目录
[1.1 if name == "main": 语句](#1.1 if name == "main": 语句)
[1.2 Argparse库的使用及创建参数解析器对象](#1.2 Argparse库的使用及创建参数解析器对象)
[2.1 name_or_flags - 参数名称或标志:](#2.1 name_or_flags - 参数名称或标志:)
[2.2 type - 参数类型](#2.2 type - 参数类型)
[2.3 required - 参数是否必须](#2.3 required - 参数是否必须)
[2.4 help - 帮助信息](#2.4 help - 帮助信息)
概要
作为初次学习使用Python脚本处理文件&执行代码,理解argparse库的用法并掌握一些基础指令。
Python脚本概念与结构
当我们创建一个 .py 文件时,通常会在其中导入特定的 Python 库,并调用其提供的方法。有时,我们也会根据需求自定义一些函数,与第三方库结合使用,以实现特定功能或进行研究。
在涉及多个自定义函数的场景中,如果这些函数日后可能被频繁复用,我们往往会考虑将它们组织成一个自定义 Python 库。这样便可以通过 import 语句随时引入并调用,提升代码的模块化和可维护性。
此时我们仍然处于交互式执行 Python 代码的阶段。而当我们希望某个 `.py 文件能够以"自动化"方式运行时,便可以将其进一步发展为 Python 脚本。这类脚本通常由自定义库演进而来,具备完整的执行逻辑,可实现重复、批量化任务的处理。
Python脚本构成
现在以一个简单的自定义库' script1.py'为例:
该库具备三个函数1.累计求和、2.指定字符串重复输出、3.输出最大值
python
"""
自定义工具库 - 包含三个简单功能函数
"""
def calculate_sum(numbers):
"""
计算列表中所有数字的和
Args:
numbers: 数字列表
Returns:
数字总和
"""
try:
return sum(numbers)
except TypeError:
print("错误:列表中包含非数字元素")
return None
def repeat_string(text, n):
"""
重复字符串指定次数
Args:
text: 要重复的字符串
n: 重复次数
Returns:
重复后的字符串
"""
if n < 0:
return ""
return text * n
def find_max(numbers):
"""
查找列表中的最大值
Args:
numbers: 数字列表
Returns:
列表中的最大值
"""
if not numbers:
print("警告:列表为空")
return None
return max(numbers)当我们需要使用上述函数时,我们需要将该库导入至.py文件 import script1 as s1
通过s1.find_max、s1.repeat_string来调用函数实现处理。
接下来我们将该自定义库转变成自动执行上述功能的python脚本:
python
def main():
"""主函数:解析参数并执行相应功能"""
import argparse
# 创建参数解析器对象
parser = argparse.ArgumentParser()
# 添加位置参数1
parser.add_argument(
"function",
choices=["sum", "max", "repeat"],help="选择要执行的功能:sum(求和), max(最大值), repeat(重复字符串)"
)
# 添加可选参数1
parser.add_argument(
"--numbers", type=str , help="输入数字列表,用逗号分隔(如:1, 2, 3, 4.5 )"
)
# 添加可选参数2
parser.add_argument(
"--text",
# required=True, # 该参数为必需参数
help="用于repeat功能的文本字符串(必需)"
)
# 添加可选参数3
parser.add_argument(
"--repeat",
type=int,
default=0, # 默认值为0
help="字符串重复次数(默认:0)"
)
# 解析参数
args = parser.parse_args()
# 根据选择的功能执行相应操作
print(f"执行功能: {args.function}")
if args.function == "sum":
# 解析数字字符串
numbers_list = list(map(float, (args.numbers).split(',')))
result = calculate_sum(numbers_list)
print(f"输入数字: {numbers_list}")
print(f"数字总和: {result}")
elif args.function == "max":
# 解析数字字符串
numbers_list = list(map(float, (args.numbers).split(',')))
result = find_max(numbers_list)
print(f"输入数字: {numbers_list}")
print(f"最大值: {result}")
elif args.function == "repeat":
if not args.text:
print("错误:repeat功能需要--text参数")
return
result = repeat_string(args.text, args.repeat)
print(f"文本: {args.text}")
print(f"重复次数(默认0): {args.repeat}")
print(f"结果: {result}")
print("=" * 40)
if __name__ == "__main__":
main()Python脚本细节
1.1 if name == "main": 语句
该语句是脚本运行不可或缺的一环,其中' name '是一个由 Python 运行时环境填充的特殊变量,其值会根据 Python 的执行方式而有所不同。当我们在终端调用命令行尝试执行某项脚本.py文件时,' name '会变成 ' main ' 此时if判断为True,遂执行下方主函数main(),(当然你也可以不精简成上述主函数,直接执行你想要的代码即可)。
