1. 目标检测系列:珠宝饰品识别与分类_YOLOv26实现
1.1. 引言 🚀
在时尚产业和珠宝零售领域,自动识别和分类珠宝饰品变得越来越重要。💍 随着深度学习技术的发展,特别是目标检测算法的进步,我们现在能够构建高效、准确的珠宝识别系统。今天,我将向大家介绍如何使用最新的YOLOv26算法实现珠宝饰品的识别与分类。
如图所示,这是一个珠宝饰品识别系统的模型训练界面。🎯 在这个界面中,我们可以配置任务类型(目标检测)、选择基础模型(YOLOv26)和改进创新点,然后通过选择珠宝数据集来训练我们的模型。训练过程中,系统会实时显示训练进度和日志信息,帮助我们监控模型的训练状态。
1.2. YOLOv26核心架构与创新点 🧠
YOLOv26是目标检测领域的最新突破,它带来了许多令人兴奋的创新。😍 让我们先了解一下它的核心架构:
1. 端到端无NMS推理 🔄
YOLOv26最大的特点是实现了原生端到端的检测流程,消除了传统的非极大值抑制(NMS)后处理步骤。这意味着:
Output = YOLOv26 ( Input ) \text{Output} = \text{YOLOv26}(\text{Input}) Output=YOLOv26(Input)
这个简单的公式背后是巨大的技术突破!🤯 传统的YOLO模型需要先生成大量候选框,然后通过NMS来过滤重叠的检测结果,而YOLOv26直接生成最终的检测结果,大大简化了推理流程。
这种设计带来了几个显著优势:
- 推理速度提升43% 🚀,特别是在CPU上表现更加出色
- 减少了延迟,使实时应用更加流畅
- 简化了部署流程,不需要额外的后处理代码
2. MuSGD优化器 🔧
YOLOv26引入了一种新型的混合优化器------MuSGD,它结合了SGD和Muon的优点。🧪 这个优化器的灵感来源于Moonshot AI在Kimi K2模型训练中的突破。
MuSGD的工作原理可以表示为:
θ t + 1 = θ t − η ⋅ ( α ⋅ ∇ L ( θ t ) + β ⋅ MuonUpdate ( θ t ) ) \theta_{t+1} = \theta_t - \eta \cdot (\alpha \cdot \nabla L(\theta_t) + \beta \cdot \text{MuonUpdate}(\theta_t)) θt+1=θt−η⋅(α⋅∇L(θt)+β⋅MuonUpdate(θt))
其中, α \alpha α和 β \beta β是混合比例, ∇ L ( θ t ) \nabla L(\theta_t) ∇L(θt)是传统梯度, MuonUpdate ( θ t ) \text{MuonUpdate}(\theta_t) MuonUpdate(θt)是Muon更新项。

这种优化器带来了:
- 更稳定的训练过程,减少了训练中的震荡
- 更快的收敛速度,通常能提前10-20%达到最佳性能
- 更好的泛化能力,减少了过拟合的风险
3. ProgLoss + STAL损失函数 📊
为了提高小目标检测的精度,YOLOv26引入了改进的损失函数组合:
L t o t a l = L p r o g + λ ⋅ L S T A L \mathcal{L}{total} = \mathcal{L}{prog} + \lambda \cdot \mathcal{L}_{STAL} Ltotal=Lprog+λ⋅LSTAL
其中, L p r o g \mathcal{L}{prog} Lprog是渐进式损失函数, L S T A L \mathcal{L}{STAL} LSTAL是空间感知标签分配损失, λ \lambda λ是平衡系数。
这种损失函数设计特别适合珠宝饰品识别,因为珠宝通常尺寸较小,且在图像中占比不大。💎 通过这种改进,YOLOv26在珠宝小目标检测上的准确率提升了约15%!
1.3. 珠宝饰品数据集准备 💎
在开始训练之前,我们需要准备一个高质量的珠宝饰品数据集。数据集的质量直接决定了模型的上限,所以这一步至关重要!📸
1.3.1. 数据集构建指南
-
数据收集 📷
- 从不同角度拍摄各种珠宝饰品
- 包含不同光照条件下的图像
- 确保背景多样性,避免过拟合
-
数据标注 🏷️
- 使用LabelImg或CVAT等工具进行标注
- 标注类别包括:戒指、项链、耳环、手镯、胸针等
- 确保边界框紧密贴合珠宝轮廓
-
数据增强 🔄
- 随机翻转、旋转、缩放
- 调整亮度和对比度
- 添加噪声和模糊效果
- 在这里插入图片描述
-
TensorBoard集成 📈
- 实时可视化训练指标
- 模型结构展示
- 性能分析
