
正文共: 1662字 9图
预计阅读时间: 5分钟
小程序上新110组素材

继Vibedebugging之后,再次体验到VibeDesign的痛苦。
今天花了整整一半天的时间,给「猜对了么」小程序上新110组素材。目前猜对了么已经更新到210关,你能通关成功吗?
「猜对了么」是一个谐音梗看图猜词小程序,大概是下面这个意思。

图片的上半部分是原图(名词词根),下半部分是谐音图(词根+修饰)。
比如上图这个,应该比较容易get。谜面是两个德国人,谜底是四字成语,你猜得出吗?
VibeDesign的过程

这个产品,Vibecoding的过程还算顺利。
第一轮素材生产(100组谐音梗看图猜词)也比较顺利,可能是运气比较好。
无论是生产文本素材(Geimini生产谐音梗),还是NanoBananaPro绘制图片素材,速度都比较快。
但是今天更新这110组,花了大概5-6个小时。
其中2-3个小时在和Gemini各种Battle,调教梗图约束。
还有一半时间在和Lovart各种掰扯,下午好大一会不听使唤,到了晚上速度才上来,准确率也基本拉满。

猜对了么目前的框架基本完善

无论是后台进行素材的快速更新、参数配置,还是关卡管理,用户数据。
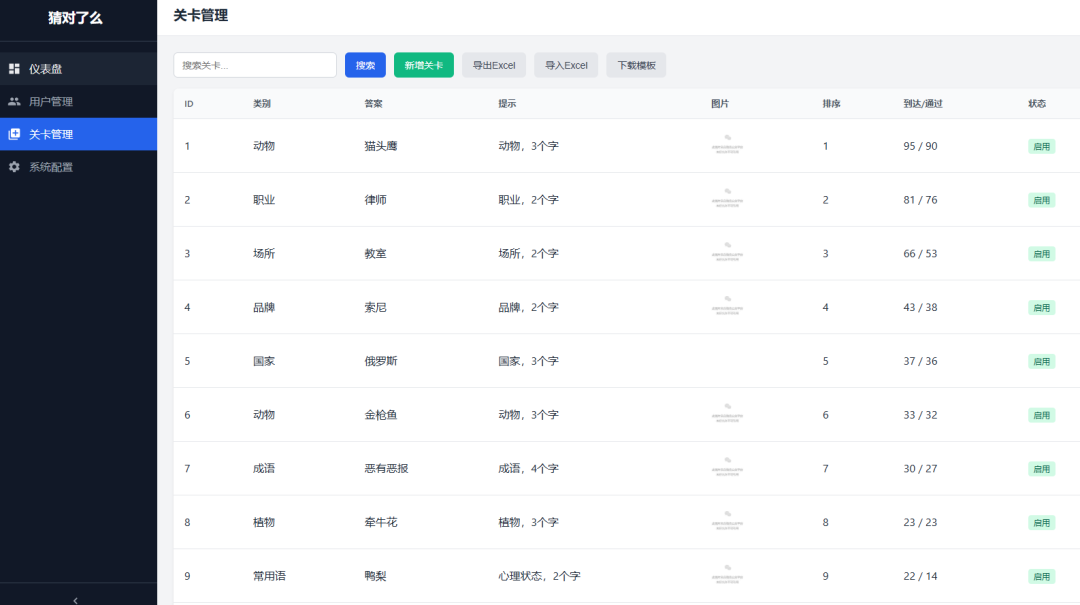
猜对了么后台支持通过Excel表格进行素材的快速录入。
素材目前存储在免费的图床,获取图片URL链接之后,连同谐音梗类别、谜底、提示词一并上传即可。
素材生产方面,使用Gemini或者其他大模型,通过以下提示词获取谐音梗部分的文本。
请参考以上具体谐音梗游戏的案例,基于我提供给你的不同类别,再输出100组谐音梗问题
以表格形式输出,表头包括:序号、谐音梗类别、谐音梗答案、提示内容、原图内容描述、谐音梗图内容描述;
其中:提示内容格式参考"xx类别,xx个字",比如"职业名称,2个字";
原图内容描述和谐音梗图内容描述格式保持统一,我要用于AI图像生成;或者直接获取Json格式文本也可以,便于导入Lovart进行画图作业。
其中,图片的核心逻辑是:
核心逻辑的修正
原图展示的物体应该是谐音梗答案中的**一个组成部分(字/词)**所对应的物体,而谐音梗图则是在这个原图物体上添加另一个谐音元素的特征。
"原图=名词词根,谐音图=词根+修饰"逻辑获取到文本内容之后,保存本地备用(用于将关卡信息上传到云端)。
之后再将谐音梗的文本内容丢给NanoBananaPro进行画图,这里根据个人情况选择工具。
如果考虑到效率和一致性,最好使用Lovart这类设计Agent调用NBP,可以起到很好的提效作用。
如果考虑到性价比,也可以使用吉优AI(geoAI)这类第三方AI大模型聚合站调用NBP,可以一站式使用Gemini、Claude、NanoBananaPro等AI大模型。
图片绘制使用的提示词约束可以参考下面的内容:
📋完整约束条件总结
1️⃣上半部分文案
使用"原图内容描述"中的内容
例如: "这是鹰"、"这是狮子"、"这是尼姑"等
2️⃣ 下半部分文案
使用"这是___"
下划线数量必须与"谐音梗答案"的字数完全一致
例如: "书包"(2字) → 2条下划线
例如: "猫头鹰"(3字) → 3条下划线
例如: "恶有恶报"(4字) → 4条下划线
3️⃣主体形象绘制
上半部分: 根据"原图内容描述"绘制
下半部分: 根据"谐音梗图"绘制
例如: 序号7上半部分是一只鳄鱼,下半部分是两只鳄鱼拥抱
4️⃣背景色
整张图片使用完全一致的纯色背景
柔和的马卡龙色调(浅蓝/奶油色等)
上下部分无缝衔接
5️⃣布局要求
无分割线、无分隔线、无明显界限
上下部分直接衔接,完全统一
纯色背景通透一致
6️⃣艺术风格
手绘Q版卡通风格
圆润线条,柔和色彩
统一的粗体黑字字体
7️⃣比例
竖版 3:4 比例获取到图片之后,按照约定格式把谐音梗类别、图片URL、谜底、提示词编辑到excel表格,上传后台即可。

目前带着答案的我,已经闯到156关了。
欢迎你也去试试,图一乐。

如果你能看到这里,非常感谢你的耐心阅读。
我会在「数字游民9527」这个账号,持续分享我探索AI的各种可能性,以及遇到的有意思的人和事儿。
欢迎成为我的精神股东,等我发达了,一定请你们一条龙。