简单实现string库里的函数,学习阶段适度造轮子,不是为了造一个更好的轮子,而是更好地理解函数以及提升代码能力、编程思维等。
1.默认成员函数
1.1 构造函数
cpp
namespace diy {//命名空间为diy,和库里string分离
class string {
public:
string(const char* str = "") ://常量字符串末尾是'\0'
//string(const char* str = nullptr) :不可以是这样,因为默认构造,没有有效字符,但是末尾要有'\0';而且strlen等函数会解引用空指针,程序崩溃
//string(const char* str = '\0') :不可以是这样,类型不匹配,左边是const char*, 右边是char
//string(const char* str = "\0") : 也可以是这样,但没必要
_size(strlen(str)),
_capacity(_size),
_str(new char[_capacity + 1]) {//这个地方是有问题的,因为初始化列表不会按照初始化列表中变量的先后顺序进行初始化,而是按照变量声明的顺序初始化,那么先初始化_str, _capacity是随机值会出问题;
//要么调整变量声明顺序,要么不在初始化列表进行初始化,因为内置变量在初始化列表和函数体初始化区别不大,一般自定义类型需要在初始化列表,因为如果自定义类型不在初始化列表,系统会调用自定义类型的默认构造,假如在函数体有带参的构造,会冲突
strcpy(_str,str);//这个地方可以用memcpy也可以是strcpy,因为传过来的是C string,有效字符不会包含'\0'
// strcpy会把'\0'拷贝过来
//strcpy和memcpy主要问题在于处理的是C string还是string,如果有C string,能够确保到\0终止,二者都可以;但如果是string,\0可以是有效字符,不表征中止,以size为衡量标准,就不能用strcpy; memcpy在使用的时候注意兼容C接口,要把末尾\0拷贝过来
}
private:
char* _str;
size_t _size;
size_t _capacity;
};
}修正如下
cpp
namespace diy {
class string {
public:
string(const char* str = "") {
_size = strlen(str);
_capacity = _size;
_str = new char[_capacity+1];
strcpy(_str,str);
}
private:
char* _str;
size_t _size;
size_t _capacity;
};
}很多时候程序出bug是问题没考虑周全,但是,情况没考虑到其实还是问题没分析到位,比如\0导致str系列函数在string这里不好使,源头是C string的\0表示终止,string有效字符可以是\0,而且为什么size下标位置要给\0,为什么开空间多开一个,为什么调用reserve之后不需要管_capacity,因为reserve自动条件capacity而不调节size,在处理问题的时候,什么改变,什么不改变,什么改变需要手动处理,什么不需要手动处理,要有复用的思想,+=直接处理好size和capacity已经size下标位置\0
1.2 拷贝构造
cpp
string(const string& s) {//推荐用const,因为权限可以缩小,不可以放大;有的时候必须用const,因为类型转换、函数传值返回都涉及到临时变量的常性问题
_str = new char[s._capacity + 1];
_capacity = s._capacity;
memcpy(_str, s._str, s._size + 1);//为了兼容C,'\0'也拷过来
// strcpy(_str, s._str); 这个地方用strcpy不严谨
_size = s._size;
}1.3 赋值函数
1.3.1 常量字符串赋值
cpp
string& operator=(const char* str) {
if (str == nullptr)
str = "";//如果str是nullptr,strlen会解引用空指针,程序崩溃
size_t len = strlen(str);
if (len <= _capacity) {
strcpy(_str, str);
