOAT,
current FLOAT,
status INT
) USING timeseries
PARTITION BY RANGE (metric_time)
WITH (
compress_interval = '7 days', -- 7天后自动压缩
retention_period = '365 days', -- 数据保留1年
chunk_interval = '1 day' -- 按天分片
);
-- 创建时间+设备复合索引
CREATE INDEX idx_device_metrics_time_device
ON device_metrics (metric_time DESC, device_id);
-- 批量写入时序数据(高性能写入)
INSERT INTO device_metrics (device_id, metric_time, temperature, humidity, pressure, voltage, current, status)
VALUES
('DEV-001', '2026-01-27 10:00:00+08', 25.6, 65.2, 101.3, 220.5, 1.2, 1),
('DEV-001', '2026-01-27 10:00:01+08', 25.7, 65.1, 101.3, 220.4, 1.3, 1),
('DEV-002', '2026-01-27 10:00:00+08', 28.3, 58.7, 101.2, 380.2, 5.6, 1);时序聚合与窗口函数:
sql
-- 按5分钟窗口聚合设备温度数据
SELECT
device_id,
time_bucket('5 minutes', metric_time) AS bucket,
AVG(temperature) AS avg_temp,
MAX(temperature) AS max_temp,
MIN(temperature) AS min_temp,
COUNT(*) AS sample_count
FROM device_metrics
WHERE metric_time >= NOW() - INTERVAL '1 hour'
GROUP BY device_id, bucket
ORDER BY device_id, bucket;
-- 计算温度的移动平均值(滑动窗口)
SELECT
device_id,
metric_time,
temperature,
AVG(temperature) OVER (
PARTITION BY device_id
ORDER BY metric_time
ROWS BETWEEN 9 PRECEDING AND CURRENT ROW
) AS moving_avg_10
FROM device_metrics
WHERE device_id = 'DEV-001'
ORDER BY metric_time DESC
LIMIT 100;
-- 检测温度异常(超过3个标准差)
WITH stats AS (
SELECT
device_id,
AVG(temperature) AS avg_temp,
STDDEV(temperature) AS std_temp
FROM device_metrics
WHERE metric_time >= NOW() - INTERVAL '24 hours'
GROUP BY device_id
)
SELECT
m.device_id,
m.metric_time,
m.temperature,
s.avg_temp,
s.std_temp,
ABS(m.temperature - s.avg_temp) / NULLIF(s.std_temp, 0) AS z_score
FROM device_metrics m
JOIN stats s ON m.device_id = s.device_id
WHERE m.metric_time >= NOW() - INTERVAL '1 hour'
AND ABS(m.temperature - s.avg_temp) > 3 * s.std_temp
ORDER BY m.metric_time DESC;时序+GIS多模融合查询(智慧交通场景):
sql
-- 启用GIS扩展
CREATE EXTENSION IF NOT EXISTS postgis;
-- 创建车辆轨迹表(时序+空间融合)
CREATE TABLE vehicle_tracks (
vehicle_id VARCHAR(20) NOT NULL,
track_time TIMESTAMPTZ NOT NULL,
location GEOMETRY(POINT, 4326), -- WGS84坐标
speed FLOAT,
direction INT,
status VARCHAR(10)
) USING timeseries
PARTITION BY RANGE (track_time);
-- 创建空间索引
CREATE INDEX idx_vehicle_tracks_location ON vehicle_tracks USING GIST (location);
-- 【核心场景】一条SQL查询:近7天在机场5公里内停留超30分钟的车辆
WITH airport_location AS (
-- 首都机场坐标
SELECT ST_SetSRID(ST_MakePoint(116.5871, 40.0799), 4326) AS geom
),
vehicle_stays AS (
SELECT
v.vehicle_id,
MIN(v.track_time) AS enter_time,
MAX(v.track_time) AS leave_time,
