注意:全平台付费的文献,需要你有下载权限,不能免费下载。
文章目录
- 一、Zotero简介
- 二、文献检索和导出
- 三、文献批量下载
-
- [3.1 理论:Zotero如何下载文献?](#3.1 理论:Zotero如何下载文献?)
- [3.2 操作](#3.2 操作)
-
- [3.21 导入文献](#3.21 导入文献)
- [3.22 获取全文](#3.22 获取全文)
- [3.4 处理没有获取到的文献](#3.4 处理没有获取到的文献)
- [3.5 附:整理zotero下载的文献](#3.5 附:整理zotero下载的文献)
- [四、zotero 的AI 插件](#四、zotero 的AI 插件)
一、Zotero简介
Zotero是一个免费的开源文献管理软件。
- 支持:win、mac、linux;
- 包含桌面端软件和浏览器插件;
- 开源:就有很多插件可供增强软件的功能;
- 免费:但是别人开发的插件可能是付费的,以及云同步的空间扩展也是付费的。
🟢github:https://github.com/zotero/zotero
🟢中文社区:https://zotero-chinese.com/
🟢快速入门指南:https://zotero-chinese.com/user-guide/quick-start
最新的版本是:8.0.1(前天:26-01-27)发布的,本文使用的是这个版本。
🧩最近几个大版本更新时间和主要变化:
| 版本号 | 正式发布日期 | 核心更新内容(精简版) |
|---|---|---|
| Zotero 8 | 2026年1月22日 |
全新引文对话框、列表内查看注释、开启快速更新周期 |
| Zotero 7 | 2024年8月9日 | 界面全面现代化、原生支持苹果 M 系列芯片、新增 EPUB 阅读器 |
| Zotero 6 | 2022年3月17日 | 首创内置 PDF 阅读器、上线 iOS 移动端、引入划线提炼笔记功能 |
现在起:Zotero更新频率会加快,一到三个月就会更新一个大版本,中间会有很多小版本更新。
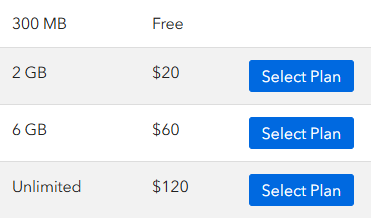
如果要使用这个软件的云同步功能,需要注册账号,然后在网页端、浏览器插件、软件里面(要登录并开启同步)、不同电脑上,就可以同步了,不过免费的存储空间只有300MB,下图是年费价格:
自己下载安装就行了。本文不用浏览器插件,你也可以安装,也挺有用的;本文也不用云同步功能。
本文主要简单讲一下借助这个软件实现英文文献的批量下载。
操作和之前讲的中文文献批量下载(用知网研学)是类似的。
- 知网文献也可以用这个软件的,操作和下文讲的应该差不多的。
- 插件自己看着装吧,中文装一下茉莉花
Jasminum(英文中文可能会有命名不友好的情况),英文可以装一下翻译插件之类的。
二、文献检索和导出
web of science 检索文献后,导出:
