Algorithms + Data Structures = Programs
------尼克劳斯·维尔特(Niklaus Wirth)
目录
1.数据结构概念
1.概念:
程序 == 数据结构 +算法
数据结构 :程序操作数据对象的结构,是数据元素的集合,这些元素之间存在某种关系。
算法:是程席操作数据对象的方法,是解决特定问题的一系列步骤
意义:程序的设计和实现都围绕着这两个核心组件展开。选择合适的数据结构可以优化算法的执行,提高程序的整体效率。
2.程序的效率的衡量指标
时间复杂度: 数据量增长与程序运行时间增长呈现的比例函数关系称为时间复杂度函数,简称为时间复杂度
O(c)
O(logn)
O(n)
O(nlogn)
O(n^2)
O(n^3)
...
0(2^n)
空间复杂度:数据量增长与程序空间增长呈现的比例函数关系称为空间复杂度
3.数据结构
1.逻辑结构
线性结构:一对一关系
树形结构:一对多关系
图形结构:多对多关系
2.存储结构
顺序存储:
优点------访问元素方便
缺点------插入数据不便,删除数据效率也低,无法利用小空间
链式存储
优点------①插入、删除效率高
②可以利用小空间
缺点------访问元素不方便
增加额外空间的开销
索引存储
散列存储
3.具体常用数据结构类型分类
顺序表(Contiguous List)
链式表【重点,应用非常多】
顺序栈
链式栈
顺序队列(就是排队)
链式队列
二叉树(完全二叉树、满二叉树)
哈希表
常见排序和查找算法
二、顺序表
概念:本质上是数组(动态数组),只不过存于堆区(通过申请堆区空间存储数据,通过首地址完成对所有空间的访问)
申请
释放
调用
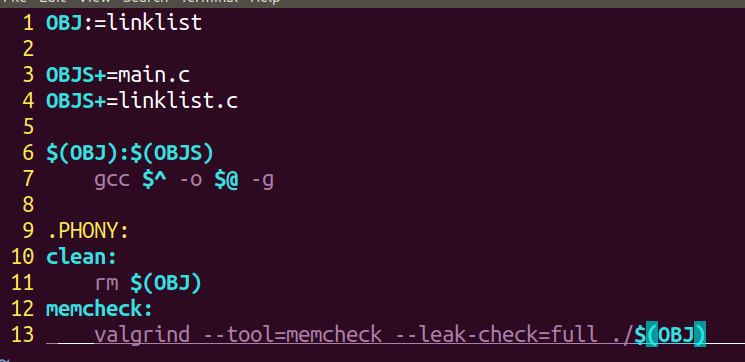
makefile
三、链式表(linklist)【重点,应用非常多】
1,简介
概念 :链表是一种牺牲随机存取性能以换取动态性和插入/删除效率的数据结构,适用于频繁增删、数据规模不确定的场景,但需注意其空间开销和顺序访问的限制。
主要缺点
失去随机存取能力:无法像数组一样通过索引直接访问元素。
空间开销较大:每个结点需额外存储指针,占用更多内存。
访问效率较低:查找特定结点需遍历链表。
2.3种分类
单向链表(分有头链表和无头链表)
注意:无头链表插入数据较麻烦(会使用二级指针),所以学习有头链表
双向链表
双向循环链表【应用最多,内核里使用。如freertos操作系统】
3.单向链表(链表最后一个节点的指针数据pnext永远为空(∵链表是前一个节点指向下一个节点,最后一个节点的下一个节点没有,所以它存的下一个节点的地址为空))
函数①------空结点创建:
分析
申请
调用
函数②------节点后插函数(作用:在某个节点*pHead的后边插入一个节点,并存储数据TmpData)
分析
四步:①申请新节点空间
②存放数据到新节点的Data
③将pHead节点的pNext值赋值给新节点pNext
④将新节点的pNext赋给pHead的节点
代码
函数③------链表元素的访问函数(两种方法)
分析:以下两种方法都能实现
p为当前节点首地址,左边的思路,可以遍历所有元素,但是无法得到最后一个元素(除非再遍历一遍),比较麻烦; 右边的思路,指针一指向最后一个元素就停下来了,想要对最后一个元素读取需在while外边再操作一行
代码
调用
结果
函数④------链表元素的删除
分析:
代码
调用
结果
函数⑤------链表元素的替换
分析:遍历所有节点,当节点数据为需要修改的数据时,将其改为新数据
代码
调用
结果
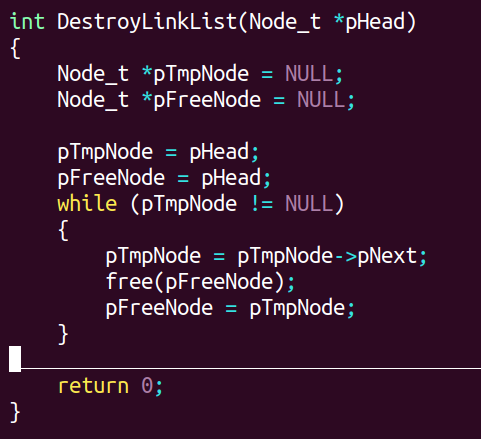
函数⑥------链表的释放
分析:定义两个指针指向链表头
代码
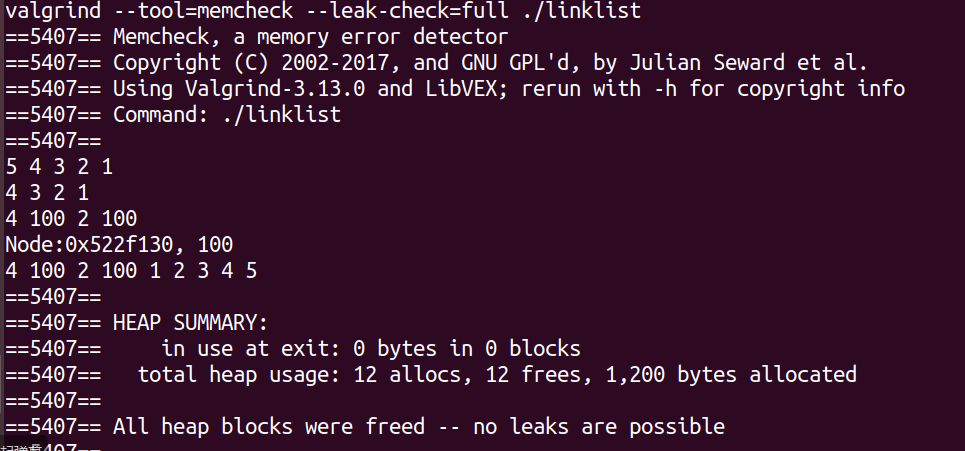
可通过valgrind检查