
目录
[一、块组内部构成:Ext2 的 "管理中枢" 与 "存储仓库"](#一、块组内部构成:Ext2 的 “管理中枢” 与 “存储仓库”)
[1.1 超级块(Super Block):文件系统的 "总配置文件"](#1.1 超级块(Super Block):文件系统的 “总配置文件”)
[1.1.1 超级块的核心信息](#1.1.1 超级块的核心信息)
[1.1.2 超级块的备份机制:文件系统的 "救命稻草"](#1.1.2 超级块的备份机制:文件系统的 “救命稻草”)
[1.1.3 实战:查看超级块信息](#1.1.3 实战:查看超级块信息)
[1.2 块组描述符表(GDT):块组的 "索引目录"](#1.2 块组描述符表(GDT):块组的 “索引目录”)
[1.2.1 块组描述符的结构](#1.2.1 块组描述符的结构)
[1.2.2 GDT 的存储与备份](#1.2.2 GDT 的存储与备份)
[1.2.3 实战:查看块组描述符信息](#1.2.3 实战:查看块组描述符信息)
[1.3 块位图(Block Bitmap):数据块的 "占用状态表"](#1.3 块位图(Block Bitmap):数据块的 “占用状态表”)
[1.3.1 块位图的工作原理](#1.3.1 块位图的工作原理)
[1.3.2 块位图的存储特点](#1.3.2 块位图的存储特点)
[1.3.3 实战:解析块位图(简化版)](#1.3.3 实战:解析块位图(简化版))
[1.4 inode 位图(Inode Bitmap):inode 的 "占用状态表"](#1.4 inode 位图(Inode Bitmap):inode 的 “占用状态表”)
[1.4.1 inode 位图的工作原理](#1.4.1 inode 位图的工作原理)
[1.4.2 inode 位图与块位图的区别](#1.4.2 inode 位图与块位图的区别)
[1.4.3 实战:查看 inode 位图状态](#1.4.3 实战:查看 inode 位图状态)
[1.5 inode 表(Inode Table):文件属性的 "数据库"](#1.5 inode 表(Inode Table):文件属性的 “数据库”)
[1.5.1 inode 表的存储计算](#1.5.1 inode 表的存储计算)
[1.5.2 inode 表的访问方式](#1.5.2 inode 表的访问方式)
[1.5.3 实战:读取 inode 表中的 inode 数据](#1.5.3 实战:读取 inode 表中的 inode 数据)
[1.6 数据块(Data Blocks):文件内容的 "存储仓库"](#1.6 数据块(Data Blocks):文件内容的 “存储仓库”)
[1.6.1 数据块的大小选择](#1.6.1 数据块的大小选择)
[1.6.2 实战:查看数据块内容](#1.6.2 实战:查看数据块内容)
[二、inode 与数据块映射:文件属性与内容的 "桥梁"](#二、inode 与数据块映射:文件属性与内容的 “桥梁”)
[2.1 映射机制:12 个直接块 + 3 个间接块](#2.1 映射机制:12 个直接块 + 3 个间接块)
[2.1.1 直接块(Direct Blocks)](#2.1.1 直接块(Direct Blocks))
[2.1.2 一级间接块(Indirect Block)](#2.1.2 一级间接块(Indirect Block))
[2.1.3 二级间接块(Double Indirect Block)](#2.1.3 二级间接块(Double Indirect Block))
[2.1.4 三级间接块(Triple Indirect Block)](#2.1.4 三级间接块(Triple Indirect Block))
[2.2 映射示意图与访问流程](#2.2 映射示意图与访问流程)
[2.3 实战:验证 inode 与数据块的映射关系](#2.3 实战:验证 inode 与数据块的映射关系)
[三、目录与文件名:文件的 "人类可读标识"](#三、目录与文件名:文件的 “人类可读标识”)
[3.1 目录的本质:"文件名→inode 号" 的映射表](#3.1 目录的本质:“文件名→inode 号” 的映射表)
[3.2 目录项的结构](#3.2 目录项的结构)
[3.3 实战:解析目录的数据块(查看 "文件名→inode 号" 映射)](#3.3 实战:解析目录的数据块(查看 “文件名→inode 号” 映射))
[3.4 文件名的查找流程:从路径到 inode](#3.4 文件名的查找流程:从路径到 inode)
[3.5 文件名的长度限制](#3.5 文件名的长度限制)
前言
在 Linux 的文件存储世界里,Ext2 文件系统凭借其简洁高效的设计,成为理解文件系统底层原理的最佳范本。之前我们已经了解了 Ext2 的块组架构、块、分区和 inode 的基础概念,但块组内部究竟藏着哪些 "管理神器"?inode 如何精准找到存储文件内容的数据块?目录和文件名又是如何关联起文件的属性与内容?今天这篇文章,我们就钻进 Ext2 的块组内部,一步步拆解超级块、位图、inode 表、数据块的协同工作逻辑,揭开目录与文件名的底层映射关系,带你看透文件存储的核心机密。下面就让我们正式开始吧!
