针对企业数字化转型中"一事一库"引发的技术栈复杂、数据孤岛、迁移成本高等痛点,金仓数据库(KingbaseES)提出"一体替代"解决方案。该方案基于多模融合内核架构,实现对Oracle、MySQL、SQL Server等主流数据库的平滑替代,同时原生支持关系、时序、GIS、文档、向量等多类数据模型的融合存储与跨模型联合查询。本文从核心技术架构、关键特性实现、迁移技术体系、企业级能力及实践案例等维度,深入剖析金仓数据库的技术原理与产业级价值,为企业构建统一数据基座提供技术参考。
引言
在数字化浪潮驱动下,企业数据类型呈现爆炸式增长态势:核心交易系统依赖Oracle/DB2的强一致性事务能力,互联网业务基于MySQL/PostgreSQL生态快速迭代,IoT场景产生海量时序数据,GIS系统管理复杂空间信息,AI创新则催生向量检索需求。传统"一事一库"的建设模式,导致企业技术栈日趋臃肿,不仅带来高昂的采购、部署与运维成本,更形成难以打破的数据孤岛,制约跨场景数据价值挖掘。
在此背景下,构建一个能够兼容多类数据库生态、承载多模态数据的统一数据基座,成为企业数字化转型的核心诉求。金仓数据库作为新一代融合数据库的引领者,以"一体替代"为核心目标,通过创新的多模融合架构与全链路迁移工具链,实现"一个数据库,全场景替代"的产业级突破,为企业解决数据库迁移"不愿用、不会用、不敢用"的难题。
一、 金仓数据库核心技术架构
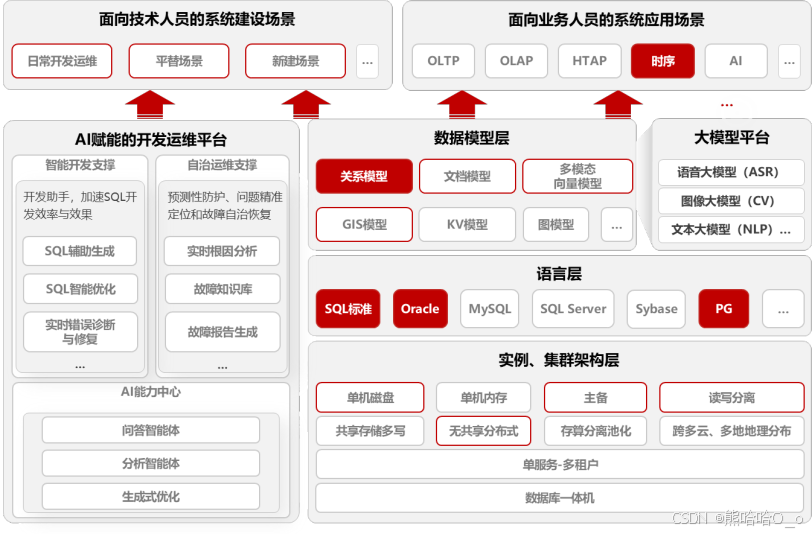
金仓数据库的"一体替代"能力,源于其分层解耦且高度集成的技术架构。该架构自上而下分为AI赋能的开发运维平台 、多模态数据模型层 、多语法兼容语言层 、实例与集群架构层四层,各层协同工作,支撑全场景业务需求。
1.1 多模融合内核分层架构
金仓数据库的内核采用模块化设计,摒弃传统数据库单一模型的局限,实现多类数据模型的原生融合与统一管理,其核心分层如下:
- 数据模型层: 作为架构核心,原生支持关系、时序、GIS、文档、向量、KV、图等多类数据模型,各类模型共享内核的存储、事务、安全等基础能力,支持跨模型联合查询。
- 语言层: 基于独创的"可插拔多语法原生兼容一体化框架",实现SQL标准、Oracle PL/SQL、MySQL语法、SQL Server T-SQL等多套语法体系的兼容,无需修改应用代码即可适配。
- 实例与集群架构层: 支持单机磁盘、单机内存、主备、读写分离、共享存储多写、无共享分布式、存算分离池化等多种部署模式,满足从单机到分布式、从本地到跨多云的部署需求。
1.2 可插拔多语法原生兼容一体化框架
语法兼容是平滑替代的基础,金仓数据库的可插拔多语法框架,通过"语法解析插件化+语义映射标准化"的设计,实现对多类数据库语法的深度兼容:
- 插件化语法解析: 针对不同数据库的语法特性,设计独立的语法解析插件。当需要兼容新的数据库语法时,仅需开发对应的插件,无需修改内核核心代码。
- 标准化语义映射: 将不同数据库的语法语义,统一映射到内核的抽象语法树(AST),确保不同语法书写的SQL,最终执行逻辑一致。
- 语法兼容度量化: 对Oracle PL/SQL、MySQL等主流语法的常用功能,实现近乎100%的兼容,仅对极少数冷门语法函数提供替代方案。
1.3 AI赋能的开发运维支撑体系
为降低开发运维门槛,金仓数据库内置AI能力中心,提供智能开发与自治运维两大核心能力:
- 智能开发支撑: 集成文本大模型(NLP)、语音大模型(ASR)等能力,实现SQL辅助生成、SQL智能优化、开发助手等功能,提升开发效率。
- 自治运维支撑: 基于预测性防护算法,实现问题精准定位、故障自治恢复、实时根因分析等功能,配合故障知识库,降低运维复杂度。
二、 关键特性技术实现与代码示例
金仓数据库的核心优势,在于超越传统关系型数据库的局限,实现多模态数据的原生融合存储与高效查询。以下针对时序、GIS、文档、向量四大核心融合场景,详解技术实现原理并提供代码示例。
2.1 时序+融合:海量时序数据高效处理
针对IoT场景中海量时序数据的存储与查询需求,金仓数据库设计了专用的时序引擎,采用"列式存储+智能分区+高压缩率"的技术方案,区别于传统关系模型的行式存储。
-
核心技术特性
- 高压缩率存储: 针对时序数据的"时间戳+指标值"特性,采用差值编码、字典编码等压缩算法,实现最高80%的压缩率,大幅降低存储成本。
- 时间+业务智能分区: 支持按时间维度(天、小时)和业务维度(设备ID、区域ID)的复合分区,将十亿级数据的查询速度提升10倍。
- 丰富时序函数: 内置时序插值、时序聚合、时序同比/环比等函数,满足时序数据分析需求。
- 跨模型联合查询: 支持时序数据与GIS、关系数据的联合查询,无需跨库ETL。
