RPA需求:PDF文件合并
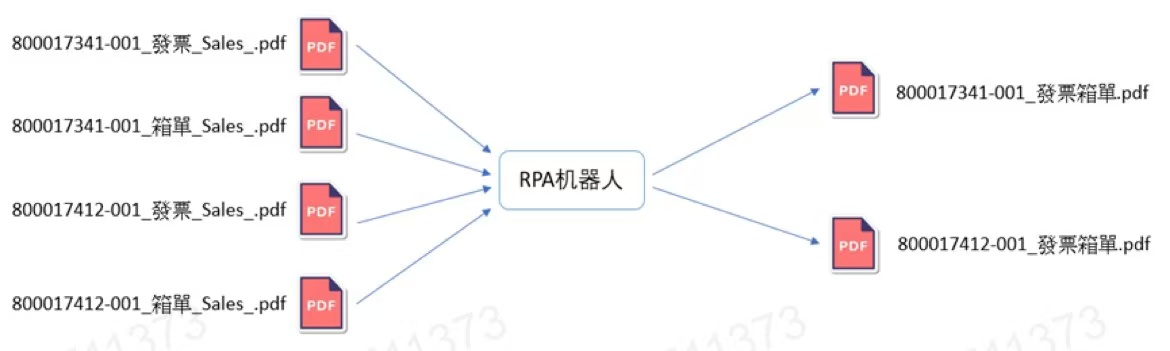
场景说明:根据文件前缀数字编号分组划分,发票在前,箱单在后,进行PDF文件合并操作
RPA功能
1.发票在前,箱单在后,根据文件前缀数字编号分组划分进行PDF文件合并操作
2.RPA仅对未合并的PDF文件执行合并操作,已合并的文件将被自动筛选并排除
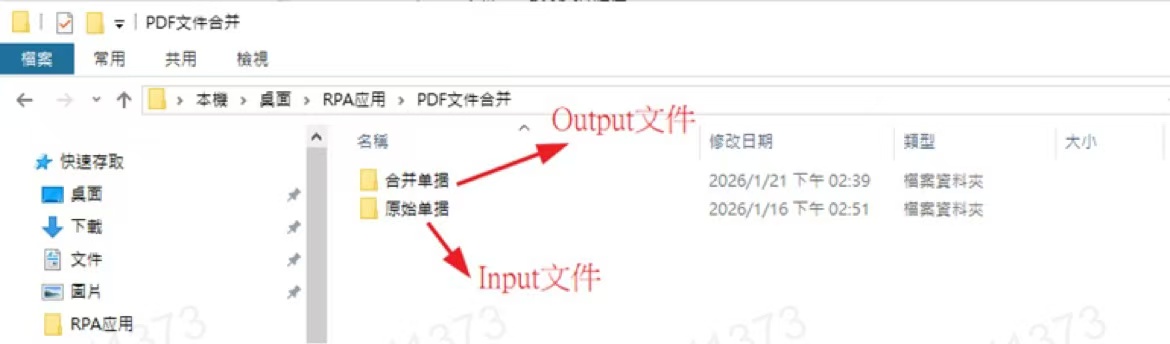
其中PDF文件存放位置如下所示:
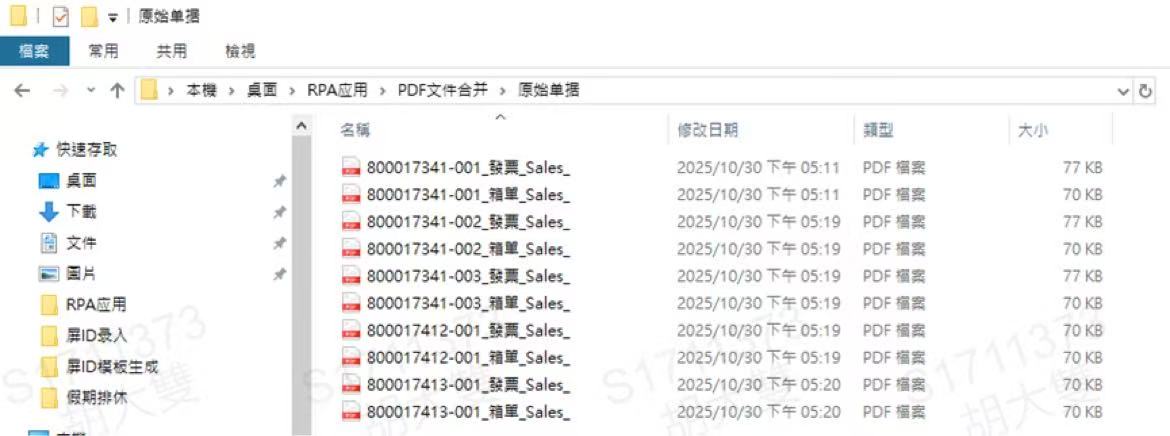
"原始单据"文件夹存放需要进行合并的PDF文档
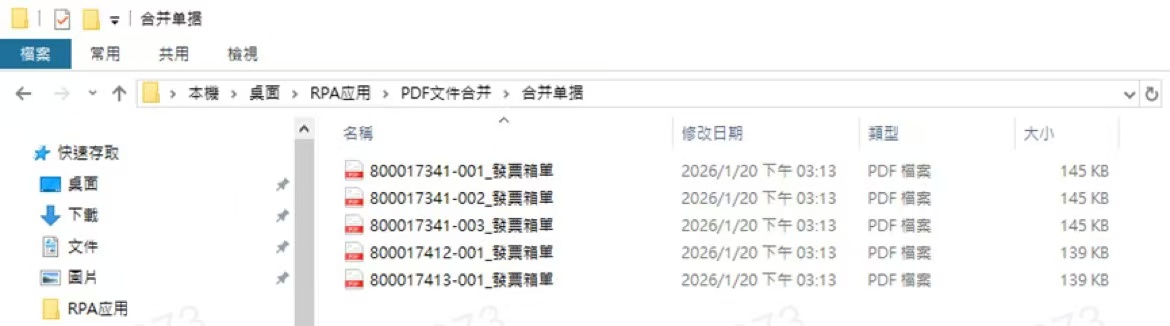
"合并单据"文件夹存放RPA处理合并后的PDF文档
RPA实现思路:
① 遍历循环"合并单据"文件路径中的pdf文件,获取文件名(带后缀名.pdf)存储在Python列表output_file_list
② 遍历循环"原始单据"文件路径中的pdf文件,获取文件名(带后缀名.pdf)存储在Python列表input_file_list
③ 使用Python代码实现以下逻辑
Step 1: 提取 output_file_list 中的所有前缀数字编号,例如"80017413-001"
Step 2: 筛选 input_file_list 中前缀数字编号不包含在Step1前缀数字编号中的文件,将其箱单和发票文件名(带后缀名.pdf)存储到Python列表filtered_input_list

④ 使用Python代码实现以下逻辑
依据 filtered_input_list 提供的文件名列表,在"原始单据"文件夹中定位所有目标PDF文件,提取每个文件名开头的数字编号作为分组依据,将同组文件合并为一个 PDF,将所有合并后的新PDF文件,统一保存至"合并单据"文件夹
搭建RPA的相关指令(仅供参考):
1.循环文件路径
2.获取文件属性
3.数组处理
4.Python脚本