_size = len;
}
else {//len>_capacity
//reserve(len); 没必要,因为原来数据已经无效了
delete[] _str;
_str = new char[len + 1];
_capacity = len;
strcpy(_str, str);//或者memcpy(_str,str,len+1);且此时memcpy效率略高,因为已知要拷贝的空间长度
_size = len;
}
return *this;
}优化
三种情况,当前对象放不下,或者是正好放下,或者放下str绰绰有余;第一种必须扩容,第二种不需要扩容(极少),第三种很可能存在内存利用率不高,直接重新开空间
cpp
string& operator=(const char* str) {
if (str == nullptr)
str = "";
size_t len = strlen(str);
delete[] _str;
_str = new char[len + 1];
_capacity = len;
strcpy(_str, str);
_size = len;
return *this;
}1.3.2 string对象赋值
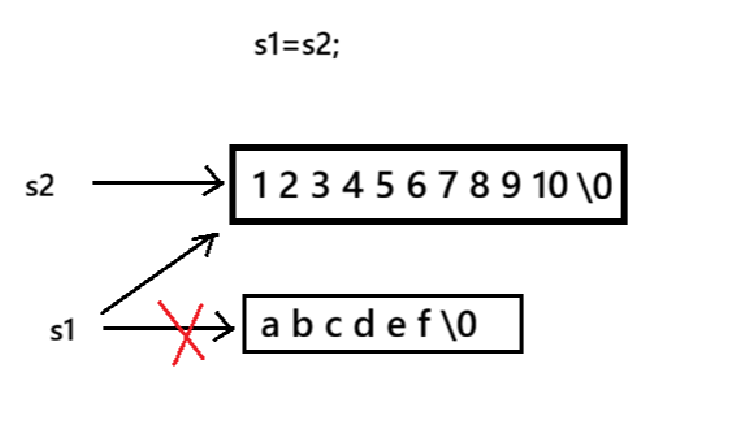
系统自动生成的赋值,内置类型默认是浅拷贝,如下图,一方面,s1本来指向的空间没有释放,导致内存泄漏;另一方面,s1, s2析构的时候会释放同一片空间,最后一个对象析构的时候访问空指针,会出问题
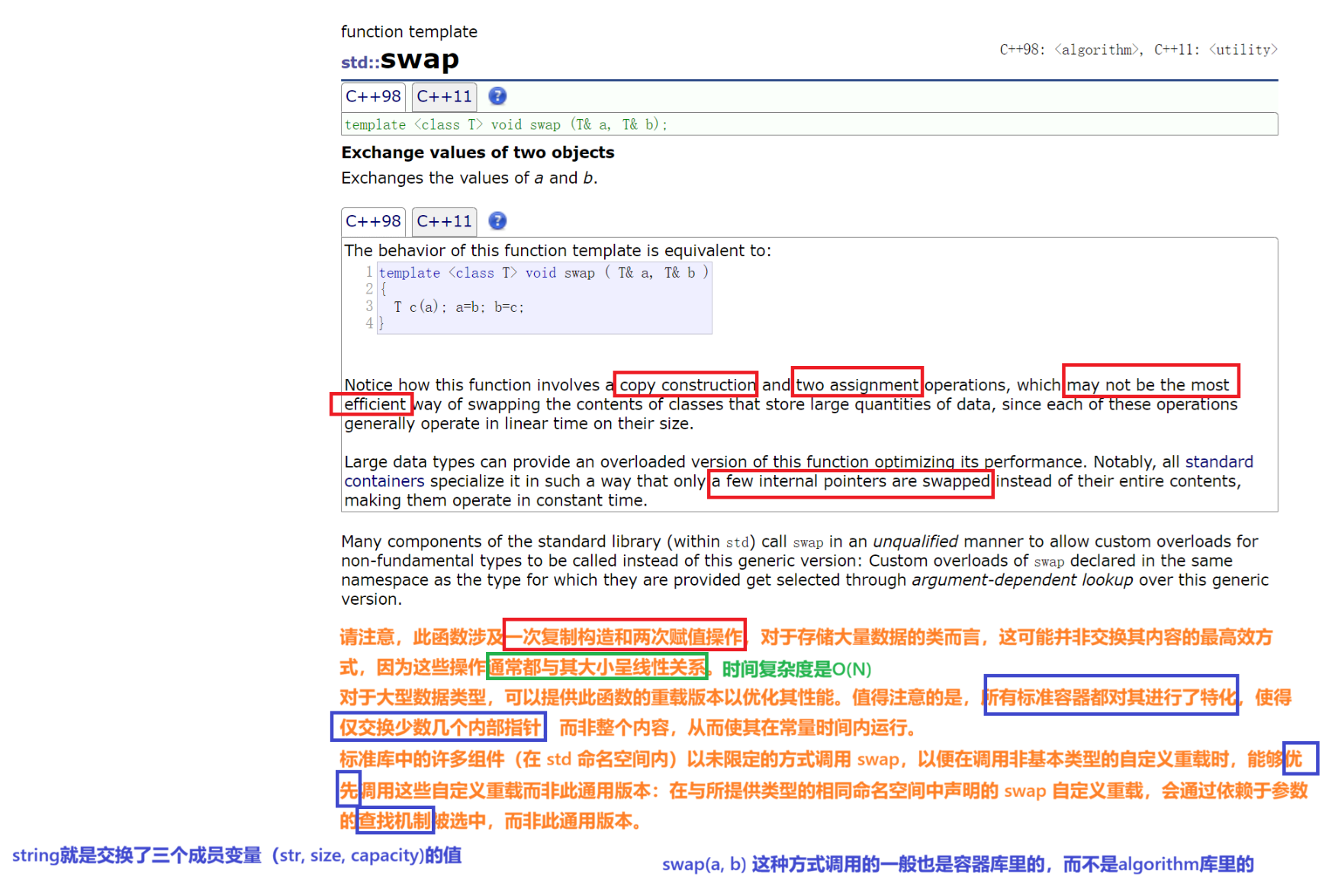
先来看swap
cpp
int main() {
string s1("she is aiming too high");
string s("dancing with your ghost");
s.swap(s1);//通过string对象调用string库里的swap
std::swap(s, s1);//调用algorithm库里的swap
return 0;
}那么为什么在algorithm库里有swap函数实现的情况下,string库里还要实现swap呢?提高效率

比如在我自行实现swap的时候,函数内部的swap系统自动匹配到了我在diy命名空间string类内实现的swap,而不是algorithm库里的
cpp
//传统写法
string& operator=(const string& s) {
if (this == &s)
return *this;
// reserve(s._capacity); 没必要,因为reserve是扩容(缩容不做处理),这里初始化肯定是扩容,存在的问题是,reserve会把原有数据拷到扩容后的空间,但字符对象本来就是空的,还拷什么
delete[] _str;//避免内存泄漏
_str = new char[s._capacity + 1];
_capacity = s._capacity;
memcpy(_str, s._str, s._size + 1);//strcpy(_str, s._str);//strcpy会把'\0'拷贝过来
_size = s._size;
return *this;
}
//现代优化
string& operator=(const string& str) {
if (this == &str)
return *this;
string tmp = str;
//swap的好处不仅在于把str进行深拷贝给*this,而且还把释放_str等数据清理的工作交给tmp,一石二鸟
std::swap(_str, tmp._str);
std::swap(_size, tmp._size);
std::swap(_capacity, tmp._capacity);
return *this;
}
//封装swap,进一步优化
void swap(string& s) {
std::swap(_str, s._str);
std::swap(_size, s._size);
std::swap(_capacity, s._capacity);
}
//优化版本1
string& operator=(const string& str) {
if (this == &str)
return *this;//防止自赋值
string tmp(str);
swap(tmp);
return *this;
}
//优化版本2
