如何形容现在市面上普遍的 OCR 呢?可能你已经习惯了它的「固执」------无论文档布局多复杂,它总是老老实实从左到右、从上到下扫一遍。遇到双栏论文还好,碰上跨页表格或者公式脚注混排,输出结果往往乱得让人头疼。这不是识别不准,而是理解方式出了问题。
今年 1 月 DeepSeek 团队推出的 DeepSeek-OCR 2 换了个思路,它不再把文档当成一张平面图,而是尝试理解这篇文章应该先读什么。新设计的 DeepEncoder V2 架构引入了因果流机制:视觉编码器看完整个页面后,由专门的查询模块决定阅读顺序------标题优先于正文,表格注释紧跟数据,公式按逻辑展开而非按位置罗列。
结果很直接。OmniDocBench 最新测试中,这套方案把整体准确率推到了 91% 以上,公式识别的提升尤为明显。更实用的是,它输出的 Markdown 已经带着层级结构,省去了大量后期整理的功夫。
参数规模控制在单卡能跑的级别,token 上限可调,重复生成的情况也比上一代少了近三分之一。对于需要批量处理文档的场景,这意味着可用性的大幅提升。
当一个模型能够同时看懂版式、识别文字并直接输出结构化结果,文档数字化的目标就不再只是「能认字」,而是「能理解」。DeepSeek-OCR 2 正是在这一方向上的一次重要尝试。
教程链接:https://go.openbayes.com/NOdm2
使用云平台: OpenBayes
http://openbayes.com/console/signup?r=sony_0m6v
首先点击「公共教程」,找到「DeepSeek-OCR 2:视觉因果流」,单击打开。
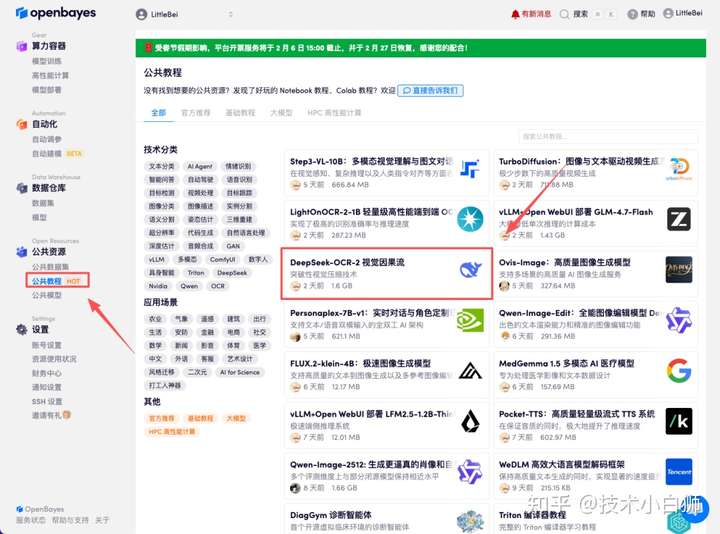
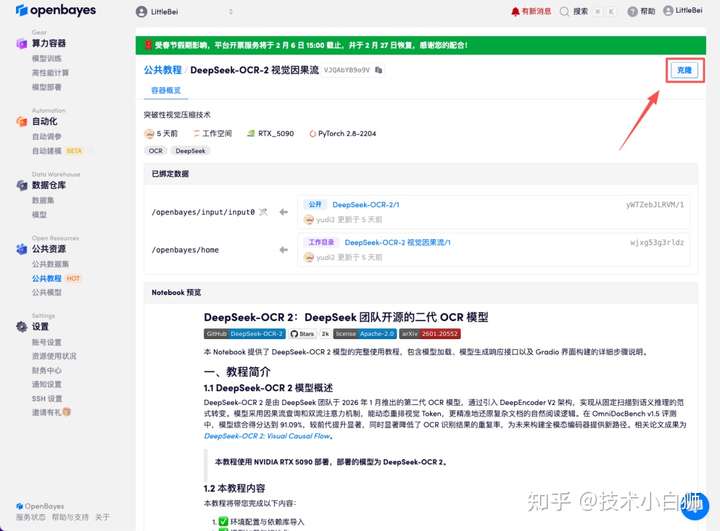
页面跳转后,点击右上角「克隆」,将该教程克隆至自己的容器中。
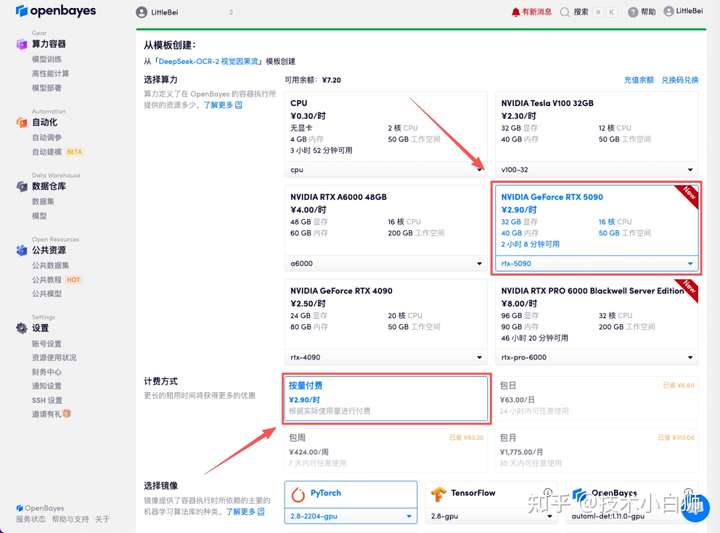
在当前页面中看到的算力资源均可以在平台一键选择使用。平台会默认选配好原教程所使用的算力资源、镜像版本,不需要再进行手动选择。点击「继续执行」,等待分配资源。