一、块组内部构成:Ext2 的 "管理中枢" 与 "存储仓库"
Ext2 文件系统将分区划分为多个块组(Block Group),每个块组都是一个独立的 "小生态",包含了文件系统正常运行所需的全部管理结构和数据存储区域。块组内部从前往后依次分为 6 个核心部分:超级块(Super Block)、块组描述符表(GDT)、块位图(Block Bitmap)、inode 位图(Inode Bitmap)、inode 表(Inode Table)和数据块(Data Blocks)。这 6 个部分各司其职、紧密配合,共同完成文件的创建、存储、查找和删除等操作。
1.1 超级块(Super Block):文件系统的 "总配置文件"
超级块是 Ext2 文件系统的 "大脑",存储了整个分区的全局配置信息,相当于一本 "系统说明书"。任何对文件系统的操作(如创建文件、分配块、挂载分区),都需要先读取超级块的信息,确认系统状态和资源情况。
1.1.1 超级块的核心信息
超级块的结构定义在 Linux 内核源码中(struct ext2_super_block),包含了数十个字段,核心信息如下(C 语言简化版):
cpp
#include <stdint.h>
// Ext2超级块结构(核心字段)
struct ext2_super_block {
uint32_t s_inodes_count; // 整个文件系统的inode总数
uint32_t s_blocks_count; // 整个文件系统的块总数
uint32_t s_r_blocks_count; // 保留块总数(仅root用户可用)
uint32_t s_free_blocks_count; // 空闲块数
uint32_t s_free_inodes_count; // 空闲inode数
uint32_t s_first_data_block; // 第一个数据块的块号
uint32_t s_log_block_size; // 块大小的日志值(块大小 = 1024 << 该值)
uint32_t s_blocks_per_group; // 每个块组的块数(默认8192)
uint32_t s_inodes_per_group; // 每个块组的inode数(默认1024)
uint32_t s_mtime; // 最后挂载时间(时间戳)
uint32_t s_wtime; // 最后写入时间(时间戳)
uint16_t s_mnt_count; // 挂载次数
uint16_t s_max_mnt_count; // 最大挂载次数(超过后需执行e2fsck检查)
uint16_t s_magic; // 魔术数(Ext2标识:0xEF53)
uint16_t s_state; // 文件系统状态(0x0001=干净,0x0002=错误)
uint16_t s_errors; // 错误处理方式(忽略/提示/修复)
uint16_t s_inode_size; // inode大小(128或256字节)
uint8_t s_uuid[16]; // 文件系统UUID(唯一标识)
char s_volume_name[16]; // 卷名(自定义文件系统名称)
char s_last_mounted[64]; // 最后挂载点路径
};这些字段看似繁杂,实则可归纳为三类核心信息:
- 资源总量 :
s_inodes_count(inode 总数)、s_blocks_count(块总数)定义了文件系统的最大存储能力;- 资源状态 :
s_free_blocks_count(空闲块数)、s_free_inodes_count(空闲 inode 数)实时反映资源剩余情况,创建文件时需先检查这两个值;- 配置参数 :
s_log_block_size(块大小)、s_inode_size(inode 大小)、s_blocks_per_group(每块组块数)等,决定了文件系统的存储格式和管理方式;- 状态标识 :
s_magic(魔术数)用于内核识别文件系统类型,s_state(系统状态)标记文件系统是否正常,避免异常挂载导致数据损坏。
1.1.2 超级块的备份机制:文件系统的 "救命稻草"
超级块是文件系统的 "命脉",一旦损坏,整个分区可能无法挂载。为了提高可靠性,Ext2 采用了 "主备份 + 多副本" 的机制:
- 主超级块:存储在块组 0 的起始位置,是文件系统挂载时优先读取的版本;
- 备份超级块:在块组 1、3、5、7 等质数编号的块组中,会存储超级块的副本(质数编号可避免备份集中在同一物理区域,降低同时损坏的风险)。
所有超级块副本的数据完全一致,当主超级块损坏时,可以通过备份超级块修复文件系统。例如,若块大小为 4KB(s_log_block_size=2),块组 0 的超级块位于块 0,块组 1 的备份超级块位于块 8192(s_blocks_per_group=8192),修复命令如下:
bash
# e2fsck:Ext系列文件系统修复工具,-b指定备份超级块的块号
e2fsck -b 8192 /dev/vda11.1.3 实战:查看超级块信息
在 Linux 中,dumpe2fs命令可读取 Ext2/Ext3/Ext4 文件系统的超级块信息。我们以一个 Ext2 磁盘镜像为例:
bash
# 1. 创建5MB的Ext2镜像文件
dd if=/dev/zero of=ext2_sb_test.img bs=1M count=5
mkfs.ext2 ext2_sb_test.img
# 2. 查看超级块信息(仅显示核心字段)
dumpe2fs ext2_sb_test.img | grep -E "Filesystem magic|Block count|Inode count|Free blocks|Free inodes|Block size|Inode size"输出示例:
Filesystem magic number: 0xEF53 # 魔术数,确认是Ext2
Block count: 1280 # 总块数(5MB / 4KB = 1280)
Inode count: 1280 # 总inode数(每个块组1280个)
Free blocks: 1167 # 空闲块数
Free inodes: 1269 # 空闲inode数
Block size: 4096 # 块大小4KB
Inode size: 128 # inode大小128字节这些输出与超级块结构中的字段一一对应,验证了超级块的核心作用。
1.2 块组描述符表(GDT):块组的 "索引目录"
如果说超级块是整个文件系统的 "总说明书",那么块组描述符表(Group Descriptor Table,GDT)就是每个块组的 "分说明书索引"。GDT 由多个块组描述符(struct ext2_group_desc)组成,每个块组对应一个描述符,记录该块组的管理结构位置和资源状态。
1.2.1 块组描述符的结构
块组描述符的 C 语言定义如下(简化版):
cpp
#include <stdint.h>
// Ext2块组描述符结构
struct ext2_group_desc {
uint32_t bg_block_bitmap; // 块位图所在的块号
uint32_t bg_inode_bitmap; // inode位图所在的块号
uint32_t bg_inode_table; // inode表的起始块号
uint16_t bg_free_blocks_count; // 该块组的空闲块数
uint16_t bg_free_inodes_count; // 该块组的空闲inode数
uint16_t bg_used_dirs_count; // 该块组的目录数
uint16_t bg_pad; // 填充字段(内存对齐用)
uint32_t bg_reserved[3]; // 保留字段
};核心字段解读:
- 管理结构位置 :
bg_block_bitmap(块位图块号)、bg_inode_bitmap(inode 位图块号)、bg_inode_table(inode 表起始块号),这三个字段是 GDT 的核心 ------ 通过它们,文件系统可以快速定位块组内的关键管理结构,无需遍历整个块组;- 资源状态 :
bg_free_blocks_count(块组空闲块数)、bg_free_inodes_count(块组空闲 inode 数),文件系统分配资源时会优先选择空闲资源充足的块组,提高访问效率;- 目录统计 :
bg_used_dirs_count(块组目录数),用于快速统计块组内的目录数量,辅助文件系统优化。
1.2.2 GDT 的存储与备份
GDT 的存储位置紧随超级块之后,占用 1 个或多个块(取决于块组数量)。例如,若分区有 10 个块组,每个描述符占 32 字节,则 GDT 共需 320 字节,占用 1 个 4KB 块。
与超级块类似,GDT 也会在多个块组中备份(与超级块的备份块组相同)。当某个块组的 GDT 损坏时,可通过其他块组的备份 GDT 恢复,确保块组管理结构的可靠性。
1.2.3 实战:查看块组描述符信息
使用dumpe2fs命令可查看每个块组的描述符信息:
bash
# 查看块组0的描述符信息
dumpe2fs ext2_sb_test.img | grep -A 10 "Group 0:"输出示例:
Group 0: (Blocks 0-1279)
Primary superblock at 0, Group descriptors at 1-1
Reserved GDT blocks at 2-63
Block bitmap at 64 (+64)
Inode bitmap at 65 (+65)
Inode table at 66-97 (+66)
1167 free blocks, 1269 free inodes, 2 directories
Free blocks: 112-1279
Free inodes: 12-1280输出中:
- Block bitmap at 64:对应
bg_block_bitmap=64;- Inode bitmap at 65:对应
bg_inode_bitmap=65;- Inode table at 66-97:对应
bg_inode_table=66(inode 表占用 32 个 4KB 块:97-66+1=32);- 1167 free blocks, 1269 free inodes:对应
bg_free_blocks_count=1167、bg_free_inodes_count=1269。
1.3 块位图(Block Bitmap):数据块的 "占用状态表"
块组内的 Data Blocks 是存储文件内容的 "仓库",而块位图就是这个仓库的 "门禁记录"------ 记录每个数据块的占用状态(空闲 / 已占用),确保块分配时不重复、释放时不遗漏。
1.3.1 块位图的工作原理
块位图是一个**"位数组"**(bit array),每个 bit 对应一个数据块,bit 的位置即为块在块组内的索引(从 0 开始):
- bit=1:对应的块已被占用;
- bit=0:对应的块空闲可用。
例如,一个块组有 8192 个数据块,对应的块位图需要 8192 个 bit(8192/8=1024 字节 = 1KB),正好占用 1 个 4KB 块(剩余空间填充为 0)。
块位图的操作逻辑非常高效:
- 分配块:遍历块位图,找到第一个值为 0 的 bit,将其设为 1,然后通过 "块组起始块号 + bit 索引" 计算出实际块号;
- 释放块:根据块号计算其在块位图中的 bit 索引(bit 索引 = 块号 - 块组起始块号),将该 bit 设为 0。
这种基于位运算的操作,时间复杂度接近O (1)(忽略遍历位图的时间),远快于线性查找空闲块。
1.3.2 块位图的存储特点
- 块位图的块号由块组描述符的**
bg_block_bitmap**字段指定,每个块组有且仅有一个块位图;- 块位图仅记录当前块组内的数据块状态,不跨块组;
- 块位图的修改是原子操作(要么修改成功,要么失败),确保数据一致性 ------ 避免多个进程同时分配同一个块。
1.3.3 实战:解析块位图(简化版)
我们可以通过debugfs命令读取块位图的原始数据,验证其工作原理:
bash
# 1. 以只读模式挂载Ext2镜像
debugfs -R "dump /bitmap_block bitmap_dump.bin" ext2_sb_test.img
# 2. 查看位图文件的前16字节(十六进制)
hexdump -C -n 16 bitmap_dump.bin输出示例:
00000000 ff ff ff ff ff ff ff ff ff ff ff ff ff ff 00 00 |................|
00000010输出解读:前 11 个字节(88 个 bit)均为ff(二进制11111111),表示前 88 个块已被占用(超级块、GDT、位图、inode 表等管理结构占用),从第 89 个 bit 开始为00,表示后续块空闲。这与dumpe2fs输出的 "Free blocks: 112-1279" 一致(块组起始块号为 0,112 号块对应第 112 个 bit,属于空闲区域)。
1.4 inode 位图(Inode Bitmap):inode 的 "占用状态表"
inode 位图与块位图的设计思想完全一致,是 inode 的**"占用状态表"**------ 通过位数组记录每个 inode 的空闲 / 占用状态,确保 inode 分配和释放的准确性。
1.4.1 inode 位图的工作原理
inode 位图也是一个位数组,每个 bit 对应一个 inode,bit 的位置即为 inode 在块组内的索引(从 0 开始):
- bit=1:对应的 inode 已被占用;
- bit=0:对应的 inode 空闲可用。
例如,一个块组有 1024 个 inode,对应的 inode 位图需要 1024 个 bit(1024/8=128 字节),占用 1 个 4KB 块的前 128 字节(剩余空间填充为 0)。
inode 位图的操作逻辑与块位图一致:
- 分配 inode:遍历 inode 位图,找到第一个值为 0 的 bit,将其设为 1,inode 号 = 块组起始 inode 号 + bit 索引;
- 释放 inode:根据 inode 号计算 bit 索引(bit 索引 = inode 号 - 块组起始 inode 号),将该 bit 设为 0。
1.4.2 inode 位图与块位图的区别
| 特性 | 块位图 | inode 位图 |
|---|---|---|
| 管理对象 | 数据块(Data Blocks) | inode(索引节点) |
| 位数组长度 | 等于块组内的数据块数 | 等于块组内的 inode 数 |
| 核心作用 | 记录块的空闲 / 占用状态 | 记录 inode 的空闲 / 占用状态 |
| 关联字段 | bg_block_bitmap | bg_inode_bitmap |
1.4.3 实战:查看 inode 位图状态
使用dumpe2fs命令可直接查看 inode 位图的状态:
bash
dumpe2fs ext2_sb_test.img | grep -A 3 "Inode bitmap at 65"输出示例:
Inode bitmap at 65 (+65)
Inode table at 66-97 (+66)
1167 free blocks, 1269 free inodes, 2 directories
Free inodes: 12-1280输出中 "Free inodes: 12-1280" 表示:块组内前 11 个 inode(0-11)已被占用(用于 root 目录、lost+found 等系统文件),从 12 号 inode 开始空闲可用,这与 inode 位图中前 11 个 bit 为 1、后续为 0 的状态一致。
1.5 inode 表(Inode Table):文件属性的 "数据库"
inode 表是块组内存储 inode 的 "数据库",由多个连续的块组成,每个块中存储多个 inode(inode 大小固定,如 128 字节)。每个文件(包括目录、链接、设备文件等)都对应一个 inode,inode 中存储了文件的所有属性(除了文件名)。
1.5.1 inode 表的存储计算
inode 表的大小可通过以下公式计算:
inode表大小 = 每个块组的inode数 × inode大小例如,块组有 1024 个 inode,每个 inode 大小 128 字节,则 inode 表大小 = 1024×128=131072 字节 = 128KB。若块大小为 4KB,则 inode 表占用的块数 = 128KB÷4KB=32 个块(与之前dumpe2fs输出的 "inode table at 66-97" 一致:97-66+1=32)。
1.5.2 inode 表的访问方式
要访问某个 inode,需经过以下步骤:
- 根据 inode 号确定其所在的块组 :块组号 =(inode 号 - 1)÷ 每个块组的 inode 数(inode 号从 1 开始,块组号从 0 开始);