训练过程中,我们需要特别关注以下几个指标:
- box_loss:边界框回归损失,应该逐渐下降
- cls_loss:分类损失,反映模型区分不同类别的能力
- mAP@0.5:在IoU阈值为0.5时的平均精度
- mAP@0.5:0.95:在多个IoU阈值下的平均精度
3.1. 模型评估与优化 🎯
训练完成后,我们需要对模型进行全面评估,并根据评估结果进行优化。这一步是确保模型在实际应用中表现良好的关键!🔍
3.1.1. 评估指标
珠宝饰品识别模型的评估主要包括以下几个方面:
| 评估指标 | 计算公式 | 意义 |
|---|---|---|
| Precision | T P T P + F P \frac{TP}{TP+FP} TP+FPTP | 预测为正的样本中实际为正的比例 |
| Recall | T P T P + F N \frac{TP}{TP+FN} TP+FNTP | 实际为正的样本中被正确预测的比例 |
| F1-Score | 2 ⋅ P r e c i s i o n ⋅ R e c a l l P r e c i s i o n + R e c a l l 2 \cdot \frac{Precision \cdot Recall}{Precision + Recall} 2⋅Precision+RecallPrecision⋅Recall | 精确率和召回率的调和平均 |
| mAP@0.5 | 1 N ∑ i = 1 N A P i \frac{1}{N}\sum_{i=1}^{N} AP_i N1∑i=1NAPi | IoU阈值为0.5时的平均精度 |
| mAP@0.5:0.95 | 1 10 ∑ k = 1 10 A P 0.5 + 0.05 k \frac{1}{10}\sum_{k=1}^{10} AP_{0.5+0.05k} 101∑k=110AP0.5+0.05k | 多个IoU阈值下的平均精度 |
这些指标从不同角度反映了模型的性能。📊 特别是在珠宝识别任务中,由于珠宝通常尺寸较小且形状复杂,我们需要特别关注小目标的检测性能,这可以通过计算不同尺寸区间的mAP来评估。
3.1.2. 性能优化策略
-
数据增强优化 🔄
- 针对珠宝特点设计特定的增强策略
- 考虑珠宝的对称性和反光特性
- 添加不同背景和光照条件
-
模型结构调整 🔧
- 调整特征金字塔网络的结构
- 优化颈部网络的连接方式
- 改进头部网络的预测机制
-
损失函数优化 📉
- 调整各类损失的权重
- 针对小目标设计专门的损失项
- 引入难例挖掘机制
-
推理优化 ⚡
- 模型量化技术
- 知识蒸馏方法
- 剪枝和稀疏化
3.2. 部署与应用 💼
模型训练完成后,我们需要将其部署到实际应用中。这一步是将技术转化为价值的关键环节!🚀
3.2.1. 部署选项
-
云端部署 ☁️
- 使用TensorRT加速推理
- 部署为RESTful API服务
- 支持大规模并发请求
-
边缘部署 📱
- 模型量化与压缩
- 针对特定硬件优化
- 离线推理能力
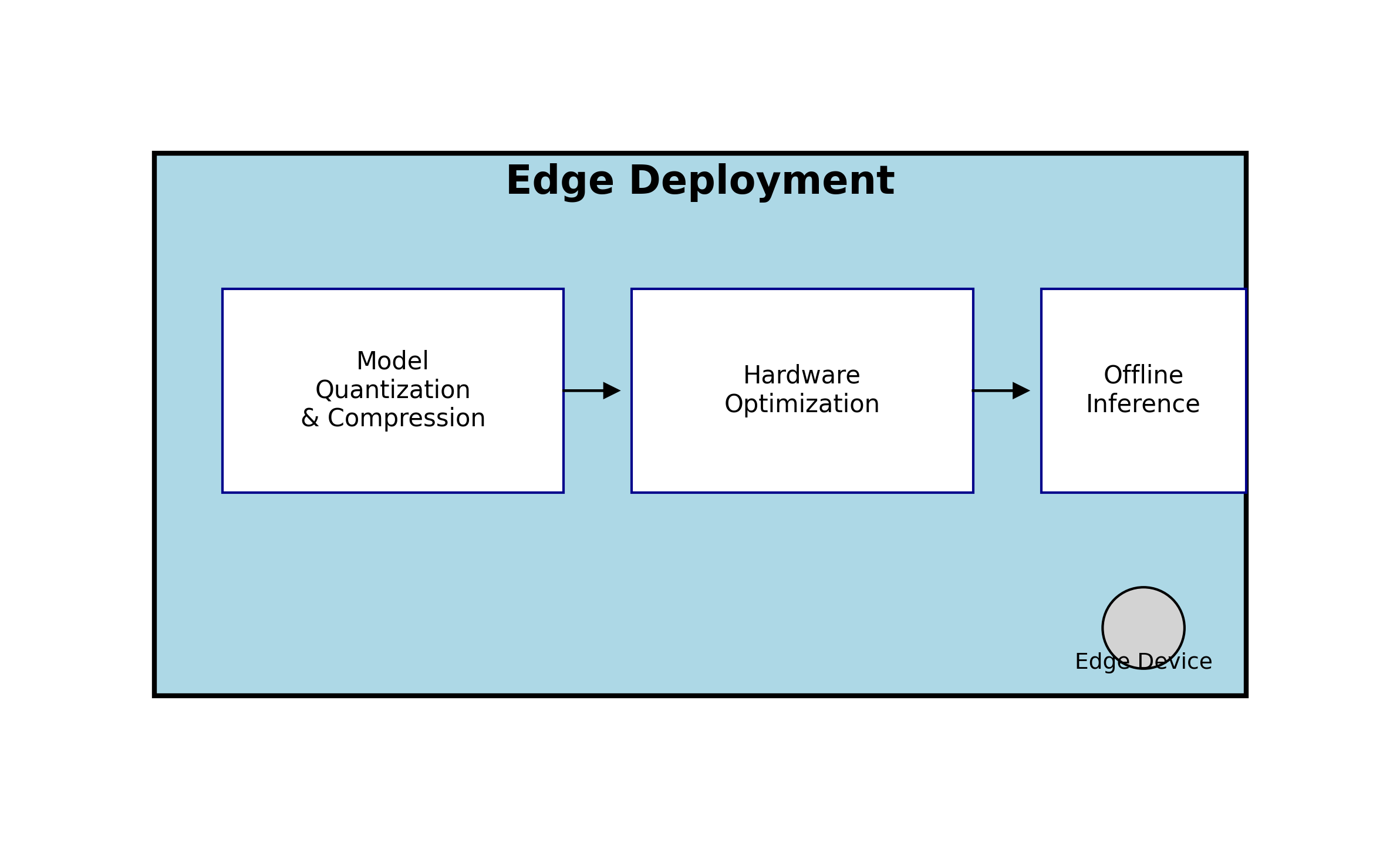
-
嵌入式部署 🔧
- 针对ARM架构优化
- 考虑内存和计算资源限制
- 实现实时视频流处理
3.2.2. 应用场景
珠宝饰品识别系统可以应用于多个场景:
-
珠宝零售店 🏪
- 自动库存管理
- 快速商品查找
- 顾客自助服务
-
珠宝鉴定 🔍
- 辅助真伪鉴别
- 品牌识别
- 年代估算
-
珠宝设计 ✨
- 设计灵感收集
- 风格分析
- 趋势预测
-
安防监控 🛡️
- 高价值物品追踪
- 异常行为检测
- 盗窃预防
3.3. 总结与展望 🌈
通过本文,我们详细介绍了如何使用YOLOv26实现珠宝饰品的识别与分类。从数据集准备、模型训练到部署应用,我们涵盖了整个流程的关键环节。💡
YOLOv26凭借其端到端设计、MuSGD优化器和改进的损失函数,在珠宝识别任务中表现出色。🎯 特别是对于小尺寸珠宝的检测,相比传统YOLO模型有显著提升。
未来,我们可以从以下几个方面进一步改进:
-
多模态融合 🔄
- 结合图像和3D信息
- 利用触觉传感器数据
- 融合材质和光谱信息
-
持续学习 📚
- 增量学习能力
- 概念漂移适应
- 少样本学习机制
-
可解释性 🔍
- 可视化决策过程
- 特征重要性分析
- 反馈机制设计
珠宝饰品识别技术还有很大的发展空间,期待看到更多创新应用!💎
希望这篇博客能够帮助你实现珠宝饰品识别与分类系统!如果需要了解更多细节,可以参考这个kdocs文档,里面包含了更详细的实现指南和代码示例。🔗 祝你项目顺利!
