欢迎来到计算机视觉的世界,在这里,计算机学会"看"懂并理解图像。想象一下,计算机不仅能识别物体,还能在它们周围画出精确的轮廓线------这就是图像分割的强大之处。
在当今这个技术驱动的时代,TensorFlow 这一机器学习工具已成为必不可少的存在。再配合 Python 语言的简洁性,我们便能通过一个有趣的项目来揭开图像分割的神秘面纱。
无论你是新手还是编程高手,本文都将是你的向导。在深入动手实践之前,让我们先花点时间了解图像分割的不同类型。

图像分割的类型:基础概念
- 语义分割(Semantic Segmentation):将图像中的每个像素分类到预定义的类别中。例如,在街景中,它会将每个像素标记为汽车、行人、道路或建筑物的一部分。其目标是理解场景的总体上下文,而无需区分不同的个体实例。
- 实例分割(Instance Segmentation):更进一步,它不仅为每个像素分配一个类别,还能精确地识别并勾勒出该类别中每个不同对象实例的边界。在一张拥挤的图片中,它能出色地区分出不同的人,即使他们属于同一类别,也能以极高的精度识别并勾勒出群体中的每一个人。
- 全景分割(Panoptic Segmentation):语义分割与实例分割的结合体。它不仅提供了对场景的详细语义理解,还分离了这些类别中的每个实例。此外,它还为背景指定了一个特殊类别,从而捕捉到整个视觉环境的整体视图。这就好比理解了一个场景的完整故事,既包括了主角,也包括了他们身后的背景。
既然我们已经了解了基础概念,让我们深入探讨实践部分。我们将重点关注语义分割,这是一种在像素级别上提供对图像详细理解的激动人心的技术。
到最后,你不仅会掌握理论知识,还可以使用 TensorFlow 和 Python 构建自己的语义分割模型。
图像分割的高层架构:拆解分析
在图像分割领域,我们遵循一种被称为encoder-decoder结构的高层架构。
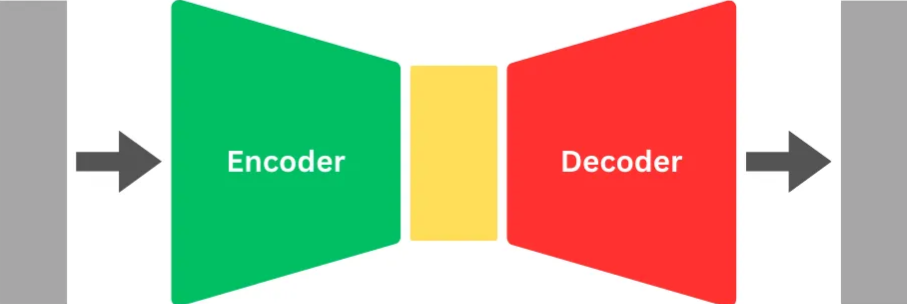
Encoder ------ 揭示特征
Encoder充当特征提取器,通常使用卷积神经网络(CNN)来实现。这一部分从图像中提取特征,形成我们所说的"feature map"。初始层专注于线条等低级特征,然后逐渐将它们聚合成眼睛和耳朵等更复杂的特征。这种聚合是通过下采样(downsampling)来实现的,类似于减少像素表示------就像你的视频聊天画面变得有点颗粒感,但你仍然可以通过那些关键特征认出你的朋友。
