一:Flink概述
1:Flink vs Spark Streaming
Spark以批处理为根本 :Spark使用的时候,需要设置一个批次间隔。攒够间隔之后,就处理这个批次的数据,他是一个批次的数据。
Spark数据模型 :Spark采用RDD魔心,Spark Streaming的DStream实际上就是一组组小批数据的RDD的集合
Spark运行时架构: Spark是批计算,将DAG划分为不同的stage,一个完成之后在计算下一个。

**Flink数据模型:**Flink基本数据模型是数据流,来一条数据,处理一条数据。以及事件(Event)序列
Flink运行时架构:flink是标准的流执行模式,一个事件在一个节点处理完后可以直接发往下一个节点进行处理
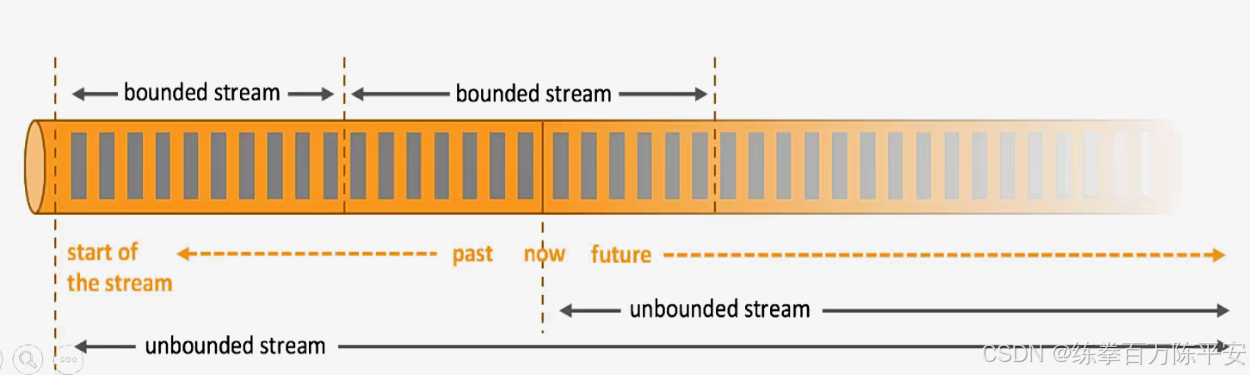
2:总结对比
|-------|-----------|-------------------|
| | Flink | Spark Streaming |
| 计算模型 | 流计算 | 微批处理 |
| 时间语义 | 事件处理、处理时间 | 处理时间 |
| 窗口 | 多、灵活 | 少、不灵活(窗口必须是批次整数倍) |
| 状态 | 有 | 没有 |
| 流式SQL | 有 | 没有 |
3:flink的应用场景
指标构建、数据分析、数据清洗等。
4:flink分层API
|-----------|-----------------------|---|
| 最高层语言 | SQL | |
| 声明式领域专用语言 | Table APIs | |
| 核心APIS | DataStream DataSetApi | |
| 底层APIs | 有状态流处理 | |
有状态流处理:
通过底层API对原始数据加工处理,底层API与DataStreamAPI相集成,可以处理复杂的计算。
DataStream API【流处理】和DataSet API【批处理】
封装了底层处理函数,提供了通用的模块,比如转换(transformations,包括map、flatmap等),连接(joins),聚合(aggregations),窗口(windows)操作等。
注意:Flink1.12以后,DataStream API已经实现真正的流批一体,所以DataSetAPI已经过时。
TableAPI是以表为中心的声明式编程
其中表可能会动态变化:同时API提供可比较的操作,例如select、project、join、group-by、aggregate等。我们可以在表与DataStream/DataSet 之间无缝切换,以允许程序将Table API与DataStream 以及DataSet 合使用。
SQL这一层在语法与表达能力上与TableAPI类似
SQL查询表达式的形式表现程序。SQL抽象与TableAPI交互密切,但同时SQL查询可以直接在TableAPI定义的表上执行。
二:Flink读取有界流
我们快速搭建一个基于Flink的程序,实现快速上手。这里以单词统计为例子。
1:添加依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.dashu</groupId>
<artifactId>flink170</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<flink.version>1.17.1</flink.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
</dependencies>
</project>
flink-streaming-java:是 Apache Flink 流处理的核心依赖,也是开发 Flink 流式计算任务的基础。
它包含了 Flink 流处理的核心 API(如 DataStream、StreamExecutionEnvironment)、算子、时间处理和状态管理等核心能力,是编写 Flink 流式作业的必备依赖。
所有基于 Java 的 Flink 流处理逻辑(如数据读取、转换、计算)都依赖该模块提供的底层能力。
flink-clients是 Flink 的客户端依赖,主要负责将编写好的 Flink 作业提交到集群(或本地运行),包含作业提交、参数解析、集群通信、任务执行模式(本地 / 集群)管理等功能。
没有该依赖,无法将编写好的流处理代码打包并提交到 Flink 集群运行,本地调试 Flink 作业也需要该依赖来启动本地执行环境,是连接开发者代码与 Flink 执行引擎的关键桥梁。
总结一下:
flink-streaming-java是流处理核心:提供编写流式计算逻辑的所有基础 API 和能力;
flink-clients是提交执行核心:负责作业的提交、运行和与集群的交互。
2:编写代码
1:批处理实现word count
这种写法已经过时了。