EXTRACT(EPOCH FROM (MAX(v.track_time) - MIN(v.track_time))) / 60 AS stay_minutes,
COUNT(*) AS track_points
FROM vehicle_tracks v, airport_location a
WHERE v.track_time >= NOW() - INTERVAL '7 days'
AND ST_DWithin(
v.location::geography,
a.geom::geography,
5000 -- 5公里范围
)
AND v.speed < 5 -- 低速或停止状态
GROUP BY v.vehicle_id
HAVING EXTRACT(EPOCH FROM (MAX(v.track_time) - MIN(v.track_time))) / 60 > 30
)
SELECT
vs.vehicle_id,
vs.enter_time,
vs.leave_time,
ROUND(vs.stay_minutes::numeric, 2) AS stay_minutes,
vs.track_points,
vi.owner_name,
vi.plate_number
FROM vehicle_stays vs
LEFT JOIN vehicle_info vi ON vs.vehicle_id = vi.vehicle_id
ORDER BY vs.stay_minutes DESC;- 超高压缩与智能分区:采用专用压缩算法,存储空间可节省高达80%;默认开启"时间+业务"双分区,使十亿级数据表的特定时间范围查询速度提升10倍。
- 原生时序函数与多模融合:内置滚动窗口、时间聚合等数十个时序函数,大幅提升分析效率。更重要的是,它能与GIS、文档、向量模型无缝协同。
2. GIS+关系:赋能空间智能决策
金仓KGIS组件符合OpenGIS标准,提供矢量、栅格、拓扑等丰富的空间数据类型,支持近700个空间函数及GiST等多种空间索引。它已深度适配国产主流GIS平台(如GeoScene、MapGIS等),在自然资源"一张图"、应急灾害监测等项目中成功替换Oracle Spatial,性能相比原系统有数倍提升。
GIS空间数据管理示例:
sql
-- 启用PostGIS扩展
CREATE EXTENSION IF NOT EXISTS postgis;
CREATE EXTENSION IF NOT EXISTS postgis_topology;
-- 创建行政区划表
CREATE TABLE administrative_regions (
region_id SERIAL PRIMARY KEY,
region_code VARCHAR(20) UNIQUE NOT NULL,
region_name VARCHAR(100) NOT NULL,
region_level INT, -- 1:省 2:市 3:区县 4:乡镇
parent_code VARCHAR(20),
boundary GEOMETRY(MULTIPOLYGON, 4326), -- 边界多边形
center_point GEOMETRY(POINT, 4326), -- 中心点
area_sqkm FLOAT,
population BIGINT,
created_at TIMESTAMPTZ DEFAULT NOW()
);
-- 创建空间索引
CREATE INDEX idx_regions_boundary ON administrative_regions USING GIST (boundary);
CREATE INDEX idx_regions_center ON administrative_regions USING GIST (center_point);
-- 创建兴趣点(POI)表
CREATE TABLE points_of_interest (
poi_id SERIAL PRIMARY KEY,
poi_name VARCHAR(200) NOT NULL,
poi_type VARCHAR(50), -- 医院、学校、商场等
location GEOMETRY(POINT, 4326),
address VARCHAR(500),
contact_phone VARCHAR(20),
business_hours VARCHAR(100),
rating FLOAT,
attributes JSONB -- 扩展属性(文档模型融合)
);
CREATE INDEX idx_poi_location ON points_of_interest USING GIST (location);
CREATE INDEX idx_poi_attributes ON points_of_interest USING GIN (attributes);
-- 插入示例数据
INSERT INTO points_of_interest (poi_name, poi_type, location, address, attributes)
VALUES
('北京协和医院', '三甲医院',
ST_SetSRID(ST_MakePoint(116.4177, 39.9139), 4326),
'北京市东城区帅府园1号',
'{"beds": 2000, "departments": ["内科", "外科", "妇产科"], "emergency": true}'::jsonb),
('清华大学', '高等院校',
ST_SetSRID(ST_MakePoint(116.3267, 39.9999), 4326),
'北京市海淀区清华园1号',
'{"founded": 1911, "type": "985/211", "students": 50000}'::jsonb);空间分析查询示例:
sql
-- 查询某区域内的所有医院
