DeepSeek-OCR-v2 深度解析:视觉因果流重构OCR技术,复杂版面处理迈入新纪元
OCR(光学字符识别)作为连接物理文档与数字世界的核心技术,已广泛应用于金融票据处理、医疗病历数字化、政务档案管理等多个领域。但传统OCR模型在面对多栏论文、嵌套表格、公式密集的复杂文档时,常陷入"机械扫描、语义割裂"的困境,难以还原人类阅读的逻辑顺序。2026年1月,深度求索发布的DeepSeek-OCR-v2,以"视觉因果流"为核心创新,彻底重构了OCR的编码逻辑,在复杂版面理解上实现质的突破,同时兼顾高效推理能力。本文将从模型结构、核心改进、传统OCR对比、部署实践四大维度,全面拆解这款新一代OCR模型。
一、OCR技术痛点回顾:为何传统模型难以应对复杂版面?
在DeepSeek-OCR-v2诞生前,传统OCR(包括早期深度学习OCR)的核心瓶颈集中在"版面理解与语义顺序对齐"上,具体表现为三大痛点:
-
扫描逻辑僵化:多数模型采用"光栅扫描"模式,固定从左到右、从上到下处理图像,强行将2D文档压为1D序列,易导致跨栏串读、表格行列混淆(如把双栏文档的右栏内容接在左栏末尾)。
-
语义与空间割裂:视觉编码与文本解码脱节,编码器仅负责提取图像特征,语义顺序纠正完全依赖解码器,大量算力耗费在顺序修复上,效率低下。
-
细节与效率失衡:要么为保留细节减少视觉Token压缩,导致显存占用过高、推理缓慢;要么过度压缩Token,丢失小字、密集表格等关键信息。
这些痛点,使得传统OCR在学术论文、古籍文献、复杂报表等场景中,难以满足高精度、高效率的处理需求。而DeepSeek-OCR-v2的核心创新------视觉因果流,正是为解决这些问题而生。
二、DeepSeek-OCR-v2 模型结构深度拆解
DeepSeek-OCR-v2延续了"编码器-解码器"的基础架构,但对核心模块进行了颠覆性重构,重点强化了编码器的语义推理能力,整体架构兼顾性能与效率,具体可分为三大模块:视觉分词模块、DeepEncoder V2编码器、MoE解码器。
2.1 视觉分词模块:高效压缩,细节与效率双兼顾
视觉分词的核心目标是将原始图像转化为可处理的视觉Token,同时平衡压缩比与细节保留。DeepSeek-OCR-v2沿用前代的高效设计,采用"SAM-base(80M参数)+两层卷积"的组合,实现16倍视觉Token压缩------即1024×1024分辨率的图像,仅生成256个视觉Token,大幅降低后续计算量与显存占用。
与传统OCR的Patch嵌入相比,该模块的优势在于:既能保留图像的局部细节(如小字、公式符号),又能捕捉全局版面结构,且支持灵活替换为简单Patch嵌入,适配不同硬件资源场景。此外,模型引入多尺度适配策略,结合1024×1024全局视图与768×768局部裁剪(最多6个裁剪块),全局视图覆盖整图语义,局部视图聚焦细节区域,总Token数控制在256~1120之间,进一步平衡全局与局部处理能力。
2.2 核心创新:DeepEncoder V2 编码器(视觉因果流载体)
DeepEncoder V2是DeepSeek-OCR-v2的灵魂模块,彻底摒弃了传统OCR的CLIP ViT编码架构,改用轻量级LLM作为底座,引入因果推理能力,实现视觉Token的动态语义重排,其核心设计包含三大亮点。
2.2.1 架构重构:用轻量LLM替代CLIP ViT
模型弃用v1版本的CLIP ViT模块,选用Qwen2-0.5B(5亿参数)轻量级大语言模型作为视觉编码底座------该参数量与CLIP ViT相当,无额外算力负担,却能将语言模型的因果推理能力引入视觉编码,从底层支持"按语义顺序处理信息",打破了传统OCR"视觉编码仅负责特征提取"的局限。
2.2.2 双流注意力机制:全局感知与因果重排双管齐下
通过定制化注意力掩码,DeepEncoder V2构建了两条并行处理流,兼顾全局版面理解与语义顺序推理,是视觉因果流的核心实现:
-
视觉流(Visual Stream):对原始视觉Token采用双向注意力(类似ViT),所有Token可全局交互,确保模型完整感知文档的布局结构(如双栏、表格位置),避免因局部处理丢失全局信息。
-
因果流(Causal Stream):引入与视觉Token数量相等的可学习因果查询Token,拼接在视觉Token之后,采用单向因果注意力(类似LLM解码器)------每个查询Token仅能关注自身之前的Token,同时可访问所有原始视觉Token,逐步预测"下一个应关注的语义区域",在编码阶段就完成视觉Token的智能重排。
