如何本地部署大模型(以PaddleOCR-VL-1.5为例)
- 阶段1:Windows环境基础准备
-
- [1-1 显卡驱动准备](#1-1 显卡驱动准备)
- [1-2 开启 WSL2](#1-2 开启 WSL2)
- [1-3 安装Docker Desktop](#1-3 安装Docker Desktop)
- 阶段2:建立工作区
-
- [2-1 创建存放模型的文件夹](#2-1 创建存放模型的文件夹)
- [2-2 下载模型](#2-2 下载模型)
- 阶段3:编写配置文件
-
- [3-1 配置文件docker-compose.yml](#3-1 配置文件docker-compose.yml)
- [3-2 配置文件Dockerfile](#3-2 配置文件Dockerfile)
- [3-3 版面分析接口文件layout_api.py](#3-3 版面分析接口文件layout_api.py)
- 阶段4:一键启动与验证
- 续更~
-
- [文件1- Docker](#文件1- Docker)
- [文件2- docker-compose.yml](#文件2- docker-compose.yml)
- [文件3- layout_api.py](#文件3- layout_api.py)
- [文件4- test_ocr.py](#文件4- test_ocr.py)
背景描述 :
近期工作时发现自己对高精度OCR的需求量很大,需求点是可支持本地离线使用+高精度,尝试了Umi-OCR模型测试第一张照片便败下阵来,联想起前段时间使用Quicker自带的OCR功能(精度很高,但免费使用次数有限,后经查询发现是百度的API),决定在本地部署百度的 PaddleOCR-VL-1.5 模型:参数量不大约为0.9B、模型文件约4GB、运行内存占用约为6GB、显卡要求为RTX3060及其以上。