SELECT
p.poi_name,
p.address,
p.attributes->>'beds' AS bed_count,
ST_Distance(
p.location::geography,
ST_SetSRID(ST_MakePoint(116.4074, 39.9042), 4326)::geography
) / 1000 AS distance_km
FROM points_of_interest p
WHERE p.poi_type = '三甲医院'
AND ST_DWithin(
p.location::geography,
ST_SetSRID(ST_MakePoint(116.4074, 39.9042), 4326)::geography,
10000 -- 10公里范围
)
ORDER BY distance_km;
-- 计算两个区域的交集面积
SELECT
a.region_name AS region_a,
b.region_name AS region_b,
ST_Area(ST_Intersection(a.boundary, b.boundary)::geography) / 1000000 AS intersection_sqkm
FROM administrative_regions a, administrative_regions b
WHERE a.region_code = '110101' AND b.region_code = '110102'
AND ST_Intersects(a.boundary, b.boundary);
-- 查找距离最近的5家医院(KNN查询)
SELECT
poi_name,
address,
ST_Distance(
location::geography,
ST_SetSRID(ST_MakePoint(116.4074, 39.9042), 4326)::geography
) AS distance_meters
FROM points_of_interest
WHERE poi_type = '三甲医院'
ORDER BY location <-> ST_SetSRID(ST_MakePoint(116.4074, 39.9042), 4326)
LIMIT 5;
-- 缓冲区分析:查找河流500米范围内的建筑
SELECT
b.building_name,
b.building_type,
ST_Distance(b.location::geography, r.geometry::geography) AS distance_to_river
FROM buildings b, rivers r
WHERE r.river_name = '永定河'
AND ST_DWithin(b.location::geography, r.geometry::geography, 500)
ORDER BY distance_to_river;3. 文档+协议:无缝接替NoSQL生态
针对MongoDB等文档数据库的替代场景,金仓文档模型不仅提供了高效的JSON/BSON数据处理能力,更实现了对MongoDB原生协议的兼容。这意味着,原有基于MongoDB的应用可以做到"0"代码改造,平滑迁移至具备企业级事务一致性(ACID)、高可用和安全审计能力的金仓数据库。
JSON文档存储与查询:
sql
-- 创建文档表(存储用户画像数据)
CREATE TABLE user_profiles (
user_id VARCHAR(50) PRIMARY KEY,
profile JSONB NOT NULL,
created_at TIMESTAMPTZ DEFAULT NOW(),
updated_at TIMESTAMPTZ DEFAULT NOW()
);
-- 创建GIN索引加速JSON查询
CREATE INDEX idx_user_profiles_profile ON user_profiles USING GIN (profile);
CREATE INDEX idx_user_profiles_tags ON user_profiles USING GIN ((profile->'tags'));
-- 插入文档数据
INSERT INTO user_profiles (user_id, profile) VALUES
('U001', '{
"name": "张三",
"age": 28,
"gender": "male",
"email": "zhangsan@example.com",
"phone": "13800138001",
"address": {
"province": "北京",
"city": "北京",
"district": "朝阳区",
"street": "建国路88号"
},
"tags": ["VIP", "活跃用户", "高消费"],
"preferences": {
"categories": ["电子产品", "图书", "运动"],
"price_range": {"min": 100, "max": 5000},
"notification": true
},
"purchase_history": [
{"order_id": "ORD001", "amount": 2999, "date": "2026-01-15"},
{"order_id": "ORD002", "amount": 599, "date": "2026-01-20"}
]
}'::jsonb),
('U002', '{
"name": "李四",
"age": 35,
"gender": "female",
"email": "lisi@example.com",
"tags": ["普通用户"],
"preferences": {