string& operator=(string tmp) {//传值传参,此时进行反自赋值需要进行成员变量的比较,有那个时间,早就swap完了
swap(tmp);
return *this;
}不能复用算法库里的swap实现赋值
cpp
string& operator=(const string& str) {
cout << "赋值" << endl;
if (this == &str)
return *this;//防止自赋值
string tmp(str);
std::swap(tmp,*this);//会引发无穷递归,因为algorithm实现swap(a, b)是先把a拷贝构造给c,接着a=b, b=c,而在a=b的时候会调用swap,
//swap又会调用赋值,赋值又会调用swap,直到栈放不下了,溢出,程序异常结束
return *this;
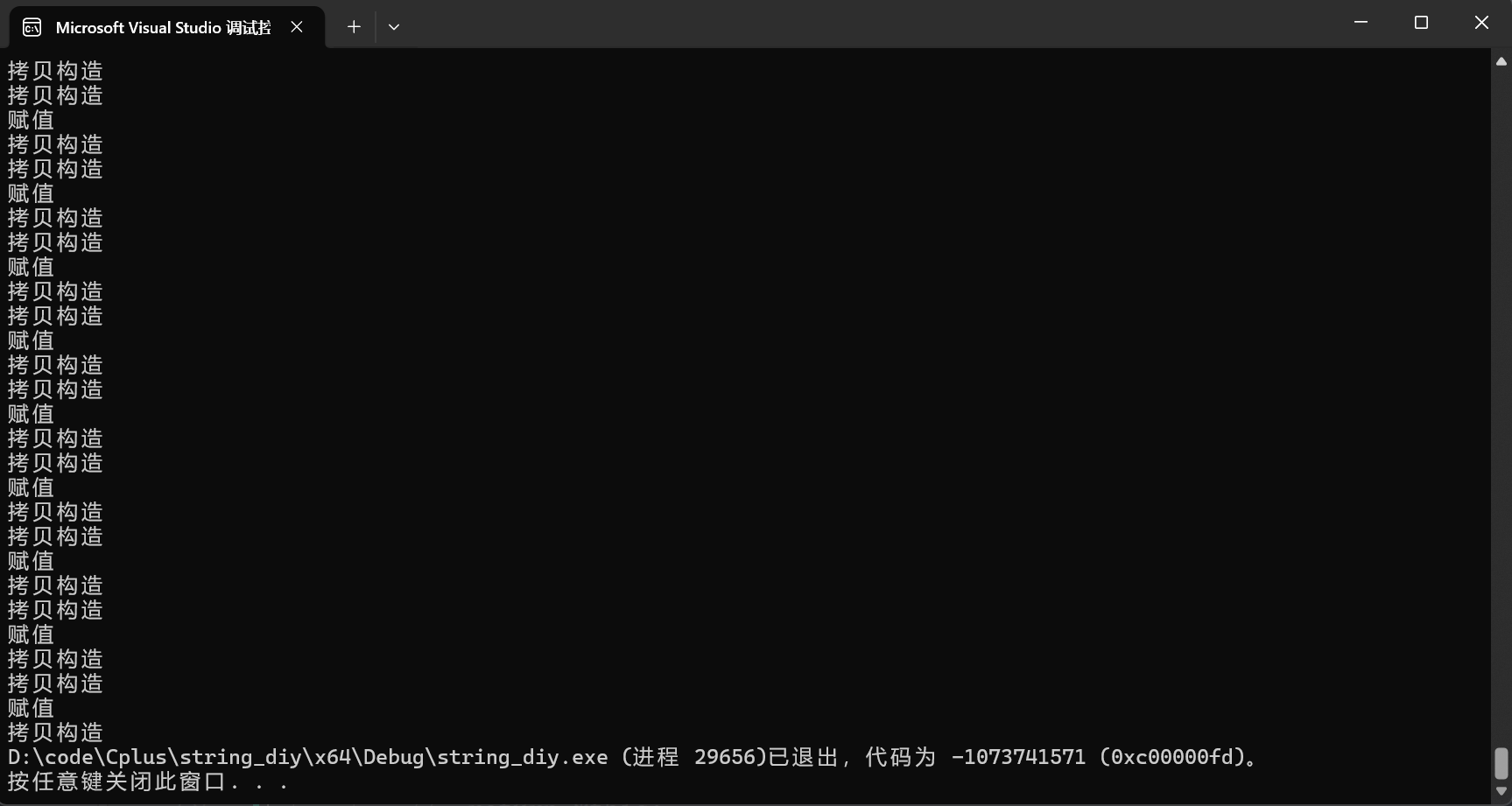
}尝试每次调用赋值或者拷贝构造就打印,结果如下(每打印两次拷贝构造之后打印一次赋值,是因为string tmp(str);还有一次构造)
2.函数
2.1 迭代器
cpp
//迭代器
typedef char* iterator;
iterator begin() {
return _str;
}
iterator end() {
return _str+_size;
}
typedef const char* const_iterator;
const_iterator begin() const{//迭代器包括普通对象和const对象的,一般情况下,普通对象既可以调普通对象也可以掉const对象的函数,但如果有普通对象的,会走最匹配的
return _str;
}
const_iterator end()const {
return _str + _size;
}
const char* c_str() const{
return _str;
}迭代器应用:范围for
范围for编译器自动替换为迭代器,但是自行实现string时begin和end函数命名要和库里实现的一致,否则即使是End正确实现,也没办法实现迭代
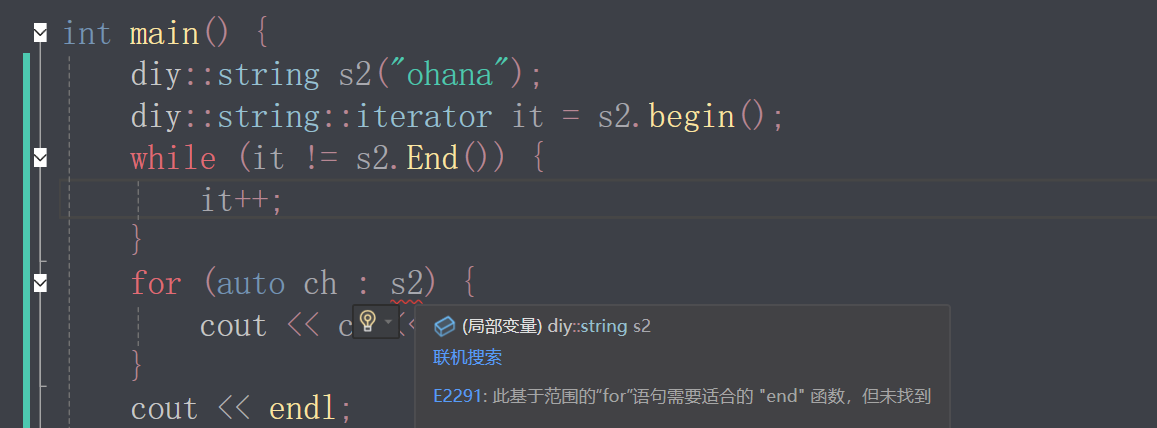
2.2 insert
我们看到当pos为零,出现了异常;
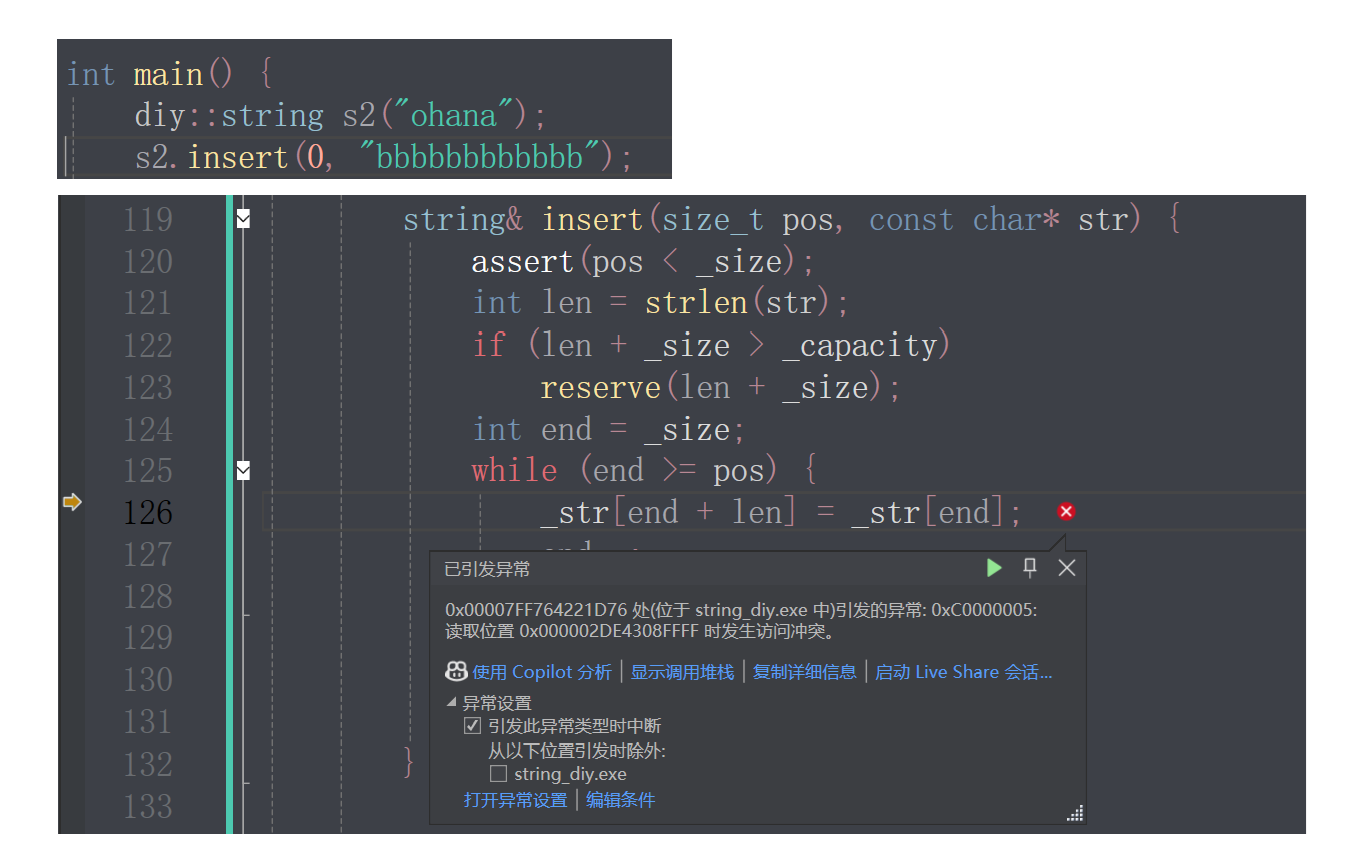
调试发现,当end为-1时,进入了循环体,但是循环条件是end>=pos,逻辑上说不应该进入;这是因为发生了整型提升,在两个不同类型数据进行比较的时候,会进行整型提升,一般范围小向范围大的类型提升,size_t和int进行比较,int提升为size_t,-1的补码是全1,是size_t的最大值,循环条件始终成立
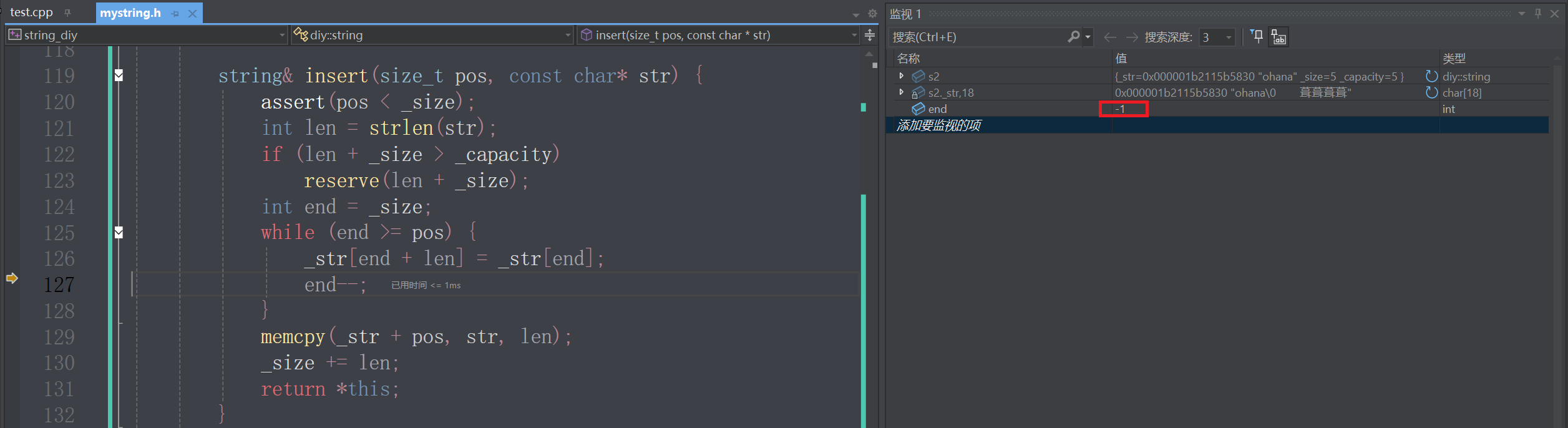
如何解决呢?
cpp
string& insert(size_t pos, const char* str) {
assert(pos < _size);
int len = strlen(str);
if (len + _size > _capacity)
reserve(len + _size);
int end = _size;
while (end >= (int)pos) {//比较时进行强转
_str[end + len] = _str[end];
end--;
}
memcpy(_str + pos, str, len);
_size += len;
return *this;
}
cpp
string& insert(size_t pos, const char* str) {
assert(pos < _size);
int len = strlen(str);
if (len + _size > _capacity)
reserve(len + _size);
size_t end = _size;
while (end >= pos && end!=npos) {//避免end为-1时进入循环
_str[end + len] = _str[end];
end--;
}
memcpy(_str + pos, str, len);
_size += len;
return *this;
}这个地方用到了npos,注意事项简要说明如下