这种设计的核心价值的是:将"空间无序的视觉信息"转化为"语义有序的因果序列",无需解码器额外纠正顺序,大幅提升推理效率。
2.2.3 两级因果推理:弥合2D图像与1D语言建模的鸿沟
DeepEncoder V2构建了两级级联的1D因果推理结构,完美解决了2D图像与1D文本生成的适配问题:
-
第一级(编码器端):因果查询Token对视觉Token进行语义重排,输出有序的因果流序列;
-
第二级(解码器端):MoE解码器对重排后的序列进行自回归生成,专注于文本识别与结构化输出,无需兼顾顺序纠错。
2.3 MoE解码器:高效推理,兼顾精度与速度
DeepSeek-OCR-v2沿用前代的3B参数MoE(混合专家系统)解码器,仅保留500M活跃参数,在不损失精度的前提下,大幅降低计算成本。与传统OCR的全参数解码器相比,MoE解码器的优势在于:可根据输入内容动态调用"专家层",对复杂文本(公式、表格)调用更多专家提升精度,对简单文本简化计算提升速度,适配不同复杂度的OCR任务。
2.4 三阶段训练流程:强化因果推理能力
为让模型充分掌握视觉因果流的重排能力,DeepSeek-OCR-v2采用三阶段训练策略,逐步优化编码器与解码器的协同效率:
-
编码器预训练:训练视觉分词器与LLM风格编码器,掌握基础特征提取、Token压缩与初步重排能力,采用语言建模目标,耦合轻量解码器联合优化;
-
查询增强:冻结视觉分词器,联合优化LLM编码器与主解码器,重点强化因果查询Token的重排能力,统一多尺度视图训练;
-
解码器微调:冻结编码器参数,仅微调解码器,提升文本识别与结构化输出精度,实现更高数据吞吐量。
三、DeepSeek-OCR-v2 核心改进点梳理
相较于前代模型(DeepSeek-OCR-v1)及传统OCR,DeepSeek-OCR-v2的改进贯穿架构、能力、效率三大维度,具体可总结为四大核心突破:
3.1 编码逻辑革新:从"机械扫描"到"语义因果推理"
这是最根本的改进。传统OCR(包括v1)均依赖固定空间顺序处理视觉Token,而v2通过视觉因果流技术,让模型先理解版面语义,再动态重排Token,模拟人类"先读标题、再读正文,先完一栏、再读下一栏"的阅读逻辑,彻底解决复杂版面的顺序混乱问题。在OmniDocBench v1.5基准测试中,v2的阅读顺序编辑距离从0.085降至0.057,复杂版面处理精度大幅提升3。
3.2 架构融合:视觉与语言模型的深度协同
打破了"视觉编码与语言解码脱节"的壁垒,用LLM替代传统ViT作为编码底座,让视觉编码具备因果推理能力,实现"编码重排+解码生成"的协同优化,而非传统OCR的"各自为战"。这种融合架构,也为多模态统一编码奠定了基础------通过适配不同模态的可学习查询Token,可扩展支持图像、音频、文本的统一处理14。
3.3 效率与精度平衡:更优的Token管理策略
在保持16倍视觉Token压缩效率的同时,通过多尺度视图适配,兼顾全局结构与局部细节,解决了传统OCR"压缩与细节不可兼得"的痛点。同时,MoE解码器的动态专家调用机制,让模型在单张A100显卡上的日处理能力可达20万页文档,兼顾高精度与高吞吐量4。
3.4 实用性提升:更强的场景适配能力
支持PDF、JPG、PNG等多种文件格式,可直接处理多栏论文、嵌套表格、公式密集文档、古籍等复杂场景,无需额外的版面分析预处理;同时,视觉分词模块支持灵活替换,适配不同硬件资源,降低落地门槛。
四、与传统OCR模型的全面对比
为更清晰地展现DeepSeek-OCR-v2的优势,我们从架构、核心能力、处理逻辑、场景适配等维度,与传统OCR(包括基于ViT的深度学习OCR)进行全面对比:
| 对比维度 | 传统OCR模型 | DeepSeek-OCR-v2 |
|---|---|---|
| 编码架构 | 基于ViT/CNN,仅负责特征提取,无因果推理能力 | LLM(Qwen2-0.5B)为底座,融合视觉-语言因果推理 |
| 注意力机制 | 多采用单向/双向固定注意力,无动态重排能力 | 双流注意力(视觉流双向+因果流单向),支持Token动态重排 |
| 处理逻辑 | 光栅扫描(固定顺序),编码器提取特征,解码器纠正顺序 | 视觉因果流(语义顺序),编码器完成重排,解码器专注生成 |
| 复杂版面适配 | 双栏、表格易串读,需额外版面分析模块 | 原生支持复杂版面,无需额外预处理,顺序还原精度高 |
| Token管理 | 压缩比与细节失衡,计算成本高 | 16倍高效压缩,多尺度适配,兼顾细节与效率 |