-
代码示例:智慧交通时空联合查询
需求: 查询过去7天,机场5公里范围内停留超过30分钟的车辆轨迹数据。
sql-- 创建时序表存储车辆轨迹数据 CREATE TABLE vehicle_track ( vehicle_id VARCHAR(32) NOT NULL, track_time TIMESTAMP NOT NULL, lon DOUBLE PRECISION NOT NULL, -- 经度 lat DOUBLE PRECISION NOT NULL, -- 纬度 speed INT NOT NULL, -- 时序引擎指定 USING TIMESERIES (track_time) -- 时间+业务复合分区 PARTITION BY RANGE (track_time) SUBPARTITION BY LIST (vehicle_id) ); -- 创建GIS函数索引,提升空间查询效率 CREATE INDEX idx_vehicle_gis ON vehicle_track USING GIST (ST_GeomFromText('POINT('||lon||' '||lat||')', 4326)); -- 时空联合查询:机场5公里范围内停留超30分钟的车辆 WITH airport_area AS ( -- 定义机场中心点(示例经纬度) SELECT ST_GeomFromText('POINT(116.58 40.08)', 4326) AS airport_center ), vehicle_stay AS ( -- 计算车辆在机场5公里内的停留时长 SELECT vehicle_id, MIN(track_time) AS stay_start, MAX(track_time) AS stay_end, EXTRACT(EPOCH FROM (MAX(track_time) - MIN(track_time)))/60 AS stay_minutes FROM vehicle_track, airport_area WHERE track_time >= NOW() - INTERVAL '7 days' -- 空间距离判断:5公里范围内 AND ST_Distance(ST_GeomFromText('POINT('||lon||' '||lat||')', 4326), airport_center) <= 5000 GROUP BY vehicle_id ) SELECT vehicle_id, stay_minutes FROM vehicle_stay WHERE stay_minutes > 30;
2.2 GIS+融合:空间信息智能分析
金仓数据库通过KGIS组件,实现对空间数据的原生支持,符合OpenGIS标准,可无缝替代Oracle Spatial,同时支持与其他数据模型的融合查询。
-
核心技术特性
- 丰富空间函数: 提供近700个空间函数,支持矢量、栅格等多种数据类型的处理。
- 国产GIS平台适配: 深度兼容GeoScene、MapGIS等国产主流GIS平台,保障生态协同。
- 高性能空间索引: 支持GIST、SP-GIST等空间索引类型,提升空间查询效率。
-
代码示例:区域内POI查询
需求: 查询某行政区域内的所有医院POI数据。
sql-- 创建GIS表存储行政区域数据 CREATE TABLE admin_area ( area_id VARCHAR(32) NOT NULL PRIMARY KEY, area_name VARCHAR(64) NOT NULL, geom GEOMETRY NOT NULL -- 存储区域边界的GIS几何数据 ); -- 创建POI表存储医院数据 CREATE TABLE poi_hospital ( poi_id VARCHAR(32) NOT NULL PRIMARY KEY, poi_name VARCHAR(64) NOT NULL, geom GEOMETRY NOT NULL, address VARCHAR(128) ); -- 空间查询:某区域内的所有医院 SELECT p.poi_name, p.address, ST_AsText(p.geom) AS poi_coordinate FROM poi_hospital p JOIN admin_area a ON ST_Contains(a.geom, p.geom) WHERE a.area_name = 'XX区';
2.3 文档+融合:NoSQL生态无缝迁移
针对MongoDB等文档数据库的替代需求,金仓数据库实现了对JSON/BSON数据的高效处理,同时兼容MongoDB原生协议,支持"0"代码改造迁移。