由于不想面临CUDA版本以及底层C++库的冲突,决定选择在Docker中部署该视觉模型,以下是一份保姆级的配置方案。
阶段1:Windows环境基础准备
1-1 显卡驱动准备
要确保自己的Windows安装了最新的 NVIDIA 显卡驱动。
- Step1。确定自己电脑的显卡类型。
win+r输入指令dxdiag,显示中查看自己
的GPU类型,图1中可看到我的GPU是RTX 3060。

(图1)
- Step2。进入NVIDIA官网https://www.nvidia.cn/drivers/,按照图2列表选择自己显卡对应的选项,点击
查找,下载图3中的NVIDIA Studio版本(适合做深度学习等任务),然后按照图4-6中的选项进行安装(过程中会让电脑重启,点击重启就行)。
安装完新版GPU驱动后可能出现输入法无法正常工作的情况,一般是由于输入法兼容性组件更新后的兼容性冲突导致,解决方案参考我的另一篇博客https://blog.csdn.net/Codefengfeng/article/details/158809276?sharetype=blogdetail&sharerId=158809276&sharerefer=PC&sharesource=Codefengfeng&spm=1011.2480.3001.8118

(图2)
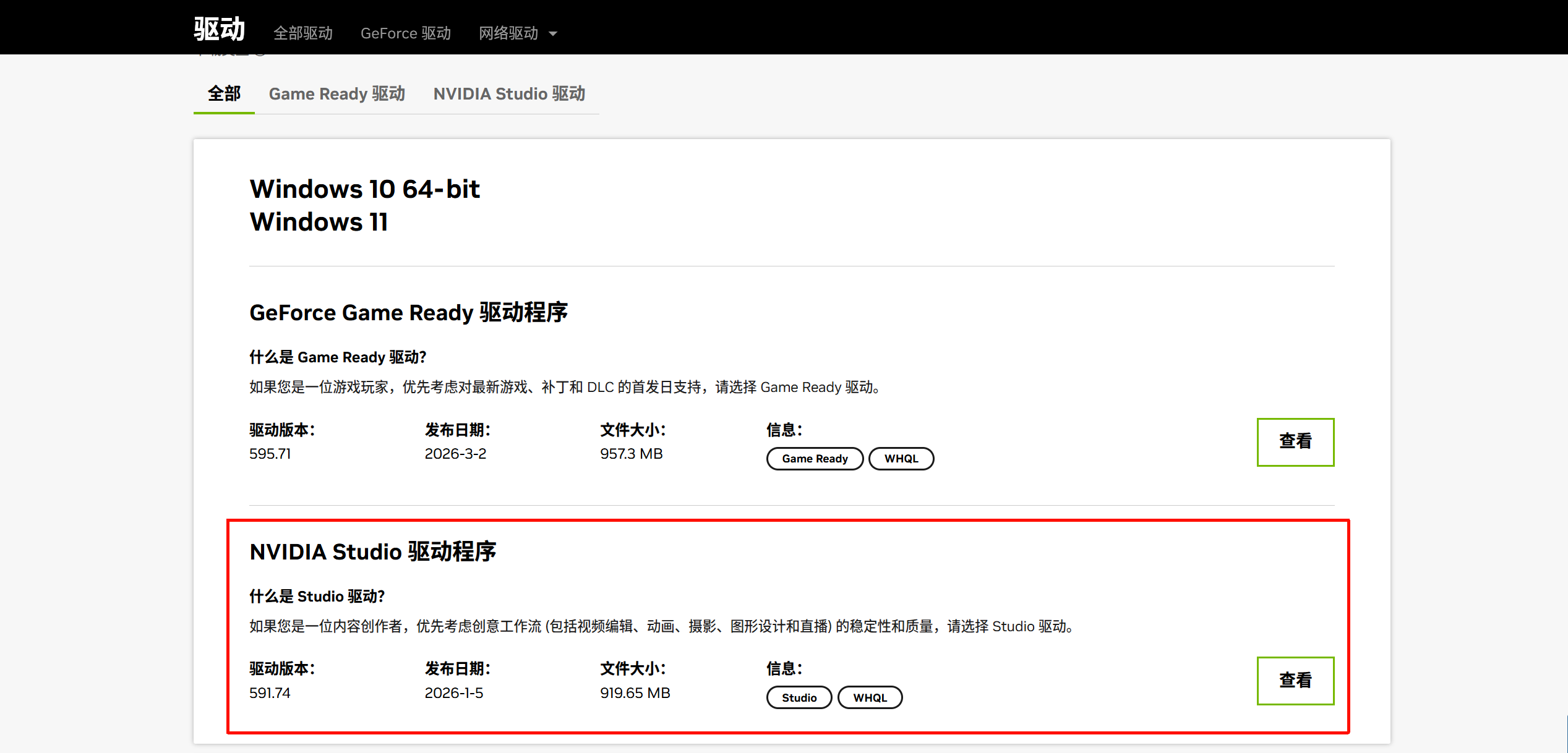
(图3)

(图4-图6)
- Step3。测试显卡驱动是否成功安装。
win+r->cmd->nvidia-smi,可看到类似图7的驱动版本信息

(图7)
1-2 开启 WSL2
- Step1。管理员身份打开WindowsPowerShell,输入命令