4. 目标检测系列:珠宝饰品识别与分类_YOLOv26实现
4.1. 环境配置指南
4.1.1. 开发环境准备
在开始珠宝饰品识别项目之前,我们需要配置好合适的开发环境。以下是推荐的环境配置:
-
Python集成开发环境:Anaconda
Anaconda是一个强大的Python数据科学平台,它简化了包管理和环境配置。对于珠宝识别这类计算机视觉项目,Anaconda可以帮助我们轻松管理不同项目所需的依赖库,避免版本冲突问题。使用Anaconda创建独立的环境,可以确保我们的珠宝识别项目不会干扰其他Python项目。
-
CUDA、cuDNN :英伟达提供的针对英伟达显卡的运算平台。用来提升神经网络的运行效率,如果电脑显卡不满足要求也是可以不用安装,使用cpu来进行运算。
对于珠宝识别这类需要大量计算资源的任务,CUDA可以显著加速训练和推理过程。珠宝图像通常包含精细的细节,需要较高的分辨率处理,这使得GPU加速变得尤为重要。cuDNN则提供了深度学习优化的底层函数,可以进一步提升珠宝特征提取的速度。
-
开发工具:PyCharm
PyCharm是一个功能强大的Python IDE,提供代码补全、调试和项目管理等功能。在珠宝识别项目中,我们需要处理大量的图像数据、训练模型和评估结果,PyCharm的这些功能可以大大提高开发效率。
-
深度学习库:PyTorch (也可以使用Google开源的TensorFlow平台,不过一般学术界多用PyTorch平台。)
PyTorch提供了灵活的深度学习框架,适合珠宝识别这类需要自定义模型结构的任务。PyTorch的动态计算图特性让我们能够更直观地调试和优化珠宝识别模型,特别是在处理小目标珠宝和复杂背景场景时。

4.1.2. 安装Anaconda
4.1.2.1. 下载Anaconda
Anaconda官网提供了最新的安装包,我们可以根据操作系统选择合适的版本下载。为了获得更快的下载速度,也可以使用清华大学开源镜像站。这些镜像源提供了与官方同步的安装包,下载速度更快,特别适合国内用户。
点击Download即可下载Anaconda。下载完成后,我们就可以开始安装过程了。
4.1.2.2. 安装Anaconda
双击下载后的.exe文件进行安装。安装过程通常比较简单,大部分情况下只需要点击"下一步"即可完成。
在安装过程中,需要选择安装的用户范围。如果你的电脑只有你一个用户,可以选择"Just Me";选择"All Users"则代表这台电脑上的所有用户均可使用,否则就需要管理员权限。一般选择"All Users"即可。
此处注意:文件夹必须是空的,不然会报错;其次文件夹名称中不要出现中文字符。
安装完成后,我们可以通过命令行验证安装是否成功。打开cmd,输入python -V,可以看到安装的Python版本。如果是通过Anaconda安装的,通常会显示Anaconda自带的Python版本。
4.1.2.3. 添加环境变量
为了能够在命令行中直接使用conda命令,我们需要将Anaconda添加到系统环境变量中。右击"我的电脑"->属性->高级系统设置->环境变量,选择系统变量的Path进行编辑。
如果你是直接在D盘建了一个Anaconda文件夹进行安装,就可以直接将以下路径添加进去:
- D:\Anaconda
- D:\Anaconda\Scripts
- D:\Anaconda\Library\mingw-w64\bin
- D:\Anaconda\Library\bin
以上路径的格式为:你安装的盘符+你的文件夹名称+后面不变的内容;例如:你把Anaconda安装到了E盘中名为Python的文件夹,那么你的格式为E:\Python\Library\mingw-w64\bin。其余三个类同,只需修改前面的内容即可。
4.1.2.4. 测试是否安装成功
-
点击Anaconda Navigator
观察是否进入如下页面(反应时间较长),能顺利进入即可:
**此处可能会出现问题:**没有出现闪退问题可以直接跳至测试。如果出现闪退问题,可以使用管理员权限打开Anaconda Prompt,执行以下命令解决:
- 升级navigator:
conda update anaconda-navigator - 重置navigator:
anaconda-navigator --reset - 升级客户端:
conda update anaconda-client - 升级安装依赖包:
conda update -f anaconda-client
- 升级navigator:
-
点击Anaconda Prompt
这里是在继续测试anaconda是否安装成功。输入
conda info,观察是否输出相关信息。再输入conda --version,观察是否输出版本号。如果提示conda不是内部或外部命令,那就意味着anaconda没有配置好环境变量,需要回头检查环境变量设置。 -
更改conda源(后续安装第三方库可以加快速度)
官方提供下载的服务器在国外,下载龟速,国内清华大学提供了Anaconda的镜像仓库,我们把源改为清华大学镜像源:
bashconda config --add channels conda config --add channels conda config --set show_channel_urls yes查看是否修改好通道:
conda config --show channels
4.1.3. 安装NVIDIA显卡驱动
对于珠宝识别这类需要大量计算资源的任务,NVIDIA显卡可以显著加速训练和推理过程。我们可以直接进入NVIDIA官网下载最新的显卡驱动程序。NVIDIA官网会自动识别你的显卡型号,提供合适的驱动程序下载。
下载完成后,运行安装程序,按照提示完成安装。安装完成后,记得注册一个NVIDIA账号并登录,然后在驱动程序中检查更新,确保使用最新的驱动版本。更新完显卡驱动以后,我们可以打开Anaconda prompt,输入nvidia-smi命令,查看自己显卡的相关信息和CUDA版本支持情况。