| 推理效率 | 解码器需纠正顺序,算力浪费严重 | 编码阶段完成重排,MoE解码器高效生成,吞吐量提升显著 |
| 落地门槛 | 需搭配版面分析、顺序纠正模块,部署复杂 | 端到端处理,支持多格式文件,部署简洁 |
| 从对比中可看出,DeepSeek-OCR-v2的核心优势并非"局部优化",而是对OCR处理逻辑的重构------以人类阅读认知为灵感,用因果推理替代机械扫描,让模型真正"看懂"文档结构,而非单纯"识别"字符。 |
五、DeepSeek-OCR-v2 部署实践(基于VLLM)
DeepSeek-OCR-v2支持多种部署方式,结合模型的高效推理特性,推荐采用"FastAPI+VLLM"的异步部署方案,兼顾高并发与低延迟,适配生产环境的单文件(图片/PDF)处理需求。以下是详细部署步骤:
5.1 部署环境准备
5.1.1 硬件要求
推荐GPU配置:NVIDIA A100(16G及以上显存);入门配置:NVIDIA RTX 3090/4090(适合测试与小规模部署);CPU部署需关闭VLLM,推理速度会大幅下降,不推荐生产使用。
5.1.2 软件依赖安装
创建虚拟环境并安装依赖:
bash
# 创建虚拟环境
conda create --name deepseek-ocr-2 python=3.12
conda activate deepseek-ocr-2
# 安装核心依赖
pip install torch==2.6.0 torchvision==0.21.0 -//mirrors.tuna.tsinghua.edu.cn/pypi/web/simple/
pip install vllm==0.8.5 -i https://mirrors.tunua.edu.cn/pypi/web/simple/
# 安装deepseek-ocr2相关依赖(需从官方仓库获取process模块)
git clone https://github.com/deepseek-ai/DeepSeek-OCR2.git
cd DeepSeek-OCR2
pip install -r requirements.txts://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple/
pip install flash-attn==2.7.3 -d-isolation5.2 核心配置文件(config.py)
配置模型路径、处理参数、文件路径等,适配自身环境:
进入vllm路径 DeepSeek-OCR-2/DeepSeek-OCR2-master/DeepSeek-OCR2-vllm/config.py
python
BASE_SIZE = 1024
IMAGE_SIZE = 768
CROP_MODE = True
MIN_CROPS= 2
MAX_CROPS= 6 # max:6
MAX_CONCURRENCY = 100 # If you have limited GPU memory, lower the concurrency count.
NUM_WORKERS = 64 # image pre-process (resize/padding) workers
PRINT_NUM_VIS_TOKENS = False
SKIP_REPEAT = True
MODEL_PATH = '/data/models/deepseek-ai/DeepSeek-OCR-2' # change to your model path
# TODO: change INPUT_PATH
# .pdf: run_dpsk_ocr_pdf.py;
# .jpg, .png, .jpeg: run_dpsk_ocr_image.py;
# Omnidocbench images path: run_dpsk_ocr_eval_batch.py
# 替换你自己的pdf路径 和输出路径
INPUT_PATH = '/data/huangchangbin/deepseek-ocr-2/DeepSeek-OCR-2/DeepSeek-OCR2-master/input_data/wangxuewen.pdf'
OUTPUT_PATH = '/data/huangchangbin/deepseek-ocr-2/DeepSeek-OCR-2/DeepSeek-OCR2-master/output_data/'
PROMPT = '<image>\n<|grounding|>Convert the document to markdown.'