- RIS格式;
- Records from:这个一次最多导出1000条,要分多次导出,如:1-1000,1001-2000
- Full Record
保存的.ris文件(纯文本)就是每篇文献的元数据,如:标题、作者、年份、DOI、期刊等等一大堆。
三、文献批量下载
3.1 理论:Zotero如何下载文献?
🟢 (1)先找文献的开放获取渠道
这是 Zotero 最主要的合法下载渠道。
- 去哪下:
Unpaywall以及各种机构存储库(如学术论文预印本库 arXiv)。- 原理: 当你导入条目或点击"查找全文本"时,Zotero 会拿着 DOI 去这些合法的开源数据库查询。如果这篇论文是开源的,它会直接下载。
- 特点: 速度较快,完全合法。
如果你在寻找文献时发现"此处付费,彼处免费",Unpaywall 通常就是那个帮你找到"彼处"的关键工具。
Unpaywall 是由非营利组织 OurResearch 维护的一个庞大数据库。它索引了全球超过 50,000 个开放存取(OA)存储库、大学机构库和出版商官网的合法免费版本。
这让人很快就想到了:sci-hub,但它们完全不同。
- Sci-Hub : 通过爬取和共享账号绕过版权限制(非法/灰色)。
- 它已经被制裁了(在绝大多数国家是非法的行为),最近几年的文献大概率是没有的。
- Unpaywall : 只索引合法公开的内容。它抓取的是:
- 作者按法律规定上传到学校网站的副本。
- 预印本平台(如 biorXiv, medRxiv)的内容。
- 出版商自己搞活动"限时免费"或"永久开源"的内容。
🟢 (2)使用机构权限下载--浏览器
你的学校、机构购买了相关数据库,你在内网就可以下载相应的文献了。
- 去哪下: 出版商官网(如 Nature, Science, Elsevier, Wiley 等)。
- 原理: 当你在浏览器里使用 Zotero Connector 插件时,Zotero 会利用你当前的 IP 权限。如果你有权限看这篇论文,它就模仿你的操作,点击网页上的"Download PDF"按钮把文件"抓"回来。
- 特点: 准确率最高,能下到解析最完美的官方 PDF。
🟢 (3)图书馆数字资源
和第二种方式是类似的。
- 去哪下: 你所属大学图书馆的数字资源库。 原理: 你可以在 Zotero 设置里填入学校图书馆的
OpenURL- 地址。当你找不动文献时,点击它,它会跳转到学校图书馆搜索该条目。
2和3是有限制的:
- 只能在浏览器,使用zotero的浏览器插件下载,因为这个设计身份认证;
- 不能大量下载:一方面是你所在机构不允许你大批量下载,另一方面是出版方网站不允许你大批量下载。
OpenURL不是所有高校图书馆都支持的,很多都没有的。
🟢 (4)sci-hub
Zotero 默认不从 Sci-Hub 下载。 原因很简单:版权和法律风险。