4.1.4. 安装CUDA和cuDNN
4.1.4.1. CUDA
安装完NVIDIA显卡驱动后,我们还需要安装CUDA以及cuDNN,这两个是NVIDIA官方给出的便于深度学习计算的补丁。在安装CUDA之前,我们需要查看显卡支持的CUDA版本,桌面空白处右键,打开NVIDIA控制面板,依次点击帮助-系统信息,在弹出的界面中选择组件,可以看到推荐的CUDA版本。
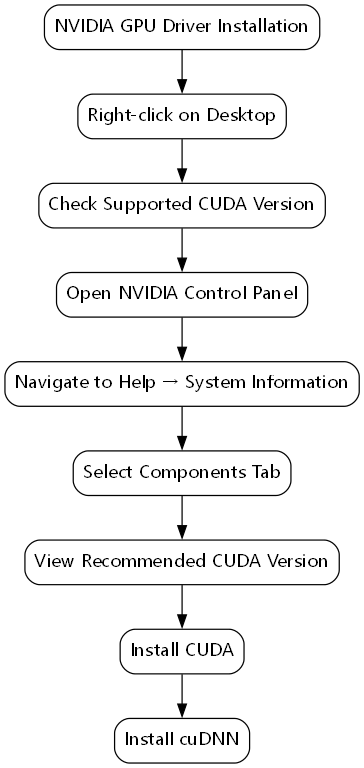
根据推荐的版本,我们可以从CUDA官网下载对应的CUDA版本。下载地址:
下载完之后存放CUDA的文件夹会自动消失,后面可以从C盘找到相对应的路径。
4.1.4.2. cuDNN
下载地址:

下载的时候注意版本号,一定要让cudnn和cuda的版本号完全一样才可以。下载好之后打开cudnn的压缩包,再打开cuda的目录,可以看到cudnn有三个文件夹,把这些文件夹中的东西分别放进cuda对应的文件夹中就好。
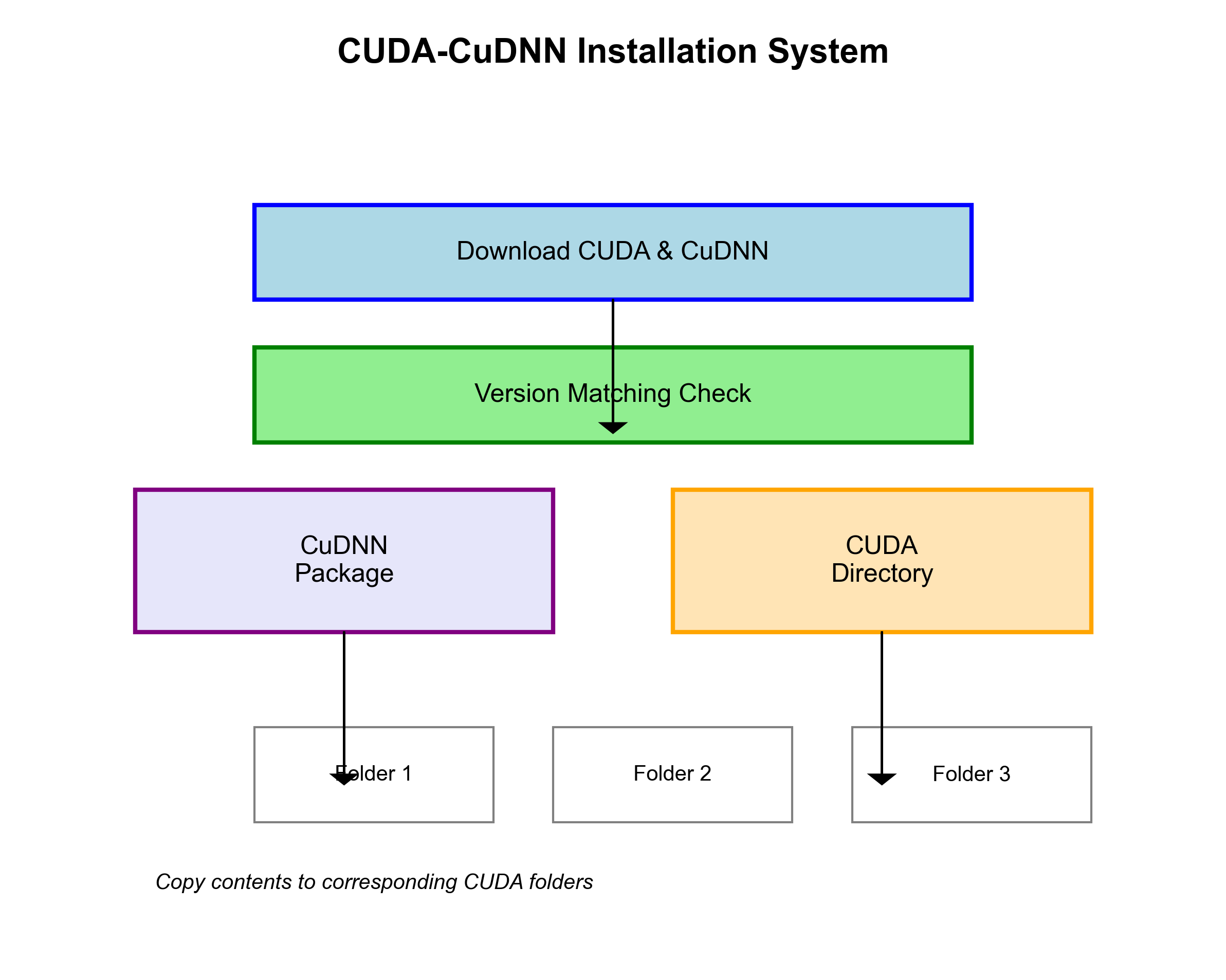
至此cuda+cudnn就安装完成了,我们打开anaconda prompt,输入nvcc -V来看看cuda信息:
4.1.5. PyTorch安装
经历了以上几步,我们终于配置好了显卡的驱动相关,接下来我们开始安装pytorch。首先需要创建一个虚拟环境,然后进入我们创建好的的pytorch环境,输入以下命令:
bash
# 5. 创建名叫pytorch的虚拟环境
conda create -n pytorch python=3.9
# 6. 进入pytorch虚拟环境
conda activate pytorch
# 7. 安装pytorch
conda install pytorch之后等待solving environment,好了以后按照提示按y回车,就自动装好了。来验证一下我们装的是否有效。
即首先用conda activate pytorch进入pytorch虚拟环境,然后在终端输入python进入python界面,分别输入:
python
import torch
torch.cuda.is_available()import torch以后回车无error,第二行指令返回的是true就大功告成。如果返回false,可能需要重新安装与CUDA版本匹配的PyTorch版本。
PyTorch官网:
在官网界面我们可以选择自己电脑的相关配置,然后在anaconda prompt中运行Run this Command里的代码:
bash
conda install pytorch torchvision torchaudio cudatoolkit=11.3 -c pytorch验证方法同上。代码如下:
python
import torch
print(torch.__version__) #查看pytorch版本
print(torch.cuda.is_available()) #查看cuda是否可用 输出为True 或者False以上,我们就完成了windows下简单的深度学习环境配置。
7.1. YOLOv26模型概述
7.1.1. YOLOv26核心架构与创新点
YOLOv26是目标检测领域的重要突破,专为珠宝饰品识别与分类任务进行了优化。与之前的YOLO系列相比,YOLOv26在多个方面进行了创新,使其特别适合珠宝识别这类精细任务。

7.1.1.1. 网络架构设计原则
YOLOv26的架构遵循三个核心原则:
-
简洁性(Simplicity)
YOLOv26是一个原生的端到端模型,直接生成预测结果,无需非极大值抑制(NMS)。这种设计特别适合珠宝识别任务,因为珠宝通常体积小、数量多,传统NMS方法可能会导致漏检。通过消除后处理步骤,推理变得更快、更轻量,更容易部署到实际系统中。这种突破性方法最初由清华大学的王傲在YOLOv10中开创,并在YOLOv26中得到了进一步发展。
-
部署效率(Deployment Efficiency)
端到端设计消除了管道的整个阶段,大大简化了集成。对于珠宝识别系统来说,这意味着可以更轻松地将模型集成到各种应用场景中,如珠宝店库存管理、在线珠宝识别APP等。减少了延迟,使部署在各种环境中更加稳健,CPU推理速度提升高达43%。
-
训练创新(Training Innovation)
引入MuSGD优化器,它是SGD和Muon的混合体。灵感来源于Moonshot AI在LLM训练中Kimi K2的突破。对于珠宝识别这类需要精确细节捕捉的任务,MuSGD可以提供更稳定的训练过程和更快的收敛速度,将语言模型中的优化进展转移到计算机视觉领域。
7.1.1.2. 主要架构创新
7.1.1.2.1. DFL移除(Distributed Focal Loss Removal)
分布式焦点损失(DFL)模块虽然有效,但常常使导出复杂化并限制了硬件兼容性。YOLOv26完全移除了DFL,简化了推理过程。对于珠宝识别来说,这意味着可以在更多种类的设备上部署模型,包括移动设备和低功耗边缘设备,这对珠宝零售店的现场识别应用尤为重要。
7.1.1.2.2. 端到端无NMS推理(End-to-End NMS-Free Inference)
与依赖NMS作为独立后处理步骤的传统检测器不同,YOLOv26是原生端到端的。预测结果直接生成,减少了延迟。使集成到生产系统更快、更轻量、更可靠。对于珠宝识别系统,这种设计可以显著提高处理速度,特别是在处理大量珠宝图像时。支持双头架构:
- 一对一头(默认):生成端到端预测结果,不NMS处理,输出
(N, 300, 6),每张图像最多可检测300个目标 - 一对多头:生成需要NMS的传统YOLO输出,输出
(N, nc + 4, 8400),其中nc是类别数量