"categories": ["服装", "美妆"],
"notification": false
}
}'::jsonb);
-- 查询VIP用户
SELECT user_id, profile->>'name' AS name, profile->>'email' AS email
FROM user_profiles
WHERE profile->'tags' ? 'VIP';
-- 查询北京朝阳区的用户
SELECT user_id, profile->>'name' AS name
FROM user_profiles
WHERE profile->'address'->>'province' = '北京'
AND profile->'address'->>'district' = '朝阳区';
-- 查询消费金额超过2000的订单
SELECT
user_id,
profile->>'name' AS name,
order_item->>'order_id' AS order_id,
(order_item->>'amount')::numeric AS amount
FROM user_profiles,
jsonb_array_elements(profile->'purchase_history') AS order_item
WHERE (order_item->>'amount')::numeric > 2000;
-- 更新嵌套字段
UPDATE user_profiles
SET profile = jsonb_set(
profile,
'{address,street}',
'"建国路100号"'::jsonb
),
updated_at = NOW()
WHERE user_id = 'U001';
-- 向数组添加元素
UPDATE user_profiles
SET profile = jsonb_set(
profile,
'{tags}',
(profile->'tags') || '["新标签"]'::jsonb
)
WHERE user_id = 'U002';MongoDB协议兼容(Python应用示例):
python
from pymongo import MongoClient
# 原MongoDB连接
# client = MongoClient('mongodb://192.168.1.100:27017/')
# 迁移到KES,仅需修改连接地址,代码完全不变
client = MongoClient('mongodb://192.168.1.200:27018/')
db = client['ecommerce']
collection = db['products']
# 插入文档
product = {
"sku": "PROD-001",
"name": "智能手表",
"price": 1299.00,
"category": "电子产品",
"specs": {
"screen": "1.4英寸AMOLED",
"battery": "300mAh",
"waterproof": "IP68"
},
"tags": ["智能穿戴", "健康监测", "运动"]
}
result = collection.insert_one(product)
print(f"插入文档ID: {result.inserted_id}")
# 查询文档
products = collection.find({
"category": "电子产品",
"price": {"$lt": 2000}
}).sort("price", -1).limit(10)
for p in products:
print(f"{p['name']}: ¥{p['price']}")
# 聚合查询
pipeline = [
{"$match": {"category": "电子产品"}},
{"$group": {
"_id": "$category",
"avg_price": {"$avg": "$price"},
"count": {"$sum": 1}
}}
]
results = collection.aggregate(pipeline)4. 向量+AI:构筑大模型应用的全栈底座
面向AI浪潮,金仓向量数据库组件支持高维度向量的高效存储与检索,提供对IVFFlat、HNSW等主流索引和多种距离计算方法的支持。其独特优势在于向量与标量数据的原生混合查询,能够将非结构化数据的语义搜索与结构化数据的精确筛选完美结合,为RAG、智能推荐、预测性维护等AI应用提供了性能、安全和成本更优的一站式数据支撑。
向量数据库配置与使用:
sql
-- 启用向量扩展
CREATE EXTENSION IF NOT EXISTS vector;
-- 创建商品向量表(用于智能推荐)
CREATE TABLE product_embeddings (
product_id VARCHAR(50) PRIMARY KEY,
product_name VARCHAR(200) NOT NULL,
category VARCHAR(50),
price DECIMAL(10,2),
description TEXT,
embedding VECTOR(768), -- 768维向量(如BERT模型输出)
image_embedding VECTOR(512), -- 图像特征向量
created_at TIMESTAMPTZ DEFAULT NOW()
);
-- 创建HNSW索引(高性能近似最近邻搜索)
CREATE INDEX idx_product_embedding_hnsw
ON product_embeddings
USING hnsw (embedding vector_cosine_ops)
WITH (m = 16, ef_construction = 64);
