
⭐️在这个怀疑的年代,我们依然需要信仰。
个人主页:YYYing.
⭐️Linux/C++进阶 系列专栏:【从零开始的linux/c++进阶编程】
⭐️ 其他专栏:【linux基础】【数据结构与算法】【从零开始的计算机网络学习】
系列下期内容:暂无
目录
[2)编译程序,编译选项中需要加上 -g](#2)编译程序,编译选项中需要加上 -g)
前言:
从此篇章开始就到我们的linux/c++进阶篇章了,那么在这一篇中我们先来讲解一下我们的前置所需内容。也就是我们学linux时必须得会的一些技术。
一、man手册的解析以及使用
1、什么是man手册?
我们不妨看看linux是怎么给我们解释的
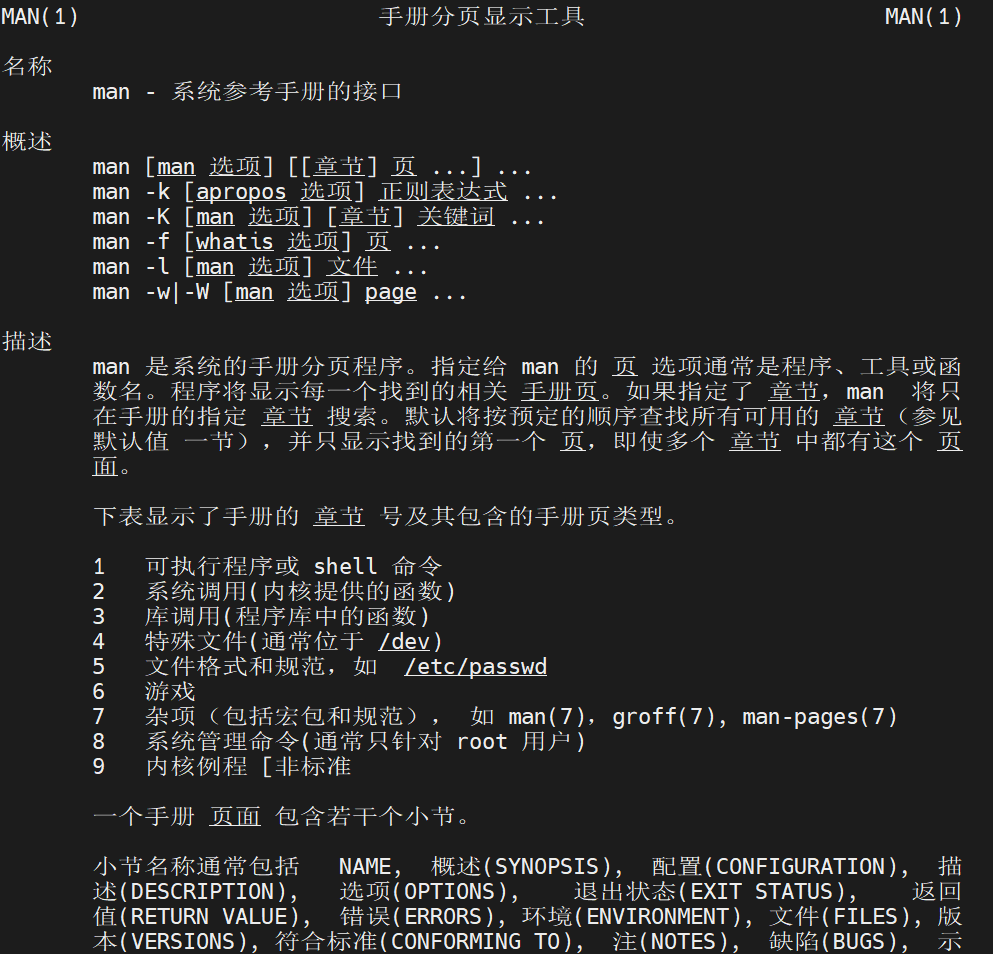
那么其实就是linux系统提供的有关函数或指令介绍的相关帮助手册,可以在该手册也中查看函数、指令的功能,说白了就是相关操作的使用说明书,一共有七章内容,主要使用前三章,第一章是shell指令相关说明,第二章是系统调用函数相关说明(重点),第三章是库函数(重要)
2、man手册的使用
只需要键入 man + 相关函数/指令即可
退出手册:键入 q
比如我们想看看ls的指令
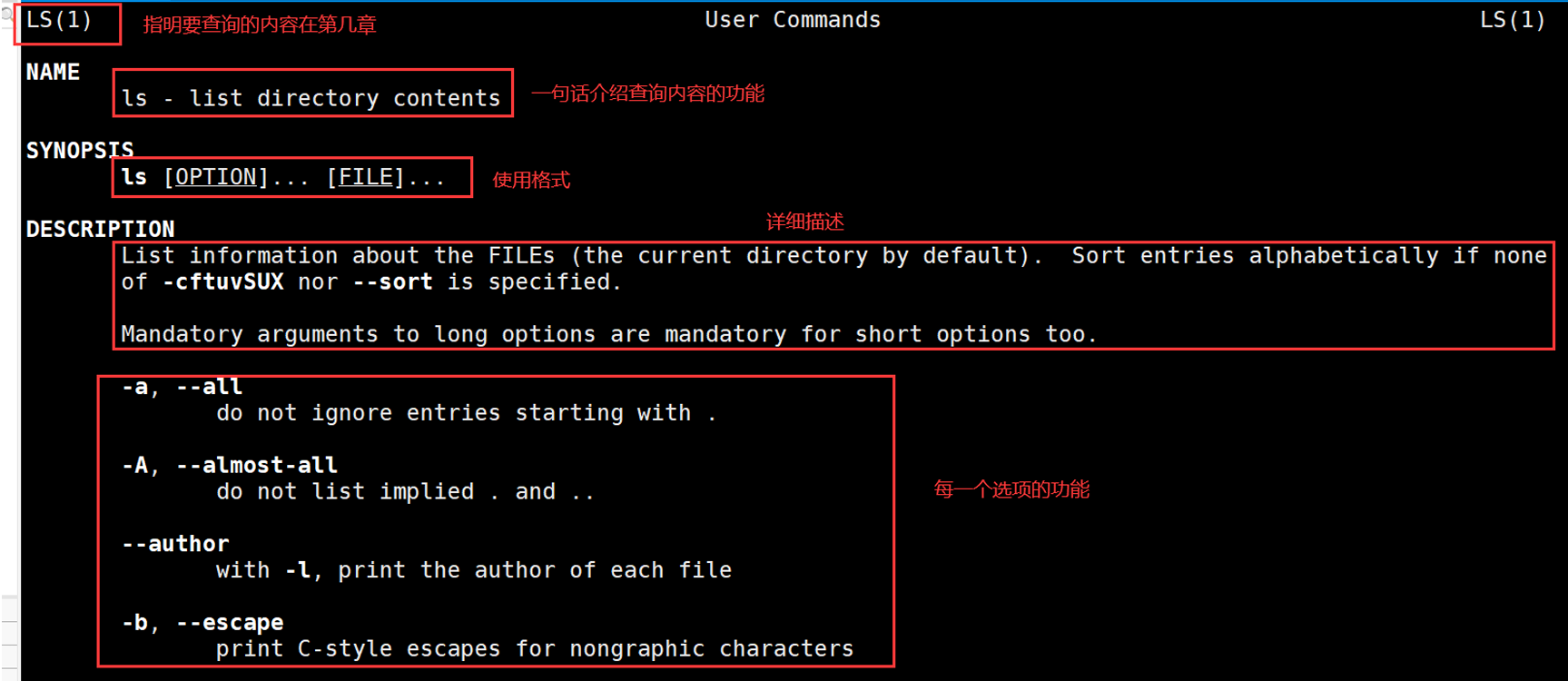
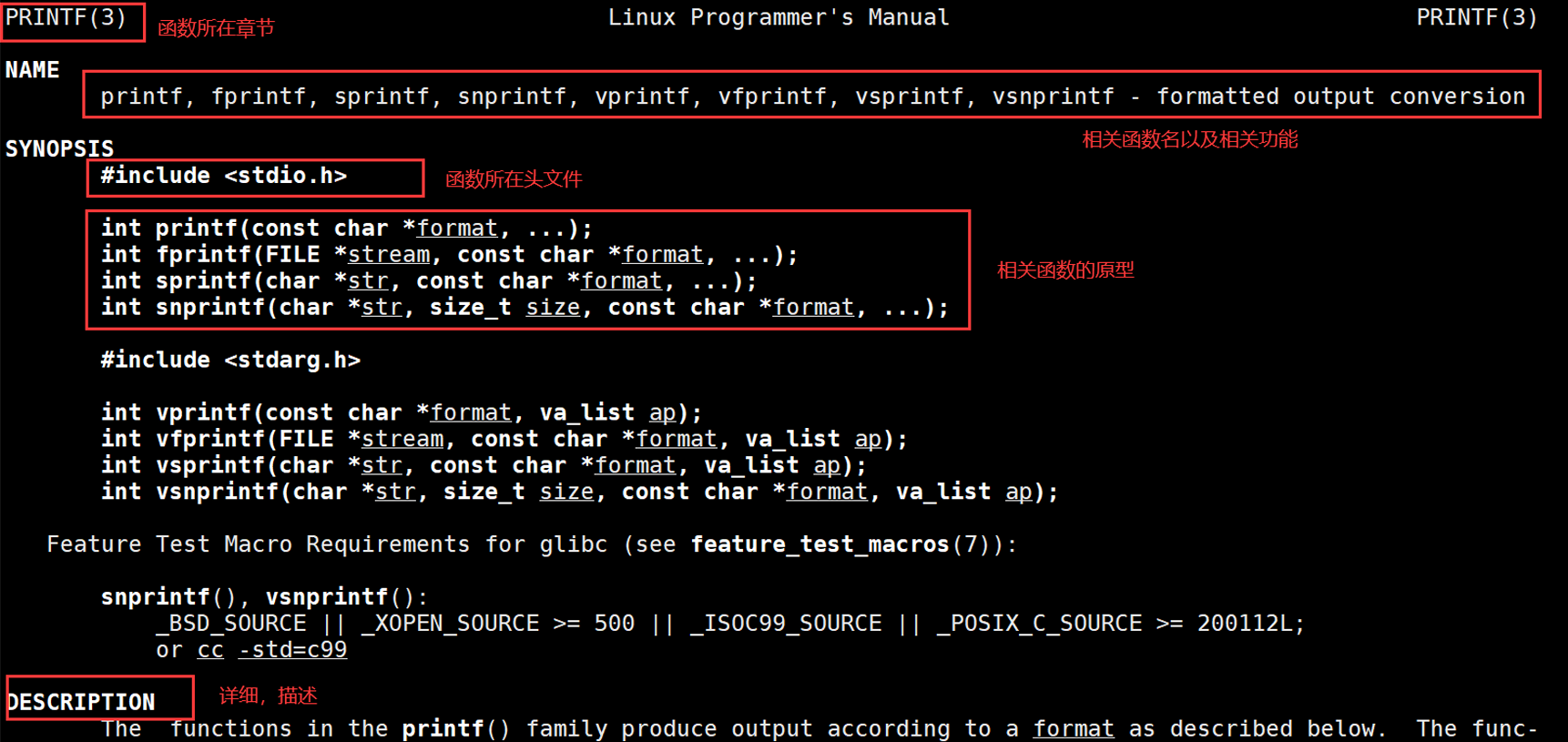