但是,Zotero 的用户手册里其实通过"PDF 查找引擎(Resolvers)"功能给用户留了自定义空间。你可以通过以下方式让 Zotero 去 Sci-Hub 下载:
- 手动配置方法: 在 Zotero 的 设置 -> 高级 -> 编辑器设置 (Config Editor) 中,找到一个叫
extensions.zotero.findPDFs.resolvers的项。- 实现效果: 只要把一段针对 Sci-Hub的代码(JSON 格式)粘贴进去,Zotero 的"查找可用 PDF"功能就会增加一个 Sci-Hub 的搜索路径。
你也不用手动写了,zotero是开源软件,早有人写好了插件,拿来用即可。
3.2 操作
3.21 导入文献
- 软件里面可以新建一个分类:点击左上角,我的文库,左上方的文件夹加号,就可以新建一个文件夹了。
- 然后把前面下载的
.ris文件拖到这个文件夹里面。 - 双击拖进去的ris文件,就会弹出是否导入,如果勾选:导入到新收藏,就会自动根据ris文件名创建一个文件夹,然后把文献导入进去。
如图所示:
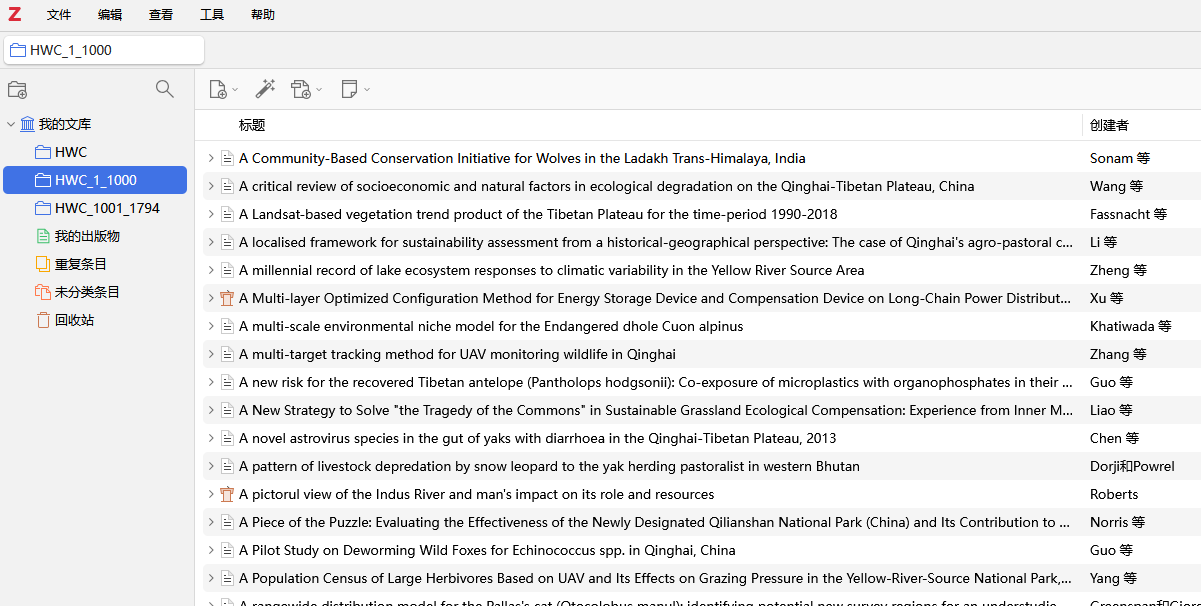
不必完全按照我的来,基本导入方法就是这样。
3.22 获取全文
在:编辑--设置--高级,里面可以自己设置保存路径。
数据保存路径的:storage目录,是文献存储目录,你不同分类下的文献都会保存到这里,保存目录这里不会再次分类,每个文献对应一个子目录,里面可能又2个文件,一个是缓存文件,不用管,另一个就是下载到的PDF(如果成功下载的话)。
最后如果要批量分析PDF内容,写个python脚本把PDF提取(复制)到一个目录就行了。
在某个条目上右键:查找全文,就会下载相应的PDF到本地,如果获取成功,右侧会出现一个PDF的图标。
如要批量获取全文,可以:
- ctrl A:全选所有文献,然后右键,查找全文
可能只能下载一般多一些的文献,现在就用sci-hub吧。
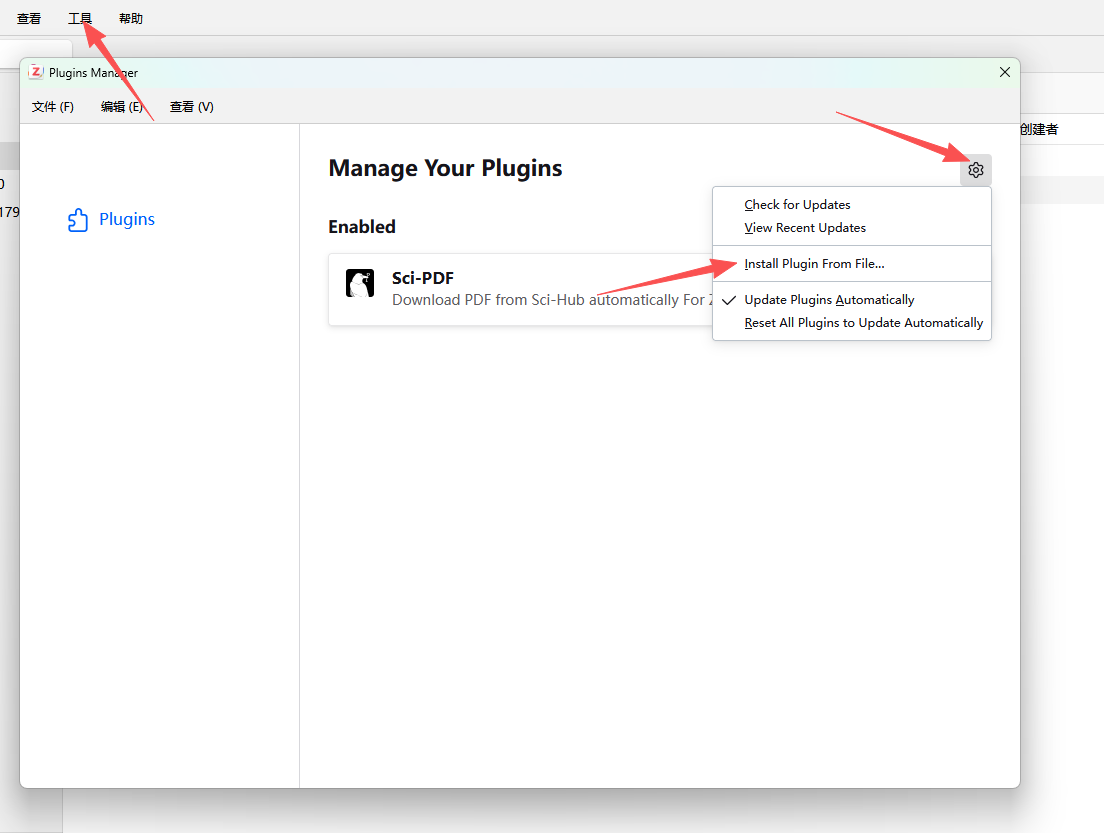
插件:https://github.com/syt2/zotero-scipdf?tab=readme-ov-file
点击上述链接页面的中右侧的:Releases,进去后下载.xpi后缀的那个即可。
在Zotero软件里面:工具--插件--设置--从文件安装
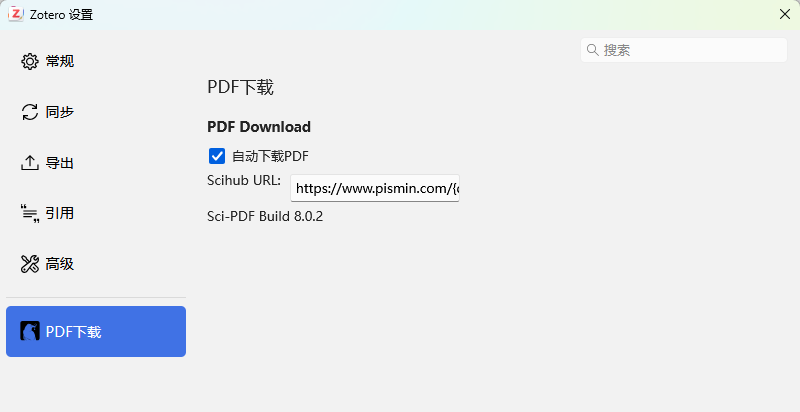
这个插件已经内置了sci-hub的一些站点,基本是可用的,你也可以自己添加:编辑--设置
你可以把它的url全选复制出来,然后添加新的之后再粘贴回去。
- 格式:
https://sci-hub.st/{doi},你只需要改前面的,{doi}这个是自动根据每篇文献来填充的,没有doi的肯定下载不了。 - 多个站点url之间是英文的封号;
- 上面这两点你复制出来看也能观察出规律。
现在,还是一样的操作,全选--右键--查找全文,就会下载:有doi,且之前没有下载的文献了。
这个插件做了什么?