-- 创建IVFFlat索引(适合大规模数据)
CREATE INDEX idx_product_image_ivfflat
ON product_embeddings
USING ivfflat (image_embedding vector_l2_ops)
WITH (lists = 100);
-- 插入向量数据(实际应用中向量由AI模型生成)
INSERT INTO product_embeddings (product_id, product_name, category, price, description, embedding)
VALUES
('P001', '无线蓝牙耳机', '电子产品', 299.00, '高品质音效,长续航',
'[0.1, 0.2, 0.3, ...]'::vector), -- 768维向量
('P002', '智能手环', '电子产品', 199.00, '健康监测,运动追踪',
'[0.15, 0.25, 0.35, ...]'::vector);向量相似度搜索:
sql
-- 基于文本语义的相似商品搜索(余弦相似度)
SELECT
product_id,
product_name,
category,
price,
1 - (embedding <=> '[0.12, 0.22, 0.32, ...]'::vector) AS similarity
FROM product_embeddings
ORDER BY embedding <=> '[0.12, 0.22, 0.32, ...]'::vector
LIMIT 10;
-- 基于图像的相似商品搜索(欧氏距离)
SELECT
product_id,
product_name,
image_embedding <-> '[0.5, 0.6, 0.7, ...]'::vector AS distance
FROM product_embeddings
WHERE image_embedding IS NOT NULL
ORDER BY image_embedding <-> '[0.5, 0.6, 0.7, ...]'::vector
LIMIT 5;
-- 【核心场景】向量+标量混合查询(RAG应用)
-- 在特定类别和价格范围内进行语义搜索
SELECT
product_id,
product_name,
category,
price,
description,
1 - (embedding <=> $1) AS relevance_score
FROM product_embeddings
WHERE category = '电子产品'
AND price BETWEEN 100 AND 500
ORDER BY embedding <=> $1
LIMIT 5;Python RAG应用集成示例:
python
import psycopg2
from sentence_transformers import SentenceTransformer
# 加载向量化模型
model = SentenceTransformer('paraphrase-multilingual-MiniLM-L12-v2')
# 连接金仓数据库
conn = psycopg2.connect(
host="192.168.1.200",
port=54321,
database="ai_app",
user="system",
password="kingbase"
)
def semantic_search(query_text, category=None, top_k=5):
"""语义搜索:结合向量相似度和业务条件"""
# 生成查询向量
query_embedding = model.encode(query_text).tolist()
cursor = conn.cursor()
if category:
sql = """
SELECT product_id, product_name, category, price, description,
1 - (embedding <=> %s::vector) AS score
FROM product_embeddings
WHERE category = %s
ORDER BY embedding <=> %s::vector
LIMIT %s
"""
cursor.execute(sql, (query_embedding, category, query_embedding, top_k))
else:
sql = """
SELECT product_id, product_name, category, price, description,
1 - (embedding <=> %s::vector) AS score
FROM product_embeddings
ORDER BY embedding <=> %s::vector
LIMIT %s
"""
cursor.execute(sql, (query_embedding, query_embedding, top_k))
results = cursor.fetchall()
cursor.close()
return results
# 使用示例
results = semantic_search("适合运动时使用的耳机", category="电子产品", top_k=5)
for r in results:
print(f"[{r[5]:.3f}] {r[1]} - ¥{r[3]}")一库全替代:融合架构带来的根本性优势
金仓数据库的"多模融合、一库全替代"模式,为企业带来的价值是系统性的:
技术栈收敛,成本降低
无需采购、部署、维护多套异构数据库,极大简化了架构复杂度,降低了软硬件采购、授权、运维及人员学习成本,总体拥有成本(TCO)显著优化。