const static size_t/int/long/long long/char类型可以在类内直接定义,但double, long double, float不可以,只能在类内声明,类外定义;推荐做法是统一进行类内声明,类外定义
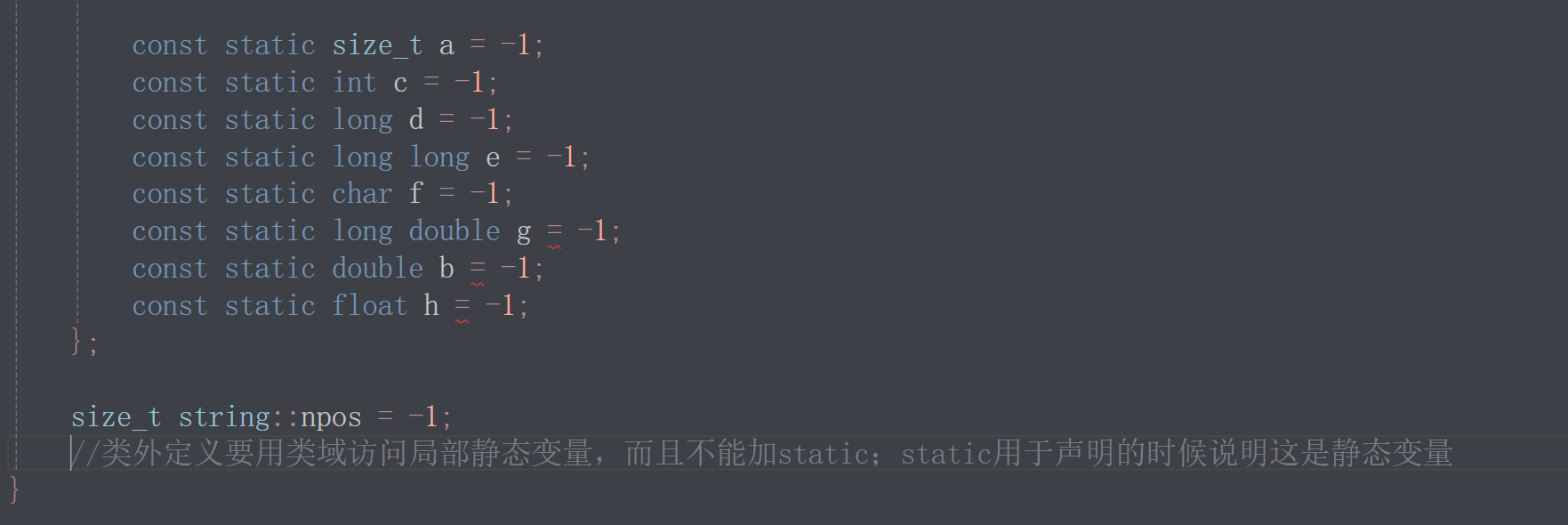
我们看到npos赋值给到-1,因为-1的机器码是全1,以size_t类型存储的全1机器码是size_t所能表示的最大值

cpp
//插入n个字符ch的情况
string& insert(size_t pos, size_t n, char ch) {
assert(pos <= _size);
if(n==0) return *this;//避免无意义的判断和循环
if (n + _size > _capacity)
reserve(n + _size);
size_t end = _size;//连'\0'一起挪
while (end >= pos && end != npos) {
_str[end + n] = _str[end];
end--;
}
for (size_t i = 0; i < n; i++)
_str[pos + i] = ch;
/*memset(_str + pos, ch, n);适用于char类型的ch,不适用wchar_t 字符*/
_size += n;
return *this;
}2.3 +=
cpp
string& push_back(char ch) {
if (_size + 1 > _capacity)
reserve(_capacity == 0 ? 4 : 2 * _capacity);//如果_capacity为零,就适当开4个空间,否则就2倍扩容
_str[_size++] = ch;
_str[_size] = '\0';
return *this;
}
string& append(size_t n, char ch) {
if(n==0) return *this;
size_t len = _size + n;
if (len > _capacity)
reserve(len);
for (size_t i = 0; i < n; i++)
_str[_size + i] = ch;
/*memset(_str + _size, ch, n * sizeof(ch)); 适用于char类型的ch,不适用wchar_t 字符*/
_size += n;
_str[_size] = '\0';
return *this;
}
string& append(const char* str) {
if (str == nullptr) str = "";
size_t len = strlen(str);
if (len+_size > _capacity)
reserve(len+_size);
strcpy(_str + _size, str);//memcpy(_str+_size, str, len+1);
_size += len;
return *this;
}
string& operator+=(const char* str) {
append(str);
return *this;
}
string& operator+=(char ch) {
push_back(ch);
return *this;
}我们看到+=复用了拷贝构造,那么拷贝构造可以复用字符串构造,
cpp
string(const string& s):{
string tmp(s._str);
swap(tmp);
}测试
cpp
int main() {
diy::string s1("she is aiming too high");
diy::string s2(s1);
diy::string s3 = ("we are here just to celebrate");
s3 = s1;
cout << s1 << endl;
return 0;
}因为默认初始化内置变量不进行处理
s1拷贝构造s2的时候,this进行初始化

s3=s1,s1传参的时候要进行拷贝构造,此时this也初始化(VS2019没有,会崩溃)

但是标准没有要求,是编译器个性化行为,不要依赖编译器的初始化,一个平台能跑的代码换个平台就不一定能跑,不利于写作和推广
有可能编译器不进行内置变量处理,是随机值,访问野指针,崩溃
delete或free空指针不会出问题,因为有检查机制,如果不放心,可以在析构加判断条件,毕竟析构空指针没啥意义
所以推荐在初始化列表初始化
cpp