Decoder ------ 创造预测
现在,让我们转向Decoder。它的作用是获取这些提取出的特征并生成模型的输出或预测。和编码器一样,解码器也是一个卷积神经网络。它为缩小尺寸的特征图中的每个像素分配中间类别标签。然后,它开始进行上采样(upsampling)的复杂任务,逐渐恢复原始图像的精细细节。这个过程一直持续,直到图像恢复到其原始尺寸。
最后的修饰 ------ 像素级标签
最终的结果是一张像素级的标签图。每个像素都被分配了一个最终的类别标签,捕捉到了该像素在图像更广泛背景中所代表的本质。
简单来说,你可以把编码器想象成一名侦探,勤奋地从图像中提取线索(特征)。解码器则是讲故事的人,将这些线索拼凑起来,逐像素地揭示出完整的叙事。这种架构中编码器和解码器的配合,构成了图像分割算法的骨干,为我们提供了关于视觉数据的详细、像素级的洞察。
在本文中,我们将剖析用于语义分割的两个强大的架构:全卷积网络(FCN)和 U-Net。我们将与您一起深入探讨这些框架的核心,并使用 Python 和 TensorFlow 来实现并揭开它们的神秘面纱。我们将提供清晰、简洁的代码片段,并辅以富有见地的解释,以满足初学者和资深从业者的需求。准备好进行一次理论与实践相结合的动手探索,让您能够在项目中有效地利用 FCN 和 U-Net。无论您是好奇的爱好者还是经验丰富的开发者,本文都是您掌握语义分割的指南。
全卷积网络(FCN)
在传统的卷积神经网络(CNN)中,最后几层通常是全连接层,这意味着它们将每个神经元连接到其他的每个神经元。对于图像分类等任务来说,这没问题,因为在这些任务中空间信息并不那么关键。
然而,对于语义分割等任务,目标是将图像中的每个像素分类到特定的类别(例如,人、车、背景)中,保留空间信息至关重要。Long、Shelhamer 和 Darrell 在他们的论文《Fully Convolutional Neural Networks for Semantic Segmentation》中提出了全卷积神经网络(FCN)。FCN 通过用卷积层替换全连接层来解决这个问题。这使得网络可以接受任何大小的输入,并产生相应大小的输出。
在语义分割中,FCN 通过在整个网络中保留空间信息,实现了像素级的预测。网络学习将输入图像中的每个像素与特定类别相关联,从而生成详细的分割图。这对于计算机视觉应用特别有用,例如目标检测、场景理解和图像分割。
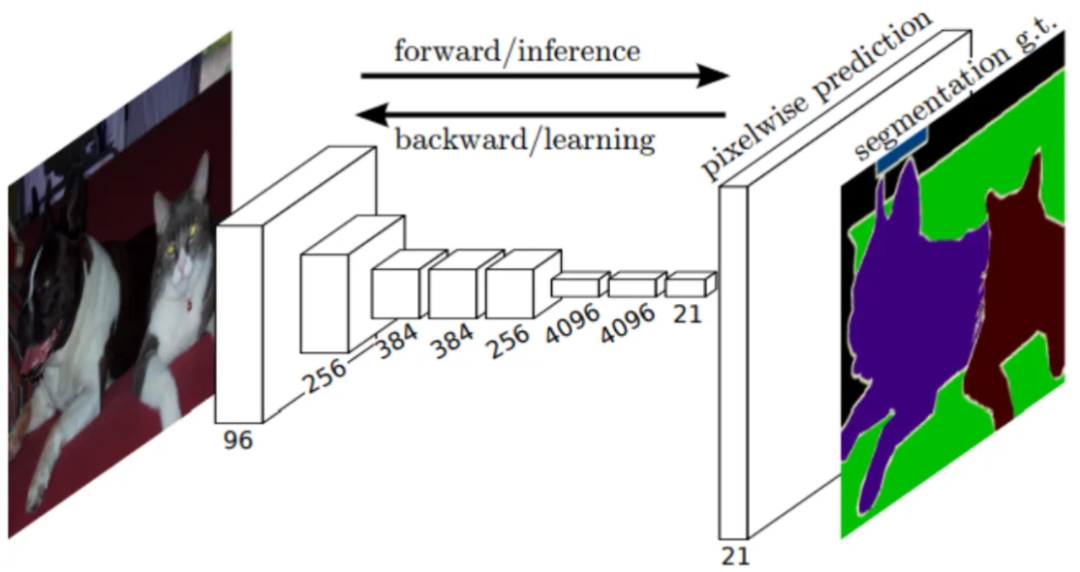