而当该文件作为模块导入到另一个 Python 脚本中时,' name ' 会变成该文件的文件名,此时if判断为False,不执行主函数,故该文件仅作库被其他文件导入后调用方法。
1.2 Argparse库的使用及创建参数解析器对象
argparse作为python自带的工具库,能够处理携带参数的命令行。如果我们在执行python脚本时需要为某些变量赋值&传入文件,我们首先需要在脚本里导入argparse库,并调用该库的' .ArgumentParser() '方法,创建一个参数解析器对象。
接下来我们为解析器对象设定要解析的参数,需要使用' .add_argument() '方法:
python
parser.add_argument(
name_or_flags, # 参数名称或标志
action=None, # 参数动作类型
nargs=None, # 参数个数
const=None, # 某些动作的常量值
default=None, # 参数默认值
type=None, # 参数类型
choices=None, # 参数可选值范围
required=False, # 是否为必需参数
help=None, # 帮助信息
metavar=None, # 使用信息中显示的参数名称
dest=None # 解析后在结果中的属性名
)该方法能重复使用,为解析器对象设定多个参数,由于该方法结构涉及到多个参数设定,本文仅介绍常用设定。
2.1 name_or_flags - 参数名称或标志:
-
位置参数 :只有一个名称,如
"numbers"、"function" 位置参数设定后必须赋值 不可缺少,且顺序固定,如果在add_argument()第一&第二个参数设定为位置参数,则命令行里需严格遵守顺序,前两参数必须给位置参数赋值(由于可选参数存在不赋值情况,通常我们将位置参数靠前创建,避免与可选参数混淆)。 -
可选参数 :以
-或--开头的标志,如"--text" (长参数)、"-t" (短参数) 可选参数设定后灵活赋值,可以设定默认值,也可以不赋值。
python
# 位置参数示例
parser.add_argument("function", help="选择要执行的功能")
# 可选长参数
parser.add_argument("--text", help="文本字符串")
# 可选短参数+长参数 (相同表达)(常用缩写)
parser.add_argument("-t", "--text", help="文本字符串")2.2 type - 参数类型
为规范输入的变量值 我们需要设定输入参数类型如下:
python
# 基础类型转换 为3个长参数各自设定参数类型 输入变量值后会自动转换,如果输入不规范值会报错
parser.add_argument("--count", type=int) # 转换为整数
parser.add_argument("--price", type=float) # 转换为浮点数
parser.add_argument("--name", type=str) # 转换为字符串
# 自定义类型转换函数 为某些文件赋值参数设定文件格式
def valid_filename(filename):
if not filename.endswith('.txt'):
raise argparse.ArgumentTypeError("文件名必须以.txt结尾")
return filename
# 参数类型可以是基础数据类型 也可以是自定义的类型转换函数
parser.add_argument("--file", type=valid_filename)2.3 required - 参数是否必须
-
位置参数 :默认为
True(必须提供) -
可选参数 :默认为
False(可选提供)
python
# 必需的可选参数
parser.add_argument("--config", required=True, help="配置文件路径")
# 可选参数(可以不提供)
parser.add_argument("--verbose", action="store_true", help="详细模式")2.4 help - 帮助信息
python
parser.add_argument(
"--input",
help="输入文件路径,支持相对路径或绝对路径"
)
# 多行帮助信息
parser.add_argument(
"--output",
help="""
输出文件路径:
- 如不指定,则输出到标准输出
- 支持 .txt, .csv, .json 格式
"""
)创建好位置&可选参数后,我们还需要调用' .parse_args() '整合这些参数,返回一个argparse.Namespace对象,该对象具备的属性即为我们设定的参数,并且接下来我们通过调用该对象的属性来获取相应的输入的参数值
标准模式总结
-
参数创建 :
add_argument()定义了参数的名称、类型、默认值等 -
命令行赋值:在终端中运行程序时,用户为这些参数提供具体的值
-
对象封装 :
parse_args()将所有参数打包成一个Namespace对象 ' args = parser.parse_args() ' -
属性访问:每个参数都成为该对象的属性,用户提供的值就是属性的值
-
主函数使用 :在程序中通过 该对象args
.参数名直接访问这些值 -
参数名就是属性名 :
add_argument('--name')→args.name -
用户输入的值就是属性值 :命令行输入
--name Alice→args.name = 'Alice' -
类型自动转换 :如果定义了
type=int,命令行字符串会自动转换为整数 -
默认值处理 :如果用户没提供值,使用
add_argument中定义的默认值,可选参数在命令行未赋值时,Namespace对象仍然有这些属性
-
如果未设置
default参数 → 值为None -
如果设置了
default=None→ 值为None -
如果设置了其他默认值 → 值为该默认值
测试脚本运行
理解上述参数介绍并配置好脚本,接下来我们尝试运行。
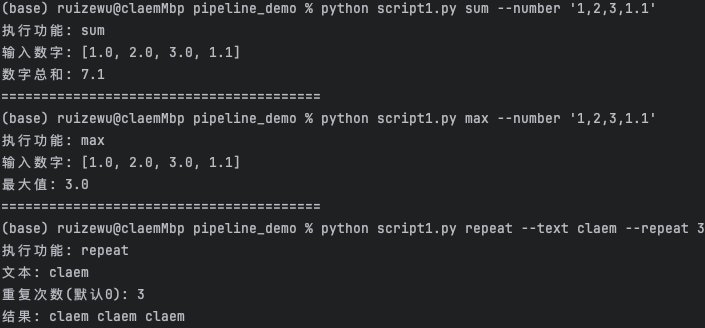
完毕~