传统方案 vs 金仓融合方案对比:
| 场景 | 传统方案 | 金仓融合方案 |
|---|---|---|
| 关系数据 | Oracle/MySQL | KingbaseES |
| 时序数据 | InfluxDB/TimescaleDB | KingbaseES时序引擎 |
| 空间数据 | Oracle Spatial/PostGIS | KingbaseES KGIS |
| 文档数据 | MongoDB | KingbaseES文档模型 |
| 向量数据 | Milvus/Pinecone | KingbaseES向量引擎 |
| 数据库数量 | 5套 | 1套 |
| 运维复杂度 | 高 | 低 |
| 数据孤岛 | 存在 | 消除 |
数据孤岛打破,价值深入释放
关系数据、时序轨迹、空间位置、文档资料、向量特征得以在同一平台内一体化存储与处理,支持复杂的跨模型关联分析,让数据资产产生"1+1>2"的协同价值。
跨模型联合查询示例(智慧城市场景):
sql
-- 综合查询:结合时序、空间、文档、向量多模数据
-- 场景:查找过去24小时内,在商业区停留且消费行为与"高端消费"语义相似的用户
WITH
-- 1. 时序数据:获取用户位置轨迹
user_locations AS (
SELECT
user_id,
track_time,
location,
stay_duration
FROM user_location_tracks
WHERE track_time >= NOW() - INTERVAL '24 hours'
AND stay_duration > INTERVAL '30 minutes'
),
-- 2. 空间数据:筛选在商业区内的用户
users_in_commercial AS (
SELECT DISTINCT ul.user_id
FROM user_locations ul
JOIN commercial_zones cz ON ST_Within(ul.location, cz.boundary)
WHERE cz.zone_type = '核心商圈'
),
-- 3. 向量数据:语义相似度匹配
high_value_users AS (
SELECT
up.user_id,
1 - (up.behavior_embedding <=>
(SELECT embedding FROM behavior_templates WHERE name = '高端消费')
) AS similarity
FROM user_profiles up
WHERE up.user_id IN (SELECT user_id FROM users_in_commercial)
AND 1 - (up.behavior_embedding <=>
(SELECT embedding FROM behavior_templates WHERE name = '高端消费')
) > 0.8
)
-- 4. 文档数据:获取用户详细画像
SELECT
hvu.user_id,
hvu.similarity AS behavior_match_score,
up.profile->>'name' AS user_name,
up.profile->'preferences' AS preferences,
up.profile->'purchase_history' AS recent_purchases
FROM high_value_users hvu
JOIN user_profiles up ON hvu.user_id = up.user_id
ORDER BY hvu.similarity DESC
LIMIT 100;企业级能力无缝继承
无论处理何种模型的数据,都能天然享有金仓数据库在以下方面的成熟企业级特性:
高可用配置示例(主备集群):
sql
-- 查看集群状态
SELECT * FROM sys_stat_replication;
-- 配置同步复制(RPO=0)
ALTER SYSTEM SET synchronous_standby_names = 'standby1, standby2';
ALTER SYSTEM SET synchronous_commit = 'remote_apply';
SELECT sys_reload_conf();
-- 查看复制延迟
SELECT
client_addr,
state,
sent_lsn,
write_lsn,
flush_lsn,
replay_lsn,
pg_wal_lsn_diff(sent_lsn, replay_lsn) AS replay_lag_bytes
FROM sys_stat_replication;安全审计配置:
sql
-- 启用审计功能
ALTER SYSTEM SET audit_enabled = ON;
ALTER SYSTEM SET audit_log_destination = 'file';
-- 配置审计策略
CREATE AUDIT POLICY sensitive_data_access
ACTIONS SELECT, UPDATE, DELETE
ON TABLE customers, orders, payments
WHEN (current_user != 'admin');
-- 查看审计日志
SELECT
audit_time,
user_name,
client_ip,
operation,
object_name,
sql_text
FROM sys_audit_log
WHERE audit_time >= NOW() - INTERVAL '1 day'
ORDER BY audit_time DESC;平滑演进,面向未来