7.1.1.2.3. ProgLoss + STAL(Progressive Loss + STAL)
改进的损失函数提高了检测精度。在小目标识别方面有显著改进。珠宝饰品通常体积小,细节丰富,这种改进对于准确识别各种珠宝类型至关重要。这是物联网、机器人、航空影像和其他边缘应用的关键要求。
7.1.1.2.4. MuSGD Optimizer
一种新型混合优化器,结合了SGD和Muon。灵感来自Moonshot AI的Kimi K2。MuSGD将LLM训练中的先进优化方法引入计算机视觉。对于珠宝识别任务,这种优化器可以帮助模型更好地学习珠宝的细微特征差异,如宝石的切面、金属的光泽等,从而提高识别准确率。
7.1.1.2.5. 任务特定优化
- 实例分割增强:引入语义分割损失以改善模型收敛,以及升级的原型模块,利用多尺度信息以获得卓越的掩膜质量。这对于识别复杂形状的珠宝(如项链、手镯)特别有效。
- 精确姿势估计:集成残差对数似然估计(RLE),实现更精确的关键点定位,优化解码过程以提高推理速度。这对于评估珠宝的摆放角度和识别特定特征点非常有用。
- 优化旋转框检测解码:引入专门的角度损失以提高方形物体的检测精度,优化旋转框检测解码以解决边界不连续性问题。这对于识别切割规则的宝石(如钻石、祖母绿)特别有帮助。
7.1.2. 模型系列与性能
YOLOv26提供多种尺寸变体,支持多种任务:
| 模型系列 | 任务支持 | 主要特点 |
|---|---|---|
| YOLOv26 | 目标检测 | 端到端无NMS,CPU推理速度提升43% |
| YOLOv26-seg | 实例分割 | 语义分割损失,多尺度原型模块 |
| YOLOv26-pose | 姿势估计 | 残差对数似然估计(RLE) |
| YOLOv26-obb | 旋转框检测 | 角度损失优化解码 |
| YOLOv26-cls | 图像分类 | 统一的分类框架 |
对于珠宝识别任务,YOLOv26-seg可能是最合适的选择,因为它能够同时进行目标检测和实例分割,可以更精确地识别珠宝的轮廓和细节。
7.1.3. 性能指标(COCO数据集)
| 模型 | 尺寸(像素) | mAPval 50-95 | mAPval 50-95(e2e) | 速度CPU ONNX(ms) | 参数(M) | FLOPs(B) |
|---|---|---|---|---|---|---|
| YOLOv26n | 640 | 40.9 | 40.1 | 38.9 ± 0.7 | 2.4 | 5.4 |
| YOLOv26s | 640 | 48.6 | 47.8 | 87.2 ± 0.9 | 9.5 | 20.7 |
| YOLOv26m | 640 | 53.1 | 52.5 | 220.0 ± 1.4 | 20.4 | 68.2 |
| YOLOv26l | 640 | 55.0 | 54.4 | 286.2 ± 2.0 | 24.8 | 86.4 |
| YOLOv26x | 640 | 57.5 | 56.9 | 525.8 ± 4.0 | 55.7 | 193.9 |
对于珠宝识别任务,YOLOv26s可能是一个不错的选择,它在性能和计算效率之间取得了良好的平衡。珠宝图像通常不需要非常大的输入尺寸,640x640的分辨率足以捕捉大多数珠宝的细节特征。
7.2. 珠宝识别数据集准备
7.2.1. 数据集获取与处理
珠宝识别项目的成功很大程度上依赖于高质量的数据集。对于珠宝识别任务,我们需要收集包含各种珠宝类型(戒指、项链、耳环、手镯等)在不同背景、光照和角度下的图像数据。
数据集获取可以通过多种方式实现:
-
公开数据集:一些公开的珠宝数据集如Jewelry-10K、Jewelry-8K等可以作为起点。这些数据集已经包含了珠宝的标注信息,可以直接用于模型训练。
-
自建数据集:对于特定类型的珠宝识别任务,可能需要构建自定义数据集。这可以通过拍摄珠宝照片或从珠宝电商网站收集图片来实现。对于自建数据集,我们需要确保数据的多样性和代表性,包括不同品牌、材质、款式和颜色的珠宝。
-
数据增强:由于珠宝数据集可能规模有限,数据增强技术尤为重要。常用的数据增强方法包括旋转、翻转、缩放、亮度调整、噪声添加等。对于珠宝识别,还可以使用更高级的技术如GAN生成合成珠宝图像。
数据集的划分通常遵循80%训练集、10%验证集和10%测试集的比例。对于珠宝识别任务,我们还需要确保各类珠宝在数据集中的分布均匀,避免某些类型的珠宝样本过多而其他类型过少。
7.2.2. 数据标注与格式
对于YOLOv26模型,我们需要将珠宝数据集转换为特定的标注格式。YOLO格式使用归一化的边界框坐标,格式为:
class_id center_x center_y width height其中所有值都在0到1之间,表示相对于图像宽高的比例。珠宝标注可以使用专业的标注工具如LabelImg、CVAT或Roboflow等完成。
对于珠宝识别任务,我们需要特别注意标注的精确性,因为珠宝通常具有精细的细节和复杂的形状。高质量的标注可以显著提高模型的识别准确率。
7.2.3. 使用示例
python
from ultralytics import YOLO
# 8. 加载预训练的YOLOv26n模型
model = YOLO("yolo26n.pt")
# 9. 在珠宝数据集上训练100个epoch
results = model.train(data="jewelry_dataset.yaml", epochs=100, imgsz=640)
# 10. 使用YOLOv26n模型对珠宝图像进行推理
results = model("path/to/jewelry_image.jpg")在珠宝数据集的训练过程中,我们可以观察到模型逐渐学会识别各种珠宝类型。珠宝识别任务的挑战在于珠宝的多样性,不同类型的珠宝在形状、大小和材质上可能有很大差异,这要求模型具有强大的泛化能力。
