在 Java 应用的性能优化中,JVM 执行引擎是核心环节。理解 JVM 如何执行代码、如何识别热点代码、如何进行编译优化,对于构建高性能 Java 应用至关重要。本文将深入剖析 JVM 执行引擎的原理与优化技术,助您掌握这一核心技能。
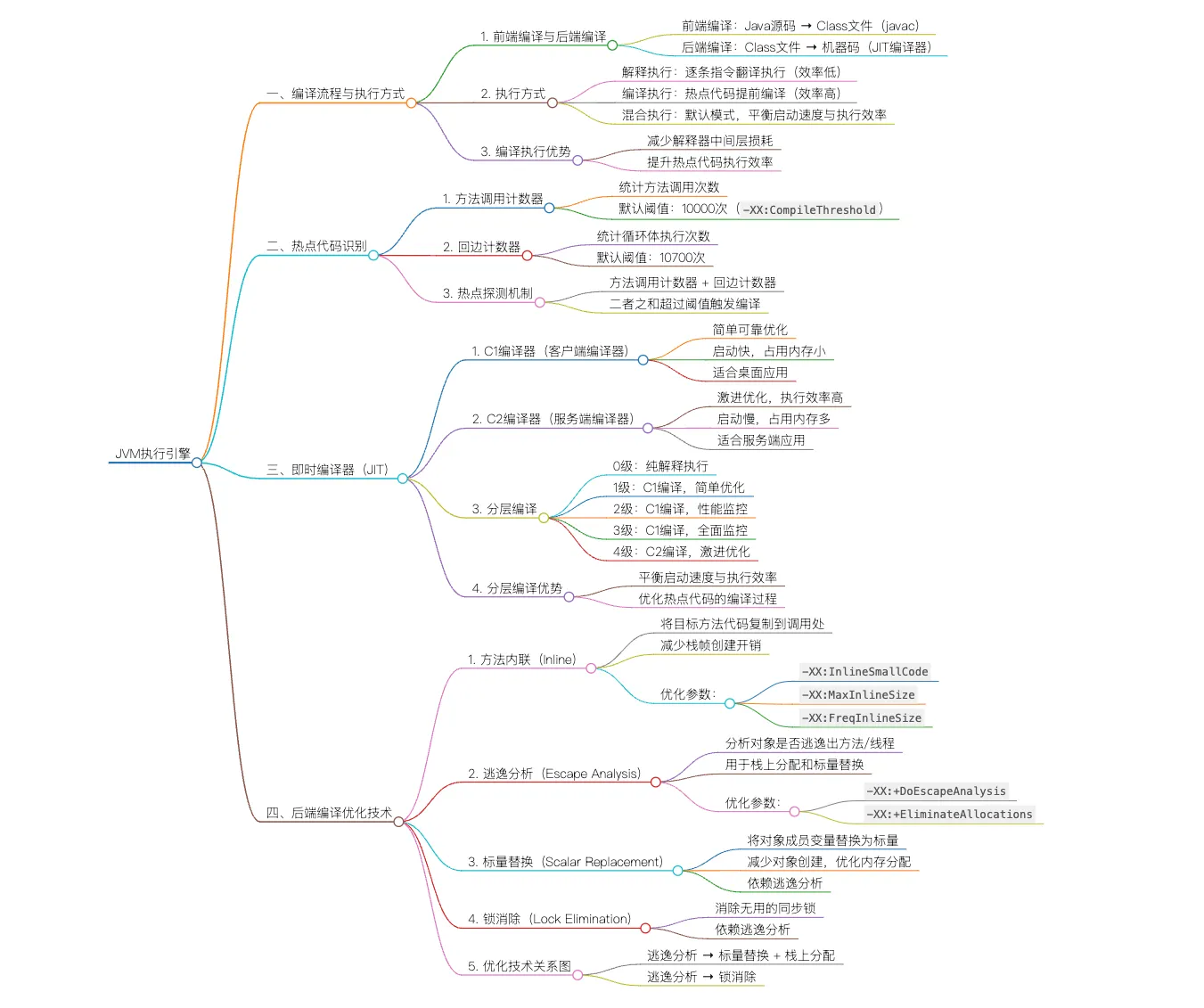
一、编译流程与执行方式
1. 前端编译与后端编译
- 前端编译 :Java 源码 → Class 文件(由 javac 完成)
- 与 JVM 无直接关系
- 任何能生成符合 JVM 规范的 Class 文件的语言都可以在 JVM 上运行
- 后端编译 :Class 文件 → 机器码(由 JIT 编译器完成)
- JVM 执行引擎的核心工作
- 将字节码指令翻译为操作系统识别的机器指令
2. 执行方式对比
| 执行方式 | 工作原理 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 解释执行 | 逐条指令翻译执行 | 启动快,内存占用小 | 执行效率低 | 资源紧张的场景 |
| 编译执行 | 热点代码提前编译 | 执行效率高 | 启动慢,内存占用大 | 服务端应用 |
| 混合执行 | 结合两者 | 平衡启动速度与执行效率 | 无 | HotSpot 默认模式 |
为什么 JVM 不直接采用编译执行:
- 资源紧张场景(如客户端应用、嵌入式系统)需要节省内存
- 编译执行需要预热过程,初期性能可能更低
- 编译执行需要解释执行提供性能监控数据
二、热点代码识别机制
JVM 识别热点代码的核心是"热点探测",HotSpot 采用基于计数器的热点探测方法。
1. 方法调用计数器
- 作用:统计方法被调用的次数
- 默认阈值 :10000 次(可通过
XX:CompileThreshold设置) - 工作流程 :
- 调用方法时,计数器 +1
- 判断方法调用计数器与回边计数器之和是否超过阈值
- 超过阈值,触发即时编译
2. 回边计数器
-
作用:统计方法中循环体代码执行的次数
-
默认阈值:10700 次
-
阈值计算公式:
回边计数器阈值 = 方法调用计数器阈值 × (OSR比率 - 解释器监控比率) / 100- 默认:10000 × (140 - 33) = 10700
-
工作流程:
- 遇到回边指令时,回边计数器 +1
- 判断是否超过阈值
- 超过阈值,触发编译
3. 热点探测示意图
方法调用 → 计数器+1 → 判断是否超过阈值
↗
回边指令 → 计数器+1 → 判断是否超过阈值
↘
触发即时编译三、即时编译器(JIT)深度解析
HotSpot 虚拟机内置了两个即时编译器:C1(客户端编译器)和 C2(服务端编译器)。
1. C1 编译器(客户端编译器)
- 特点:简单可靠,启动快,占用内存小
- 优化级别 :0-3 级
- 0 级:纯解释执行
- 1 级:C1 编译,简单优化
- 2 级:C1 编译,性能监控
- 3 级:C1 编译,全面监控
- 适用场景:桌面应用、客户端应用
2. C2 编译器(服务端编译器)
- 特点:激进优化,执行效率高,启动慢
- 优化级别 :4 级
- 4 级:C2 编译,激进优化
- 适用场景:服务端应用、高性能计算
3. 分层编译机制
HotSpot 采用分层编译,平衡启动速度与执行效率:
启动阶段 → 0-1级(解释执行/C1简单优化)
→ 2级(C1全面监控)
→ 3级(C1全面优化)
→ 4级(C2激进优化)JDK 8 分层编译参数:
bash