# PROMPT = '<image>\nFree OCR.'
# .......
from transformers import AutoTokenizer
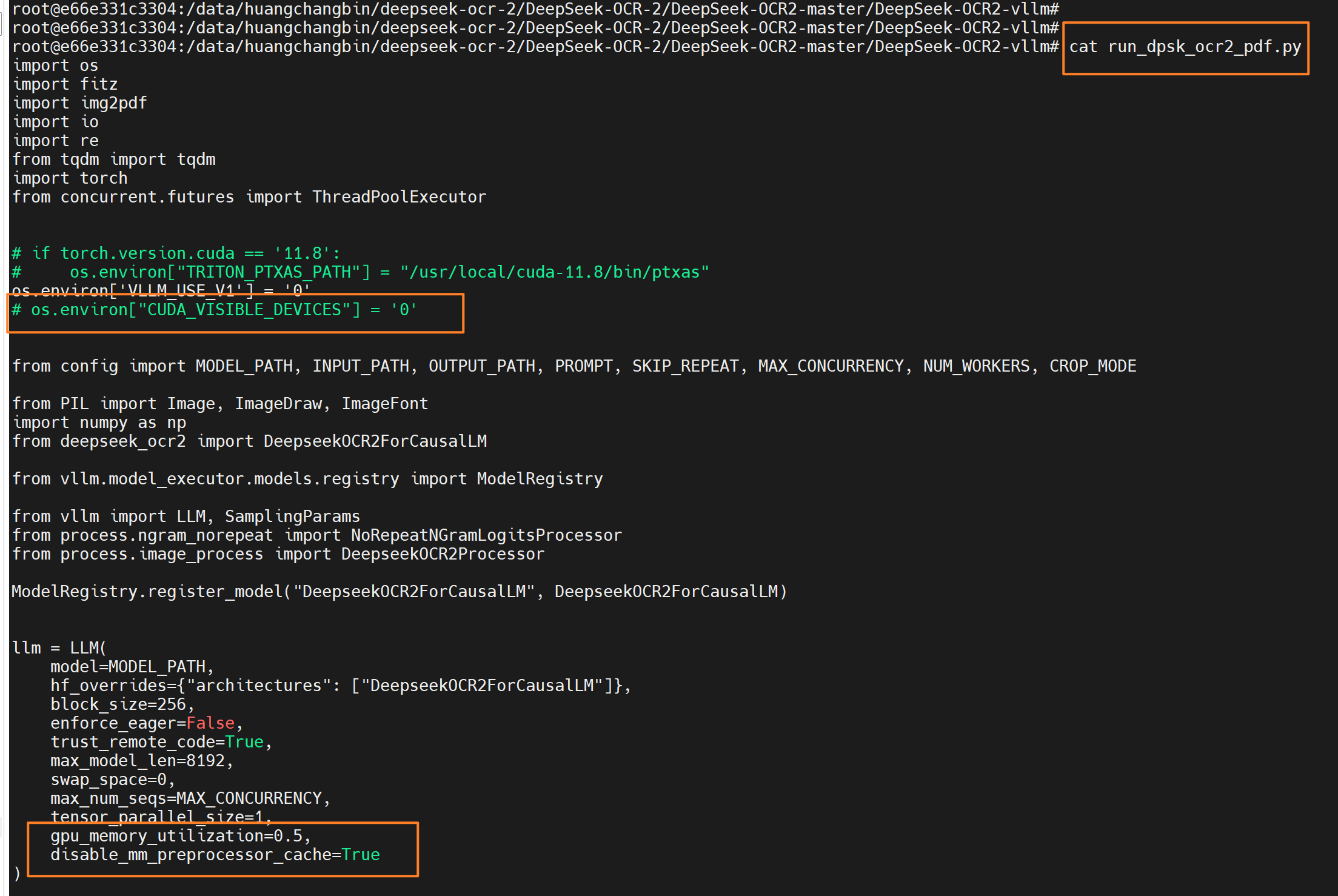
TOKENIZER = AutoTokenizer.from_pretrained(MODEL_PATH, trust_remote_code=True)执行pdf解析
根据你的GPU情况调整一些配置:
python
# 指定卡号执行,如果你只有一张卡则不用指定
CUDA_VISIBLE_DEVICES=2 python run_dpsk_ocr2_pdf.py六、OCR服务封装-简易前后端
上面的操作能够跑通deepseek-ocr-2,但是使用起来不方便。现在构造一个简易的客户端,可以直接上传图片并输出解析结果。
后端服务
.../DeepSeek-OCR-2/DeepSeek-OCR2-master/DeepSeek-OCR2-vllm下创建下面两个文件。
config.py
python
# config.py
import os
from transformers import AutoTokenizer
# 基础配置
BASE_SIZE = 1024
IMAGE_SIZE = 768
CROP_MODE = True
MIN_CROPS = 2
MAX_CROPS = 6 # max:6
MAX_CONCURRENCY = 100 # GPU显存不足时降低
NUM_WORKERS = 64 # 图片预处理线程数
PRINT_NUM_VIS_TOKENS = False
SKIP_REPEAT = True
# 模型路径(请修改为你的实际路径)
MODEL_PATH = '/data/models/deepseek-ai/DeepSeek-OCR-2'
# 提示词配置
PROMPT = '<image>\n<|grounding|>Convert the document to markdown.'
