从Token压缩到因果阅读:DeepSeek-OCR系列的视觉编码演进
论文信息
论文 f842cb8

标题: DeepSeek-OCR: Contexts Optical Compression
作者: Haoran Wei, Yaofeng Sun, Yukun Li
-
会议/期刊: arXiv
论文 f17b245

标题: DeepSeek-OCR 2: Visual Causal Flow
作者: Haoran Wei, Yaofeng Sun, Yukun Li
-
会议/期刊: arXiv
引言:视觉Token作为LLM上下文压缩的新范式
大语言模型(LLM)在处理长上下文时,Self-Attention 的二次复杂度 始终是难以逾越的计算高墙。当序列长度突破数万Token,显存与算力消耗呈爆炸式增长------这催生了对高效信息表征的迫切需求。DeepSeek-OCR 与 DeepSeek-OCR 2 正是在这一背景下,分别从效率压缩 与逻辑建模两个维度,对传统视觉语言模型(VLM)的视觉编码范式发起挑战。
前者提出将图像作为文本的"外部压缩缓存 ":一张1024×1024文档图像经 DeepEncoder 压缩后仅需256个视觉Token,即可还原近2500个文本Token,压缩比超10倍,OCR精度仍高达97%。这不仅是工程优化,更暗示了一种生物启发式的记忆机制------通过多级分辨率模拟人类"近期清晰、远期模糊"的遗忘曲线。
而后者则直指传统光栅扫描的逻辑缺陷。DeepSeek-OCR 2 引入可学习的因果流查询 ,让视觉Token按语义重要性重排序,而非死守空间坐标。其阅读顺序Edit Distance从0.085降至0.057,用更少Token讲出更连贯的故事。
两篇工作目标迥异,却共享同一技术脉络:视觉编码正从"量"的压缩迈向"质"的重构 。如下图所示,这种从光学表征中自然涌现出的记忆与逻辑双重机制,或许正是突破LLM上下文瓶颈的关键钥匙。
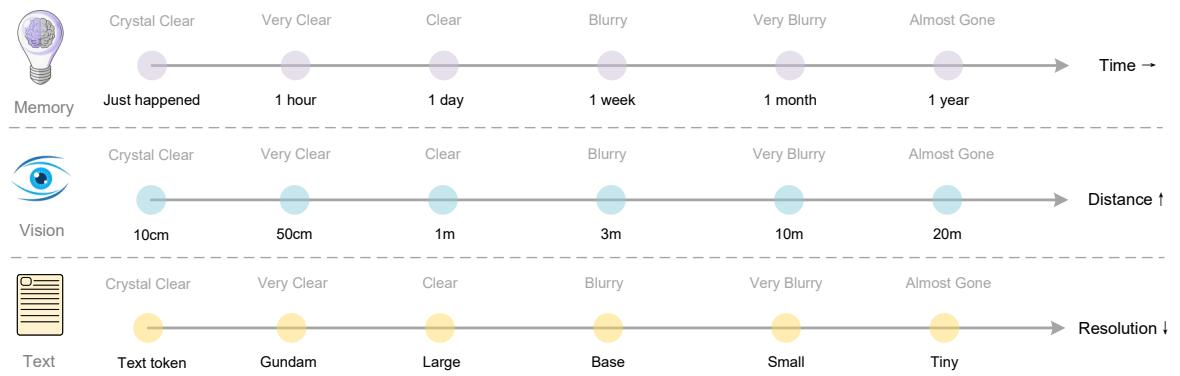
人类记忆、视觉感知与文本表征随时间/距离/分辨率衰减的类比示意图,三者均呈现"近期清晰、远期模糊"的渐进式退化模式
2者异同点:效率优先 vs 因果建模的双路径探索
DeepSeek-OCR 与 DeepSeek-OCR 2 虽同出一门,却走上截然不同的技术岔路。二者均聚焦端到端OCR任务 ,坚持高分辨率输入+低Token输出策略,核心目标一致:为LLM/VLM提供高效、可扩展的上下文压缩方案。
初代 DeepSeek-OCR 是效率优先 的极致践行者。它采用 SAM + CLIP 串行架构 ,中间嵌入一个16倍卷积压缩模块 ,将4096个视觉token骤压至256个。这种设计在Fox基准上实现了97% OCR精度仅需10倍压缩比的惊人效果,直击LLM长上下文的计算瓶颈------用图像作"外部压缩缓存",以空间换序列长度。
而 DeepSeek-OCR 2 则转向因果建模 的新范式。它彻底抛弃CLIP ,改用 LLM风格视觉编码器 (基于Qwen2-0.5B架构),并引入一组可学习因果流查询 (causal flow queries)。这些查询通过混合注意力掩码------视觉token间全连接,查询token间因果掩码------动态重排语义顺序,模拟人类"先标题、再正文"的阅读逻辑。结果?OmniDocBench上的阅读顺序Edit Distance从0.085降至0.057,文本重复率显著下降。
一条路压Token数量,一条路塑Token秩序。前者问"能压缩多少?",后者问"该按什么顺序读?"。两者共同揭示:视觉Token不仅是信息载体,更是结构与因果的容器。