在继续探索全卷积网络(FCN)的过程中,让我们深入研究一下被称为 FCN-8、FCN-16 和 FCN-32 的变体。这些都是 FCN 架构的不同配置,各自拥有独特的特性。
FCN-8、FCN-16 和 FCN-32:配置解析
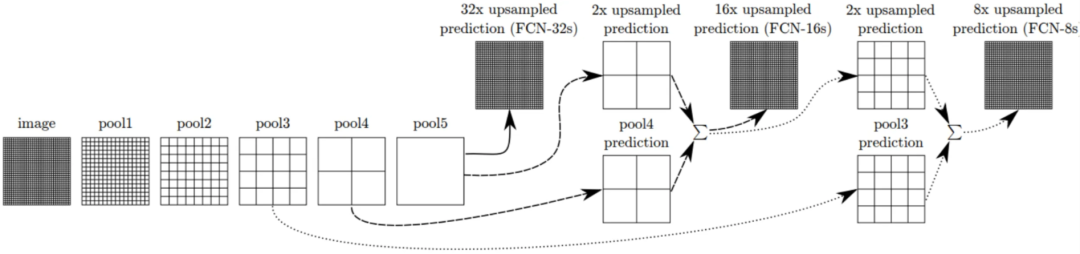
FCN-32
FCN-32 在最后一层采用了 32 像素的步幅,导致输出分辨率仅为输入的 1/32。这种配置优先考虑计算效率,而非详细的空间信息。FCN-32 在处理速度上更快,使其适用于对速度要求极高、而对精细分割细节要求不那么严格的场景。
FCN-8
FCN-8 指的是最后一层具有 8 像素步幅的全卷积网络。换句话说,最后一层产生的输出分辨率是输入分辨率的 1/8。这种配置能够实现更精细的预测,捕捉分割图中更细微的差别。FCN-8 的解码器涉及融合来自不同层(包括空间信息较粗糙的层)的预测结果。这种融合过程提升了整体的分割质量。
FCN-16
FCN-16 则是在最后一层采用了 16 像素的步幅。这意味着输出分辨率是输入分辨率的 1/16。虽然与 FCN-8 相比,FCN-16 牺牲了一些空间细节,但它在分辨率和计算效率之间取得了很好的平衡。中间层有助于最终的分割图,提供了精细细节和计算资源之间的折衷方案。
选择合适的配置
FCN-8 通过 8 像素的步幅实现详细预测,捕捉细微差别;FCN-16 通过 16 像素的步幅在分辨率和效率之间取得平衡;而 FCN-32 则通过 32 像素的步幅优先考虑计算效率。
这些配置之间的选择取决于项目需求。在接下来的内容中,我们将使用 TensorFlow 和 Python 来实现每一种配置,从而释放 FCN 变体在语义分割中的潜力。
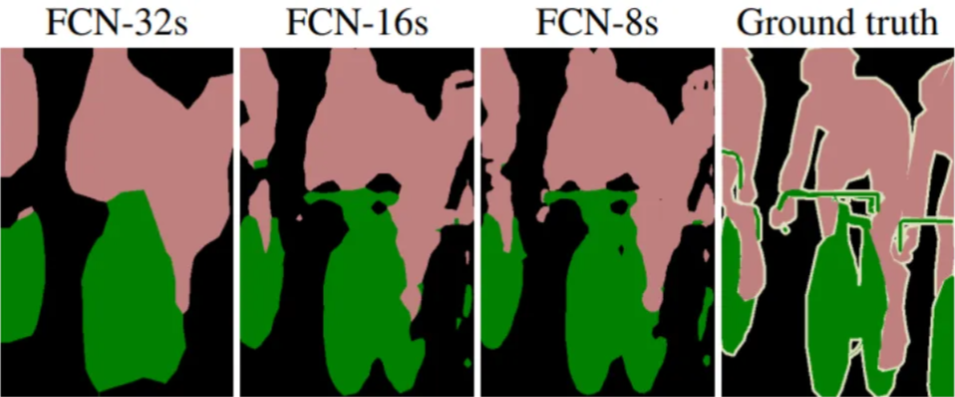
但这还不是全部------让我们通过结合迁移学习,利用 VGG16 或 ResNet 等预训练编码器,来为我们的 FCN 模型"超级充电"。这一变革性方法可以加速训练并提高准确性,尤其是在标记数据有限的情况下。
万字详解具身智能用的VLA:视觉-语言-动作模型(VLA)概述与Octo、OpenVLA、π0、GR00T N1等模型介绍
接下来是动手实践环节,我将提供代码片段和解释,提升您在计算机视觉领域的理解和熟练度。利用迁移学习的额外优势,释放 FCN-8、FCN-16 和 FCN-32 的全部潜力!