# 初始化tokenizer
TOKENIZER = AutoTokenizer.from_pretrained(MODEL_PATH, trust_remote_code=True)
# 临时文件目录(自动创建)
TEMP_DIR = './temp'
os.makedirs(TEMP_DIR, exist_ok=True)
# 输出目录
OUTPUT_BASE_PATH = './output'
os.makedirs(OUTPUT_BASE_PATH, exist_ok=True)main.py
python
import re
import os
import io
import tempfile
import asyncio
from pathlib import Path
from typing import Optional
import fitz
import img2pdf
import numpy as np
from PIL import Image, ImageDraw, ImageFont, ImageOps
from tqdm import tqdm
import torch
from fastapi import FastAPI, UploadFile, File, HTTPException, Request
from fastapi.staticfiles import StaticFiles
from fastapi.responses import HTMLResponse, JSONResponse
from vllm import AsyncLLMEngine, SamplingParams
from vllm.engine.arg_utils import AsyncEngineArgs
from vllm.model_executor.models.registry import ModelRegistry
# 导入配置
from config import (
MODEL_PATH, PROMPT, CROP_MODE, SKIP_REPEAT,
TEMP_DIR, OUTPUT_BASE_PATH, MAX_CONCURRENCY
)
# 注册DeepSeek-OCR2模型
from deepseek_ocr2 import DeepseekOCR2ForCausalLM
ModelRegistry.register_model("DeepseekOCR2ForCausalLM", DeepseekOCR2ForCausalLM)
# 导入处理器
from process.ngram_norepeat import NoRepeatNGramLogitsProcessor
from process.image_process import DeepseekOCR2Processor
# 全局初始化vllm异步引擎(避免重复加载模型)
engine: Optional[AsyncLLMEngine] = None
# FastAPI应用初始化
app = FastAPI(title="DeepSeek-OCR-v2 Service", version="1.0")
# 挂载静态文件(前端页面)
app.mount("/static", StaticFiles(directory="static"), name="static")
# ======================== 工具函数 ========================
def init_vllm_engine():
"""初始化vllm异步引擎(全局单例)"""
global engine
if engine is None:
# 设置CUDA环境
# if torch.version.cuda == '11.8':
# os.environ["TRITON_PTXAS_PATH"] = "/usr/local/cuda-11.8/bin/ptxas"
os.environ['VLLM_USE_V1'] = '0'
# os.environ["CUDA_VISIBLE_DEVICES"] = '0'
# 引擎参数
engine_args = AsyncEngineArgs(
model=MODEL_PATH,
hf_overrides={"architectures": ["DeepseekOCR2ForCausalLM"]},
dtype="bfloat16",
max_model_len=8192,
enforce_eager=False,
trust_remote_code=True,
tensor_parallel_size=1,
gpu_memory_utilization=0.5,
max_num_seqs=MAX_CONCURRENCY,
swap_space=0,
disable_mm_preprocessor_cache=True
)
engine = AsyncLLMEngine.from_engine_args(engine_args)
return engine
def pdf_to_images_high_quality(pdf_path: str, dpi: int = 300) -> list[Image.Image]:
"""PDF转高质量图片"""
images = []
try:
pdf_document = fitz.open(pdf_path)
zoom = dpi / 72.0
matrix = fitz.Matrix(zoom, zoom)
for page_num in range(pdf_document.page_count):
page = pdf_document[page_num]
pixmap = page.get_pixmap(matrix=matrix, alpha=False)
Image.MAX_IMAGE_PIXELS = None
img_data = pixmap.tobytes("png")
img = Image.open(io.BytesIO(img_data))
# 处理透明背景
if img.mode in ('RGBA', 'LA'):
background = Image.new('RGB', img.size, (255, 255, 255))
background.paste(img, mask=img.split()[-1] if img.mode == 'RGBA' else None)
img = background
images.append(img)
pdf_document.close()
except Exception as e:
raise HTTPException(status_code=500, detail=f"PDF转图片失败: {str(e)}")
return images
def load_image(image_bytes: bytes) -> Image.Image:
"""加载图片(处理EXIF旋转)"""
try:
image = Image.open(io.BytesIO(image_bytes))
corrected_image = ImageOps.exif_transpose(image)
return corrected_image.convert('RGB')