- 读取该块组的描述符(从 GDT 中获取),得到 inode 表的起始块号(bg_inode_table);
- 计算 inode 在 inode 表中的偏移 :inode 在块组内的索引 =(inode 号 - 1)% 每个块组的 inode 数;
- 计算 inode 的实际存储位置 :inode 地址 = inode 表起始块号 × 块大小 + 索引 ×inode 大小;
- 从该地址读取 inode 数据,解析文件属性。
1.5.3 实战:读取 inode 表中的 inode 数据
使用debugfs命令可直接读取某个 inode 的详细信息:
bash
# 读取inode号为12的inode数据(12号是第一个空闲inode)
debugfs -R "stat <12>" ext2_sb_test.img输出示例:
Inode: 12 Type: regular Mode: 0644 Flags: 0x0 Generation: 0
User: 0 Group: 0 Size: 0
File ACL: 0 Directory ACL: 0
Links: 0 Blockcount: 0
Fragment: Address: 0 Number: 0 Size: 0
ctime: 0x00000000 -- Wed Dec 31 19:00:00 1969
atime: 0x00000000 -- Wed Dec 31 19:00:00 1969
mtime: 0x00000000 -- Wed Dec 31 19:00:00 1969
dtime: 0x00000000 -- Wed Dec 31 19:00:00 1969
Block: 0: 0 1: 0 2: 0 3: 0 4: 0
Block: 5: 0 6: 0 7: 0 8: 0 9: 0
Block: 10: 0 11: 0 12: 0 13: 0 14: 0输出中:
Type: regular:文件类型为普通文件;- Mode: 0644:文件权限(对应
i_mode字段);Size: 0:文件大小为 0(空闲 inode 未被使用);Links: 0:硬链接数为 0(对应i_links_count字段);Block: 0-14: 0:数据块指针均为 0(对应i_block[15]字段,未分配数据块)。
1.6 数据块(Data Blocks):文件内容的 "存储仓库"
数据块是块组内最大的区域,用于存储文件的实际内容。根据文件类型的不同,数据块的存储内容也不同:
- 普通文件:直接存储文件的二进制数据(如文本、图片、视频等);
- 目录文件:存储 "文件名→inode 号" 的映射关系(每个目录项包含文件名和对应的 inode 号);
- 软链接文件:存储原文件的路径字符串(如 "../test.c");
- 设备文件 / 管道文件:不存储实际数据,仅存储设备号或管道相关的元信息。
数据块的分配遵循 "连续优先" 原则:文件系统会尽量为文件分配连续的数据块,减少磁头移动次数,提高读写效率。若连续块不足,则分配离散块,通过 inode 中的块指针关联。
1.6.1 数据块的大小选择
数据块的大小(1KB/2KB/4KB/8KB)在格式化时指定,选择合适的块大小对性能影响显著:
- 小 block(1KB/2KB):适合小文件较多的场景(如日志文件、配置文件),减少内部碎片(文件大小不足一个块时的空间浪费);
- 大 block(4KB/8KB):适合大文件较多的场景(如视频、数据库文件),减少块数量,降低 inode 中块指针的开销,提高连续读写效率。
例如,一个 1MB 的文件:
- 若块大小为 1KB,需占用 1024 个块,inode 需记录 1024 个块指针(需用到间接块);
- 若块大小为 4KB,仅需占用 256 个块,inode 的直接块指针即可覆盖(12 个直接块可支持 12×4KB=48KB,超过后需用间接块)。
1.6.2 实战:查看数据块内容
使用debugfs命令可读取某个数据块的内容。例如,读取块组 0 中 112 号空闲块(未被占用,内容为 0):
bash
# dump 112号块的内容到block_dump.bin文件
debugfs -R "dump <112> block_dump.bin" ext2_sb_test.img
# 查看前16字节(全为0,说明块空闲)
hexdump -C -n 16 block_dump.bin输出示例:
00000000 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000010若块已被占用(如存储了文件内容),则输出会显示对应的二进制数据(文本文件会显示可读字符)。
二、inode 与数据块映射:文件属性与内容的 "桥梁"
我们知道,文件 = 属性(存储在 inode)+ 内容(存储在数据块),而 inode 中的i_block[15]字段就是连接两者的 "桥梁"------ 通过 15 个块指针,记录文件内容所在的数据块号,实现属性到内容的快速定位。
2.1 映射机制:12 个直接块 + 3 个间接块
Ext2 的 inode 中共包含 15 个块指针(EXT2_N_BLOCKS=15),分为 4 种类型:12 个直接块指针、1 个一级间接块指针、1 个二级间接块指针、1 个三级间接块指针。这种设计既能高效支持小文件,又能兼容超大文件。
2.1.1 直接块(Direct Blocks)
**i_block[0]到i_block[11]**是 12 个直接块指针,每个指针直接指向存储文件内容的数据块。
例如,若块大小为 4KB,12 个直接块可支持的文件最大大小为:
12 × 4KB = 48KB对于小文件(≤48KB),仅需通过直接块指针即可找到所有数据块,访问效率最高(无需额外间接查找)。
2.1.2 一级间接块(Indirect Block)
当文件大小超过 48KB 时,会使用**i_block[12]**(一级间接块指针)。该指针不直接指向数据块,而是指向一个 "间接块"------ 间接块中存储的是多个数据块的块号(每个块号占 4 字节,4KB 块可存储 1024 个块号)。
一级间接块支持的文件大小为:
1024 × 4KB = 4MB此时,文件的总最大支持大小为:48KB + 4MB = 4.048MB。
2.1.3 二级间接块(Double Indirect Block)
当文件大小超过 4.048MB 时,会使用**i_block[13]**(二级间接块指针)。该指针指向一个 "二级间接块",二级间接块中存储的是多个一级间接块的块号,每个一级间接块再存储 1024 个数据块号。
二级间接块支持的文件大小为:
1024 × 1024 × 4KB = 4GB此时,文件的总最大支持大小为:48KB + 4MB + 4GB = 4.004GB。
2.1.4 三级间接块(Triple Indirect Block)
当文件大小超过 4.004GB 时,会使用**i_block[14]**(三级间接块指针)。该指针指向一个 "三级间接块",三级间接块中存储的是多个二级间接块的块号,每个二级间接块存储 1024 个一级间接块号,每个一级间接块存储 1024 个数据块号。
三级间接块支持的文件大小为:
1024 × 1024 × 1024 × 4KB = 4TB最终,Ext2 文件系统支持的单个文件最大大小为:48KB + 4MB + 4GB + 4TB ≈ 4TB(受限于块大小和指针位数,32 位系统中最大支持 2TB)。
2.2 映射示意图与访问流程
为了更直观理解,我们用一张示意图展示 inode 与数据块的映射关系:
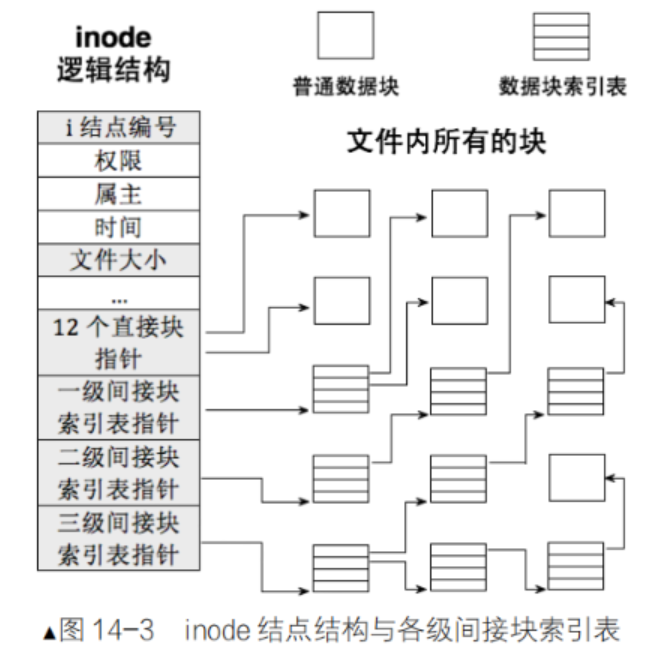
访问不同大小文件的流程:
- 小文件(≤48KB):inode → 直接块 → 数据(1 次 IO);
- 中文件(48KB~4.048MB):inode → 一级间接块 → 数据块 → 数据(2 次 IO);
- 大文件(4.048MB~4.004GB):inode → 二级间接块 → 一级间接块 → 数据块 → 数据(3 次 IO);
- 超大文件(>4.004GB):inode → 三级间接块 → 二级间接块 → 一级间接块 → 数据块 → 数据(4 次 IO)。
可见,文件越大,访问所需的 IO 次数越多,效率越低。这也是为什么大文件的读写效率通常低于小文件(连续存储的大文件除外)。
2.3 实战:验证 inode 与数据块的映射关系
我们创建一个 50KB 的文件(超过 12 个直接块的 48KB 限制,需用到一级间接块),验证映射关系:
bash
# 1. 创建50KB的测试文件(填充随机数据)
dd if=/dev/urandom of=test_50k.bin bs=1K count=50
# 2. 将文件复制到Ext2镜像中(需先挂载镜像)
mkdir -p /mnt/ext2_test
mount -o loop ext2_sb_test.img /mnt/ext2_test
cp test_50k.bin /mnt/ext2_test/
umount /mnt/ext2_test
# 3. 查看该文件的inode号
debugfs -R "ls -l /" ext2_sb_test.img | grep test_50k.bin输出示例:
-rw-r--r-- 1 1000 1000 51200 2024-10-31 15:00 test_50k.bin (inode=12)接着,查看 inode=12 的块指针信息:
bash
debugfs -R "stat <12>" ext2_sb_test.img | grep "Block:"输出示例:
Block: 0: 112 1: 113 2: 114 3: 115 4: 116
Block: 5: 117 6: 118 7: 119 8: 120 9: 121
Block: 10: 122 11: 123 12: 124 13: 0 14: 0输出解读:
i_block[0]~i_block[11](0~11)对应数据块 112~123(12 个直接块,共 12×4KB=48KB);i_block[12](12)对应数据块 124(一级间接块);- 剩余 2KB 数据(50KB-48KB=2KB)存储在一级间接块指向的数据块中(数据块 125,块号记录在 124 号间接块中);
i_block[13](13)和**i_block[14]**(14)为 0,未使用。
最后,验证一级间接块的内容(存储数据块 125 的块号):
bash
# 读取一级间接块(124号块)的内容
debugfs -R "dump <124> indirect_block.bin" ext2_sb_test.img
hexdump -C -n 8 indirect_block.bin输出示例:
00000000 7d 00 00 00 00 00 00 00 |}.......|
00000008输出中7d是十六进制,转换为十进制为 125,即一级间接块指向的数据块号为 125,与预期一致。
三、目录与文件名:文件的 "人类可读标识"
我们访问文件时,使用的是文件名(如test.c),而非 inode 号或块号。但 inode 中并不存储文件名,那么文件名是如何与 inode 关联的?目录又扮演了什么角色?