-
核心技术特性
- 协议级兼容: 支持MongoDB的原生协议,应用无需更换驱动,仅修改连接地址即可接入。
- ACID事务支持: 为文档数据提供金融级ACID事务保障,解决传统文档数据库的事务短板。
- JSON索引优化: 支持对JSON字段的精准索引,提升文档查询效率。
-
代码示例:MongoDB协议兼容连接与查询
-
应用端连接示例(Python)
无需修改代码,仅更换连接地址即可从MongoDB迁移至金仓数据库。pythonfrom pymongo import MongoClient # 原MongoDB连接地址 # client = MongoClient('mongodb://localhost:27017/') # 金仓数据库MongoDB协议兼容地址 client = MongoClient('mongodb://kingbase_user:kingbase_pwd@localhost:27018/') # 选择数据库和集合 db = client['test_db'] collection = db['user_info'] # 查询操作(与MongoDB语法完全一致) result = collection.find({"age": {"$gt": 25}}) for doc in result: print(doc) -
SQL方式查询JSON数据
sql-- 创建文档表 CREATE TABLE user_info ( id SERIAL PRIMARY KEY, doc JSONB NOT NULL ); -- 插入JSON数据 INSERT INTO user_info (doc) VALUES ('{"name": "张三", "age": 30, "address": {"city": "北京"}}'), ('{"name": "李四", "age": 24, "address": {"city": "上海"}}'); -- 查询年龄大于25的用户 SELECT doc->>'name' AS name, (doc->>'age')::INT AS age FROM user_info WHERE (doc->>'age')::INT > 25;
-
2.4 向量+融合:AI应用全栈数据底座
面向大模型与AI应用的向量检索需求,金仓数据库内置向量引擎,支持高效向量检索与混合查询(向量+关系标量数据),为RAG、智能推荐等场景提供一站式数据支撑。
-
核心技术特性
- 多向量索引支持: 支持HNSW、IVFFlat等主流向量索引算法,适配不同规模的向量数据检索需求。
- 混合查询能力: 支持向量相似度检索与关系数据条件过滤的联合查询,无需跨库操作。
- 低延迟高吞吐: 优化向量计算的硬件加速能力,降低大模型应用的检索时延。
-
代码示例:RAG场景向量混合查询
需求: 查询与用户提问向量最相似的前5条知识库文档,并过滤出属于"数据库技术"分类的内容。
sql-- 创建向量表存储知识库文档 CREATE TABLE knowledge_base ( doc_id VARCHAR(32) NOT NULL PRIMARY KEY, doc_title VARCHAR(128) NOT NULL, doc_content TEXT NOT NULL, doc_category VARCHAR(64) NOT NULL, -- 向量维度:768(适配BERT类模型) doc_vector VECTOR(768) NOT NULL ); -- 创建向量索引(HNSW算法) CREATE INDEX idx_doc_vector ON knowledge_base USING HNSW (doc_vector) WITH (m = 16, ef_construction = 64); -- 用户提问向量(示例) SELECT '[-0.023, 0.125, ..., 0.089]'::VECTOR(768) AS query_vector; -- 向量混合查询:相似度Top5 + 分类过滤 SELECT doc_id, doc_title, doc_category, -- 计算余弦相似度 1 - (doc_vector <=> query_vector) AS cos_similarity FROM knowledge_base WHERE doc_category = '数据库技术' ORDER BY cos_similarity DESC LIMIT 5;
三、 平滑迁移技术体系
"一体替代"的前提是实现企业历史资产的安全、高效、低成本迁移。金仓数据库构建了"语法兼容+协议兼容+工具链支撑"的全流程迁移体系,保障业务连续性。