except Exception as e:
raise HTTPException(status_code=500, detail=f"加载图片失败: {str(e)}")
def re_match(text: str) -> tuple[list, list, list]:
"""匹配并提取ref/det标签内容"""
pattern = r'(<\|ref\|>(.*?)<\|/ref\|><\|det\|>(.*?)<\|/det\|>)'
matches = re.findall(pattern, text, re.DOTALL)
mathes_image = []
mathes_other = []
for a_match in matches:
if '<|ref|>image<|/ref|>' in a_match[0]:
mathes_image.append(a_match[0])
else:
mathes_other.append(a_match[0])
return matches, mathes_image, mathes_other
def clean_content(content: str, matches_images: list, matches_other: list, page_idx: int = 0) -> str:
"""清理OCR结果,移除冗余标签,替换图片引用"""
# 替换图片标签
for idx, a_match_image in enumerate(matches_images):
content = content.replace(a_match_image, f'\n')
# 移除其他标签并清理特殊字符
for a_match_other in matches_other:
content = content.replace(a_match_other, '')
content = content.replace('\\coloneqq', ':=').replace('\\eqqcolon', '=:')
content = re.sub(r'\n{3,}', '\n\n', content) # 合并多余换行
# 移除结束符
if '<|end▁of▁sentence|>' in content:
content = content.replace('<|end▁of▁sentence|>', '')
return content
async def ocr_single_image(image: Image.Image, prompt: str = PROMPT) -> str:
"""单张图片OCR处理(异步)"""
# 初始化引擎
engine = init_vllm_engine()
# 图片预处理
image_features = DeepseekOCR2Processor().tokenize_with_images(
images=[image], bos=True, eos=True, cropping=CROP_MODE
)
# 采样参数
logits_processors = [NoRepeatNGramLogitsProcessor(
ngram_size=20, window_size=90, whitelist_token_ids={128821, 128822}
)]
sampling_params = SamplingParams(
temperature=0.0,
max_tokens=8192,
logits_processors=logits_processors,
skip_special_tokens=False,
include_stop_str_in_output=True,
)
# 构建请求
request_id = f"ocr-{int(asyncio.get_event_loop().time() * 1000)}"
request = {
"prompt": prompt,
"multi_modal_data": {"image": image_features}
}
# 异步生成结果
full_text = ""
async for request_output in engine.generate(request, sampling_params, request_id):
if request_output.outputs:
full_text = request_output.outputs[0].text
return full_text
# ======================== 核心OCR处理函数 ========================
async def process_pdf_file(file_bytes: bytes) -> str:
"""处理PDF文件,返回最终的contents"""
# 保存临时PDF文件
with tempfile.NamedTemporaryFile(
suffix='.pdf', dir=TEMP_DIR, delete=False
) as temp_pdf:
temp_pdf.write(file_bytes)
temp_pdf_path = temp_pdf.name
try:
# PDF转图片
images = pdf_to_images_high_quality(temp_pdf_path)
total_contents = []
# 逐页处理
for page_idx, image in enumerate(tqdm(images, desc="Processing PDF pages")):
# OCR识别
raw_content = await ocr_single_image(image)
# 跳过重复内容(配置控制)
if SKIP_REPEAT and '<|end▁of▁sentence|>' not in raw_content:
continue
# 清理内容
_, matches_images, matches_other = re_match(raw_content)
cleaned_content = clean_content(raw_content, matches_images, matches_other, page_idx)
# 添加分页标记
total_contents.append(f"\n<--- Page {page_idx + 1} --->\n{cleaned_content}")
# 合并所有页面内容
final_content = "\n".join(total_contents)
return final_content
finally:
# 删除临时文件
os.unlink(temp_pdf_path)
async def process_image_file(file_bytes: bytes) -> str:
"""处理图片文件,返回最终的contents"""
# 加载图片
image = load_image(file_bytes)
# OCR识别
raw_content = await ocr_single_image(image)
# 清理内容
_, matches_images, matches_other = re_match(raw_content)