如果想要查看C语言库函数相关功能,需要安装相关库
cpp
// ubuntu
sudo apt install man-pages man-pages-devel
// centos
sudo yum install man-pages man-pages-devel然后我们就可以查看了:
二、常用内核提供的函数库
1、文件的操作:open()、read()、write()、close()、lseek() 等等
2、进程控制函数:fork()、exit()、wait()、execl()等等
3、信号操作:kill()、signal()等等
4、网络通信:socket()、bind()、listen() 等等
虽然我们还没讲,但我们可以来看看例子
cpp
#include<iostream>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<string.h>
#include<stdio.h>
#include<error.h>
#include<unistd.h>
using namespace std;
int main(){
//1、定义文件描述符,并打开文件
int fd = -1;
if((fd = open("./test.txt", O_WRONLY|O_CREAT|O_TRUNC, 0664)) ==-1){
perror("open error");
return -1;
}
//2、读写文件
write(fd, "hello", strlen("hello"));
//3、关闭文件
close(fd);
}三、使用GDB调试程序
1、两种bug信息
在linux系统下,当程序出现bug时,linux终端会给大家两种不同的信息
警告(warning):有时的警告是不影响可执行程序的产生

错误(error):错误如果不改正,是不能生产可执行程序的
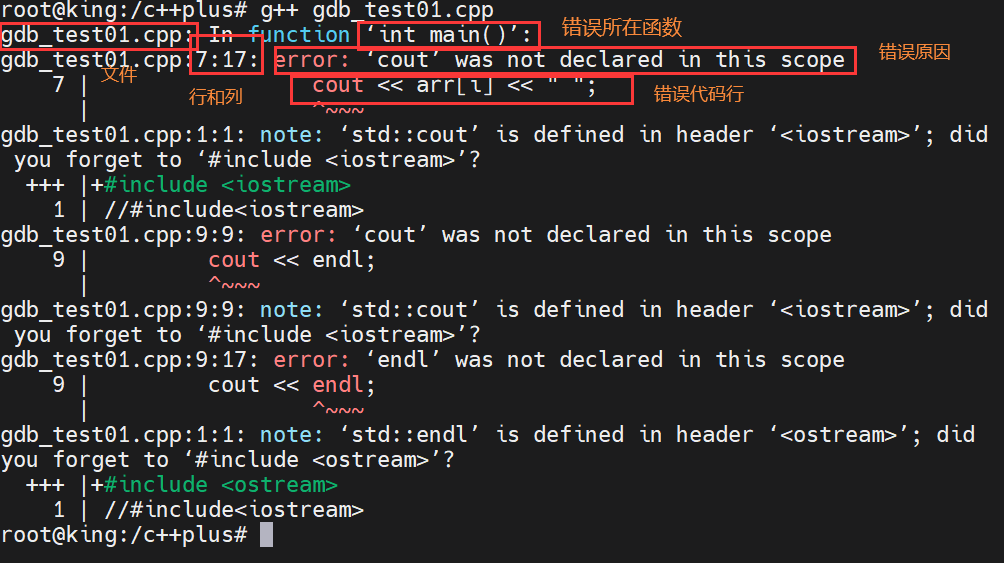
警告可以被忽略,继续产生可执行程序,但是错误必须更改后才能产生可执行程序
如果你用过gcc,那么就会发现相比于gcc编译器,g++编译器要求更加严格,当然这点了解即可。
2、什么是GDB?
我们可以看官网是怎么说的:https://www.sourceware.org/gdb/

------ GDB, GNU项目调试器,允许您查看一个程序执行时"内部"发生了什么,或者一个程序崩溃时 正在做什么。
3、GDB是干什么的?
当然下一句就是我们的信息
gdb只干四件事:
**●**启动程序,指定可能影响其行为的任何内容。
**●**使程序在指定条件下停止。
**●**检查程序停止时发生了什么。
**●**更改程序中的内容,这样您就可以尝试纠正一个错误的影响,并继续了解另一个错误。
4、GDB如何使用