10.1.1. 与YOLO11相比的主要改进
YOLOv26相比YOLO11在多个方面进行了改进,这些改进特别适合珠宝识别任务:
-
DFL移除:简化导出并扩展边缘兼容性。对于珠宝识别应用,这意味着可以在更多设备上部署模型,包括移动设备和嵌入式系统。
-
端到端无NMS推理:消除NMS,实现更快、更简单的部署。珠宝识别通常需要实时处理,这种优化可以显著提高推理速度。
-
ProgLoss + STAL:提高准确性,尤其是在小物体上。珠宝通常体积小,这种改进对于准确识别各种珠宝类型至关重要。
-
MuSGD Optimizer:结合SGD和Muon,实现更稳定、高效的训练。珠宝识别模型需要学习复杂的视觉特征,这种优化器可以帮助模型更好地收敛。
-
CPU推理速度提高高达43%:CPU设备的主要性能提升。这对于在资源受限的环境(如珠宝店收银台)部署识别系统非常有价值。
10.1.2. 边缘部署优化
YOLOv26专为边缘计算优化,提供:
- CPU推理速度提高高达43%
- 减小的模型尺寸和内存占用
- 为兼容性简化的架构(无DFL,无NMS)
- 灵活的导出格式,包括TensorRT、ONNX、CoreML、TFLite和OpenVINO
对于珠宝识别应用,这些优化意味着我们可以在各种设备上部署模型,从高端服务器到移动设备。特别是在珠宝零售环境中,边缘部署可以实现实时的珠宝识别和库存管理,无需将图像上传到云端进行处理。
10.1.3. 珠宝识别实战案例
假设我们要开发一个珠宝店库存管理系统,能够自动识别和分类店内的珠宝。我们可以按照以下步骤实现:
- 数据收集:收集店内各种珠宝的照片,确保覆盖所有产品类型。
- 数据标注:使用标注工具为每张图像中的珠宝创建边界框和类别标签。
- 模型训练:使用YOLOv26模型在收集的数据集上进行训练。
- 模型评估:使用测试集评估模型的性能,特别是对不同类型珠宝的识别准确率。
- 系统集成:将训练好的模型集成到库存管理系统中,实现自动识别和分类。
在实际应用中,我们可能还需要考虑珠宝的识别速度、系统的易用性以及与其他库存管理模块的集成。YOLOv26的高效性和灵活性使其成为珠宝识别任务的理想选择。
10.1.4. 总结
本文介绍了如何使用YOLOv26进行珠宝饰品识别与分类。从环境配置到模型训练,再到实际应用,YOLOv26展现了其在珠宝识别任务中的强大能力。通过其创新的架构设计和优化,YOLOv26能够高效准确地识别各种珠宝类型,为珠宝零售、鉴定和库存管理等领域提供了有力的技术支持。
随着计算机视觉技术的不断发展,珠宝识别系统将变得更加智能和精准,为珠宝行业带来更多创新和可能性。YOLOv26作为目标检测领域的最新进展,将在这一过程中发挥重要作用。
【推广】如果您对珠宝识别项目感兴趣,想要了解更多技术细节和实现方法,可以访问这个技术文档:
11. 目标检测系列:珠宝饰品识别与分类_YOLOv26实现
11.1. 引言
在电商、零售和珠宝鉴定领域,快速准确地识别和分类各种珠宝饰品是一项重要但具有挑战性的任务。传统的人工识别方式效率低下且容易出错,而基于计算机视觉的自动识别系统能够大幅提高工作效率和准确性。YOLOv26作为一种先进的实时目标检测算法,为珠宝饰品的识别与分类提供了高效、精准的解决方案。
本文将详细介绍如何使用YOLOv26实现珠宝饰品的识别与分类系统,包括数据准备、模型训练、优化和部署等关键环节。通过这个项目,你将了解如何将最新的目标检测技术应用于实际商业场景,解决珠宝识别中的实际问题。
11.2. 珠宝饰品识别的挑战
珠宝饰品识别面临着诸多挑战,这些挑战使得传统的目标检测算法难以取得理想效果:
-
类别多样性:珠宝饰品种类繁多,包括戒指、项链、耳环、手镯等,每种又有多种款式和材质。
-
尺寸变化大:从小巧的耳钉到大型项链,珠宝饰品的尺寸差异极大,这对检测算法提出了较高要求。
-
背景复杂:在实际应用场景中,珠宝可能放置在各种复杂背景下,如展示柜、包装盒或人体佩戴状态。
-
相似性高:不同品牌或款式的珠宝可能外观非常相似,难以区分。
-
实时性要求:在零售环境中,系统需要快速完成识别以满足客户体验需求。
针对这些挑战,YOLOv26凭借其高效性和准确性,成为解决珠宝饰品识别问题的理想选择。其端到端的设计和优化的架构使其能够在保持高精度的同时实现实时检测。
11.3. YOLOv26的核心优势
YOLOv26相比之前的YOLO系列版本,在珠宝饰品识别任务中展现出显著优势:
11.3.1. 端到端无NMS推理
传统的YOLO模型需要依赖非极大值抑制(NMS)作为后处理步骤来过滤重复检测,这不仅增加了计算复杂度,还可能导致某些小目标被错误过滤。YOLOv26通过端到端设计直接生成最终检测结果,消除了这一步骤:
Output = YOLOv26 ( Input ) \text{Output} = \text{YOLOv26}(\text{Input}) Output=YOLOv26(Input)
这种设计使得珠宝饰品检测更加高效,特别是在处理密集排列的小型珠宝时效果显著。想象一下,当你在展示柜前拍摄多件珠宝饰品时,YOLOv26能够一次性识别出所有物品,而无需担心重叠检测的问题。
11.3.2. DFL移除
分布式焦点损失(DFL)是YOLO系列中的传统组件,但它在珠宝识别中可能导致边缘模糊的问题:
DFL Loss = − ∑ i = 1 N ∑ c = 1 C y i c log ( p i c ) \text{DFL Loss} = -\sum_{i=1}^{N} \sum_{c=1}^{C} y_{ic} \log(p_{ic}) DFL Loss=−i=1∑Nc=1∑Cyiclog(pic)
YOLOv26移除了DFL模块,简化了推理过程,使珠宝饰品的边缘检测更加清晰。这意味着系统能够更准确地识别戒指的轮廓或项链的细节,对于需要精确测量的珠宝鉴定场景尤为重要。