string(const string& s):
_str(nullptr),
_size(0),
_capacity(0)
{
string tmp(s._str);
swap(tmp);
}但是这样处理,如果string对象有\0作为有效数据,就会出现\0之后的数据丢失,所以还是有风险
2.4 reverse
cpp
void reserve(size_t n=0) {
//只扩容,缩容或容量不变不做处理
if (n > _capacity) {
char* tmp = new char[n + 1];//n个可用空间,多开一个末尾是'\0'
memcpy(tmp, _str, _size+1);//strcpy(tmp, _str);有缺陷
delete[] _str;
_str = tmp;
_capacity = n;
}
}2.5 erase
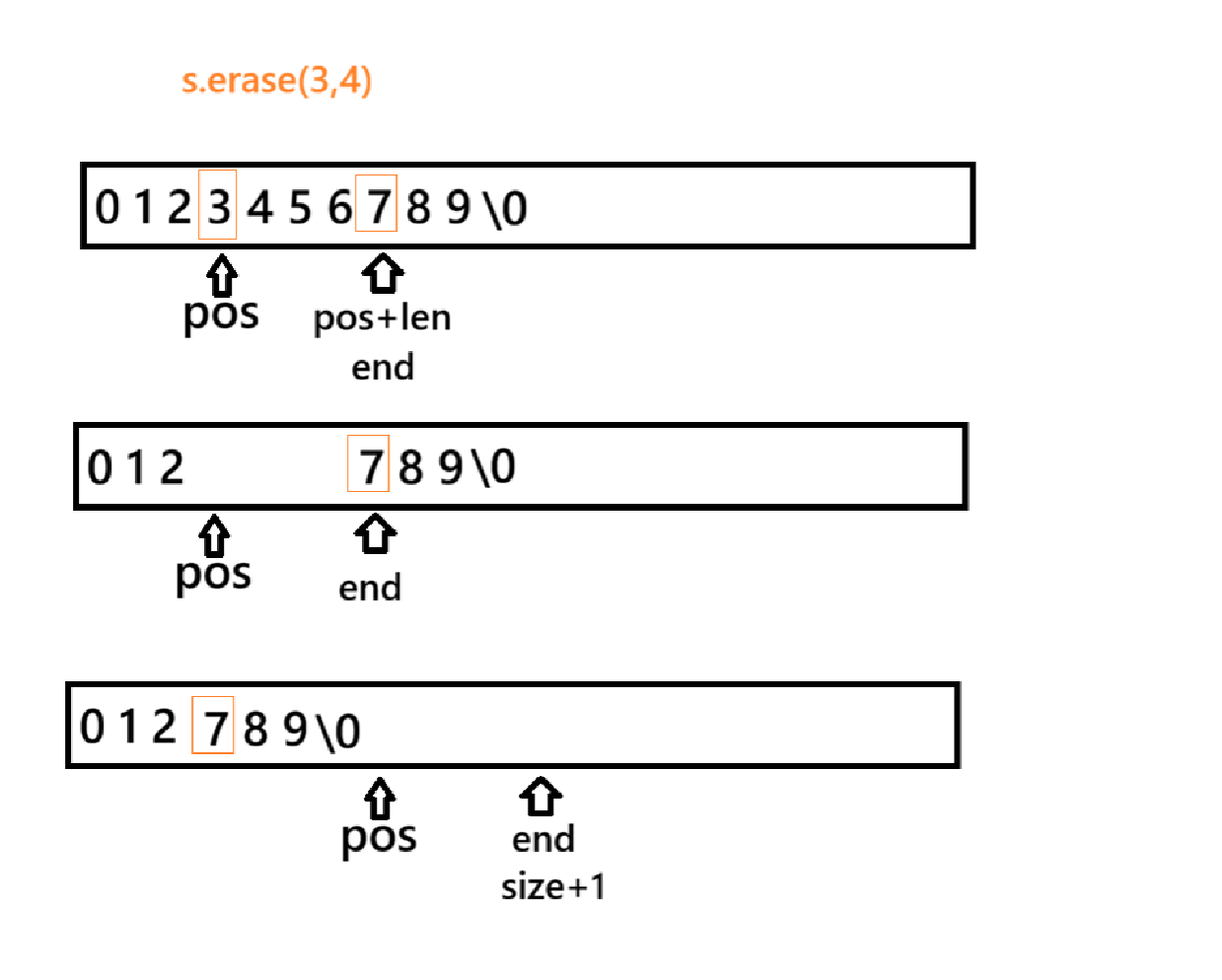
cpp
string& erase(size_t pos = 0, size_t len = npos) {
assert(pos <= _size);
if(len==0) return *this;
if (len == npos || len + pos > _size) {//pos位置开始全部抹除
_size = pos;
_str[_size] = '\0';
}
else {
size_t end = pos + len;
while (end <= _size) // \0也拷
_str[pos++] = _str[end++];
_size -= len;
}
return *this;
}2.6 find
cpp
size_t find(char ch, size_t pos = 0) {
assert(pos < _size);
for (size_t i = pos; i < _size; i++) {
if (_str[i] == ch)
return i;
}
return npos;
}
size_t find(const char* str, size_t pos = 0) {
assert(pos < _size);
const char* ptr = strstr(_str + pos, str);
//这个地方暴力匹配,因为只是简单实现,kmp名声在外,但其实库里实现strstr用的并不是kmp(预处理成本高),而是BM
if (ptr)
return ptr - _str;
else
return npos;
}
2.7 substr
cpp
string substr(size_t pos = 0, size_t len = npos) {
assert(pos < _size);
if (len == npos || pos + len > _size)
len = _size - pos;//如果没有给len,默认截取到最后一个有效字符;亦或是截取字符数量超过从pos开始的有效字符数量,也默认截取到最后一个字符
string tmp;
tmp.reserve(len);
/*memcpy(tmp._str, c_str() + pos, len);
tmp._size=len;
tmp._str[tmp._size] = '\0';*/
for (size_t i = pos; i < pos + len; i++)
tmp += _str[i];//+=会修改_size,而且_size位置一直都有'\0'
return tmp;
}2.8 判断函数
不能用strcmp,因为遇到\0就停止比较,\0的ascii值虽然是0,可是首先C string末尾的'\0'并不是有效字符,不能参与比较;其次,unicode编码汉字读取出来的编码一般是负的;因为string对象的有效字符可以是'\0'
2.8.1 operator<
cpp
//手动挡
bool operator<(const string& s) {
int i1 = 0, i2 = 0,len1=_size,len2=s._size;
while (i1 < len1 && i2 < len2) {
if (_str[i1] < s._str[i2])
return true;
else if (_str[i1] > s[i2])
return false;
else {
++i1;
++i2;
}
}
/*int len = _size < s._size ? _size : s._size;