1)准备我们的程序:
cpp
#include<iostream>
#include<cstdio>
using namespace std;
int main(){
int arr[5] = {1,2,3,4,5};
for(int i=0;i<5;i++){
cout << arr[i] << " ";
}
cout << endl;
return 0;
}2)编译程序,编译选项中需要加上 -g
cpp
g++ -g xxx.cpp -o xxx3)启动gdb调试
cpp
gdb ./xxx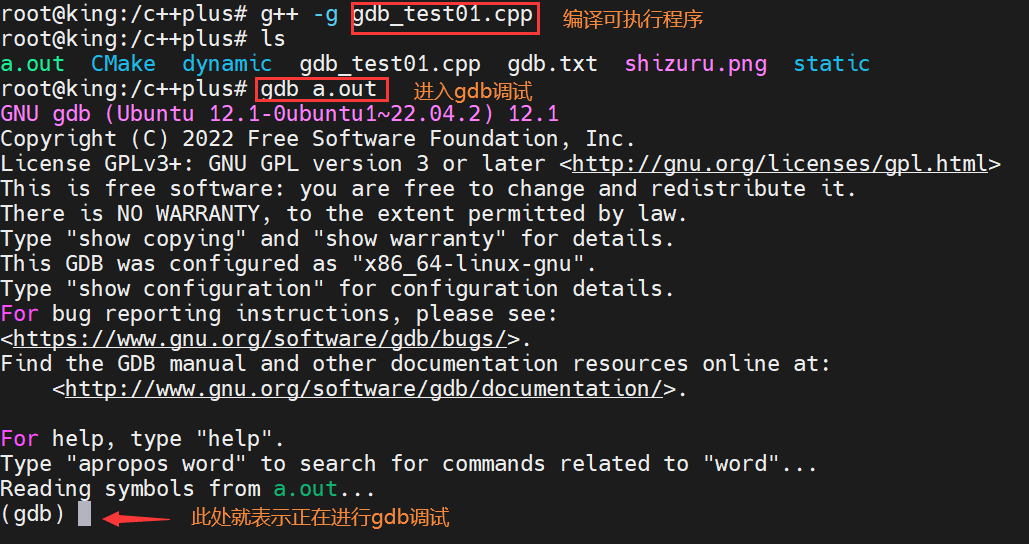
4)gdb常用指令
quit(q):表示退出gdb调试
run(r):表示执行可执行程序,如果没有设置断点,则将整个程序从头到尾执行一遍
list(l):展示可执行程序的相关行信息,默认展示10行
list m,n :表示展示从m行到n行的信息
list func:表示展示func函数旁边的相关程序
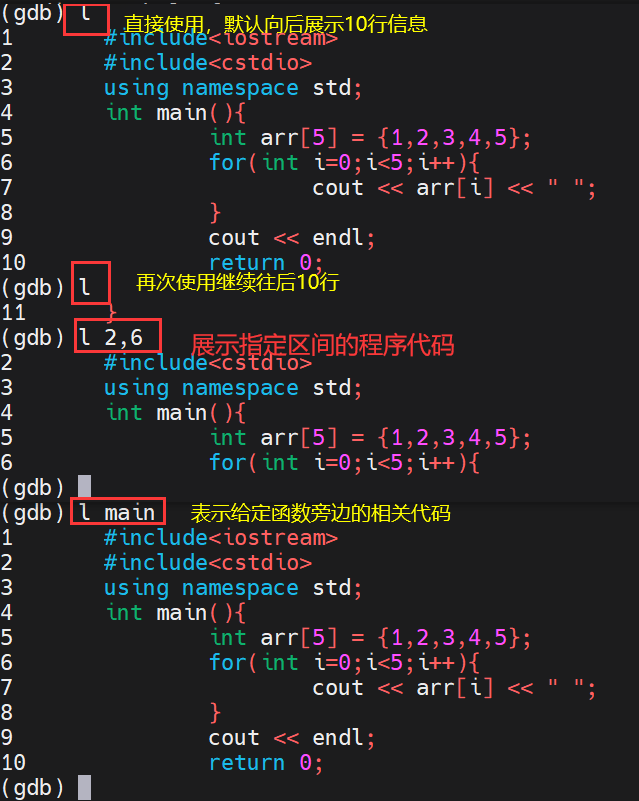
break(b):表示设置断点,当调试器将程序运行到断点所在位置后,会暂停于此
break 行号:表示在某行设置断点
break func:表示在指定的函数处设置断点
info break:查看所有断点的信息