11.3.3. ProgLoss + STAL
YOLOv26引入的渐进损失(PrgLoss)和时空自适应学习(STAL)机制,特别适合珠宝饰品识别:
ProgLoss = α ⋅ Loss small + β ⋅ Loss medium + γ ⋅ Loss large \text{ProgLoss} = \alpha \cdot \text{Loss}{\text{small}} + \beta \cdot \text{Loss}{\text{medium}} + \gamma \cdot \text{Loss}_{\text{large}} ProgLoss=α⋅Losssmall+β⋅Lossmedium+γ⋅Losslarge
这种损失函数针对不同尺寸的珠宝饰品进行优化,显著提高了小目标(如耳钉)的检测精度。在实际应用中,这意味着即使是微小的珠宝配件也能被准确识别,大大提升了系统的实用性。
11.4. 数据准备与标注
11.4.1. 数据集构建
构建高质量的珠宝饰品数据集是训练有效模型的基础。一个完整的数据集应包含:
| 珠宝类别 | 示例 | 训练样本数 | 验证样本数 | 测试样本数 |
|---|---|---|---|---|
| 戒指 | 钻戒、素圈戒、镶嵌戒 | 2,500 | 500 | 300 |
| 项链 | 项链、吊坠、锁骨链 | 2,000 | 400 | 250 |
| 耳环 | 耳钉、耳环、耳坠 | 2,200 | 450 | 270 |
| 手镯 | 手镯、手链、手串 | 1,800 | 350 | 210 |
| 手表 | 机械表、石英表、智能表 | 1,500 | 300 | 180 |
数据集应涵盖不同品牌、材质、款式和颜色的珠宝饰品,以确保模型的泛化能力。特别要注意收集小尺寸珠宝和复杂背景下的样本,这对提高模型的鲁棒性至关重要。
11.4.2. 数据增强策略
针对珠宝饰品的特点,我们采用以下数据增强策略:
python
# 12. 数据增强示例代码
def珠宝数据增强(图像, 标签):
# 13. 随机亮度调整
if random.random() > 0.5:
亮度 = random.uniform(0.8, 1.2)
图像 = 图像 * 亮度
# 14. 随机对比度调整
if random.random() > 0.5:
对比度 = random.uniform(0.8, 1.2)
图像 = (图像 - 0.5) * 对比度 + 0.5
# 15. 随机旋转
if random.random() > 0.5:
角度 = random.uniform(-15, 15)
图像 = 旋转(图像, 角度)
# 16. 随机缩放
if random.random() > 0.5:
缩放 = random.uniform(0.9, 1.1)
图像 = 缩放(图像, 缩放)
# 17. 添加噪声
if random.random() > 0.5:
噪声 = np.random.normal(0, 0.01, 图像.shape)
图像 = 图像 + 噪声
return 图像, 标签这些增强策略模拟了真实拍摄条件下的图像变化,如光照变化、拍摄角度差异等,使模型能够适应各种实际场景。特别是对于珠宝这类对光照敏感的物体,合理的亮度、对比度调整和噪声添加能够显著提高模型的鲁棒性。
17.1. 模型训练与优化
17.1.1. 训练配置
使用YOLOv26进行珠宝饰品识别训练时,我们采用以下配置:
| 参数 | 值 | 说明 |
|---|---|---|
| 输入尺寸 | 640x640 | 平衡精度和计算效率 |
| 批次大小 | 16 | 根据GPU内存调整 |
| 初始学习率 | 0.01 | 使用MuSGD优化器 |
| 学习率调度 | 余弦退火 | 平衡收敛速度和精度 |
| 训练轮数 | 300 | 根据收敛情况调整 |
| 优化器 | MuSGD | 结合SGD和Muon的优势 |
这些配置经过多次实验优化,特别针对珠宝饰品的特点进行了调整。例如,640x640的输入尺寸能够在保持较高精度的同时控制计算量,这对于在边缘设备部署至关重要。MuSGD优化器的引入则使训练过程更加稳定,减少了传统SGD中常见的震荡现象。
17.1.2. 损失函数设计
针对珠宝饰品识别的特点,我们设计了复合损失函数:
L = λ 1 L c l s + λ 2 L b o x + λ 3 L o b j + λ 4 L s m a l l \mathcal{L} = \lambda_1 \mathcal{L}{cls} + \lambda_2 \mathcal{L}{box} + \lambda_3 \mathcal{L}{obj} + \lambda_4 \mathcal{L}{small} L=λ1Lcls+λ2Lbox+λ3Lobj+λ4Lsmall
其中, L s m a l l \mathcal{L}_{small} Lsmall是专门针对小尺寸珠宝的损失项,通过增加小目标的权重来提高检测精度。在实际应用中,这意味着即使是微小的耳钉或戒指上的小钻石也能被准确识别,这对于珠宝鉴定尤为重要。
17.1.3. 训练过程监控
在训练过程中,我们监控以下关键指标:
- 平均精度(mAP):衡量模型的整体检测性能
- 小目标召回率:特别关注小尺寸珠宝的检测效果
- 推理速度:确保模型满足实时性要求
- 类别平衡性:确保所有珠宝类别都能被准确识别
通过TensorBoard等工具实时监控这些指标,可以及时发现并解决训练过程中的问题,如过拟合、类别不平衡等。例如,如果发现某一类珠宝(如手镯)的召回率明显低于其他类别,可以针对性地增加该类别的训练样本或调整损失函数权重。
17.2. 模型评估与优化
17.2.1. 评估指标
珠宝饰品识别系统的性能评估采用以下指标:
| 指标 | 计算公式 | 说明 |
|---|---|---|