final_content = clean_content(raw_content, matches_images, matches_other)
return final_content
# ======================== API接口 ========================
@app.get("/", response_class=HTMLResponse)
async def serve_frontend():
"""提供前端页面"""
with open("static/index.html", "r", encoding="utf-8") as f:
return HTMLResponse(content=f.read(), status_code=200)
@app.post("/api/ocr")
async def ocr_api(file: UploadFile = File(...)):
"""
OCR核心接口
支持文件类型:pdf, jpg, jpeg, png
返回:清理后的markdown格式内容
"""
try:
# 验证文件类型
file_ext = Path(file.filename).suffix.lower()
supported_ext = ['.pdf', '.jpg', '.jpeg', '.png']
if file_ext not in supported_ext:
raise HTTPException(
status_code=400,
detail=f"不支持的文件类型:{file_ext},仅支持:{', '.join(supported_ext)}"
)
# 读取文件内容
file_bytes = await file.read()
if not file_bytes:
raise HTTPException(status_code=400, detail="上传文件为空")
# 根据文件类型处理
if file_ext == '.pdf':
result = await process_pdf_file(file_bytes)
else:
result = await process_image_file(file_bytes)
return JSONResponse({
"status": "success",
"filename": file.filename,
"content": result
})
except HTTPException as e:
raise e
except Exception as e:
raise HTTPException(status_code=500, detail=f"处理失败:{str(e)}")
# ======================== 启动入口 ========================
if __name__ == "__main__":
import uvicorn
# 启动服务(支持热重载,生产环境请关闭reload)
uvicorn.run(
"main:app",
host="0.0.0.0",
port=8001, # 实际调整
reload=False, # 生产环境设为False
workers=1 # 模型单例,仅需1个worker
)前端界面
目录下新建 static 目录,创建index.html文件
python
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>DeepSeek-OCR-v2 在线服务</title>
<style>
* {
margin: 0;
padding: 0;
box-sizing: border-box;
font-family: Arial, sans-serif;
}
body {
max-width: 1200px;
margin: 0 auto;
padding: 20px;
background-color: #f5f5f5;
}
.container {
background: white;
padding: 30px;
border-radius: 8px;
box-shadow: 0 2px 10px rgba(0,0,0,0.1);
}
h1 {
color: #333;
margin-bottom: 20px;
text-align: center;
}
.upload-area {
border: 2px dashed #ccc;
border-radius: 6px;
padding: 40px 20px;
text-align: center;
margin-bottom: 20px;
cursor: pointer;
transition: border-color 0.3s;
}
.upload-area:hover {
border-color: #4299e1;
}
.upload-area.active {
border-color: #48bb78;
}
#file-input {
display: none;
}
.btn-container {
text-align: center;
margin-bottom: 20px; /* 和上传区域分开 */
}
.upload-btn {
background-color: #4299e1;
color: white;
border: none;
padding: 10px 20px;
border-radius: 4px;
cursor: pointer;
font-size: 16px;
}
.upload-btn:hover {
background-color: #3182ce;
}
.upload-btn:disabled {
background-color: #ccc;
cursor: not-allowed;
}
.result-area {
margin-top: 30px;
display: none;
}
.result-title {
font-size: 18px;
margin-bottom: 10px;
color: #333;
}
.result-content {
width: 100%;
height: 400px;
border: 1px solid #ccc;
border-radius: 4px;
padding: 10px;
font-family: monospace;
white-space: pre-wrap;
overflow-y: auto;
background-color: #fafafa;
}
.loading {
text-align: center;
margin: 20px 0;
display: none;
}
.error {
color: #e53e3e;
text-align: center;
margin: 10px 0;
display: none;
}
.file-name {
text-align: center;
margin: 10px 0;
color: #666;
display: none;
}
</style>
</head>
<body>
<div class="container">