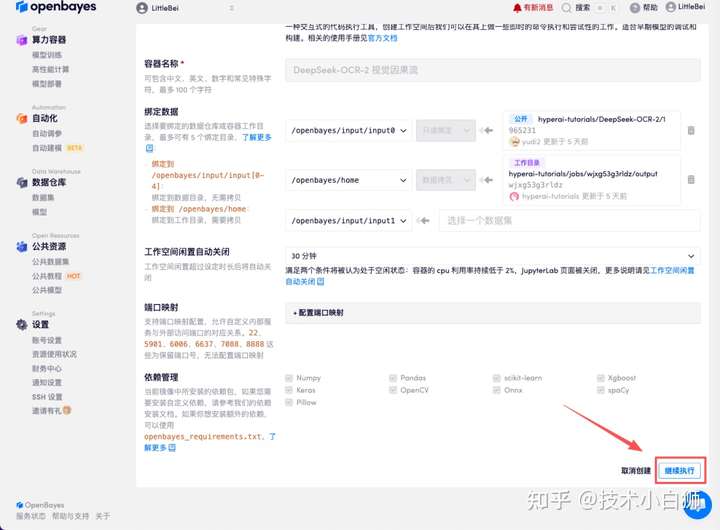
若显示「Bad Gateway」,这表示模型正在加载中,请等待约 2-3 分钟后刷新页面即可。
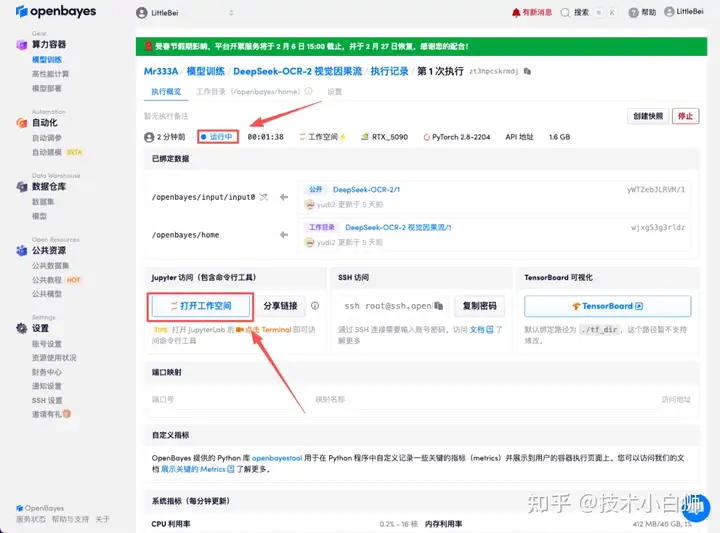
使用步骤如下:
- 页面跳转后,点击左侧 README 页面,进入后点击上方「运行」。
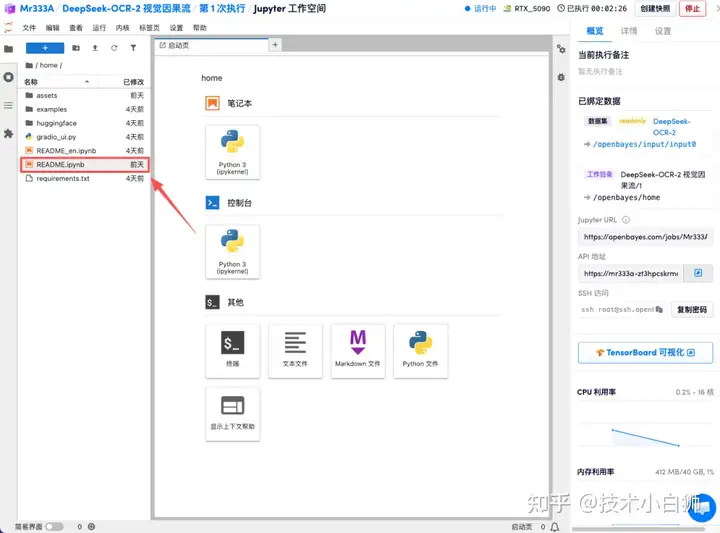
2.点击运行后等待加载模型与初始化
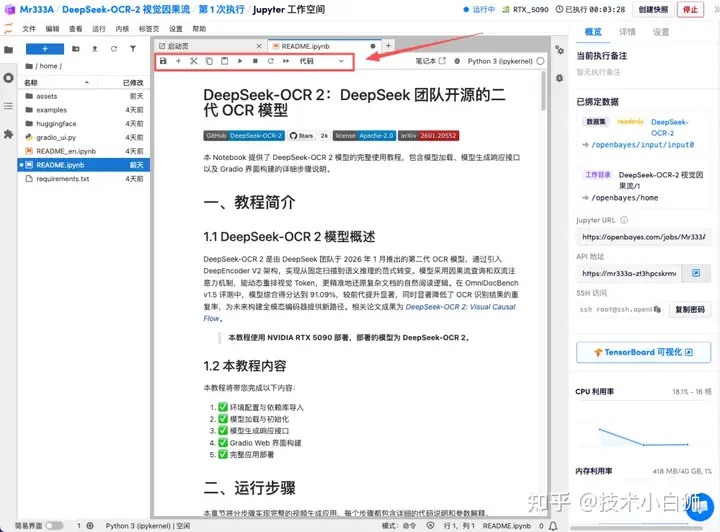
3.运行完成,即可点击右侧 API 地址跳转至 demo 页面。
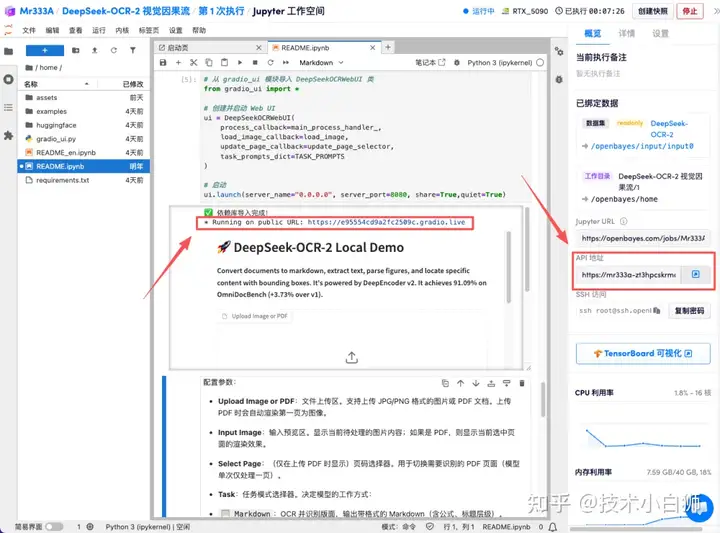
4.上传所需要的 JPG/PNG 格式的图片或 PDF 文档。
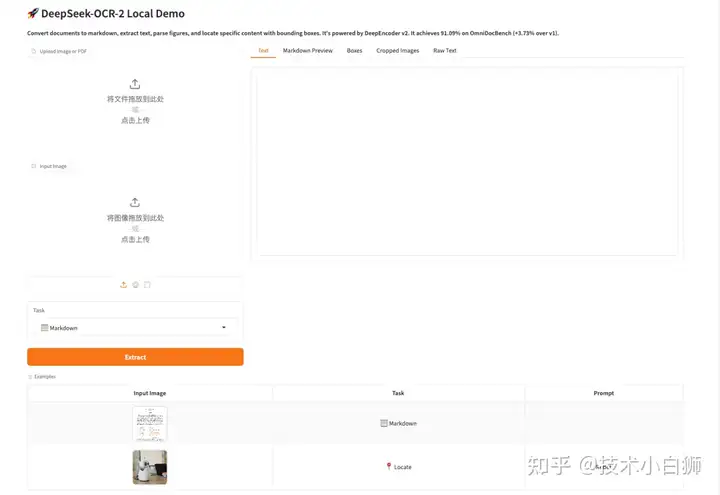
5.上传完成后点击运行,稍等片刻右侧结果框生成纯文本结果。
