一、MinIO和S3的核心区别
S3是一个托管的云存储服务,而MinIO是一个可以自己部署和管理的开源对象存储软件,S3是亚马逊提供的"云上存储即服务",而MinIO是你可以装在自家服务器或私有云上的、能提供和S3一样接口的"存储软件"。
| 对比维度 | Amazon S3 (Simple Storage Service) | MinIO |
|---|---|---|
| 本质 | 托管的云服务,由亚马逊完全运维。 | 开源对象存储软件,需要自行部署和管理。 |
| 所有权与控制权 | 无服务器(Serverless) 模式,用户不管理底层基础设施。 | 完全自管,掌控从硬件、网络到软件的全栈。 |
| 成本模型 | 按使用量付费(存储量、请求次数、流量),无前置成本,属运营支出。 | 一次性的硬件与运维成本,软件免费,属资本支出。 |
| 数据主权与位置 | 数据存储在亚马逊全球的数据中心,受其政策及所在地法规约束。 | 数据完全留在自有机房或指定的私有云/公有云主机中。 |
| 核心功能 | 功能极度丰富(版本控制、生命周期、事件通知等),与AWS生态深度集成。 | 功能聚焦核心对象存储,100%兼容S3 API,轻量高效。 |
| 性能与扩展 | 近乎无限的扩展能力,性能由服务等级(如S3 Standard, S3 Intelligent-Tiering)保障。 | 性能取决于自有的硬件和网络,扩展需自行规划集群。 |
| 生态系统 | AWS云服务的核心,拥有最广泛的第三方工具和应用原生支持。 | 作为"开源版S3",被所有支持S3协议的工具和应用兼容,是混合云的关键桥梁。 |
二、如何选择:S3 还是 MinIO?
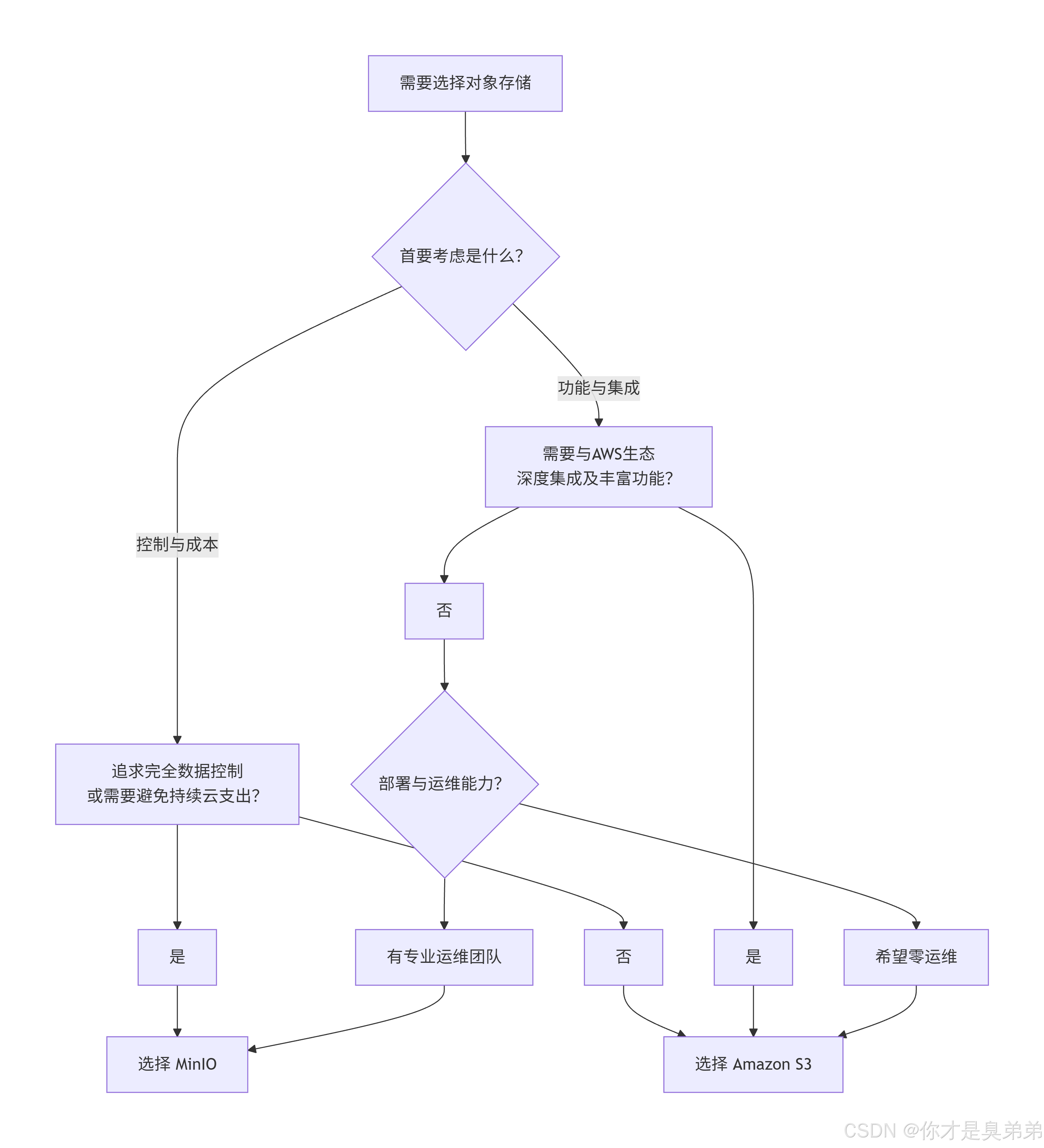
-
选择 Amazon S3 :如果你在公有云(尤其是AWS) 上构建数据湖,希望零运维、弹性扩展,并充分利用云生态。这是最主流、最省心的方式。
-
选择 MinIO :如果你需要在私有数据中心、其他云厂商的虚拟机或Kubernetes 上,构建一个完全自主可控、且与S3生态兼容的数据湖存储层。它是避免云厂商锁定和满足数据驻留要求的利器。
三、结合数据湖架构的实践建议
针对 Apache Iceberg + Flink 的数据湖架构:
-
S3路径 :
s3://your-bucket/warehouse/path -
MinIO路径 :