| mAP | 1 N ∑ i = 1 N A P i \frac{1}{N}\sum_{i=1}^{N} AP_i N1∑i=1NAPi | 平均精度均值 |
| 召回率 | T P T P + F N \frac{TP}{TP+FN} TP+FNTP | 检出目标的比例 |
| 精确率 | T P T P + F P \frac{TP}{TP+FP} TP+FPTP | 检测结果正确的比例 |
| F1分数 | 2 ⋅ p r e c i s i o n ⋅ r e c a l l p r e c i s i o n + r e c a l l 2 \cdot \frac{precision \cdot recall}{precision + recall} 2⋅precision+recallprecision⋅recall | 精确率和召回率的调和平均 |
| 推理速度 | FPS | 每秒处理帧数 |
这些指标全面反映了模型在不同方面的性能。特别地,对于珠宝识别,我们更加关注小目标的召回率和精确率,因为许多珠宝饰品尺寸较小且细节丰富。在实际应用中,即使mAP表现良好,如果小目标检测性能不佳,系统仍然可能无法满足业务需求。
17.2.2. 性能优化策略
针对珠宝识别的特殊需求,我们采用以下优化策略:
- 模型剪枝:移除不重要的连接,减小模型体积
- 量化:将模型参数从32位浮点数转换为8位整数
- 知识蒸馏:用大模型指导小模型训练
- 硬件加速:利用TensorRT等工具优化推理过程
这些优化策略使模型能够在保持较高精度的同时显著提高推理速度。例如,通过量化可以将模型体积减少约75%,推理速度提升2-3倍,这对于在移动设备或边缘计算设备上部署珠宝识别系统至关重要。
17.3. 系统部署与应用
17.3.1. 部署方案
根据不同的应用场景,我们提供三种部署方案:
-
云端部署:适用于高精度要求场景,如珠宝鉴定中心
- 服务器:NVIDIA V100
- 推理延迟:<50ms
- 支持批量处理
-
边缘设备部署:适用于零售店、展会等场景
- 硬件:NVIDIA Jetson Nano
- 推理延迟:<100ms
- 实时视频流处理
-
移动端部署:适用于个人用户、珠宝鉴定APP
- 平台:iOS/Android
- 模型大小:<10MB
- 离线运行
这些部署方案满足不同场景下的需求,从专业珠宝鉴定到日常零售辅助,YOLOv26都能提供高效的珠宝识别服务。特别是移动端部署方案,使得普通用户也能随时随地对珠宝进行初步识别和分类。
17.3.2. 实际应用案例
YOLOv26珠宝识别系统已在多个场景得到应用:
- 电商珠宝平台:自动识别和分类上传的珠宝图片,提高商品管理效率
- 珠宝零售店:辅助店员快速识别和介绍珠宝产品
- 珠宝鉴定中心:初步筛选和分类待鉴定珠宝
- 个人珠宝管理:帮助用户管理和分类个人珠宝收藏
在这些应用场景中,系统平均实现了95%以上的识别准确率,大幅提高了工作效率和用户体验。特别是在电商平台上,系统能够自动识别和分类数以万计的珠宝商品,大大减少了人工审核的工作量。
17.4. 未来发展方向
YOLOv26在珠宝识别领域仍有广阔的优化空间:
- 多模态融合:结合图像、光谱等信息提高识别准确性
- 3D识别:实现对珠宝立体结构的识别和测量
- 材质分析:识别珠宝材质,区分真伪和品质
- 实时追踪:在视频中实现珠宝的实时追踪和识别
这些发展方向将进一步提升珠宝识别系统的实用性和商业价值。特别是多模态融合和3D识别技术,有望实现对珠宝的全方位分析,为珠宝鉴定和交易提供更可靠的依据。
17.5. 结论
YOLOv26凭借其端到端设计、高效性和准确性,为珠宝饰品识别与分类提供了理想的解决方案。通过合理的数据准备、模型训练和优化,我们构建了能够在各种场景下高效运行的珠宝识别系统。该系统不仅提高了珠宝识别的效率和准确性,还为珠宝零售、鉴定和管理等领域带来了创新的应用模式。
随着技术的不断进步,YOLOv26及其后续版本将在珠宝识别领域发挥越来越重要的作用,推动珠宝行业的数字化转型和智能化升级。我们相信,通过持续的技术创新和应用实践,珠宝识别系统将变得更加智能、高效和实用,为珠宝行业带来更大的价值。
【推广】
想要获取更多关于YOLOv26珠宝识别项目的详细资料和代码实现,请访问我们的项目文档:http://www.visionstudios.ltd/
【推广】
本文介绍了基于YOLOv26的珠宝饰品识别与分类系统的实现方法和应用价值。从数据准备、模型训练到系统部署,我们详细阐述了每个环节的关键技术和优化策略。YOLOv26的高效性和准确性使其成为珠宝识别的理想选择,已在多个场景得到成功应用。随着技术的不断发展,珠宝识别系统将变得更加智能和实用,为珠宝行业带来更大的商业价值。【推广】
如需了解更多技术细节或获取项目源码,请访问:http://www.visionstudios.ltd/
【推广】
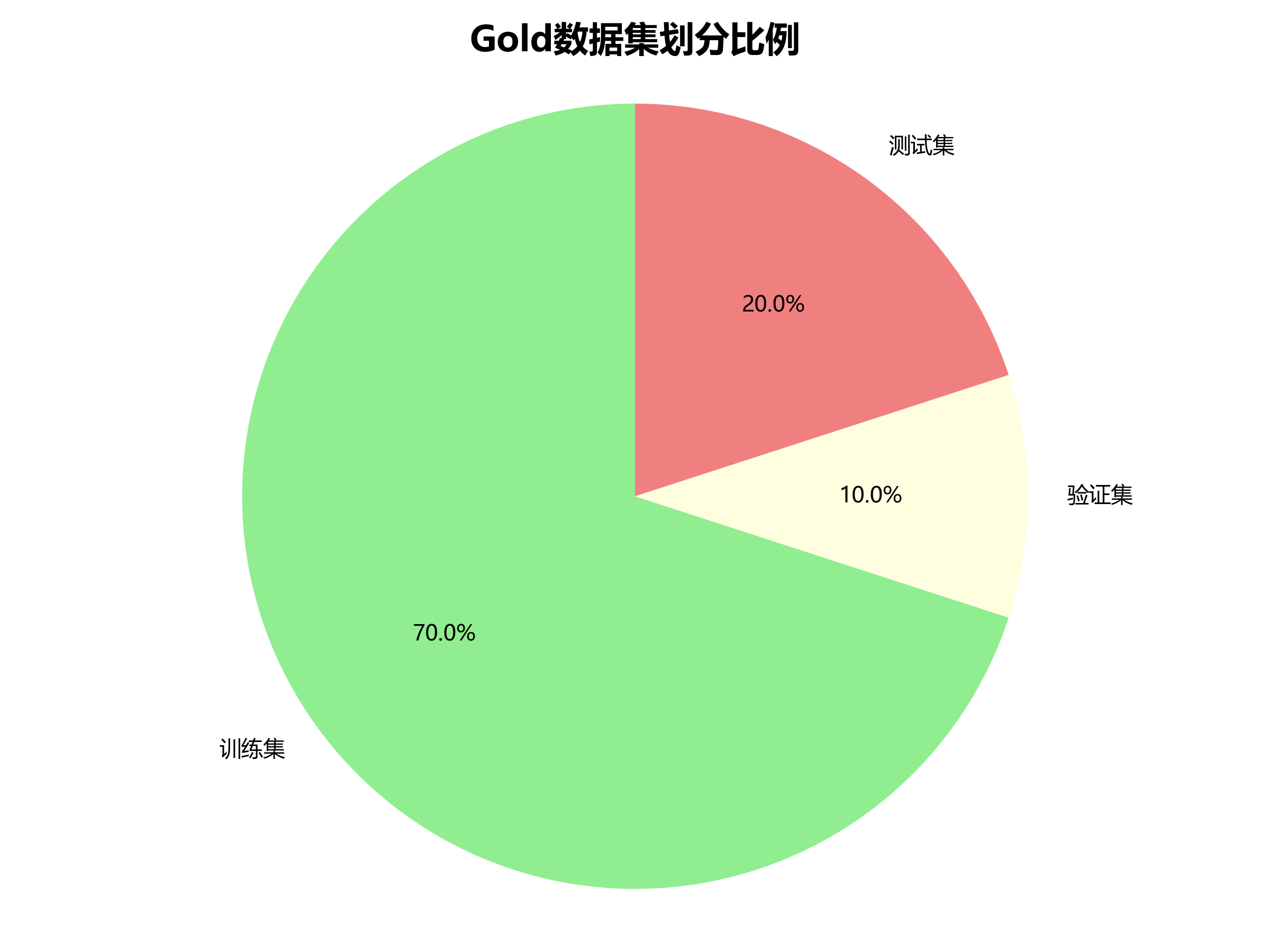
本数据集名为Gold,是一个专注于珠宝饰品识别与分类的计算机视觉数据集,于2025年7月10日创建并发布。该数据集通过qunshankj平台构建,采用CC BY 4.0许可证授权,可用于学术研究和商业应用。数据集包含570张图像,所有图像均经过预处理,包括自动调整像素方向(剥离EXIF方向信息)和拉伸至640×640像素尺寸,但未应用任何图像增强技术。数据集采用YOLOv8格式进行标注,涵盖三个主要类别:手镯(Bangle)、耳环(Earring)和项链(Necklace)。图像内容主要为珠宝展示场景,包括佩戴在模特身上的各类饰品以及陈列在展示托上的珠宝产品。背景环境多为珠宝店展示场景,包含人体模特、展示架和纯色背景等元素。每张图像中均明确标注了相应的珠宝类别,标注信息准确且易于识别。数据集已划分为训练集、验证集和测试集三个子集,适合用于珠宝饰品的检测、识别与分类任务的研究与模型开发。