其实就是帮你修改了一下软件的:extensions.zotero.findPDFs.resolvers配置项,这个默认是空值。
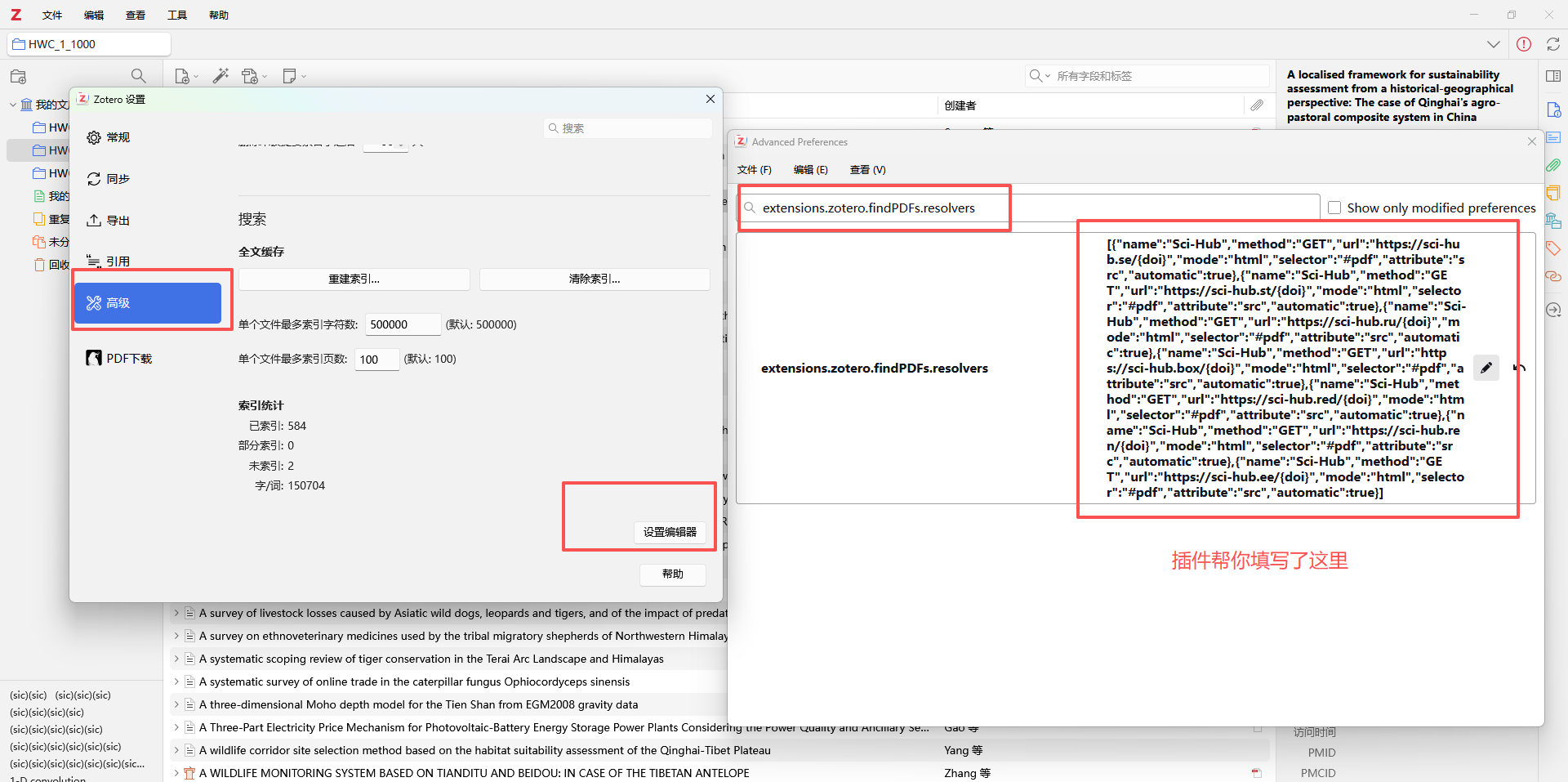
插件里面默认的这些sci-hub站点随时可能失效,这种东西肯定是被制裁的嘛。你可以一个一个复制网址看看能不能打开,或者直接填写当前能打开的url。
你也可以在软件的:工具--开发者--error console里面看到报错,如:
- 可以看到里面的2个站点是失效的,复制域名到浏览器中也是打不开的
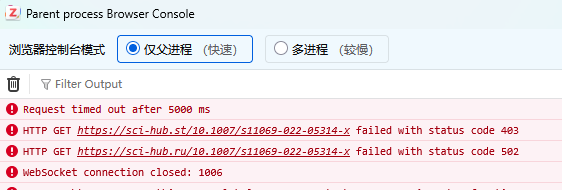
失效的可以删了,添加目前能用的就行,可以自己搜一搜哪些能用,这个是动态的。
3.4 处理没有获取到的文献
我发现有一些文献,有DOI,而且可用在sci-hub上手动搜索到,但是前面的方法却下载不下来,故写一个python脚本来下载。
现在就处理没有下载到的文献嘛,下载前,先分个类,在zotero里面单独建一个文件夹,把没有下载到的文献放在里面,便于管理。
点击这个附件图标(回形针这个),文献就会按照有无附件排列(其他列也有这个功能,如按照标题排列),然后选择没有下载附件的文献,拉到新建的文件夹里面即可。
多选文献的方法(不是全选):点击要选择的第一个文献,滚到要选择的最后一个文献那里,按住shift,点击最后一个文献,就可以实现多选。
然后把没下载的文献导出一下,主要是获取DOI,文件夹上右键--导出分类,选择RIS。
接着将导出的ris文件的路径,要保存PDF的路径,填入下面的代码对应位置即可下载sci-hub可以下载,但在zotero里面没有成功下载的文献。
代码让AI写就行了,自己审查一下。
c
# -*- coding = utf-8 -*-
# @TIME : 2026/01/29 16:12
# @Author : Grace
# @File : wos_download_pro.py
# @Software : PyCharm Professional 2025.1.2
# Introduction:
import os
import time
import requests
import pandas as pd
import rispy
from bs4 import BeautifulSoup
import concurrent.futures
from concurrent.futures import ThreadPoolExecutor, as_completed
import warnings
import re
# 忽略SSL警告
warnings.filterwarnings('ignore')
os.environ['CURL_CA_BUNDLE'] = ''
# ================= 配置区域 =================
RIS_PATH = r"xxx.ris"
DOWNLOAD_DIR = r"xxx\未下载"
LOG_FILE = os.path.join(DOWNLOAD_DIR, "download_status_log.csv")
# 7个镜像站点模板
SCIHUB_MIRRORS_TEMPLATE = [
"https://www.pismin.com/{doi}",
# "https://sci-hub.se/{doi}",
"https://sci-hub.st/{doi}",
"https://sci-hub.ru/{doi}",
"https://sci-hub.box/{doi}",
"https://sci-hub.red/{doi}",
"https://sci-hub.ren/{doi}",
"https://sci-hub.ee/{doi}"
]
# 伪装头
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/142.0.0.0 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8',