wsl --install并回车(过程中不要开启梯子)

(图8)
- Step2。重启电脑使WSL2生效(WSL2,即Windows Subsystem for Linux 2,是微软在 Windows 10/11 上运行 Linux 环境的第二代架构)
1-3 安装Docker Desktop
- Step1。查看自己电脑的架构类型。
win+r->cmd->msinfo32,会出现图9所示的界面,系统类型显示为基于x64的电脑说明我的电脑为AMD64架构(若这里显示基于 ARM64 的电脑或基于 ARM的电脑则说明电脑为ARM64架构)

(图9)
- Step2。去Docker官网https://www.docker.com/products/docker-desktop/选择对应自己电脑架构的Docker Desktop版本下载,然后一路点OK默认完成安装。

(图10)
- Step3。Docker启动初尝试。点击桌面的Docker Desktop图标,可能会弹出一个服务条款让你点击 Accept(接受)。进去之后稍微等一下,直到你看到软件界面左下角显示绿色的 "Engine running",这就说明底层环境全部搭建完毕了。

(图11)
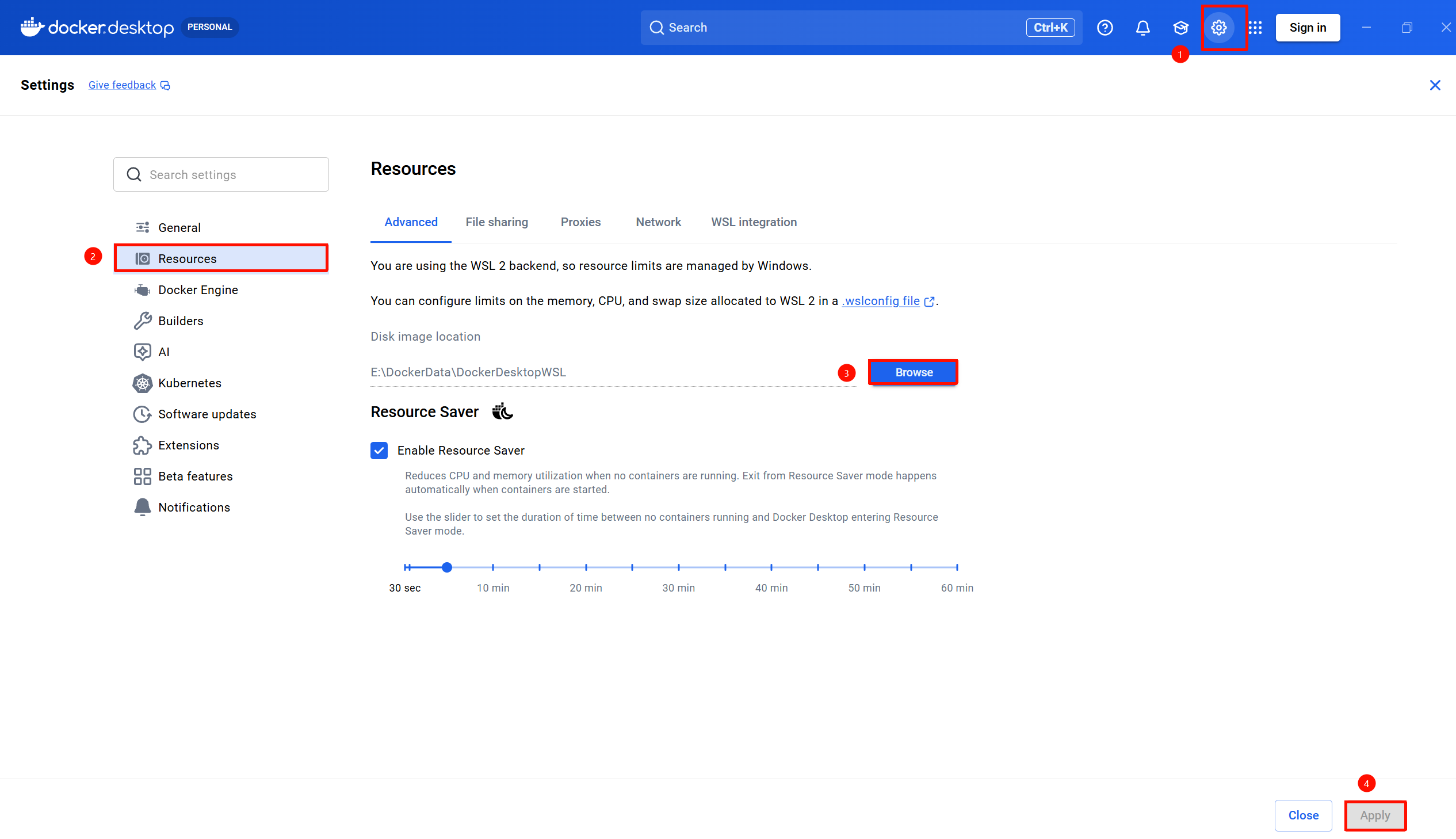
- Step4。更改Dockerd数据输出位置。"Settings" -> "Resources" -> "Browse",选择你中意的文件夹路径,然后点击"Apply""即可。(这步一定要做,我去看了一下Docker解压后的基础配置文件,分居于C:\Users\Lxf\AppData\Local\Docker和C:\Program Files\Docker下,直接干了我C盘5.5个G,后面进一步部署大模型会把全部文件放到C盘会导致C盘直接炸掉)