FCN-编码器:VGG16 迁移学习
VGG16(Visual Geometry Group 16)是一种著名的卷积神经网络,以其简单性和在图像分类中的高效性而闻名。它拥有统一的结构和 16 层,擅长学习分层特征。在我们的 FCN-编码器中,我们将利用 VGG16 进行迁移学习,利用其预训练权重来增强语义分割任务中的特征提取能力。以下是获取 VGG-16 预训练权重的链接。
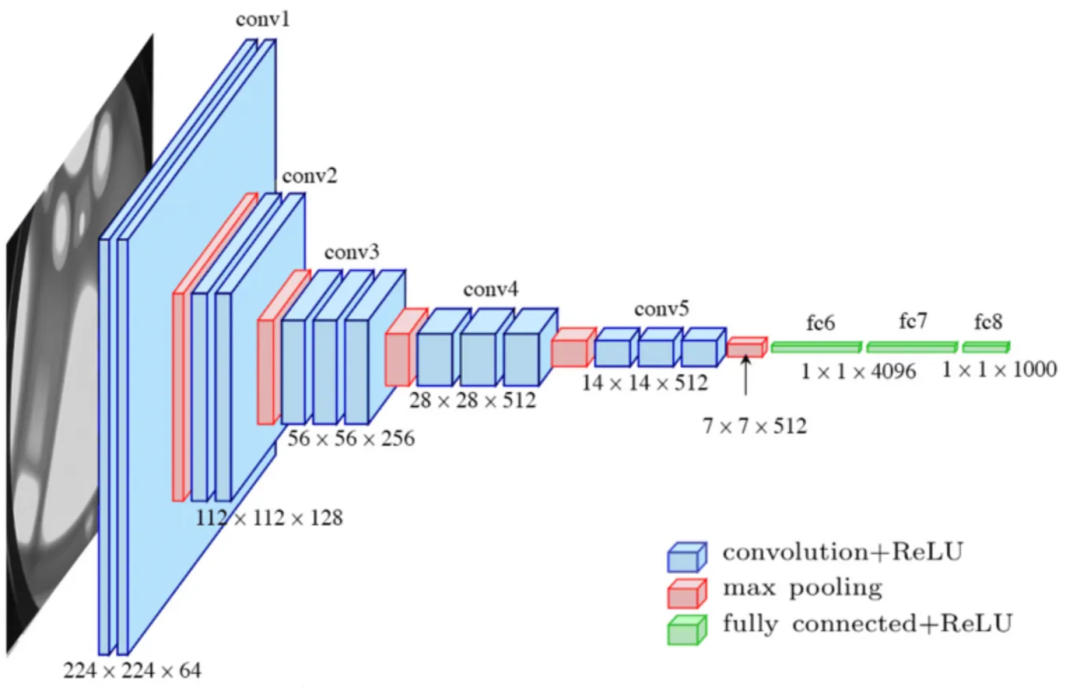
随后,我们利用 VGG16 函数基于上述图像创建 VGG16 网络(仅包含卷积部分 conv1、conv2、conv3、conv4 和 conv5)。接着,我们加载下载的权重,并获取 FCN 解码器部分所需的关键层。
下载权重 vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5
权重文件
代码:
def VGG_16(image_input): x = tf.keras.layers.Conv2D(filters=64, kernel_size=(3,3), activation='relu', padding='same', name='conv1-1')(image_input) x = tf.keras.layers.Conv2D(filters=64, kernel_size=(3,3), activation='relu', padding='same', name='conv1-2')(x) x = tf.keras.layers.MaxPooling2D(pool_size=(2,2), strides=(2,2), name='max1')(x) p1 = x x = tf.keras.layers.Conv2D(filters=128, kernel_size=(3,3), activation='relu', padding='same', name='conv2-1')(x) x = tf.keras.layers.Conv2D(filters=128, kernel_size=(3,3), activation='relu', padding='same', name='conv2-2')(x) x = tf.keras.layers.MaxPooling2D(pool_size=(2,2), strides=(2,2), name='max2')(x) p2 = x x = tf.keras.layers.Conv2D(filters=256, kernel_size=(3,3), activation='relu', padding='same', name='conv3-1')(x) x = tf.keras.layers.Conv2D(filters=256, kernel_size=(3,3), activation='relu', padding='same', name='conv3-2')(x) x = tf.keras.layers.Conv2D(filters=256, kernel_size=(3,3), activation='relu', padding='same', name='conv3-3')(x) x = tf.keras.layers.MaxPooling2D(pool_size=(2,2), strides=(2,2), name='max3')(x) p3 = x x = tf.keras.layers.Conv2D(filters=512, kernel_size=(3,3), activation='relu', padding='same', name='conv4-1')(x) x = tf.keras.layers.Conv2D(filters=512, kernel_size=(3,3), activation='relu', padding='same', name='conv4-2')(x) x = tf.keras.layers.Conv2D(filters=512, kernel_size=(3,3), activation='relu', padding='same', name='conv4-3')(x) x = tf.keras.layers.MaxPooling2D(pool_size=(2,2), strides=(2,2), name='max4')(x) p4 = x x = tf.keras.layers.Conv2D(filters=512, kernel_size=(3,3), activation='relu', padding='same', name='conv5-1')(x) x = tf.keras.layers.Conv2D(filters=512, kernel_size=(3,3), activation='relu', padding='same', name='conv5-2')(x) x = tf.keras.layers.Conv2D(filters=512, kernel_size=(3,3), activation='relu', padding='same', name='conv5-3')(x) x = tf.keras.layers.MaxPooling2D(pool_size=(2,2), strides=(2,2), name='max5')(x) p5 = x vgg = tf.keras.Model(image_input, p5) vgg.load_weights('vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5') return (p1, p2, p3, p4, p5)FCN-8-解码器:上采样
fcn8_decoder 函数利用 Conv2DTranspose 进行上采样。此操作对于增加特征图的空间分辨率至关重要。与通过步幅(stride)降低分辨率的传统卷积不同,Conv2DTranspose 使用步幅来提高分辨率。
简单来说,它"填充"了现有像素之间的间隙,有效地扩大了图像尺寸。这在语义分割中至关重要,因为它有助于恢复在编码器下采样过程中丢失的精细细节。
在代码 o = tf.keras.layers.Conv2DTranspose(n_classes , kernel_size=(4,4) , strides=(2,2) , use_bias=False)(f5) 中,转置卷积操作使空间维度加倍,随后的操作进一步优化了分割图。
总而言之,Conv2DTranspose 通过扩大特征图的分辨率,成为了在语义分割中重建详细信息的关键。
def fcn8_decoder(convs, n_classes): """ FCN-8解码器:将编码器特征图逐步上采样并与浅层特征融合 参数: convs: 编码器的五个特征图 [f1, f2, f3, f4, p5] n_classes: 分割类别数 """ f1, f2, f3, f4, p5 = convs n = 4096 # 卷积层的通道数 # 对编码器输出进行两次卷积 c6 = tf.keras.layers.Conv2D(n, (7, 7), activation='relu', padding='same', name="conv6")(p5) c7 = tf.keras.layers.Conv2D(n, (1, 1), activation='relu', padding='same', name="conv7")(c6) f5 = c7 # 对编码器输出进行2倍上采样,并裁剪多余的像素 o = tf.keras.layers.Conv2DTranspose(n_classes, kernel_size=(4, 4), strides=(2, 2), use_bias=False)(f5) o = tf.keras.layers.Cropping2D(cropping=(1, 1))(o) # 处理pool4特征:通过1x1卷积调整通道数与上采样结果一致 o2 = f4 o2 = tf.keras.layers.Conv2D(n_classes, (1, 1), activation='relu', padding='same')(o2) # 将上采样结果与pool4预测结果相加(特征融合) o = tf.keras.layers.Add()([o, o2]) # 