'Connection': 'keep-alive',
'Upgrade-Insecure-Requests': '1',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'none',
'Sec-Fetch-User': '?1',
}
# ================= 核心功能函数 =================
def sanitize_filename(filename):
"""文件名清洗,移除Windows非法字符"""
if not isinstance(filename, str): return "Unknown_Filename"
filename = re.sub(r'[\\/*?:"<>|]', '_', filename) # 替换非法字符
filename = re.sub(r'\s+', ' ', filename).strip() # 去除多余空格
return filename[:200] # 截断防止路径过长
def parse_ris_robust(file_path):
"""暴力解析WoS导出的RIS,解决字段识别问题"""
print(f"[解析] 正在读取 RIS 文件: {file_path}")
# 尝试使用 rispy 读取
with open(file_path, 'r', encoding='utf-8-sig', errors='ignore') as f:
entries = rispy.load(f)
parsed_data = []
for entry in entries:
# 1. 获取DOI (WoS可能在 DO, DI, 或 N1 中)
doi = entry.get('doi') or entry.get('DO') or entry.get('number')
if not doi:
# 有些RIS把DOI放在 notes 里,这里做个简单检查
notes = entry.get('notes', [])
if isinstance(notes, list):
for n in notes:
if '10.' in n and '/' in n:
doi = n
break
# 2. 获取标题 (重点解决 Unknown Title)
# 顺序尝试: title, primary_title, secondary_title, TI, T1, CT
title = entry.get('title') or entry.get('primary_title') or entry.get('TI') or entry.get('T1') or entry.get('T2')
if not title:
title = "Unknown_Title"
# 3. 获取年份
year = entry.get('year') or entry.get('publication_year') or entry.get('PY') or entry.get('Y1')
if not year:
# 尝试从日期提取
date = entry.get('date') or entry.get('DA')
if date:
year = date[:4]
else:
year = "NoYear"
# 清洗数据
doi = str(doi).strip() if doi else ""
title = str(title).strip()
year = str(year).strip()
# 生成目标文件名
clean_title = sanitize_filename(title)
filename = f"[{year}] {clean_title}.pdf"
status = 'Pending' if doi else 'No_DOI'
if not doi:
print(f" [警告] 发现无DOI文献: {title[:30]}...")