delete breakpoint 断点编号:表示删除指定的断点
next(n):表示执行下一条语句
continue(c):表示从断点处继续向后执行,直到遇到下一个断点或者程序结束
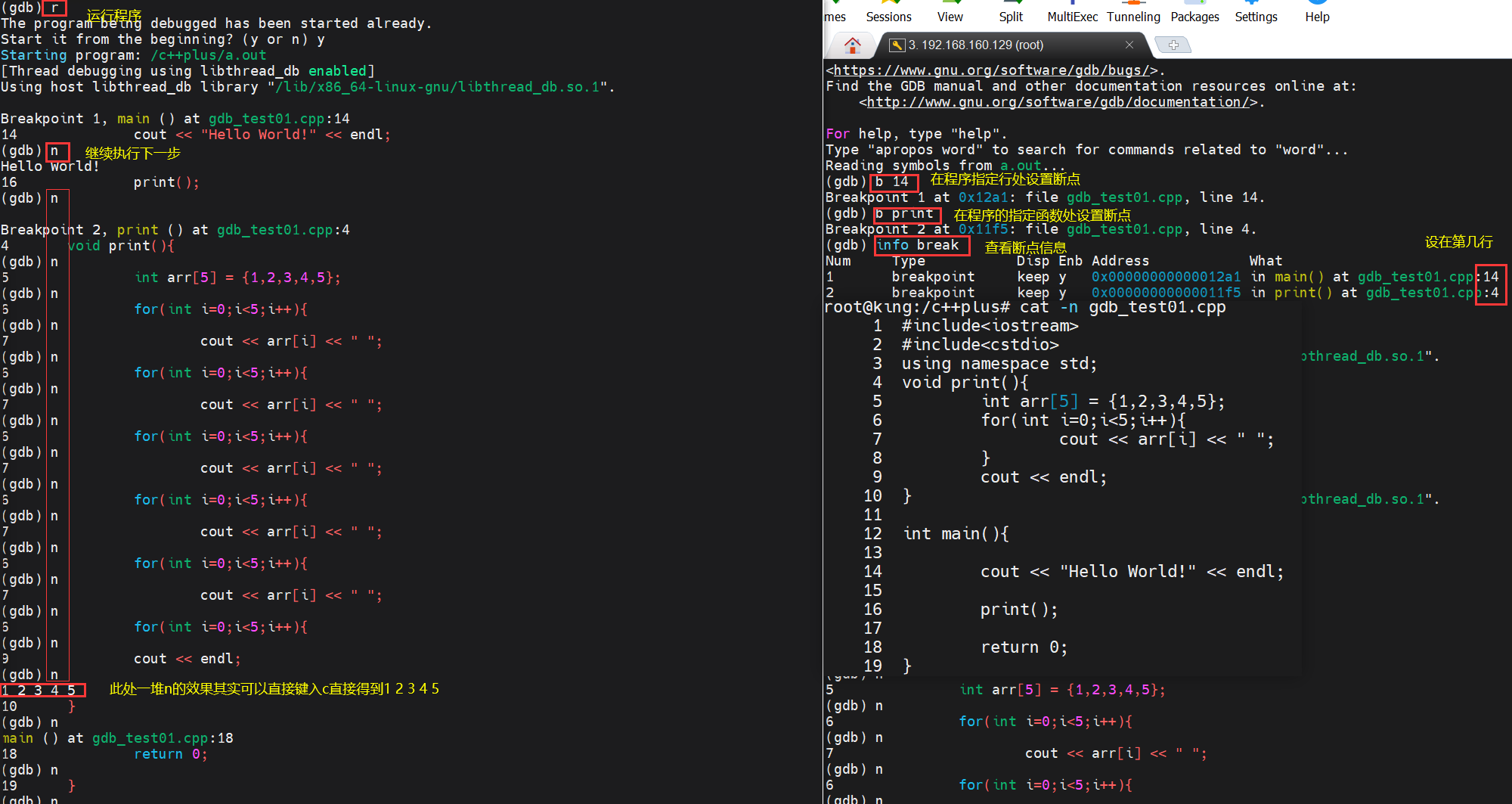
step(s):能够跳入到指定函数中,查看相关函数内部代码
print(p):变量名/地址 :表示打印指定变量或地址信息
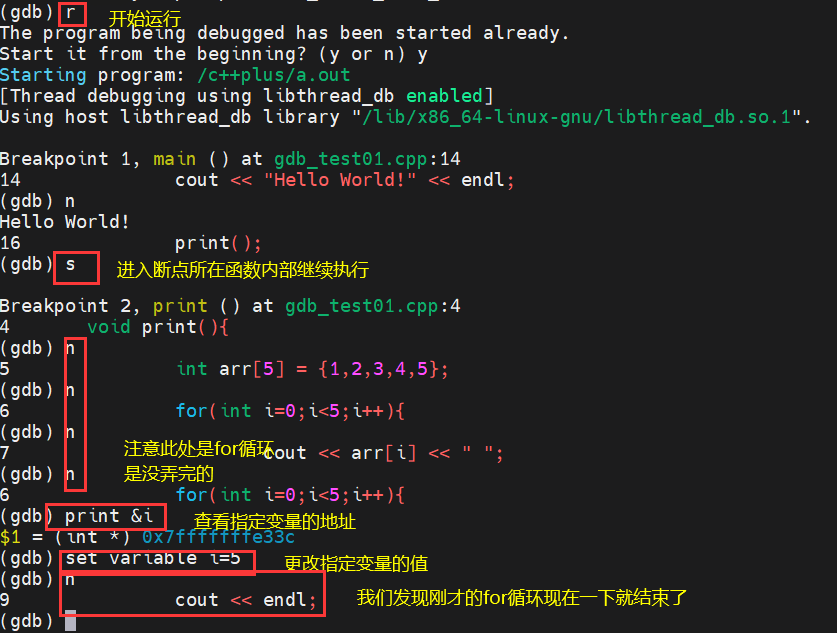
5)gdb使用小技巧
shell :后面可以跟终端指令,表示执行终端相关操作
set logging on:设置开启日志功能,会在当前目录中生成一个gdb.txt文件记录接下来的调试内容
watchpoint :观察点,如果设置的观察点的值发生改变,则会将该值的旧值和新值全部展示出来
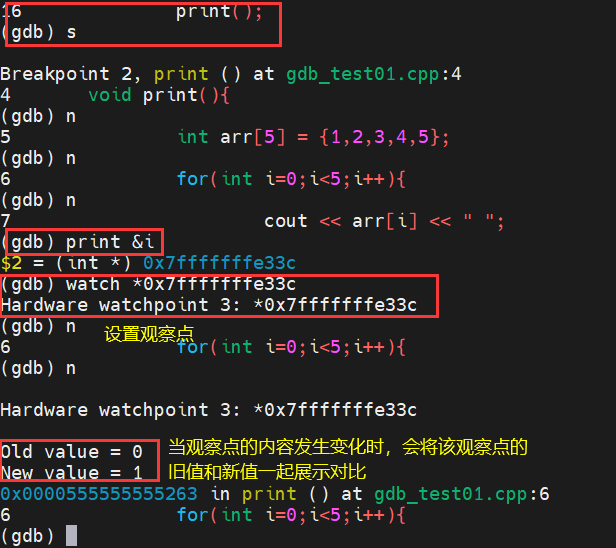
6)gdb调试出错的文件
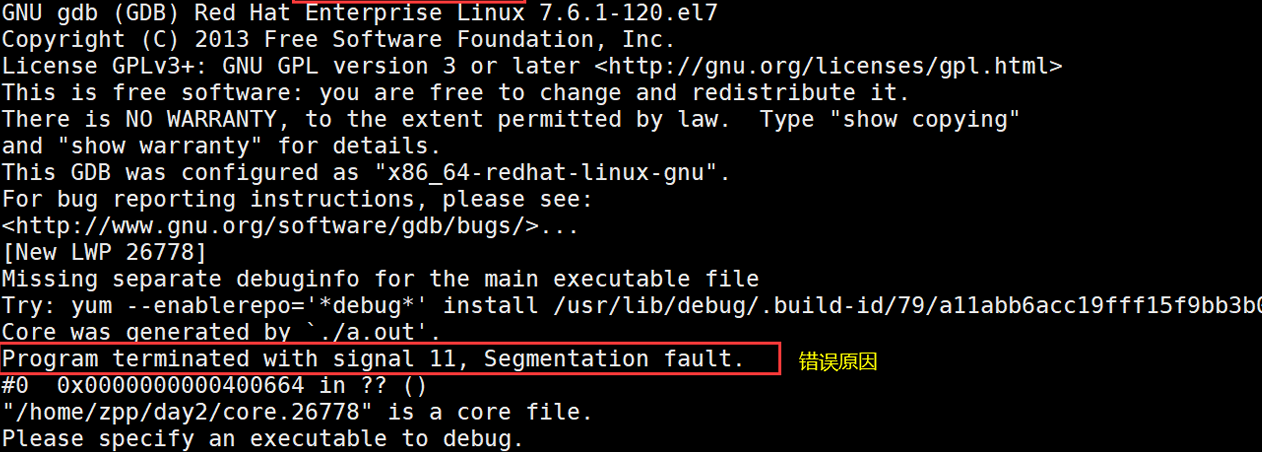
当一个可执行程序出现错误时,会产生一个core文件,用于查看相关错误信息
linux系统默认是不产生core文件,需要进行相关设置后才能产生
通过 ulimit -a 查看所有linux的限制内容
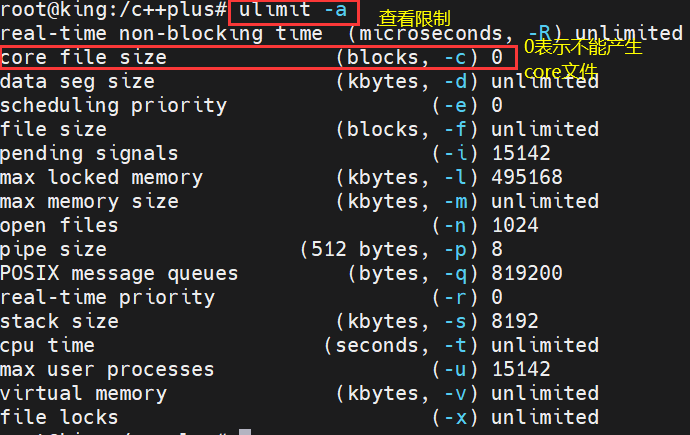