for (int i = 0; i < len; i++) {
if (_str[i1] < s._str[i2])
return true;
else if (_str[i1] > s[i2])
return false;
}*/ //功能上一致
//前面都相等
//i1==len1 i2<len2 true
//i1==len1 i2==len2 false
//i1<len1 i2==len2 false
if (i1 == len1 && i2 < len2)
return true;
else if (i1 == len1 && i2 == len2)
return false;
else if (i1 < len1 && i2 == len2)
return false;
}
cpp
//自动挡 学会复用
bool operator<(const string& s) {
int ret = memcmp(_str, s._str, _size < s._size ? _size : s._size);
//helloxxx hello false
//hello helloxxx true
//hello hello false
return ret == 0 ? _size < s._size : ret < 0;
//return ret<0 || (ret == 0 && _size < s._size);
}2.8.2 operator==
cpp
bool operator==(const string& s) {
int ret = memcmp(_str, s._str, _size < s._size ? _size : s._size);
return ret == 0 && _size == s._size;
}
cpp
//复用,> = <存在天然的互斥关系
bool operator<=(const string& s) {
return *this == s || *this < s;
}
bool operator>(const string& s) {
return !(*this <= s);
}
bool operator>=(const string& s) {
return *this==s || *this>s;
}2.9 resize
cpp
void resize(size_t n, char ch = '\0') {
if (n <= _size) {
_size = n;
_str[_size] = '\0';
}
else {
reserve(n);
for (size_t i = 0; i < n; i++)
_str[_size + i] = ch;
_str[_size] = '\0';
_size = n;
}
//下面逻辑可以合成上面的else,reverse只扩不缩,后两种情况处理基本一致
//else if (n <= _capacity) {//不需扩容,需插入
// for (size_t i = 0; i < n; i++)
// _str[_size + i] = ch;
// _str[_size] = '\0';
// _size = n;
//}
//else {//n > _capacity 需扩容、插入
// reserve(n);
// for (size_t i = _size; i < n; i++)
// _str[i] = ch;
// _str[_size] = '\0';
// _size = n;
//}
}2.10 << 流插入
不能定义为成员函数,因为成员函数默认第一个参数是this指针,但是流插入和流提取第一个参数是流对象
cpp
//友元
namespace diy {
class string {
public:
...
friend std::ostream& operator<<(std::ostream& out, const diy::string& str);
private:
...
};
ostream& operator<<(ostream& out, const string& str) {
for (size_t i = 0; i < str._size; i++)
out << str[i];
return out;
}
//范围for
namespace diy {
class string {
public:
...
private:
...