parsed_data.append({
'DOI': doi,
'Title': title,
'Filename': filename,
'Status': status,
'Message': ''
})
return pd.DataFrame(parsed_data)
def init_task_manager():
"""初始化任务列表,如果旧文件有大量Unknown则强制重建"""
if not os.path.exists(DOWNLOAD_DIR):
os.makedirs(DOWNLOAD_DIR)
rebuild = False
if os.path.exists(LOG_FILE):
df = pd.read_csv(LOG_FILE)
# 检查是否是之前的垃圾解析(比如只要有超过5个Unknown Title就认为以前解析废了)
unknown_count = df['Title'].str.contains('Unknown Title', case=False, na=False).sum()
if unknown_count > 5:
print(f"[检测] 旧记录文件包含 {unknown_count} 个未知标题,判定为解析失败。正在强制重新解析RIS...")
rebuild = True
else:
print(f"[读取] 加载现有进度,共 {len(df)} 条记录。")
# 恢复中断的任务
df.loc[df['Status'] == 'Downloading', 'Status'] = 'Pending'
else:
rebuild = True
if rebuild:
df = parse_ris_robust(RIS_PATH)
df.to_csv(LOG_FILE, index=False)
print(f"[构建] 新的统计文件已创建,共 {len(df)} 条。")
return df
def get_pdf_direct_link(session, url):
"""在镜像页面中提取PDF真实下载链接"""
try:
# 短超时,快速探测
resp = session.get(url, headers=HEADERS, timeout=10, verify=False, allow_redirects=True)
if resp.status_code != 200:
return None
soup = BeautifulSoup(resp.content, 'html.parser')
# 策略1: embed/iframe src
target = soup.find('embed', attrs={'type': 'application/pdf'}) or \
soup.find('iframe', attrs={'src': re.compile(r'\.pdf')}) or \
soup.find('div', id='pdf')
if target and target.get('src'):
raw_url = target.get('src')
# 补全链接
if raw_url.startswith('//'): return 'https:' + raw_url
if raw_url.startswith('/'): return '/'.join(url.split('/')[:3]) + raw_url
return raw_url
# 策略2: onclick save button
# SciHub有时只有一个按钮
btn = soup.find('button', onclick=True)
if btn and 'location.href' in btn['onclick']:
# 提取 location.href='...';
match = re.search(r"href='(.*?)'", btn['onclick'])
if match:
raw_url = match.group(1)
if raw_url.startswith('//'): return 'https:' + raw_url
return raw_url
except Exception:
pass
return None
def attempt_download_single_mirror(url_template, doi, save_path):
"""单个镜像的尝试逻辑,用于线程里跑"""
mirror_url = url_template.replace("{doi}", doi)
session = requests.Session()
session.mount('https://', requests.adapters.HTTPAdapter(max_retries=1))
try:
# 1. 获取PDF链接
pdf_url = get_pdf_direct_link(session, mirror_url)
if not pdf_url:
return False, "Page parsed but no PDF found"
# 2. 下载文件
# 设置流式下载,超时要设置短一点以便快速切换
r = session.get(pdf_url, headers=HEADERS, stream=True, timeout=20, verify=False)
# 验证是否是真PDF (检查Content-Type或文件头)
ct = r.headers.get('Content-Type', '').lower()
if 'html' in ct or len(r.content) < 1000: # 可能是报错页面
return False, "Not a PDF file"
if r.status_code == 200:
with open(save_path, 'wb') as f:
for chunk in r.iter_content(chunk_size=8192):
f.write(chunk)
return True, mirror_url # 成功返回
except Exception as e:
return False, str(e)
return False, "Unknown Error"
def parallel_download_handler(index, row, df):
"""针对单个DOI的并行下载控制器"""
doi = row['DOI']
filename = row['Filename']
save_path = os.path.join(DOWNLOAD_DIR, filename)
# 状态更新
print(f"\n--> [{index + 1}/{len(df)}] 开始并行下载: {doi}")
print(f" 目标文件: {filename}")