package com.dashu.worldcount;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.AggregateOperator;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.FlatMapOperator;
import org.apache.flink.api.java.operators.UnsortedGrouping;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
public class wordCountBatch {
public static void main(String[] args) throws Exception {
// 创建执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 从文件中读取数据
DataSource<String> lineDS = env.readTextFile("D:\\code\\flink\\flink-1.17\\target\\classes\\input\\word.txt");
// 调用算子切分转换
FlatMapOperator<String, Tuple2<String, Integer>> wordAndOne = lineDS.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> collector) throws Exception {
// 按照空格切分单词
String[] words = value.split(" ");
for (String word : words) {
Tuple2<String, Integer> wordTuple = Tuple2.of(word, 1);
// 使用colletor往下游发送数据
collector.collect(wordTuple);
}
}
});
// 按照单词分组
// 按照位置0分组
UnsortedGrouping<Tuple2<String, Integer>> worldAndOneGroupBy = wordAndOne.groupBy(0);
// 分组内聚合
// 按照位置1聚合
AggregateOperator<Tuple2<String, Integer>> sum = worldAndOneGroupBy.sum(1);
// 输出
sum.print();
}
}
SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
(flink,1)
(world,1)
(hello,3)
(java,1)2:流处理实现word count
1.12开始官方推荐使用DataStream API
package com.dashu.worldcount;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.operators.AggregateOperator;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.FlatMapOperator;
import org.apache.flink.api.java.operators.UnsortedGrouping;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class wordCountStream {
public static void main(String[] args) throws Exception {
// 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 从文件中读取数据
DataStreamSource<String> lineDS = env.readTextFile("D:\\code\\flink\\flink-1.17\\target\\classes\\input\\word.txt");
// 调用算子切分/转换/分组/聚合
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = lineDS.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
// 按照空格切分
String[] s = value.split(" ");
for (String word : s) {
// 转换成二元组
Tuple2<String, Integer> wordAndOne = Tuple2.of(word, 1);
// 通过采集器向下游发送数据
out.collect(wordAndOne);
}
}
});
// 按照单词分组
// 按照位置0分组