(图12)
阶段2:建立工作区
2-1 创建存放模型的文件夹
这一步的目的是在物理盘中建立一个干净的工作区。打开 PowerShell,按顺序运行以下命令创建文件夹:
bash
# 创建主目录
mkdir E:\PaddleDeploy
# 创建存放模型权重的目录
mkdir E:\PaddleDeploy\models
# 创建存放版面分析代码的目录
mkdir E:\PaddleDeploy\layout_service2-2 下载模型
由于我本地Base环境中已经安装了Python,因此直接使用pip install指令将PaddleOCR-VL-1.5的权重下载到本地即可,但正式下载前需要先做一下网络配置以确保Powershell终端能正常使用上网络代理。
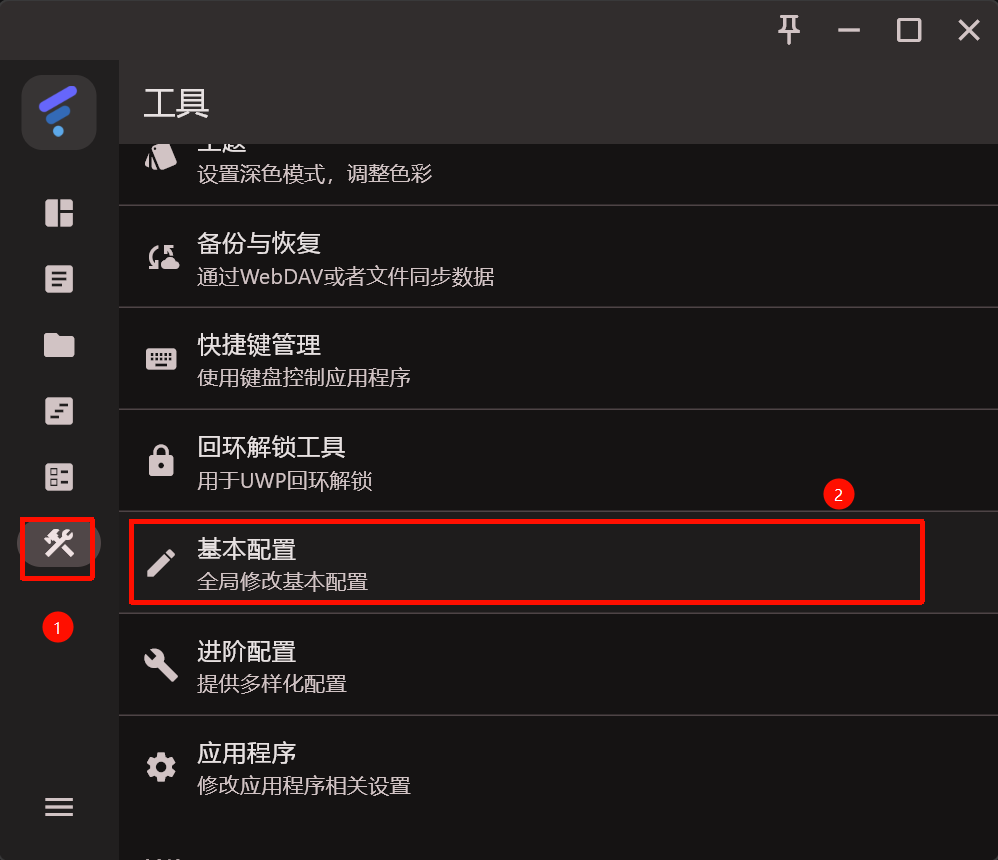
- Step1。开启网络代理软件、查看HTTP本地代理端口。"Settings" -> "基本配置" ,下拉列表中找到"端口",可知我的端口为7890(我使用的软件是FIClash,其他网络代理的设置步骤也都大同小异)

(图13-图14)
- Step2。PowerShell中手动指派本地代理。分别输入以下两句指令并回车即可
bash
$env:HTTP_PROXY="http://127.0.0.1:7890"
$env:HTTPS_PROXY="http://127.0.0.1:7890"- Step3。下载模型到本地
直接在PowerShell中使用下面的指令并回车。(下载过程将持续一段时间,因为大概有4GB,下载过程中请打开梯子以确保能稳定访问到Huggingface官网)
bash