df.at[index, 'Status'] = 'Downloading'
success = False
winning_mirror = ""
# === 并行核心 ===
# 同时启动8个线程访问不同镜像
with ThreadPoolExecutor(max_workers=8) as executor:
# 提交任务字典 {future: mirror_url}
future_to_url = {
executor.submit(attempt_download_single_mirror, url, doi, save_path): url
for url in SCIHUB_MIRRORS_TEMPLATE
}
# 谁先完成算谁的
for future in as_completed(future_to_url):
url = future_to_url[future]
try:
is_success, msg = future.result()
if is_success:
success = True
winning_mirror = msg
print(f" [√] 成功! 来源镜像: {winning_mirror.split('/')[2]}")
# 关键:一旦有一个成功,取消其它未开始的任务,不再等待其它正在运行的任务
# (由于Python线程很难强制Kill,我们直接break出去,主程序往下走,
# 线程池会稍微等待后台线程结束,但不会阻塞主逻辑太久)
executor.shutdown(wait=False, cancel_futures=True)
break
except Exception:
continue
# === 结果记录 ===
if success:
df.at[index, 'Status'] = 'Downloaded'
df.at[index, 'Message'] = f"From {winning_mirror}"
else:
df.at[index, 'Status'] = 'Failed'
df.at[index, 'Message'] = "All mirrors failed or timed out"
print(f" [X] 所有镜像均失败: {doi}")
# 每次下载完一个立即保存进度
df.to_csv(LOG_FILE, index=False)
def main():
print("=== 2026 WoS 极速下载器 (并行版) ===")
# 1. 初始化 & 修正RIS解析
df = init_task_manager()
# 2. 筛选任务
# 选择 Pending 和 之前意外中断的
tasks = df[df['Status'] == 'Pending']
total = len(tasks)
print(f"\n=== 待处理队列: {total} 个文献 ===")
if total == 0:
print("没有由于下载的任务。检查是否需要重置 'Failed' 状态。")
return
# 3. 遍历下载 (主循环)
for index, row in tasks.iterrows():
# 检查文件是否已经物理存在(防止重复下载)
file_path = os.path.join(DOWNLOAD_DIR, row['Filename'])
if os.path.exists(file_path) and os.path.getsize(file_path) > 2000:
print(f"[{index + 1}] 文件已存在,跳过: {row['Filename']}")
df.at[index, 'Status'] = 'Downloaded'
df.at[index, 'Message'] = 'File exists'
df.to_csv(LOG_FILE, index=False)
continue
# 执行并行下载
parallel_download_handler(index, row, df)
# 虽然是并行,但在不同文献之间稍微停一下,防止请求频率过高导致本机IP被ban
# 也就是:每个文献内部并发,文献与文献之间串行+延迟
time.sleep(1)
if __name__ == "__main__":
main()完事后发现还有文献没有下载,这些就是:
- 没有DOI的(应该较少);
- 在哪都要付费的。
这个就要自己在浏览器里面下载了。
3.5 附:整理zotero下载的文献
作用:将zotero下载的文献整理到一个目录下
你不一定需要做这个,我是要逐篇分析文献(LLM),所以整理到一起。
c
# -*- coding = utf-8 -*-
# @TIME : 2026/01/29 13:20
# @Author : Grace
# @File : wos_move.py
# @Software : PyCharm Professional 2025.1.2
# Introduction:将zotero下载的文献整理到一个目录下
import os
import shutil
from pathlib import Path
def collect_zotero_pdfs(src_dir, dest_dir):
# 将路径转换为 pathlib 对象,自动处理不同系统的斜杠问题
src_path = Path(src_dir)
dest_path = Path(dest_dir)
# 如果输出目录不存在,则创建
if not dest_path.exists():
dest_path.mkdir(parents=True, exist_ok=True)
print(f"已创建输出目录: {dest_path}")
print("正在扫描并复制文件,请稍候...")
count = 0
# rglob('*.pdf') 会递归搜索所有子目录下的 pdf 文件
for pdf_file in src_path.rglob('*.pdf'):
try:
# 构建目标文件的完整路径
target_file = dest_path / pdf_file.name
# 冲突处理:如果目标目录已存在同名文件,自动添加编号防止覆盖
if target_file.exists():
stem = pdf_file.stem
suffix = pdf_file.suffix
counter = 1
while target_file.exists():
target_file = dest_path / f"{stem}_{counter}{suffix}"
counter += 1
# 执行复制操作(shutil.copy2 会保留原始元数据如修改时间)
shutil.copy2(pdf_file, target_file)
count += 1
if count % 10 == 0:
print(f"已处理 {count} 个文件...")