对融合结果进行2倍上采样 o = tf.keras.layers.Conv2DTranspose(n_classes, kernel_size=(4, 4), strides=(2, 2), use_bias=False)(o) o = tf.keras.layers.Cropping2D(cropping=(1, 1))(o) # 处理pool3特征:通过1x1卷积调整通道数 o2 = f3 o2 = tf.keras.layers.Conv2D(n_classes, (1, 1), activation='relu', padding='same')(o2) # 将上采样结果与pool3预测结果相加(特征融合) o = tf.keras.layers.Add()([o, o2]) # 最终8倍上采样,恢复到原始图像尺寸 o = tf.keras.layers.Conv2DTranspose(n_classes, kernel_size=(8, 8), strides=(8, 8), use_bias=False)(o) # 添加softmax激活函数获取类别概率 o = tf.keras.layers.Activation('softmax')(o) return oFCN-16-解码器:上采样
FCN-16s 架构结合了最终层和步幅为 16 的 pool4 层的预测结果。这使得网络能够在保留最终层高层语义信息的同时,利用来自 pool4 的高分辨率信息来预测更精细的细节。它在细节信息和语义上下文之间取得了平衡。
def fcn16_decoder(convs, n_classes): """ FCN-16解码器:将编码器特征图与中间特征融合,直接上采样到原始尺寸 参数: convs: 编码器的五个特征图 [f1, f2, f3, f4, p5] n_classes: 分割类别数 """ f1, f2, f3, f4, p5 = convs n = 4096 # 卷积层的通道数 # 对编码器输出进行两次卷积 c6 = tf.keras.layers.Conv2D(n, (7, 7), activation='relu', padding='same', name="conv6")(p5) c7 = tf.keras.layers.Conv2D(n, (1, 1), activation='relu', padding='same', name="conv7")(c6) f5 = c7 # 对编码器输出进行2倍上采样,并裁剪多余的像素 o = tf.keras.layers.Conv2DTranspose(n_classes, kernel_size=(4, 4), strides=(2, 2), use_bias=False)(f5) o = tf.keras.layers.Cropping2D(cropping=(1, 1))(o) # 处理pool4特征:通过1x1卷积调整通道数与上采样结果一致 o2 = f4 o2 = tf.keras.layers.Conv2D(n_classes, (1, 1), activation='relu', padding='same')(o2) # 将上采样结果与pool4预测结果相加(特征融合) o = tf.keras.layers.Add()([o, o2]) # 直接16倍上采样,恢复到原始图像尺寸 o = tf.keras.layers.Conv2DTranspose(n_classes, kernel_size=(8, 8), strides=(16, 16), use_bias=False)(o) # 添加softmax激活函数获取类别概率 o = tf.keras.layers.Activation('softmax')(o) return oFCN-32-解码器:上采样
在 FCN-32s 中,单流网络直接通过步幅为 32 的上采样,一步到位地将预测结果还原到像素级别。这种方法简化了上采样过程,为每个像素提供了整体的预测。