pip install -U "huggingface_hub[cli]"
huggingface-cli download PaddlePaddle/PaddleOCR-VL --local-dir E:\PaddleDeploy\models\PaddleOCR-VL阶段3:编写配置文件
在这个阶段将创建3个配置文件,可以用任意的文本编辑器(记事本、VScode、Notepad++等)来创建它们,建议使用Visual Studio Code来写,可支持文件类型更多而且还支持无扩展名文件,保存文件时记得编码格式要调整为UTF-8。
3-1 配置文件docker-compose.yml
创建文件docker-compose.yml,存放于路径E:\PaddleDeploy下,文件的源码放在下面的代码框中。
bash
version: '3.8'
services:
# 服务 1: 视觉大模型 (vLLM)
vlm-service:
image: vllm/vllm-openai:latest
container_name: ocr_vlm_node
ipc: host
ports:
- "8000:8000"
volumes:
# 将 Windows 下的模型目录映射到容器内的 /models
- ./models:/models
command: >
--model /models/PaddleOCR-VL
--trust-remote-code
--max-model-len 4096
--enforce-eager
--gpu-memory-utilization 0.4
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
# 服务 2: 版面分析 (PaddlePaddle)
layout-service:
build:
context: ./layout_service
dockerfile: Dockerfile
container_name: ocr_layout_node
ports:
- "8001:8001"
volumes:
- ./models:/models
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]3-2 配置文件Dockerfile
创建文件Dockerfile(注意没有后缀名,可参考图15),存放于路径E:\PaddleDeploy\layout_service下,文件的源码放在下面的代码框中。
bash
FROM paddlepaddle/paddle:latest-gpu-cuda11.8-cudnn8.6-trt8.5
RUN pip install --no-cache-dir paddleocr fastapi uvicorn python-multipart
COPY layout_api.py /app/layout_api.py
WORKDIR /app
CMD ["uvicorn", "layout_api:app", "--host", "0.0.0.0", "--port", "8001"]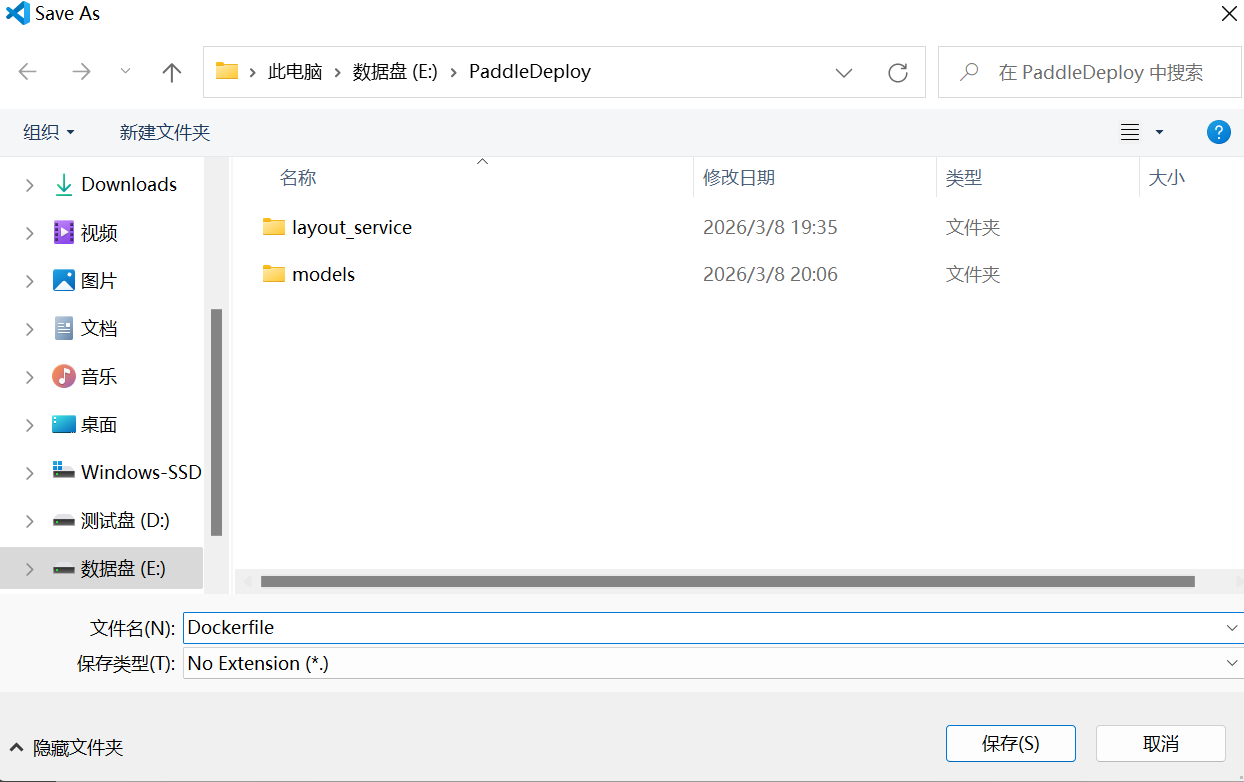
(图15)
3-3 版面分析接口文件layout_api.py
创建文件layout_api.py,将其存放于路径E:\PaddleDeploy\layout_service,文件源码存放于下面的代码块中。
python
from fastapi import FastAPI, UploadFile, File