从传统核心系统(Oracle/DB2)替代,到新型互联网应用(MySQL)、再到物联网(时序)、GIS应用和AI创新场景,一个金仓数据库底座即可支撑企业从当前到未来的全业务演进需求。
实践证明:全行业、全场景的成功落地
金仓数据库的这一理念已在全国范围内得到广泛验证。
金融行业案例
新疆农信经营分析系统Oracle RAC替代:
sql
-- 金融报表查询优化示例
-- 原Oracle语法在KES中直接运行
SELECT /*+ PARALLEL(t, 4) */
branch_code,
TO_CHAR(trans_date, 'YYYY-MM') AS month,
SUM(DECODE(trans_type, 'DEPOSIT', amount, 0)) AS total_deposit,
SUM(DECODE(trans_type, 'WITHDRAW', amount, 0)) AS total_withdraw,
COUNT(DISTINCT customer_id) AS active_customers
FROM transactions t
WHERE trans_date >= ADD_MONTHS(TRUNC(SYSDATE, 'YEAR'), 0)
GROUP BY branch_code, TO_CHAR(trans_date, 'YYYY-MM')
ORDER BY branch_code, month;
-- 分区表管理(按月分区)
CREATE TABLE loan_records (
loan_id VARCHAR(50) NOT NULL,
customer_id VARCHAR(50) NOT NULL,
loan_amount DECIMAL(18,2),
interest_rate DECIMAL(5,4),
loan_date DATE NOT NULL,
due_date DATE,
status VARCHAR(20)
) PARTITION BY RANGE (loan_date);
-- 自动创建分区
CREATE TABLE loan_records_2026_01 PARTITION OF loan_records
FOR VALUES FROM ('2026-01-01') TO ('2026-02-01');
CREATE TABLE loan_records_2026_02 PARTITION OF loan_records
FOR VALUES FROM ('2026-02-01') TO ('2026-03-01');能源电力案例
龙源电力新能源场站监控系统:
sql
-- 风电场实时监控数据存储
CREATE TABLE wind_turbine_metrics (
turbine_id VARCHAR(30) NOT NULL,
collect_time TIMESTAMPTZ NOT NULL,
wind_speed FLOAT, -- 风速 m/s
rotor_speed FLOAT, -- 转子转速 rpm
power_output FLOAT, -- 发电功率 kW
nacelle_direction INT, -- 机舱方向 度
pitch_angle FLOAT, -- 桨距角 度
generator_temp FLOAT, -- 发电机温度 ℃
gearbox_temp FLOAT, -- 齿轮箱温度 ℃
vibration_x FLOAT, -- X轴振动
vibration_y FLOAT, -- Y轴振动
alarm_code INT
) USING timeseries
PARTITION BY RANGE (collect_time)
WITH (chunk_interval = '1 hour', compress_interval = '1 day');
-- 实时功率曲线分析
SELECT
turbine_id,
time_bucket('10 minutes', collect_time) AS time_slot,
AVG(wind_speed) AS avg_wind_speed,
AVG(power_output) AS avg_power,
MAX(power_output) AS max_power,
-- 计算理论功率与实际功率偏差
AVG(power_output) / NULLIF(AVG(theoretical_power(wind_speed)), 0) * 100 AS efficiency_pct
FROM wind_turbine_metrics
WHERE collect_time >= NOW() - INTERVAL '24 hours'
GROUP BY turbine_id, time_slot
ORDER BY turbine_id, time_slot;
-- 异常检测:振动超标预警
SELECT
turbine_id,
collect_time,
vibration_x,
vibration_y,
SQRT(vibration_x^2 + vibration_y^2) AS total_vibration
FROM wind_turbine_metrics
WHERE collect_time >= NOW() - INTERVAL '1 hour'
AND SQRT(vibration_x^2 + vibration_y^2) > 5.0 -- 振动阈值
ORDER BY collect_time DESC;智慧政务案例
自然资源"一张图"系统:
sql
-- 土地利用现状数据管理
CREATE TABLE land_parcels (
parcel_id VARCHAR(30) PRIMARY KEY,
land_type VARCHAR(50), -- 耕地、林地、建设用地等
land_grade INT, -- 土地等级
area_sqm FLOAT, -- 面积(平方米)