<h1>DeepSeek-OCR-v2 在线识别</h1>
<!-- 上传区域(仅用于选择文件) -->
<div class="upload-area" id="upload-area">
<p>点击或拖拽文件到此处上传</p>
<p style="color: #666; margin-top: 10px;">支持格式:PDF、JPG、PNG</p>
<input type="file" id="file-input" accept=".pdf,.jpg,.jpeg,.png">
</div>
<!-- 已选择文件提示 -->
<div class="file-name" id="file-name">已选择:<span id="selected-file-name"></span></div>
<!-- 提交按钮(移到上传区域外) -->
<div class="btn-container">
<button class="upload-btn" id="submit-btn" disabled>开始识别</button>
</div>
<!-- 加载提示 -->
<div class="loading" id="loading">
<p>正在识别中,请稍候...</p>
</div>
<!-- 错误提示 -->
<div class="error" id="error"></div>
<!-- 结果区域 -->
<div class="result-area" id="result-area">
<div class="result-title">识别结果:</div>
<div class="result-content" id="result-content"></div>
</div>
</div>
<script>
const uploadArea = document.getElementById('upload-area');
const fileInput = document.getElementById('file-input');
const submitBtn = document.getElementById('submit-btn');
const loading = document.getElementById('loading');
const error = document.getElementById('error');
const resultArea = document.getElementById('result-area');
const resultContent = document.getElementById('result-content');
const fileName = document.getElementById('file-name');
const selectedFileName = document.getElementById('selected-file-name');
// 拖拽文件
uploadArea.addEventListener('dragover', (e) => {
e.preventDefault();
uploadArea.classList.add('active');
});
uploadArea.addEventListener('dragleave', () => {
uploadArea.classList.remove('active');
});
uploadArea.addEventListener('drop', (e) => {
e.preventDefault();
uploadArea.classList.remove('active');
if (e.dataTransfer.files.length > 0) {
fileInput.files = e.dataTransfer.files;
updateFileInfo(); // 更新文件提示
submitBtn.disabled = false;
}
});
// 点击选择文件(仅上传区域触发)
uploadArea.addEventListener('click', () => {
fileInput.click();
});
// 文件选择后更新状态
fileInput.addEventListener('change', () => {
updateFileInfo(); // 更新文件提示
submitBtn.disabled = fileInput.files.length === 0;
});
// 更新已选择文件信息
function updateFileInfo() {
if (fileInput.files.length > 0) {
selectedFileName.textContent = fileInput.files[0].name;
fileName.style.display = 'block';
} else {
fileName.style.display = 'none';
}
}
// 提交识别(阻止事件冒泡,双重保险)
submitBtn.addEventListener('click', async (e) => {
e.stopPropagation(); // 阻止事件冒泡到上传区域
const file = fileInput.files[0];
if (!file) return;
// 重置状态
loading.style.display = 'block';
error.style.display = 'none';
resultArea.style.display = 'none';
// 构建FormData
const formData = new FormData();
formData.append('file', file);
try {
// 发送请求
const response = await fetch('/api/ocr', {
method: 'POST',
body: formData
});
const data = await response.json();
if (response.ok) {
// 显示结果
loading.style.display = 'none';
resultContent.textContent = data.content;
resultArea.style.display = 'block';
} else {
throw new Error(data.detail || '识别失败');
}
} catch (err) {
loading.style.display = 'none';
error.textContent = `错误:${err.message}`;
error.style.display = 'block';
}
});
</script>
</body>
</html>展示
虚拟环境下启动:python main.py
浏览器访问 http://10.10.185.1:8601/ ip+端口号
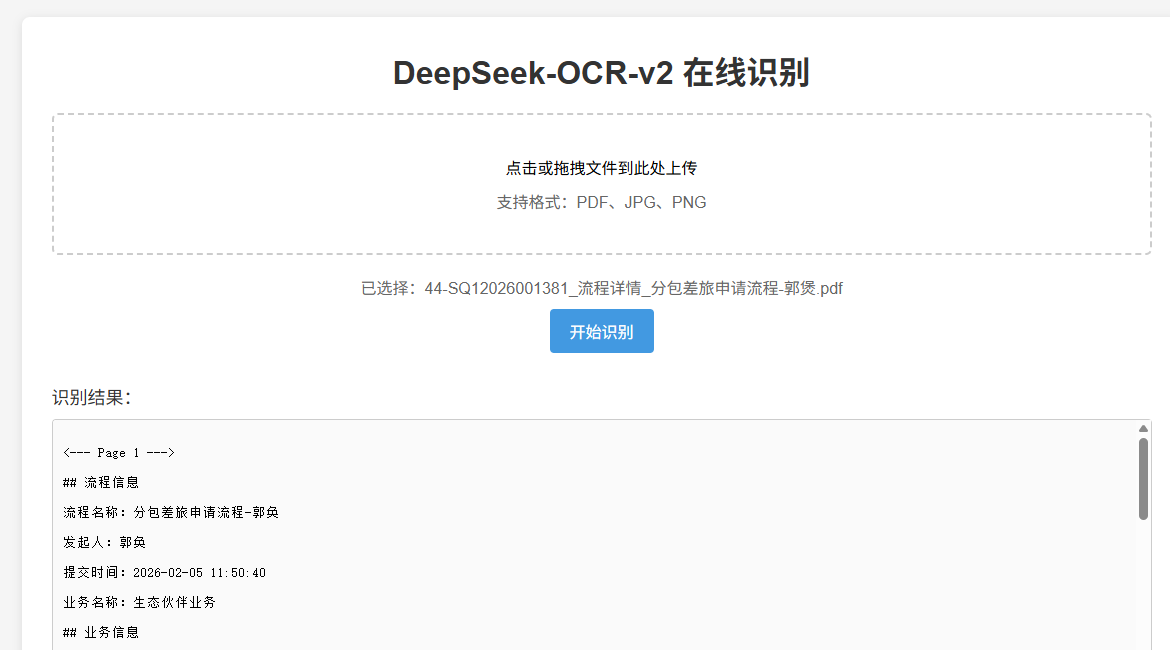
实际体验
deepseek-ocr-2效果在测试的场景中表现较佳。但是解析错误、遗漏的问题仍然存在。综合来看值得尝试应用。