通过 ulimit -c unlimited来设置core文件的个数

查看错误原因
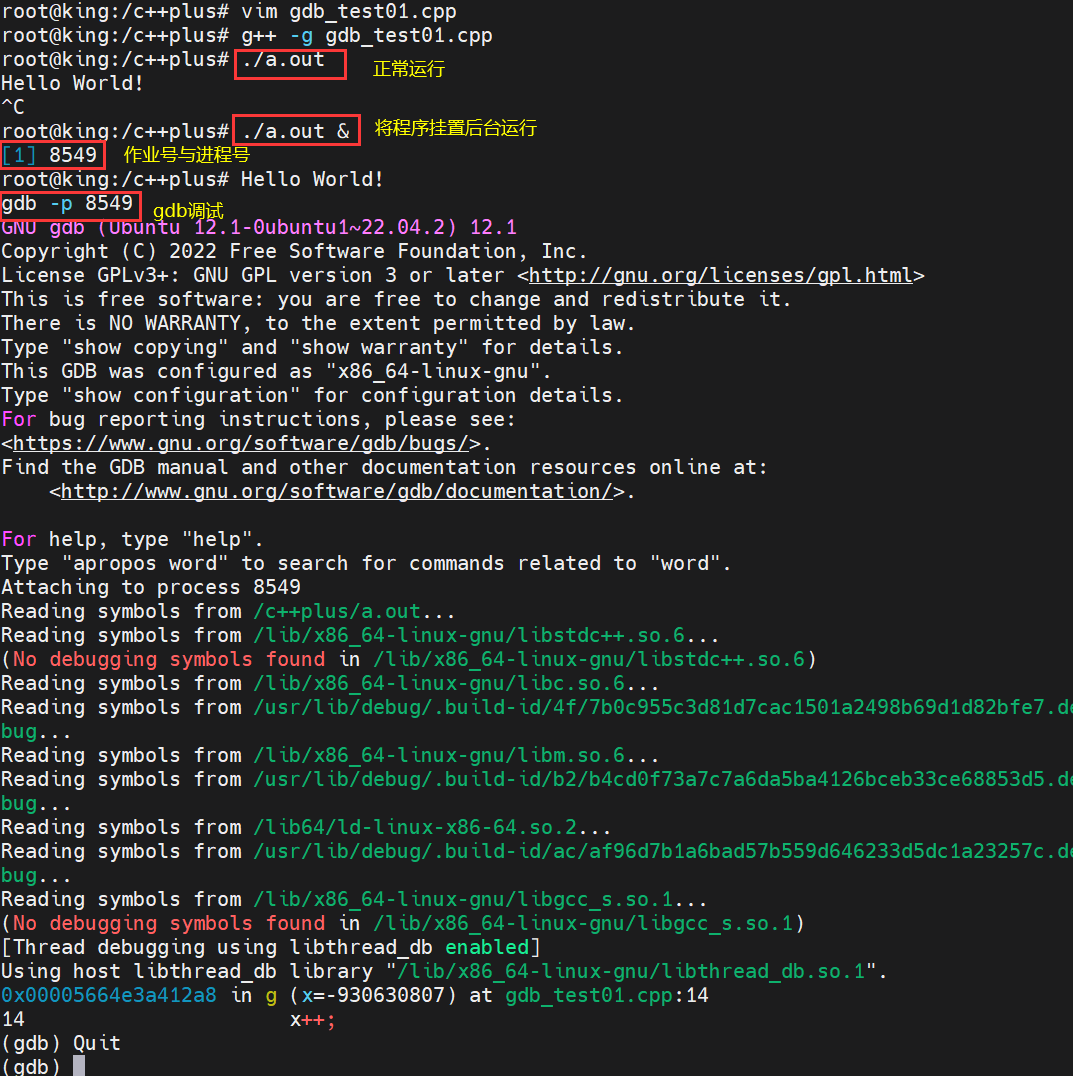
7)gdb调试其他正在运行的进程
./可执行程序 & :表示将可执行程序后台运行,不占用当前终端
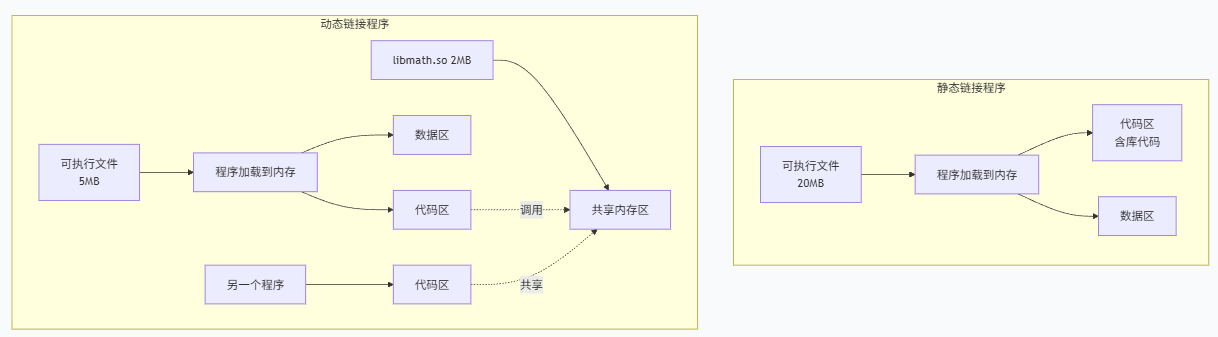
四、动态库与静态库
1、库是什么?
库在linux中是一个二进制文件,它是由 .cpp文件(不包含main函数)编译而来,其他程序如果想要使用该源文件中的函数时,只需在编译生成可执行程序时,链接上该源文件生成的库文件即可。库中存储的是二进制文件,不容易被窃取知识产权,做到了保护作用。
库在linux系统中分为两类,分别是静态库和动态库
windows:
***.lib:静态库
***.dll:动态库
linux:
***.a:静态库
***.so:动态库
-
静态库:在程序编译链接时,库的代码被完整地复制到最终的可执行文件中。程序运行时不再需要原来的静态库文件。
-
动态库:在程序编译链接时,只在可执行文件中记录需要使用的动态库中的符号(函数、变量等),而不复制库的代码。程序运行时,由操作系统动态地将动态库加载到内存,多个程序可以共享同一个动态库在内存中的副本。
2、为什么引入库?