};
ostream& operator<<(ostream& out, const diy::string& str) {//流插入对象必须传引用,无论是传参还是返回值,因为有防拷贝机制
for (auto ch : str)
out << ch;
//不可以写成out<<str.c_str(); 因为C string是以\0为结束标志,但string有效字符可以是\0
return out;
}ostream构造的防拷贝
VS2022 \0不会显示打印,13一般会,实现方式可能不完全相同
cpp
int main() {
diy::string s1("she is aiming too high");
s1 += '\0';
s1 += "i staying up all night";
cout << s1 << endl;
return 0;
}
2.11 >> 流提取
diy命名空间内,string类外定义,这样写是读不到空格或换行的,会阻塞,就是输入空格和换行系统会一直阻塞,不动了,因为默认流提取是以空格或换行做多组输入的区分;读不到空格或换行,循环没法终止
cpp
istream& operator>>(istream& in, string& str) {
char ch;
in >> ch;
while (ch != ' ' && ch != '\n') {
str += ch;
in >> ch;
}
return in;
}使用get()解决这个问题,会把空格或换行当做有效字符,从而跳出循环
cpp
istream& operator>>(istream& in, string& str) {
char ch = in.get();
str.clear();//和std中string的>>保持一致
while(ch==' ' || ch=='\n')//清除前置空格或换行
ch = in.get();
while (ch != ' ' && ch != '\n') {
str += ch;
ch = in.get();
}
return in;
}我们看到此时系统能读空格
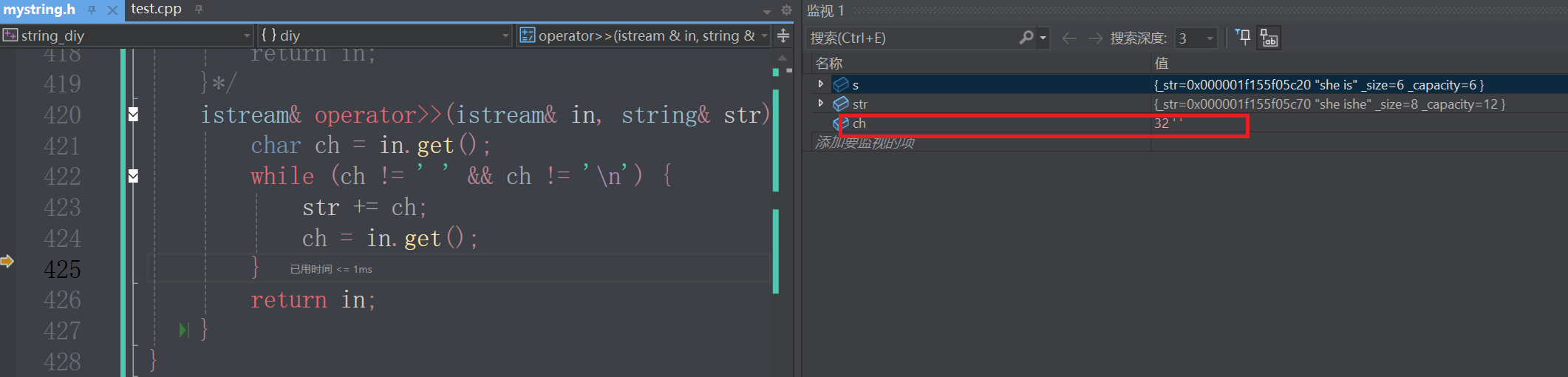
但如果插入字符数量较大,就会出现频繁扩容
cpp
int main() {
diy::string s("she is");
cin >> s;
cout << s << endl;
return 0;
}
cpp
istream& operator>>(istream& in, string& str) {
str.clear();
str.reserve(128);//如果这样处理,万一是提取的字符数量很少,很浪费
...
}开一个数组,因为是在栈上,函数调用结束即销毁,每提取127个字符才放入str,减少扩容带来的消耗
cpp
istream& operator>>(istream& in, string& str) {
str.clear();
char ch = in.get();
while(ch==' ' || ch=='\n')//清除前置空格或换行
ch = in.get();
char buff[128];
int i = 0;
//开始提取有效字符
while (ch != ' ' && ch != '\n') {
buff[i++] = ch;
if (i == 127) {
buff[i] = '\0';
str += buff;
i = 0;
}
ch = in.get();//提取下一个字符
}
//如果还有数据
if (i != 0) {
buff[i] = '\0';
str += buff;
}
return in;
}简单一些的
cpp
#pragma once
#define _CRT_SECURE_NO_WARNINGS 1
#include <iostream>
#include <string>
#include <assert.h>
using namespace std;
namespace diy {//在命名空间域内进行实现的好处是方便和库里函数效果进行对比,换一下变量的命名空间域就可以自由切换std和diy
class string {
public:
friend std::ostream& operator<<(std::ostream& out, const diy::string& str);
//size
size_t size() const {
return _size;
}
//[ ]
char& operator[](size_t pos) {
assert(pos < _size);
return _str[pos];
}
const char& operator[](size_t pos)const {