-XX:TieredStopAtLevel=1 # 只使用C1编译器
-XX:TieredStopAtLevel=5 # 使用C1和C2编译器分层编译优势:
- 早期阶段:快速启动,避免编译等待
- 后期阶段:优化热点代码,提升执行效率
- 动态调整:根据运行时数据,选择最佳编译策略
四、后端编译优化技术实战
1. 方法内联(Inline)
原理:将目标方法的代码复制到调用处,避免真实方法调用
优化效果:
- 减少栈帧创建和销毁开销
- 提高指令缓存命中率
- 为后续优化创造条件
优化参数:
bash
-XX:InlineSmallCode=1000 # 方法字节码大小阈值
-XX:MaxInlineSize=35 # 方法最大字节码大小
-XX:FreqInlineSize=325 # 热点方法内联阈值
-XX:MaxTrivialSize=6 # 简单方法最大字节码大小
-XX:+PrintInlining # 打印内联决策内联示例:
java
// 未内联
public int add(int x, int y) {
return x + y;
}
// 内联后
public int add(int x, int y) {
return x + y; // 代码被复制到调用处
}内联优化效果:
bash
# 100万次调用
# 未内联:200ms
# 内联后:50ms2. 逃逸分析(Escape Analysis)
原理:分析对象动态作用域,判断对象是否逃逸出方法/线程
逃逸类型:
- 不逃逸:对象只在方法内部使用
- 方法逃逸:对象被作为参数传递到其他方法
- 线程逃逸:对象被其他线程访问
优化基础:逃逸分析是后续优化的基础
优化参数:
bash
-XX:+DoEscapeAnalysis # 启用逃逸分析(默认开启)
-XX:+EliminateAllocations # 启用标量替换(默认开启)3. 标量替换(Scalar Replacement)
原理:将对象成员变量替换为标量,避免创建对象
优化效果:
- 减少对象创建
- 减少内存分配
- 优化内存布局
优化示例:
java
// 未优化
public void test() {
MyObject obj = new MyObject(1, 2.0);
obj.method();
}
// 优化后
public void test() {
int a = 1;
double b = 2.0;
// 直接使用标量,无需创建对象
}性能对比:
bash
# 默认开启:2ms
# 关闭逃逸分析:44ms
# 关闭标量替换:44ms4. 锁消除(Lock Elimination)
原理:消除无用的同步锁,依赖逃逸分析
优化示例:
java
// 未优化
public String BufferString(String s1, String s2) {
StringBuffer sb = new StringBuffer();
sb.append(s1);
sb.append(s2);
return sb.toString();
}
// 优化后(JIT消除锁)
public String BufferString(String s1, String s2) {
StringBuilder sb = new StringBuilder();
sb.append(s1);
sb.append(s2);
return sb.toString();
}性能对比:
bash
# 默认开启锁消除:1521ms
# 关闭锁消除:2461ms五、JVM 执行引擎优化实战
1. 优化案例:电商订单系统