在下述案例中,主程序要是有的源程序代码,在add.cpp中,如果项目结束后,到了交付阶段,由于主程序的生成需要其他程序联合编译,那么就要将源程序打包一起发给老板,这样该程序的开发者自身的价值就不大了,该项目的知识产权就很容易被窃取。为了保护我们的知识产权,我们引入了库的概念
编译选项:
-c:仅编译,生成.o目标文件;
-fPIC:生成位置无关代码(动态库必备);
-shared:生成动态库;
-static:强制静态链接(需系统安装静态库版本,如 libc.a);
-L:指定库的搜索路径;
-l:指定库名;
我们现在来实战一下
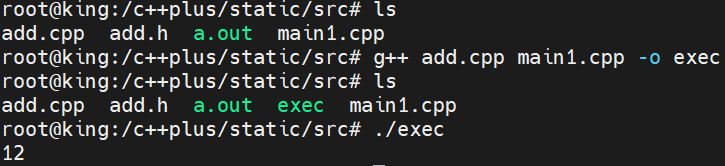
3、静态库及其制作
概念 :将一个***.cpp的文件编译生成一个 lib***.a的二进制文件,当你需要使用该源文件中的函数时, 只需要链接该库即可,后期可以直接调用
静态体现在:在使用g++编译程序时,会将你的文件和库最终生成一个可执行程序(把静态库也放入到可执行程序中),每个可执行程序单独拥有一个静态库,体积较大,但执行效率较高
1)编译生成静态库
cpp
g++ -c ***.cpp -o ***.o 只编译不链接生成二进制文件
ar -crs lib***.a ***.o 编译生成静态库
如果有多个.o文件共同编译生成静态库 :ar -crs lib***.a ***.o xxx.o ...