boundary GEOMETRY(POLYGON, 4490), -- CGCS2000坐标系
owner_info JSONB, -- 权属信息(文档)
survey_time DATE,
data_source VARCHAR(50)
);
-- 空间索引
CREATE INDEX idx_land_parcels_boundary ON land_parcels USING GIST (boundary);
-- 耕地保护红线分析
SELECT
lp.parcel_id,
lp.land_type,
lp.area_sqm / 10000 AS area_hectare,
lp.owner_info->>'owner_name' AS owner,
ST_Area(ST_Intersection(lp.boundary, rl.boundary)) / ST_Area(lp.boundary) * 100 AS overlap_pct
FROM land_parcels lp
JOIN redline_zones rl ON ST_Intersects(lp.boundary, rl.boundary)
WHERE rl.zone_type = '永久基本农田'
AND lp.land_type != '耕地'
ORDER BY overlap_pct DESC;
-- 建设用地审批空间分析
CREATE OR REPLACE FUNCTION check_land_approval(
p_project_boundary GEOMETRY,
p_project_type VARCHAR
) RETURNS TABLE (
check_item VARCHAR,
check_result BOOLEAN,
detail TEXT
) AS $$
BEGIN
-- 检查是否占用基本农田
RETURN QUERY
SELECT
'基本农田检查'::VARCHAR,
NOT EXISTS(
SELECT 1 FROM redline_zones rz
WHERE rz.zone_type = '永久基本农田'
AND ST_Intersects(p_project_boundary, rz.boundary)
),
COALESCE(
(SELECT '占用面积:' || ROUND(ST_Area(ST_Intersection(p_project_boundary, rz.boundary))::numeric, 2) || '平方米'
FROM redline_zones rz
WHERE rz.zone_type = '永久基本农田'
AND ST_Intersects(p_project_boundary, rz.boundary)
LIMIT 1),
'未占用基本农田'
);
-- 检查是否在生态保护区内
RETURN QUERY
SELECT
'生态保护区检查'::VARCHAR,
NOT EXISTS(
SELECT 1 FROM ecological_zones ez
WHERE ST_Intersects(p_project_boundary, ez.boundary)
),
COALESCE(
(SELECT '涉及保护区:' || ez.zone_name
FROM ecological_zones ez
WHERE ST_Intersects(p_project_boundary, ez.boundary)
LIMIT 1),
'未涉及生态保护区'
);
END;
$$ LANGUAGE plpgsql;医疗行业案例
医院信息系统数据整合:
sql
-- 患者360度视图(多模数据融合)
CREATE TABLE patient_records (
patient_id VARCHAR(30) PRIMARY KEY,
basic_info JSONB, -- 基本信息(文档)
medical_history JSONB, -- 病史(文档)
lab_results JSONB, -- 检验结果(文档)
imaging_features VECTOR(512), -- 影像特征向量
last_visit_time TIMESTAMPTZ,
risk_score FLOAT
);
-- 相似病例检索(辅助诊断)
SELECT
p.patient_id,
p.basic_info->>'name' AS patient_name,
p.medical_history->>'diagnosis' AS diagnosis,
1 - (p.imaging_features <=> $1) AS similarity
FROM patient_records p
WHERE p.imaging_features IS NOT NULL
ORDER BY p.imaging_features <=> $1
LIMIT 10;总结
金仓数据库以"多模融合"为核,以"全替代"为纲,不仅解决了企业过去系统迁移的"不愿用、不会用、不敢用"的难题,更以一体化的数据能力平台,为企业应对当下多样化的数据挑战、布局未来的智能创新,提供了更可靠、更高效、更经济的数据底座选择。
在数据驱动一切的时代,金仓数据库正成为企业整合数据资产、释放数据价值、赢得竞争优势的关键战略伙伴。平替用金仓,一库全替代------这不仅是一句口号,更是经过千行百业验证的最佳实践。
延伸阅读:
感谢
感谢你读到这里,说明你已经成功地忍受了我的文字考验!🎉
希望这篇文章没有让你想砸电脑,也没有让你打瞌睡。
如果有一点点收获,那我就心满意足了。
未来的路还长,愿你
遇见难题不慌张,遇见bug不抓狂,遇见好内容常回访。
记得给自己多一点耐心,多一点幽默感,毕竟生活已经够严肃了。
如果你有想法、吐槽或者想一起讨论的,欢迎留言,咱们一起玩转技术,笑对人生!😄
祝你代码无bug,生活多彩,心情常青!🚀