assert(pos < _size);
return _str[pos];
}
void clear() {
_size = 0;
_str[_size] = '\0';
}
//析构
~string() {
delete[] _str;
_str = nullptr;
_size = _capacity = 0;
}
static size_t npos;
private:
char* _str;
size_t _size;
size_t _capacity;
};
size_t string::npos = -1;
//类外定义要用类域访问局部静态变量,而且不能加static;static用于声明的时候说明这是静态变量
}进行网址的协议、域名、资源分割
cpp
#include "mystring.h"
void Divide(diy::string& url1) {
size_t pos1 = url1.find("://");
if (pos1 != diy::string::npos) {
diy::string protocol = url1.substr(0, pos1);//这个地方本来是substr传值返回,tmp复制给临时变量,再拷贝构造给protocol
//(这个地方是=,但逻辑上是初始化,所以是拷贝构造),但编译器会优化,直接用tmp拷贝构造给protocol
//但是此tmp并非局部变量,因为出了作用域,局部变量就销毁了,而是一个临时变量,具有常性,所以substr的参数应是const string&,
//如果是string&,没有办法绑定
cout << protocol.c_str() << endl;
size_t pos2 = url1.find("/", pos1 + 3);
if (pos2 != diy::string::npos) {
diy::string domain = url1.substr(pos1 + 3, pos2 - (pos1 + 3));
cout << domain.c_str() << endl;
}
diy::string uri = url1.substr(pos2 + 1);
cout << uri.c_str() << endl;
}
}
int main() {
diy::string s="https://www.doubao.com/chat/36615120415948290";
Divide(s);
return 0;
}3.知识扩展
3.1 写时拷贝
cpp
int main() {
string s1("she is aiming too high");
string s2(s1);
return 0;
}有的时候可能只是进行拷贝或者对拷贝后的数据进行读取,不做修改,因为深拷贝代价比较大,于是有些地方会进行浅拷贝,如下图所示,问题在于
1.两次析构
2.一个修改影响另一个

如何解决呢?引入引用计数(Linux内核、智能指针等都会涉及),如果s2进行析构,这片空间的引用计数-1,变为1,不为零,说明还有人在使用,不会释放这片空间,当s1进行析构,引用计数变为零,没有人使用这片空间,释放;
那么相互影响的问题呢?在使用的时候进行深拷贝,谁用谁拷贝,比如s2要修改这片数据,s2先深拷贝,之后这片空间的引用计数-1,而且s2指向的空间也会维护它的引用计数。
Linux下
(以及Linux下printf不在iostream中,VS下在)
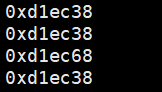
VS下没有玩这一套,输出结果不同
cpp
int main() {
string s1("she is aiming too high");
string s2("Lingua franca");
printf("%p\n", s1.c_str());//不能用cout,直接识别为字符串
printf("%p\n", s2.c_str());
return 0;
}3.2 VS下string的大小
cpp
int main() {
string s1("she is aiming too high");
cout << sizeof(s1) << endl;
return 0;
}输出28,32位下指针4B,size_t4B,按理来说是12B

因为VS下默认认为string的字符串都很短,预留了16字节的空间,如果string有效字符<16,那么直接存在buf数组中,不去堆上开辟空间
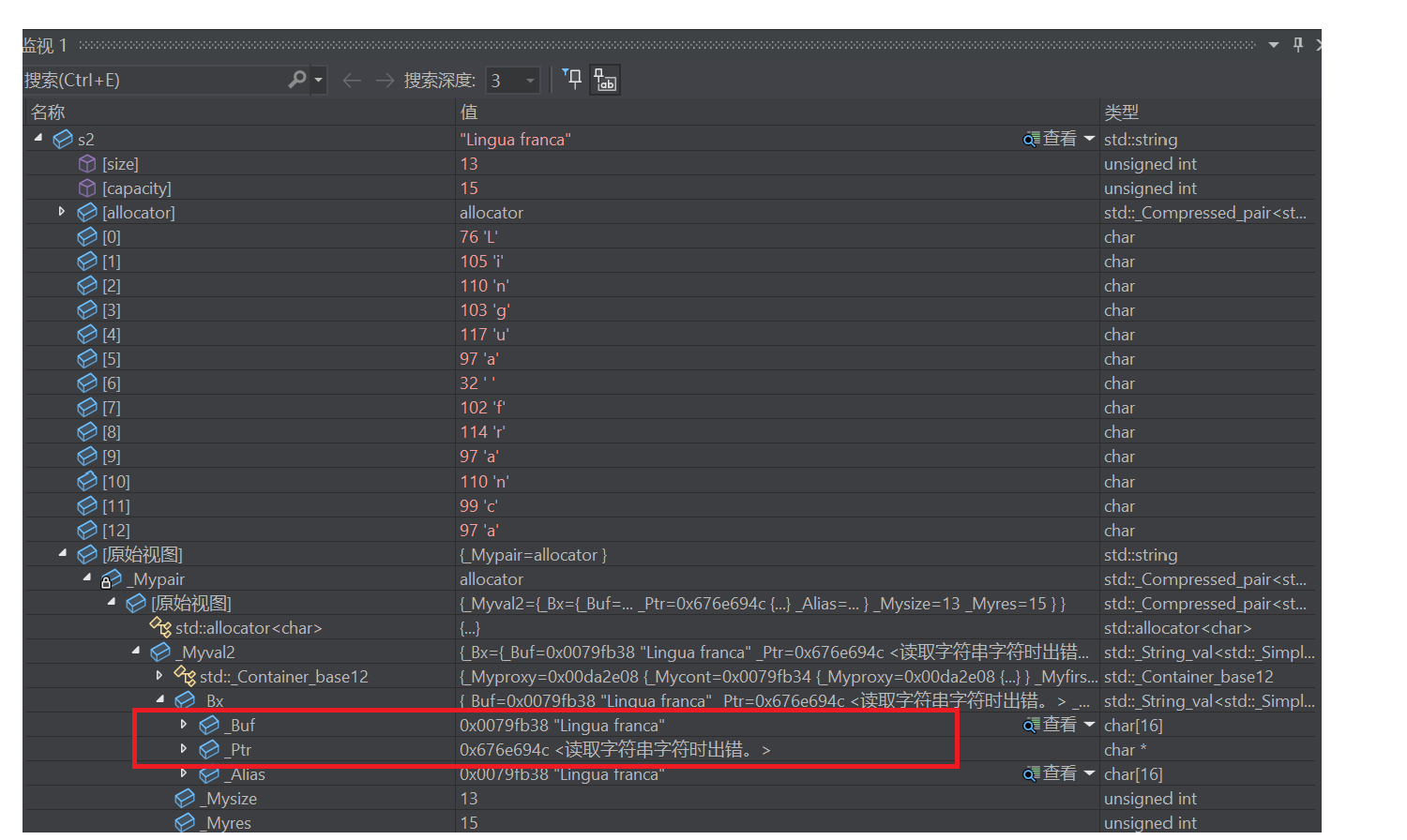
但如果>=16,去堆上开辟空间,buf浪费
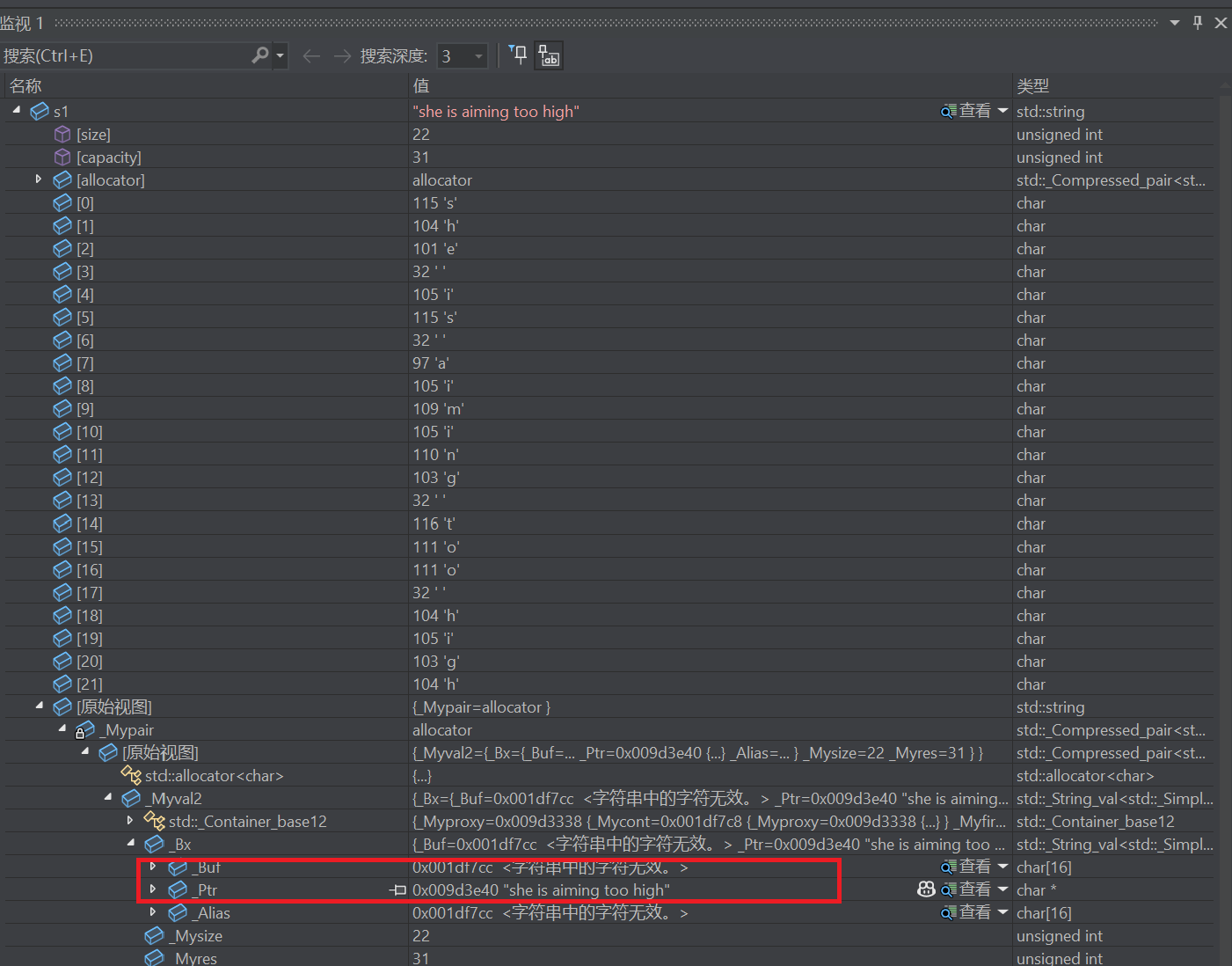
本质是空间换时间