3.1 语法与语义级深度兼容
金仓数据库通过"可插拔多语法框架",实现对主流数据库语法的深度兼容:
- Oracle PL/SQL兼容: 支持存储过程、函数、触发器、包等PL/SQL核心特性,兼容Oracle的隐式转换、函数行为等细节。
- MySQL语法兼容: 支持MySQL的自定义函数、存储过程、索引类型等特性,兼容MySQL的SQL_MODE设置。
- SQL Server T-SQL兼容: 支持T-SQL的游标、事务隔离级别、内置函数等特性。
3.2 协议级原生兼容
金仓数据库支持MySQL等数据库的原生协议,应用无需修改驱动代码,仅需修改连接地址即可接入:
- 协议兼容原理: 内核内置协议解析模块,将MySQL的通信协议转换为金仓内核的内部协议。
- 运维生态保留: 支持使用MySQL客户端、Navicat等工具连接金仓数据库,保留原有的开发运维习惯。
3.3 自动化全流程迁移工具链与实践
金仓数据库提供三大核心工具,构建"准在线"迁移方案,将TB级数据的迁移停机窗口压缩至小时级:
- KDMS(结构迁移工具): 自动解析源数据库的表结构、索引、约束等元数据,转换为金仓数据库的DDL语句,并支持差异化调整。
- KDTS(全量数据迁移工具): 支持全量数据的高速迁移,适配多种数据类型的转换,保障数据一致性。
- KFS(异构实时同步工具): 支持源数据库与金仓数据库的实时数据同步,实现双轨运行,保障业务连续性。
迁移流程示例
- 全量结构迁移: 使用KDMS解析Oracle表结构,生成金仓DDL并执行。
- 全量数据迁移: 使用KDTS将Oracle历史数据迁移至金仓。
- 实时数据同步: 部署KFS实现Oracle到金仓的实时数据同步。
- 双轨运行验证: 应用同时连接Oracle和金仓,验证数据一致性。
- 业务切换: 停机窗口内切换应用连接至金仓,完成迁移。
- 一键回退: 若出现异常,可快速切换回Oracle,保障业务无风险。
四、 企业级核心能力保障
金仓数据库的多模融合能力,建立在成熟的企业级能力之上,为全场景业务提供稳定、安全、高性能的支撑。
4.1 高可用架构:RPO=0,RTO秒级
金仓数据库支持多种高可用部署模式,满足不同业务的可用性需求:
- 主备架构: 基于日志同步实现主备切换,RPO=0,RTO秒级。
- 共享存储多写: 支持多节点同时写入,提升系统吞吐能力。
- 两地三中心: 支持跨地域部署,满足金融、政府等行业的灾备需求。
4.2 全栈纵深安全防御
金仓数据库构建了从数据存储到访问控制的全栈安全体系:
- 数据加密: 支持存储加密、传输加密、透明数据加密(TDE)。
- 访问控制: 支持基于角色的访问控制(RBAC)、行级安全、列级安全。
- 审计日志: 支持全量操作审计,满足等保2.0等合规要求。
4.3 全引擎高性能优化
金仓数据库通过多维度优化,提升全场景数据处理性能:
- 存储引擎优化: 支持行式、列式、混合存储,适配不同查询场景。
- 查询优化器: 基于代价的优化器(CBO)支持复杂查询的执行计划优化。
- 并行计算: 支持查询并行、事务并行,提升大规模数据处理效率。
4.4 智能自治运维管理
金仓数据库的AI赋能运维平台,实现运维的自动化与智能化:
- 预测性防护: 基于机器学习算法,预测潜在故障风险。
- 故障自治恢复: 支持自动识别故障类型并执行恢复操作。
- 性能智能调优: 基于运行时数据,自动优化索引、参数等配置。
五、 全行业落地实践案例
金仓数据库的"一体替代"能力已在金融、能源、政府、交通、医疗等关键行业得到广泛验证,以下为典型案例:
- 金融行业: 新疆农信经营分析系统、嘉实基金TA系统、湘财证券交易结算系统,实现Oracle RAC替代与两地三中心建设,保障核心交易系统的高可用与高性能。
- 政府行业: 北京公积金、佛山人社、多地自然资源"一张图"项目,实现Oracle及GIS平台替代,支撑空间数据与业务数据的融合分析。
- 能源行业: 龙源电力新能源监控、大唐集团电力交易系统,基于时序引擎实现海量IoT数据的高效处理,提升能源调度效率。
- 政务行业: 福建电子证照系统,实现MongoDB平滑迁移,为电子证照数据提供ACID事务保障与高安全特性。
六、 总结与展望
金仓数据库以"多模融合"为核心理念,以"一体替代"为终极目标,为企业构建了统一、高效、安全的企业级数据基座。该方案不仅解决了传统"一事一库"模式的痛点,更支撑企业从传统核心系统到新型互联网应用、再到智能创新场景的全业务生命周期演进。
未来,金仓数据库将持续深化云原生架构,扩展多模数据能力,强化AI与数据库的融合,为企业数字化转型提供更强大的技术支撑。在数据定义未来的时代,金仓数据库将成为企业构建战略数据操作系统的核心选择。