3.1 目录的本质:"文件名→inode 号" 的映射表
在 Ext2 文件系统中,目录也是一种文件------ 目录的 inode 存储目录的属性(如权限、创建时间、占用块数等),目录的数据块存储 "文件名→inode 号" 的映射关系(称为 "目录项")。
例如,一个名为**test_dir**的目录,其数据块中存储的内容类似如下结构:
| inode 号 | 文件名长度 | 文件名 |
|---|---|---|
| 263466 | 2 | . |
| 263465 | 3 | .. |
| 263467 | 5 | test.c |
| 263468 | 6 | demo.py |
其中:
- .:当前目录的目录项,inode 号等于目录自身的 inode 号;
- ..:上级目录的目录项,inode 号等于上级目录的 inode 号;
- 其他目录项:对应目录下的文件 / 子目录,inode 号为该文件 / 子目录的 inode 号。
3.2 目录项的结构
目录项的 C 语言定义如下(简化版):
cpp
#include <stdint.h>
// Ext2目录项结构
struct ext2_dir_entry {
uint32_t inode; // 对应的inode号
uint16_t rec_len; // 目录项长度(包括填充字节)
uint8_t name_len; // 文件名长度(字节)
uint8_t file_type; // 文件类型(1=普通文件,2=目录,3=字符设备,4=块设备,5=管道,6=链接,7=套接字)
char name[]; // 文件名(不包含终止符)
};核心字段解读:
inode:目录项对应的 inode 号,是文件名与 inode 的核心关联;rec_len:目录项长度(包含文件名和填充字节),用于遍历目录项(通过rec_len跳过当前目录项,找到下一个);name_len:文件名长度(不含 \0),避免读取多余字符;file_type:文件类型,快速判断该目录项对应的是文件、目录还是其他类型。
目录项的填充机制:为了内存对齐,目录项长度**rec_len会向上取整为 4 的倍数。例如,一个文件名长度为 5 字节的目录项,rec_len**可能为 8 字节(5+1(file_type)+2(填充)=8)。
3.3 实战:解析目录的数据块(查看 "文件名→inode 号" 映射)
我们通过 C 语言代码读取目录的数据块,验证目录项的结构。代码功能:读取指定目录的数据块,解析所有目录项,输出文件名和对应的 inode 号。
cpp
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <dirent.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
#include <fcntl.h>
#include <errno.h>
// 定义Ext2目录项结构(简化版)
struct ext2_dir_entry {
uint32_t inode;
uint16_t rec_len;
uint8_t name_len;
uint8_t file_type;
char name[];
};
// 读取文件的inode信息(获取数据块号)
int get_inode_blocks(const char *path, uint32_t *blocks) {
struct stat st;
if (stat(path, &st) == -1) {
perror("stat");
return -1;
}
// 打开磁盘设备(假设目录在/dev/vda1分区,需替换为实际设备)
int fd = open("/dev/vda1", O_RDONLY);
if (fd == -1) {
perror("open");
return -1;
}
// 假设块大小为4KB,inode大小为128字节
const int BLOCK_SIZE = 4096;
const int INODE_SIZE = 128;
// 计算inode所在的块组和块内偏移
const int INODES_PER_GROUP = 1024;
int group = (st.st_ino - 1) / INODES_PER_GROUP;
int inode_offset = (st.st_ino - 1) % INODES_PER_GROUP;
// 读取块组描述符(假设GDT在块1)
struct {
uint32_t bg_inode_table;
} gdt;
lseekseek(fd, 1 * BLOCK_SIZE + offsetof(struct ext2_group_desc, bg_inode_table), SEEK_SET);
read(fd, &gdt.bg_inode_table, sizeof(gdt.bg_inode_table));
// 读取inode的i_block字段(15个块指针)
lseek(fd, gdt.bg_inode_table * BLOCK_SIZE + inode_offset * INODE_SIZE + offsetof(struct ext2_inode, i_block), SEEK_SET);
read(fd, blocks, 15 * sizeof(uint32_t));
close(fd);
return 0;
}
// 解析目录的数据块,输出目录项
int parse_dir_blocks(uint32_t *blocks) {
const int BLOCK_SIZE = 4096;