from paddleocr import PPStructure
import cv2
import numpy as np
app = FastAPI()
# 初始化版面分析
layout_engine = PPStructure(show_log=True, image_dir=None)
@app.post("/analyze_layout")
async def analyze_layout(file: UploadFile = File(...)):
contents = await file.read()
nparr = np.frombuffer(contents, np.uint8)
img = cv2.imdecode(nparr, cv2.IMREAD_COLOR)
result = layout_engine(img)
regions = []
for region in result:
regions.append({
"type": region['type'],
"bbox": region['bbox']
})
return {"status": "success", "regions": regions}阶段4:一键启动与验证
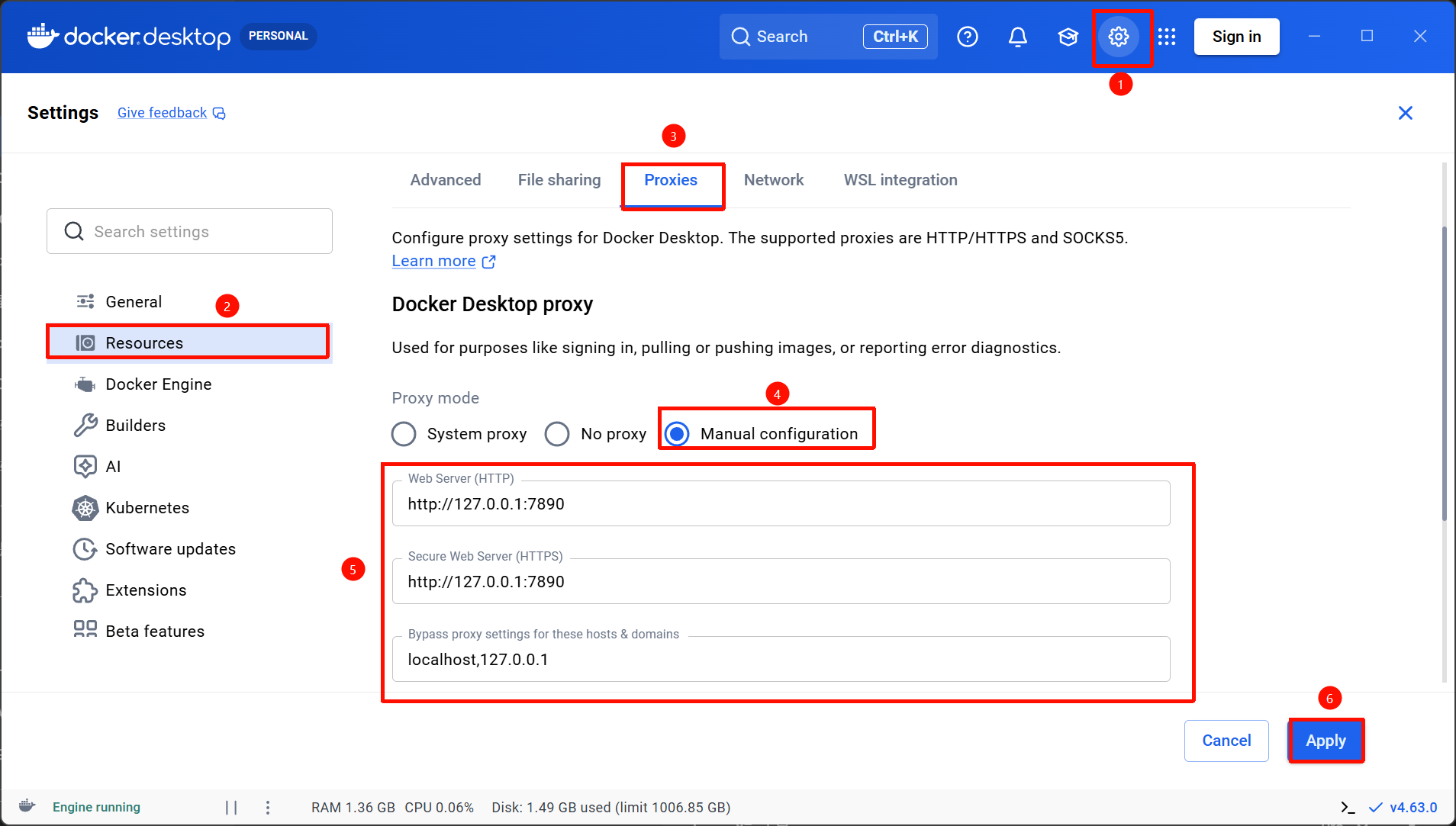
- Step1。为Docker配置网络代理。由于在前面的环节我已经确定自己本地代理的端口为7890,因此这里直接进入Docker Desktop中进行配置即可。
Settings->Resources->Proxies->Manual configuration,在 Web Server (HTTP) 和 Secure Web Server (HTTPS) 框中输入http://127.0.0.1:7890,在Bypass proxy settings for these hosts & domains 框中输入localhost,127.0.0.1,然后点击Apply & restart