KeyedStream<Tuple2<String, Integer>, Object> wordAndOneKs = wordAndOne.keyBy(new KeySelector<Tuple2<String, Integer>, Object>() {
@Override
public Object getKey(Tuple2<String, Integer> value) throws Exception {
return value.f0;
}
});
// 分组内聚合
SingleOutputStreamOperator<Tuple2<String, Integer>> sumDS = wordAndOneKs.sum(1);
// 按照位置1聚合
// 输出
sumDS.print();
// 触发执行
env.execute();
}
}
SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
13> (flink,1)
9> (world,1)
5> (hello,1)
5> (hello,2)
5> (hello,3)
3> (java,1)这就能看出来,啥叫流处理:来一条、计算一条、输出一条。
这里边也体现出来了一个东西:状态:flink将hello,2这个中间状态计算存储到自己内存当中。这就是有状态的计算。
到这里,我们操作的是文件,读文件的话就是有界流。最后,我们搞一下流处理和批处理代码上的区别
3:流处理和批处理区别
1:执行环境不一样StreamExecutionEnvironment和ExecutionEnvironment
2:执行算子大致都一样,一个是keyby 一个是group by
3:DataStream当中,excute方法是必须要调用的。不调用不执行。
三:无界流编码
1:编写无界流
package com.dashu.worldcount;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class wordCountUnboundedStream {
public static void main(String[] args) throws Exception {
// 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 从socket当中读取数据
DataStreamSource<String> lineDS = env.socketTextStream("192.168.67.137",7777);
// 调用算子切分/转换[二元组]/分组/聚合
lineDS
.flatMap((String value, Collector<Tuple2<String, Integer>> out)-> {
// 按照空格切分
String[] s = value.split(" ");
for (String word : s) {
// 转换成二元组
Tuple2<String, Integer> wordAndOn = Tuple2.of(word, 1);
// 通过采集器向下游发送数据
out.collect(wordAndOn);
}
})
.returns(Types.TUPLE(Types.STRING,Types.INT))//解决泛型擦除的问题。
.keyBy((Tuple2<String, Integer> value)->value.f0)
.sum(1)
.print();
// 触发执行
env.execute();
}
}2:安装netcat
[root@localhost ~]# yum install -y netcat
# 持续监听7777端口
[root@localhost ~]# nc -lk 7777
hello flink
hello shit
hello java
hello baby
hello gay
hello boy
hello hello
hello every3:查看结果
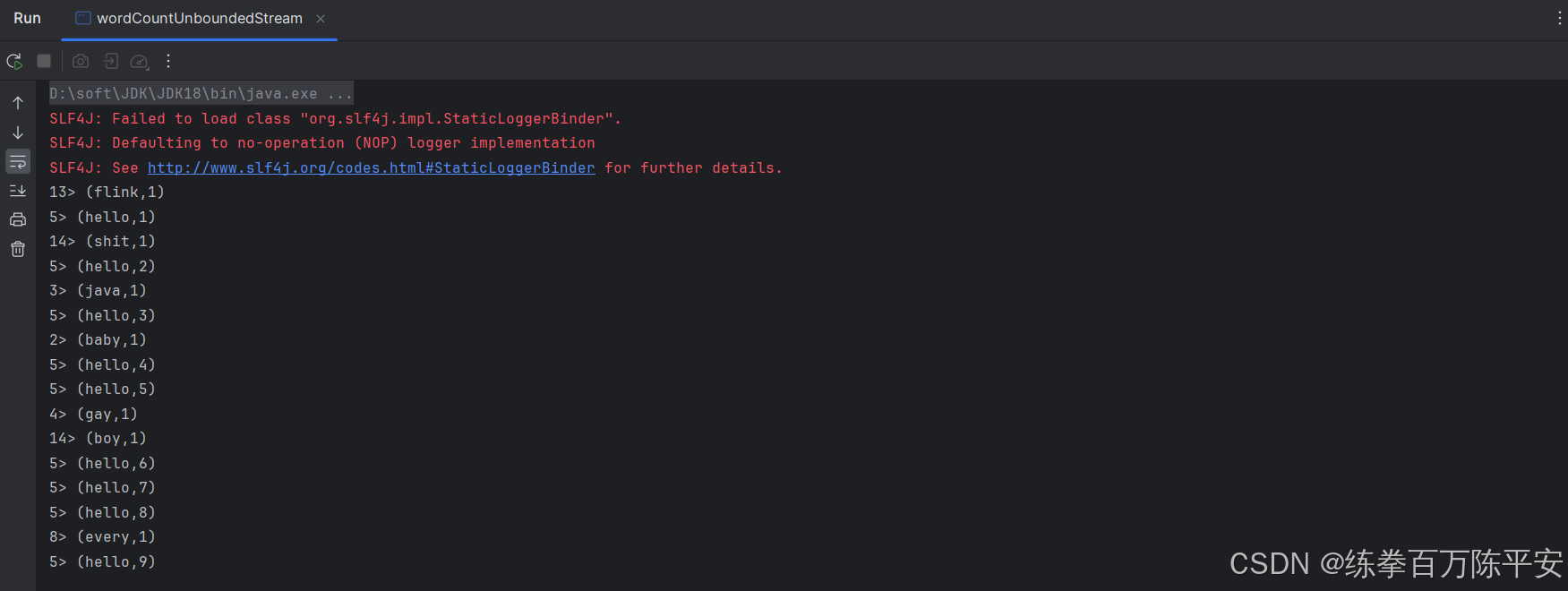
程序启动起来之后,一直在运行,不终止。监听socket。
从日志中我们,也可以看见真正的流的状态:来一条,处理一条,输出一次结果。这就是事件驱动,如果没有数据flink动都不带动的。
flink是有状态的计算,处理无界流的时候,整个的状态都在Flink当中运行。
SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
13> (flink,1)
5> (hello,1)
14> (shit,1)
5> (hello,2)
3> (java,1)
5> (hello,3)
2> (baby,1)
5> (hello,4)
5> (hello,5)
4> (gay,1)
14> (boy,1)
5> (hello,6)
5> (hello,7)
5> (hello,8)
8> (every,1)
5> (hello,9)