int fd = open("/dev/vda1", O_RDONLY);
if (fd == -1) {
perror("open");
return -1;
}
// 遍历目录的所有数据块(假设目录仅使用直接块)
for (int i = 0; i < 12 && blocks[i] != 0; i++) {
char block_data[BLOCK_SIZE];
lseek(fd, blocks[i] * BLOCK_SIZE, SEEK_SET);
read(fd, block_data, BLOCK_SIZE);
// 解析块中的所有目录项
int offset = 0;
while (offset < BLOCK_SIZE) {
struct ext2_dir_entry *dir_entry = (struct ext2_dir_entry *)(block_data + offset);
if (dir_entry->inode == 0) {
break; // 没有更多目录项
}
// 输出目录项信息
char name[256];
strncpy(name, dir_entry->name, dir_entry->name_len);
name[dir_entry->name_len] = '\0';
printf("Inode: %-6u Name: %-20s Type: %u\n", dir_entry->inode, name, dir_entry->file_type);
// 移动到下一个目录项
offset += dir_entry->rec_len;
}
}
close(fd);
return 0;
}
int main(int argc, char *argv[]) {
if (argc != 2) {
fprintf(stderr, "Usage: %s <directory_path>\n", argv[0]);
exit(EXIT_FAILURE);
}
uint32_t blocks[15] = {0};
if (get_inode_blocks(argv[1], blocks) == -1) {
exit(EXIT_FAILURE);
}
printf("Directory entries for '%s':\n", argv[1]);
parse_dir_blocks(blocks);
return 0;
}代码编译与运行:
bash
# 编译代码(需root权限,因为要访问磁盘设备)
gcc dir_parser.c -o dir_parser
# 运行程序(解析/home/whb目录的目录项)
sudo ./dir_parser /home/whb输出示例:
Directory entries for '/home/whb':
Inode: 263466 Name: . Type: 2
Inode: 263465 Name: .. Type: 2
Inode: 263467 Name: test.c Type: 1
Inode: 263468 Name: demo.py Type: 1
Inode: 263469 Name: docs Type: 2输出解读:
Type: 2:目录(.、..、docs);Type: 1:普通文件(test.c、demo.py);- 每个文件名都对应一个唯一的 inode 号,与我们之前的认知一致。
3.4 文件名的查找流程:从路径到 inode
当我们访问一个文件(如/home/whb/test.c)时,文件系统的查找流程如下:
- 从根目录开始:根目录的 inode 号是固定的(通常为 2),文件系统先找到根目录的 inode,读取其数据块中的目录项;
- 查找 "home" 目录:在根目录的数据块中,根据文件名 "home" 找到对应的 inode 号(如 263465);
- 查找 "whb" 目录:根据 "home" 的 inode 号,找到其数据块,在目录项中查找 "whb" 对应的 inode 号(如 263466);
- 查找 "test.c" 文件:根据 "whb" 的 inode 号,找到其数据块,在目录项中查找 "test.c" 对应的 inode 号(如 263467);
- 访问文件:通过 "test.c" 的 inode 号,找到其 inode 和数据块,读取文件属性和内容。
这个过程称为 "路径解析" ,本质是不断通过**"目录名→inode 号"**的映射,层层递进,最终找到目标文件的 inode。
3.5 文件名的长度限制
Ext2 文件系统对文件名长度有明确限制:单个文件名最长为 255 字节 (name_len字段为 uint8_t 类型,最大值为 255)。这个限制是由目录项结构中的name_len字段决定的,足够满足绝大多数场景的需求。
需要注意的是,这里的长度限制是指字节数,而非字符数:
- 英文文件名(ASCII 编码):1 个字符占 1 字节,最长 255 个字符;
- 中文文件名(UTF-8 编码):1 个字符占 3 字节,最长约 85 个字符。
总结
Ext2 文件系统的设计充满了 "分而治之" 和 "高效索引" 的智慧:通过块组分区减少磁头移动,通过位图实现资源的快速分配与释放,通过多级间接块支持超大文件,通过目录项映射简化文件访问。这些设计思想不仅影响了后续的 Ext3、Ext4 文件系统,也为其他文件系统(如 XFS、Btrfs)提供了重要参考。
在后续的文章中,我们将继续探讨 Ext2 文件系统的进阶内容:路径缓存(dentry)、分区挂载机制、软硬链接的实现原理等。如果大家有任何疑问或想了解的内容,欢迎在评论区留言讨论!
最后,感谢大家的阅读!如果这篇文章对你有帮助,别忘了点赞、收藏、转发哦~