问题:订单创建时响应时间高
分析:
- GC 日志显示频繁 Full GC
- 方法调用计数器高,但未触发 C2 编译
解决方案:
bash
# 调整分层编译级别
-XX:TieredStopAtLevel=4
# 优化热点方法
-XX:CompileThreshold=5000
-XX:MaxInlineSize=50效果:
- 订单创建响应时间从 800ms → 200ms
- GC 频率从每 5 分钟 1 次 → 每小时 1 次
2. 优化案例:金融交易系统
问题:交易响应波动大
分析:
- 交易方法未被内联
- 锁竞争频繁
解决方案:
bash
# 启用锁消除
-XX:+EliminateLocks
# 优化内联
-XX:FreqInlineSize=500
-XX:MaxInlineSize=100效果:
- 平均响应时间从 120ms → 45ms
- 响应波动从 50-300ms → 40-60ms
六、JVM 执行引擎优化最佳实践
1. 优化原则
- 优先让热点代码进入 C2 编译:通过调整阈值,让热点代码更快进入 C2 编译
- 合理使用内联:避免过度内联,影响代码大小
- 利用逃逸分析:减少对象创建,优化内存分配
2. 优化步骤
- 监控 :使用
XX:+PrintCompilation监控编译过程 - 分析 :通过
jstat -gcutil分析 GC 情况 - 调整:根据分析结果调整 JVM 参数
- 验证:在测试环境验证优化效果
- 上线:在生产环境实施优化
3. 优化参数推荐
bash
# 基础优化
-XX:+UseG1GC
-XX:MaxGCPauseMillis=200
# 执行引擎优化
-XX:TieredStopAtLevel=4
-XX:CompileThreshold=5000
-XX:FreqInlineSize=500
-XX:MaxInlineSize=100
-XX:+DoEscapeAnalysis
-XX:+EliminateAllocations
-XX:+PrintCompilation七、总结与建议
1. JVM 执行引擎核心原则
- 热点代码是优化重点:识别并优化热点代码
- 分层编译是平衡点:平衡启动速度与执行效率
- 逃逸分析是优化基础:为栈上分配、标量替换提供支持
- 内联是常用优化:减少方法调用开销
2. 重要提醒
- 默认参数已优化:JDK 8+ 的默认参数已考虑了大多数场景
- 不要过度调优:过度调优可能导致问题
- 监控是优化基础:没有监控,优化就是盲人摸象
"JVM 执行引擎不是魔法,而是有规律可循的系统。理解了 JVM 如何执行代码、如何识别热点、如何优化,你就能在性能优化的道路上走得更远。"
实战建议清单
| 问题类型 | 诊断方法 | 解决方案 |
|---|---|---|
| 响应时间高 | 分析 GC 日志,查看编译情况 | 调整分层编译级别,优化热点方法 |
| GC 频繁 | 监控 GC 频率,分析 GC 日志 | 优化对象生命周期,减少对象创建 |
| 方法调用慢 | 分析内联情况 | 调整内联参数,优化热点方法 |
| 锁竞争 | 分析同步方法 | 启用逃逸分析,消除无用锁 |
最后提醒:在实施 JVM 执行引擎优化前,务必在测试环境验证效果。一个错误的 JVM 参数可能导致生产环境严重问题,而正确的优化能带来 10 倍性能提升。
"当你能读懂 JVM 的编译过程、理解热点代码的识别机制、掌握优化技术,你就真正掌握了 Java 应用的性能优化。从源码到执行,这是一条充满智慧的道路。"