ar:用于生成静态库的指令
c:用于创建静态库
r:将文件插入或者替换静态库中同名文件
s:重置静态库索引2)使用静态库
cpp
g++ main.cpp -L 库的路径 -l库名 -I 头文件的名字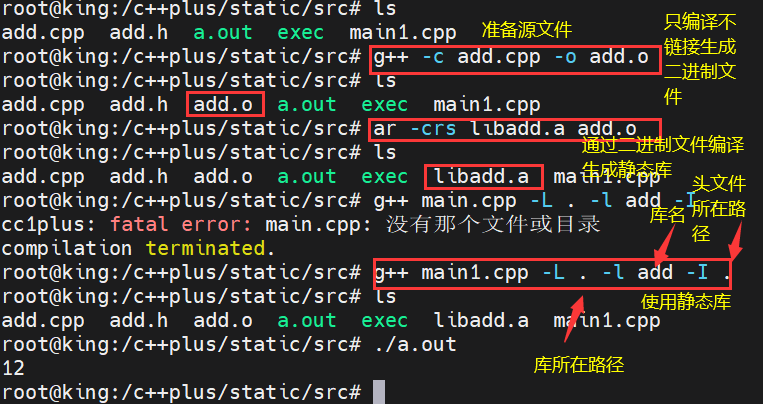
实战完后,我们会发现我们的文件是不是有点乱啊,我们现在分文件来搞一下。
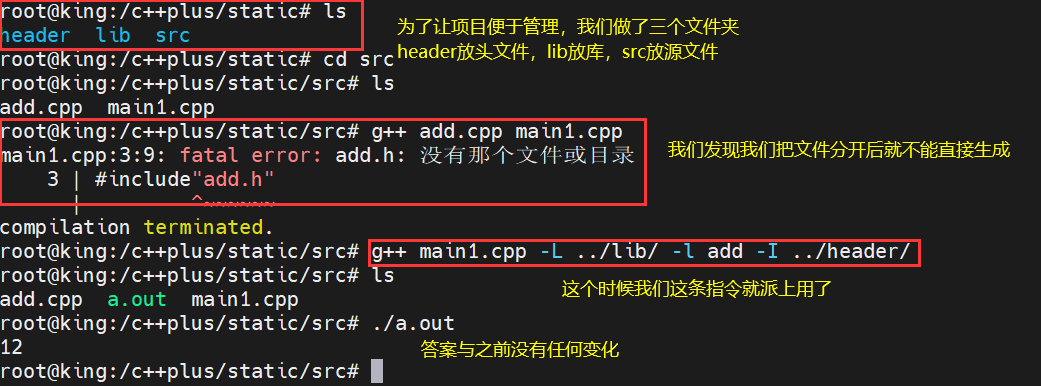
4、动态库及其制作
概念 :将一个***.cpp的文件编译生成一个 lib***.so的二进制文件,当你需要使用该源文件中的函数时,只需要链接该库即可,后期可以直接调用
动态体现在:在使用g++编译程序时,会将你的文件和库中的相关函数的索引表一起生成一个可执行程序,每个可执行程序只拥有函数的索引表,当程序执行到对应函数时,会根据索引表,动态寻找相关库所在位置进行调用,体积较小,执行效率较低,但是可以多个程序共享同一个动态库,所以,动态库也叫共享库。
1)编译生成动态库
cpp
g++ -fPIC -c ***.cpp -o ***.o 编译生成二进制文件
g++ -shared ***.o -o lib***.so 依赖于二进制文件生成一个动态库值得一提的是**,跟我们静态库不一样,这里的两个指令可以合成一个指令**
cpp
g++ -fPIC -shared ***.cpp -o lib***.so 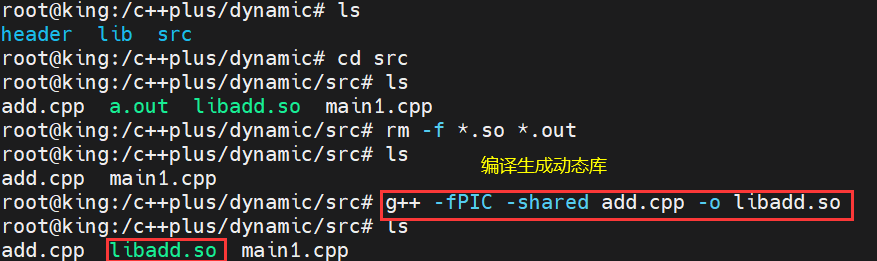
2)使用动态库
cpp
g++ main.cpp -L 库的路径 -l库名 -I 头文件的名字
运行出错是因为我们动态库必须要放在我们的系统路径里面,也就是我们系统的lib64文件中
3)以上错误内容的解决方案
方式1:更改路径的宏
cpp
export LD_LIBRARY_PATH=库的路径
只是临时有效
方法2:将自己的动态库放入到系统的库函数目录中 (/lib64 /usr/lib64)
在用这个方法之前,如果我们用过之前那个方法,我们需要把之前库的路径改回系统路径:
cpp
export LD_LIBRARY_PATH=/usr/lib64
但这种方法不推荐使用,可能会污染路径
方法3:将库路径写入 /etc/ld.so.conf,执行 ldconfig 更新缓存
方法4:用 -Wl,-rpath=/path/to/so 参数,将库路径嵌入可执行文件(推荐工业级使用)
后面两种方法在此就不再演示了,大家可以自己去玩玩。
5、两者的核心区别
|-------------|-----------------------------------------------|---------------------------------------------------------|
| 维度 | 静态库(.a) | 动态库(.so) |
| 链接阶段 | 编译时静态链接,将库代码复制到可执行文件中 | 编译时动态链接,仅记录库的引用信息,运行时才加载库 |
| 可执行文件大小 | 较大(包含库代码) | 较小(仅包含引用) |
| 内存占用 | 多个程序使用同一库时,会在内存中存在多份副本 | 多个程序共享同一份库代码(内存中仅一份),节省内存 |
| 更新维护 | 库更新后,依赖它的程序需重新编译链接 | 库更新后,无需重新编译程序,直接替换库文件即可(需保证接口兼容) |
| 运行依赖 | 不依赖外部库文件,可独立运行 | 依赖动态库文件,运行时若库缺失则报错 |
| 链接速度 | 较快(直接复制代码) | 较慢(需处理动态引用) |
| 使用场景 | 1. 程序需独立部署(无外部依赖);2. 库体积小,更新频率低;3. 对运行时性能要求极高 | 1. 多个程序共享同一库(如系统库 libadd.so);2. 库体积大,更新频率高;3. 需动态扩展功能 |
结语
那么关于linux/c++进阶篇前置的部分基础讲解就到这里了。
我是YYYing,后面还有更精彩的内容,希望各位能多多关注支持一下主包。
无限进步, 我们下次再见。
---⭐️ 封面自取 ⭐️---