except Exception as e:
print(f"处理文件 {pdf_file.name} 时出错: {e}")
print("-" * 30)
print(f"任务完成!共成功复制 {count} 个PDF文件到:")
print(dest_path)
if __name__ == "__main__":
# 输入和输出路径
input_directory = r"你的zotero的数据保存路径\storage"
output_directory = r"输出目录"
collect_zotero_pdfs(input_directory, output_directory)本文主要内容已完。
四、zotero 的AI 插件
以AI对话插件为例,其它插件(如翻译),可以自己下载。
中文社区的:https://zotero-chinese.com/plugins/
下载页面:https://github.com/MuiseDestiny/zotero-gpt/releases
安装不重复将了。
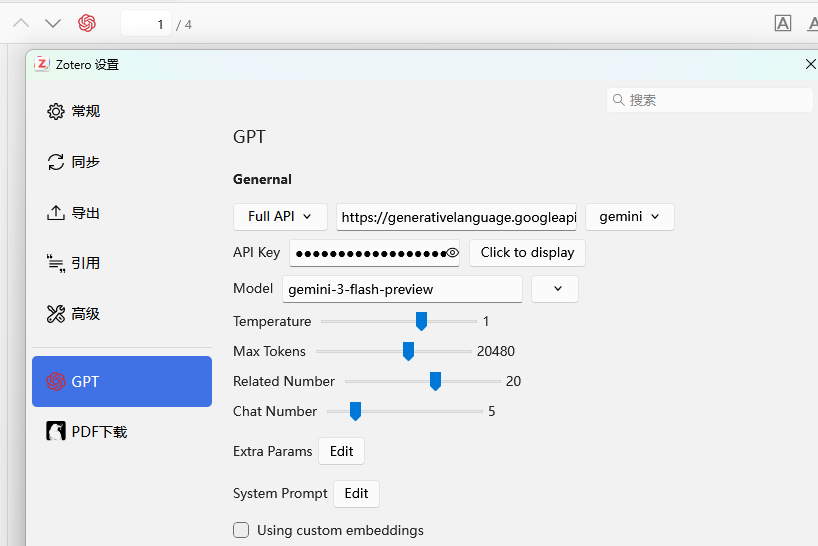
设置一下模型和api key:我用的是Gemini,
- 选择Full API,这一行第三个下拉款选择你使用的AI,有很多的,api地址会自动填入第二个框;
- 填入你的api key;
- 手动填写api id:
gemini-3-flash-preview,他内设的只有2.5,所以要自己填一下(pro是:gemini-3-pro-preview) - token 限制,等其它参数自己设置一下
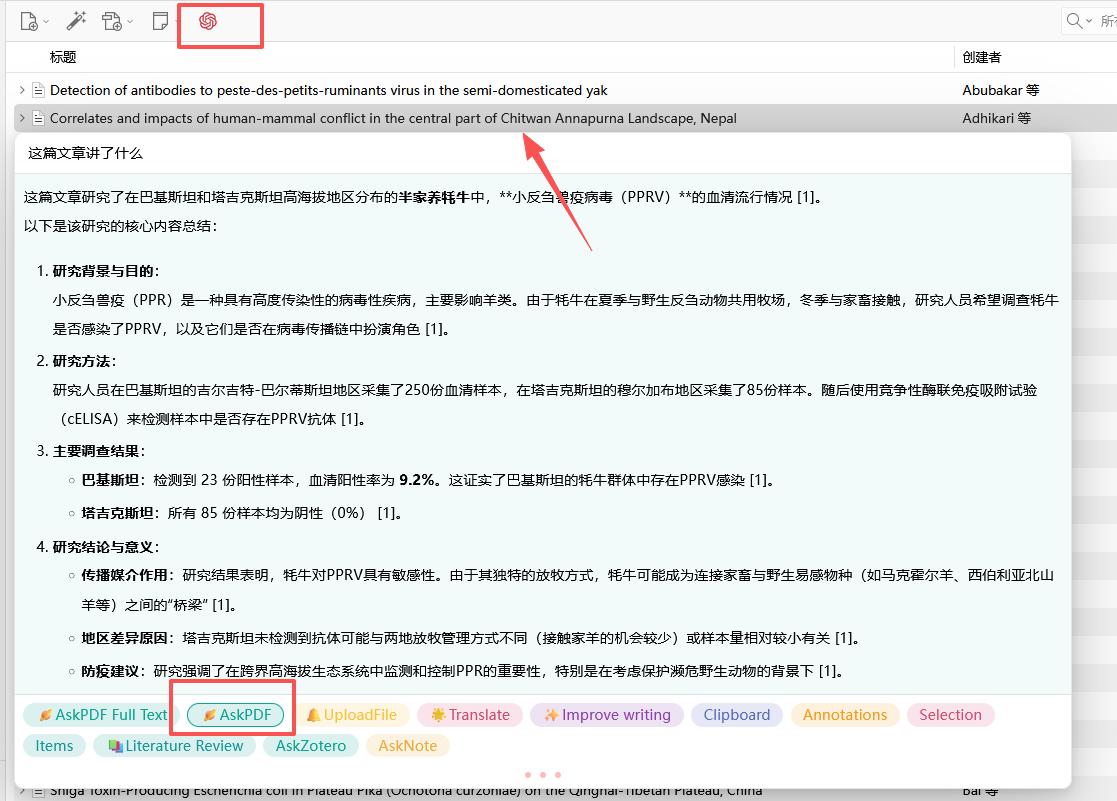
选择一篇文献,点击GPT 图标(关闭的话再点一次),选择一个功能,提问即可:
也可以用deepseek,这个门槛最低,自己搜:deepseek开放平台,充值买api key即可。