昨天,DeepSeek发布了DeepSeek-OCR-21,主要是对编码器部分,进行了一个小修改。
比起,DeepSeek-OCR,DeepSeek-OCR-2 的改动幅度不大,有点像是做了一个固定解码器,优化编码器的消融实验,比起 DeepSeek-OCR 的创新程度,这篇工作有点让人失望。
这篇文章的内容建立在已经充分了解前作 DeepSeek-OCR 的基础之上。
如果不了解DeepSeek-OCR,可以回看我之前写的文章。
DeepSeek-OCR-2 新内容
这篇文章的新内容乏善可陈,一句话就能描述完,那就是把 DeepEncoder 升级成了 DeepEncoder V2。
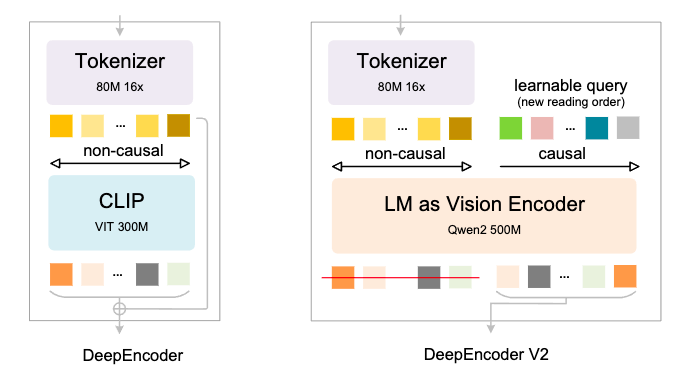
如图所示,具体就是把原本的 CLIP 换成了 Qwen2-500M 这样一个语言模型。
为什么要怎么做?
出发点还是模拟人类:人类在阅读文章时,往往是按照一定顺序,比如从上到下,从左到右,没有谁会倒着读上来。
所以,对于模型来说,一堆视觉Token一起输入进来,也应该按照一定的先后顺序去阅读。
因此,DeepEncoder V2在除了保留视觉Token之外,加入了可学习的序列(learnable query),并使用因果注意力(causal)。
因果注意力的原理很简单,就是用一个下三角掩码去让当前token只关注到当前和其前面的信息,而看不到后面的信息。这个是一个比较常见的操作。
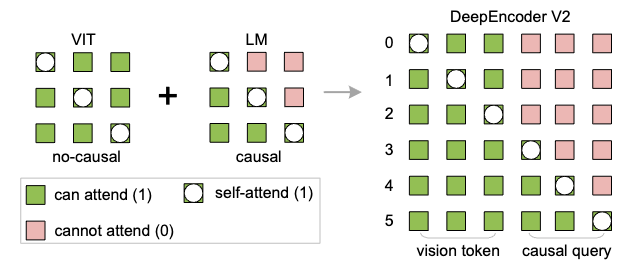
下面这张图很明确地把DeepEncoder V2的精髓画出来了,那就是视觉编码VIT不用mask,就像人看书时,整页纸是能够一块被看到的。
而额外引入的语言编码LM就需要做mask,它代表的是阅读顺序,至于顺序是从上往下,还是从左往右,不强制,让模型自己学出来。
看到这里,新的内容已经结束了,DeepSeek-OCR-2 唯一的新变化就是改了这一步骤,把原本的CLIP变成了一个语言模型,去做视觉编码。
为什么选择Qwen2-500M呢?因为其 500M 参数与 CLIP (300M) 参数差不多,这样对模型来说,参数量不会增加太多。
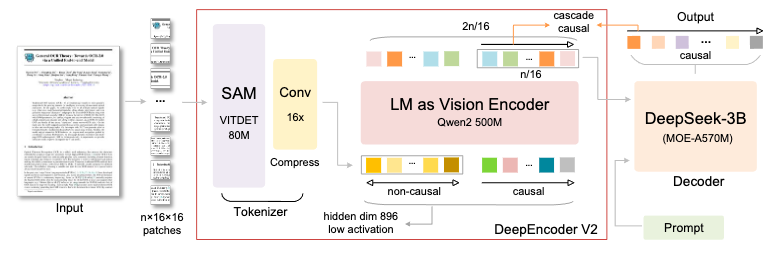
其余部分就没有变化,整个模型结构如下图所示。
实验结果
仅改进了这一点,效果如何呢?作者还是选用文档解析的 OmniDocBench Benchmark进行实验,结果如下表所示。
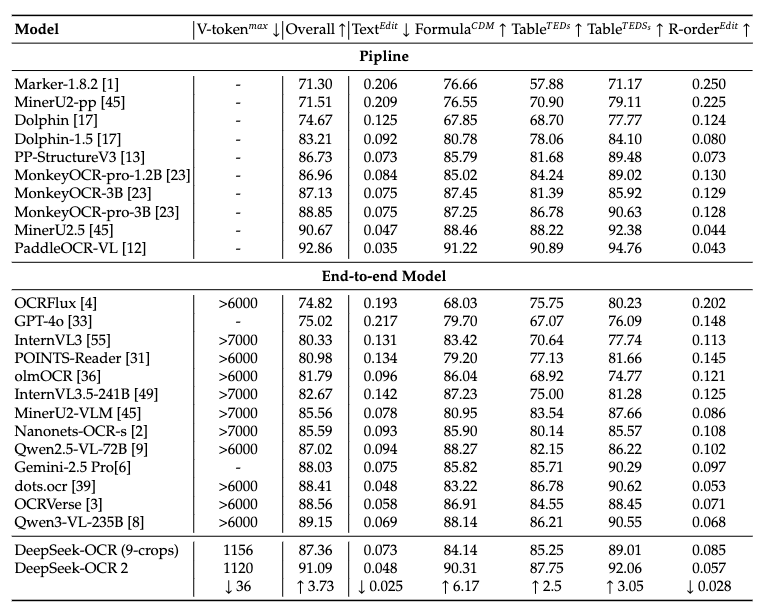
相比于DeepSeek-OCR,二代版本在视觉压缩方面没有明显的进步(减少36个Token),综合性能来说有明显提升(提升了三个点),但目前还不是SOTA。
总结
DeepSeek-OCR-2主要就是把一些已知的内容进行了一些工程化结合,没有太多创新性。
整体观感乏善可陈。
主要是 DeepSeek-OCR 的这个概念很新颖,属于是可能颠覆掉分词器的架构。
所以,大家普遍认为,既然 DeepSeek-OCR 已经在文档解析这个任务上验证过有效性了,那下一步应该推广到更广泛的领域,做成通用的形态。
但是,DeepSeek-OCR-2还是在小范围的试错,做小修小补的工作,更希望在下一代能够看到它把步子迈得再大点。
参考
1 https://github.com/deepseek-ai/DeepSeek-OCR-2/blob/main/DeepSeek_OCR2_paper.pdf