迭代和演进关系:从空间压缩到语义重排序的技术跃迁
DeepSeek-OCR 首次验证了视觉 Token 的压缩极限------一张 1024×1024 文档图像可被压缩至仅 256 个 Token,仍保持 97% OCR 精度。但其依赖的光栅扫描顺序,将二维语义强行拉成一维序列,导致复杂排版中阅读逻辑错乱。这暴露了纯工程优化的天花板:Token 越少越好,却未必"读得对"。
DeepSeek-OCR 2 正是在此瓶颈上实现认知跃迁。它不再满足于压缩数量,而是在编码阶段注入阅读因果性 。通过引入可学习的"因果流查询"与混合注意力掩码,模型能动态重排视觉 Token 的语义顺序,模拟人类"先标题、再正文、后图表"的注视路径。其掩码结构可形式化为:
M = 1 m × m 0 m × n 1 n × m LowerTri ( n ) , where n = m M = \begin{bmatrix} \mathbf{1}{m \times m} & \mathbf{0}{m \times n} \\ \mathbf{1}_{n \times m} & \text{LowerTri}(n) \end{bmatrix}, \quad \text{where } n = m M=1m×m1n×m0m×nLowerTri(n),where n=m
前半段保留视觉全局感知,后半段强制因果依赖,首次让视觉编码具备"先看哪里、后看哪里"的推理能力。
架构层面,这一跃迁体现为从"SAM+CLIP"向"SAM+LLM as Vision Encoder"的范式迁移。抛弃 CLIP 的静态特征提取,转而采用 LLM 风格的因果主干,标志着视觉编码正向统一语言建模范式靠拢 。评估维度也随之升级:性能不再仅看 OCR 精度,更引入阅读顺序 Edit Distance------DeepSeek-OCR 2 将该指标从 0.085 降至 0.057,证明其真正理解了文档的内在逻辑流。
如下图所示,新架构通过因果流查询实现语义驱动的 token 重排序,彻底摆脱光栅扫描的束缚:
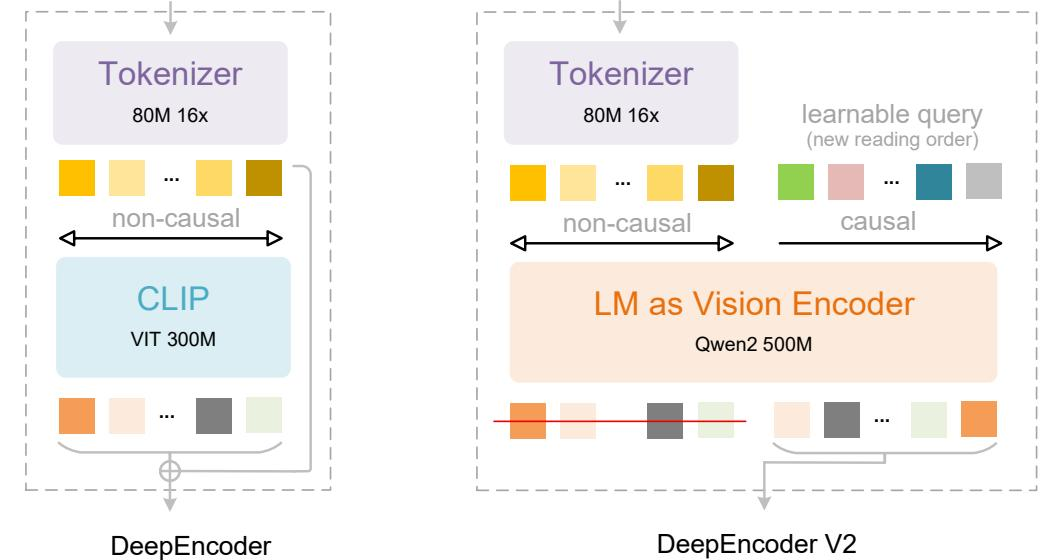
DeepEncoder 与 DeepEncoder V2 架构对比:后者以 LM as Vision Encoder 替代 CLIP,并引入可学习因果查询实现语义驱动的 token 重排序。
多模态编码正从"省 Token"走向"懂逻辑",这场从空间压缩到语义重排序的跃迁,或许正是通向类人视觉理解的关键一步。
总结:迈向生物启发的多模态上下文管理
DeepSeek-OCR 与 DeepSeek-OCR 2 共同勾勒出一条突破 LLM 上下文瓶颈的新路径。前者证明视觉可作为高效外部记忆 ,通过 DeepEncoder 实现近 10倍 Token 压缩 ,同时保持 97% 的 OCR 精度 ,将长文本"封存"为图像,绕过 Self-Attention 的平方墙。后者则更进一步,赋予视觉理解类人阅读逻辑 ------借助因果流查询与混合注意力掩码,动态重排视觉 token 顺序,使阅读顺序错误率显著下降,重复率从 6.25% 降至 4.17%。
二者互补,指向一种新型上下文管理范式 :近期高保真、远期低开销的多级压缩记忆系统 。这不仅是工程优化,更是对人类记忆衰减机制的模拟------清晰保留当下,模糊但可用地存储过往。未来方向已然清晰:跨模态统一编码 、多跳重排序机制 ,以及与 LLM 原生集成的端到端训练,或将催生真正具备生物启发式记忆能力的下一代多模态智能体。