def fcn32_decoder(convs, n_classes): """ FCN-32解码器:直接将编码器特征图上采样到原始尺寸 参数: convs: 编码器的五个特征图 [f1, f2, f3, f4, p5] n_classes: 分割类别数 """ f1, f2, f3, f4, p5 = convs n = 4096 # 卷积层的通道数 # 对编码器输出进行两次卷积 c6 = tf.keras.layers.Conv2D(n, (7, 7), activation='relu', padding='same', name="conv6")(p5) c7 = tf.keras.layers.Conv2D(n, (1, 1), activation='relu', padding='same', name="conv7")(c6) f5 = c7 # 直接32倍上采样,恢复到原始图像尺寸 o = tf.keras.layers.Conv2DTranspose(n_classes, kernel_size=(8, 8), strides=(32, 32), use_bias=False)(f5) # 添加softmax激活函数获取类别概率 o = tf.keras.layers.Activation('softmax')(o) return o在上采样的背景下,步幅(stride)至关重要,因为它决定了采样点之间的间距,从而影响输出尺寸。另一方面,卷积核大小(kernel size)影响滤波器的大小以及每个单元收集的信息,但在上采样期间它并不直接影响输出的空间分辨率。选择合适的步幅是控制网络在像素级别预测精细程度的关键。
计算掩码评估指标
该函数计算预测掩码与真实标签掩码之间的两个核心指标------交并比(Intersection over Union, IOU)和 Dice 系数(Dice Score)。这些指标由以下公式表示:
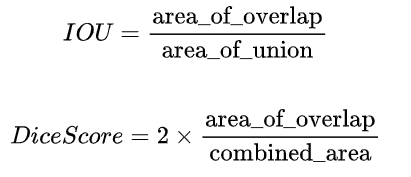
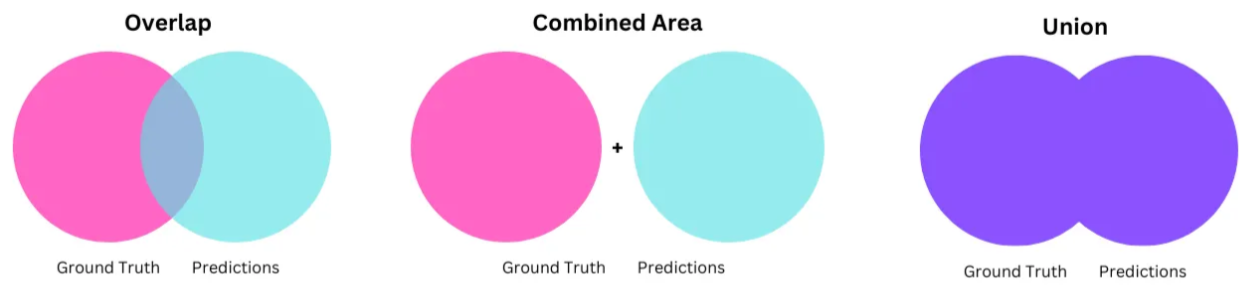
为了方便您使用,提供的代码会自动执行此计算。此外,我们在分母中加入了一个微小的平滑因子,以防止可能出现的除零情况。
def IOU_diceScore(y_true, y_pred): class_wise_iou = [] class_wise_dice_score = [] smoothening_factor = 0.00001 for i in range(12): intersection = np.sum((y_pred==i) * (y_true==i)) y_true_area = np.sum((y_true==1)) y_pred_area = np.sum((y_pred==i)) combined_area = y_true_area + y_pred_area iou = (intersection + smoothening_factor) / (combined_area-intersection+smoothening_factor) class_wise_iou.append(iou) dice_score = 2 * ((intersection+smoothening_factor)) / (combined_area + smoothening_factor) class_wise_dice_score.append(dice_score) return class_wise_iou, class_wise_dice_score结语
在结束对 TensorFlow 语义分割的探索时,我们涵盖了基础知识,解析了图像分割的类型,并深入探讨了 FCN 的高层架构。文章剖析了 FCN 的不同变体,强调了根据项目需求在 FCN-8、FCN-16 和 FCN-32 之间进行战略性选择的重要性。
通过引入迁移学习(特别是使用 VGG16 作为编码器),我们的 FCN 模型得到了增强,这不仅提升了训练效率和准确性,尤其在标记数据有限的情况下更是如此。
我们对 FCN-8、FCN-16 和 FCN-32 解码器的详细剖析,加上用于模型评估的 IOU 和 Dice Score 等指标,使读者能够有效地实现这些架构。
无论您是初学者还是经验丰富的开发者,本文都提供了一份简洁的指南,包含清晰的代码片段和动手实践环节。要获取所有的实现代码和数据预处理细节,请私信我。