s3://your-minio-bucket/warehouse/path(注意:端点endpoint需配置为你的MinIO服务器地址,如http://minio-server:9000)
关键点 :由于MinIO完全兼容S3 API,你在使用Flink或Spark写入Iceberg表时,配置方式几乎完全相同,只需将访问密钥、端点(endpoint)和路径指向你的MinIO服务即可。
可以将MinIO理解为 "开源、可自建的S3" 。它让你在任何环境中都能获得与公有云体验一致的对象存储能力,是构建现代化、云原生私有数据湖的基石。
四、Amazon S3 和 MinIO 存储区别
| 对比维度 | Amazon S3 | MinIO |
|---|---|---|
| 本质 | 托管的云存储服务 (PaaS/SaaS) | 自管理的对象存储软件 |
| 所有权 | 亚马逊管理一切基础设施,用户仅使用服务 | 用户完全掌控从硬件、软件到运维的全栈 |
| 成本模型 | 按实际使用量(存储、请求、流量)付费的运营支出(OpEx) | 前期硬件/服务器投入和后期运维的资本支出(CapEx),软件免费 |
| 数据位置 | 数据存储在亚马逊全球的数据中心 | 数据完全留在用户指定的环境(自有机房、私有云等) |
| 核心功能 | 功能极为丰富(版本控制、生命周期管理、事件通知等),与AWS生态深度集成 | 功能聚焦高性能核心存储,100%兼容S3 API,轻量高效 |
| 性能与扩展 | 近乎无限的弹性扩展能力,性能由服务等级协议保障 | 性能和扩展性完全取决于自有的硬件与集群规划 |
| 生态系统 | 云服务的基石,拥有最广泛的工具和应用原生支持 | 作为"开源S3替代",被所有支持S3协议的应用兼容 |
-
选择 Amazon S3:如果你在AWS云上、追求零运维、需要弹性伸缩,并希望充分利用云原生服务。这是构建云上数据湖的标准路径。
-
选择 MinIO:如果你的需求是数据必须留在本地或私有环境、需要避免云供应商锁定、或希望控制长期成本。它是构建现代化私有数据湖存储层的最佳实践。
无论选择哪个,对于Iceberg和Flink来说,配置方式几乎一样(都需要配置access-key, secret-key, endpoint和path)。你只需将endpoint指向AWS S3的服务地址或你自己的MinIO服务器地址即可。
-
要省心、强大、紧跟云原生,选S3。
-
要自主、可控、满足合规,选MinIO。