(图16)
- Step2。在PowrShell中输入指令
cd E:\PaddleDeploy,切换到工作目录。 - Step3。执行一键启动命令。(经过一段漫长的等待,等Docker 从网上下载 vLLM 和 PaddlePaddle 的基础环境镜像,大约60个GB,过程中可能出现CPU占用率100%、风扇狂响,等到出现图17的画面,就说明安装成功了!)
bash
docker-compose up -d --build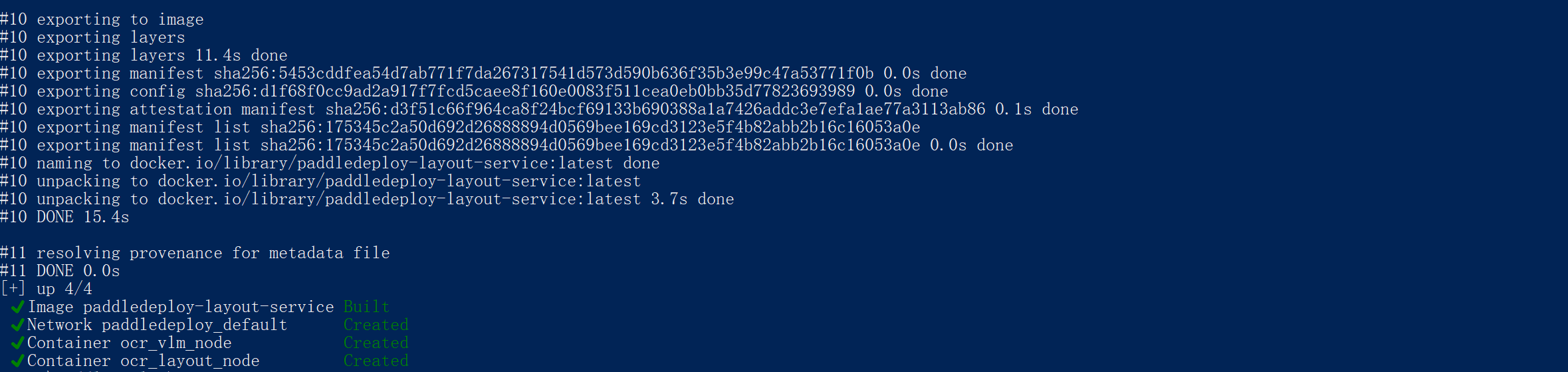
(图17)
续更~
Step3中的安装过程可能的问题说明:
- 问题1。出现图18所示的unexpected EOF报错问题,原因是网络波动导致下载中途停止,这时候不用慌,调整一下网络然后在PowerShell中输入指令
docker-compose up -d --build继续下载就行。

(图18)
- 问题2。大模型安装包下载完成,却在结尾报错"docker.io/paddlepaddle/paddle... not found"(如图19所示),这说明Docker 在官方仓库里找不到 latest-gpu-cuda11.8-cudnn8.6-trt8.5 这个确切的名字,这个问题出现概率很大,因为官方镜像库里的标签命名规则经常变动导致原来的名字失效。此时,你只需要
把报错代码喂给AI(如图20所示),让他去找现在对应最新的镜像库来修改一下配置文件即可。
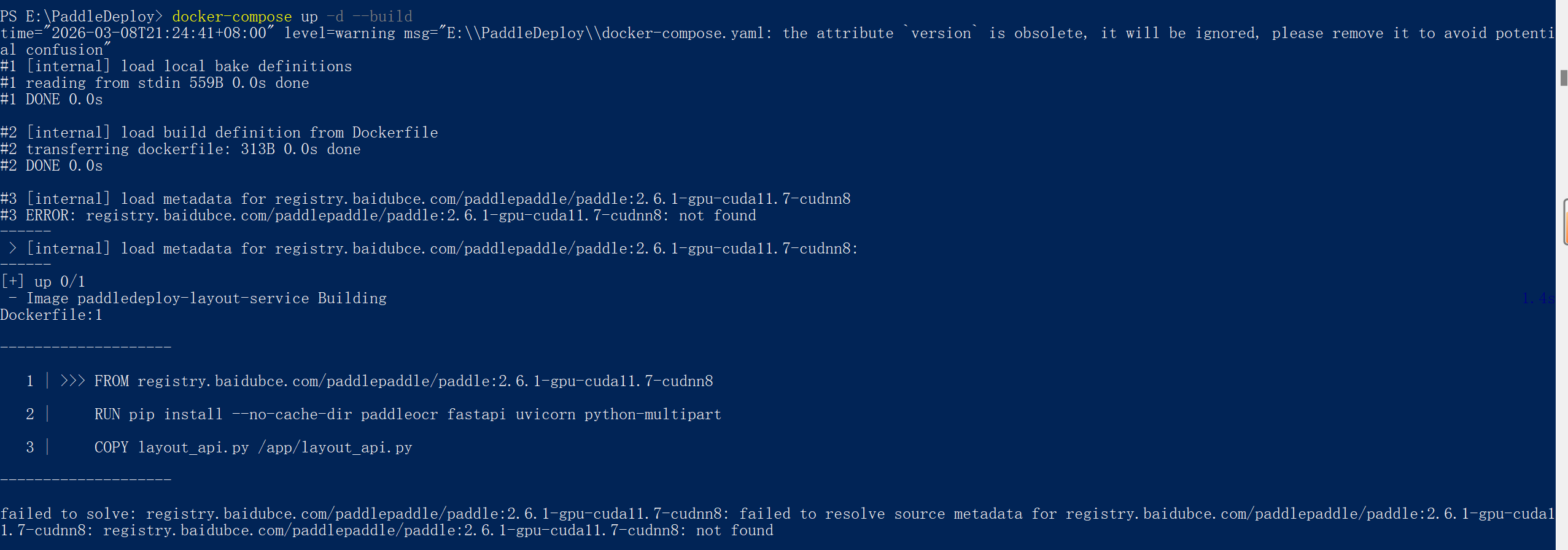
(图19)
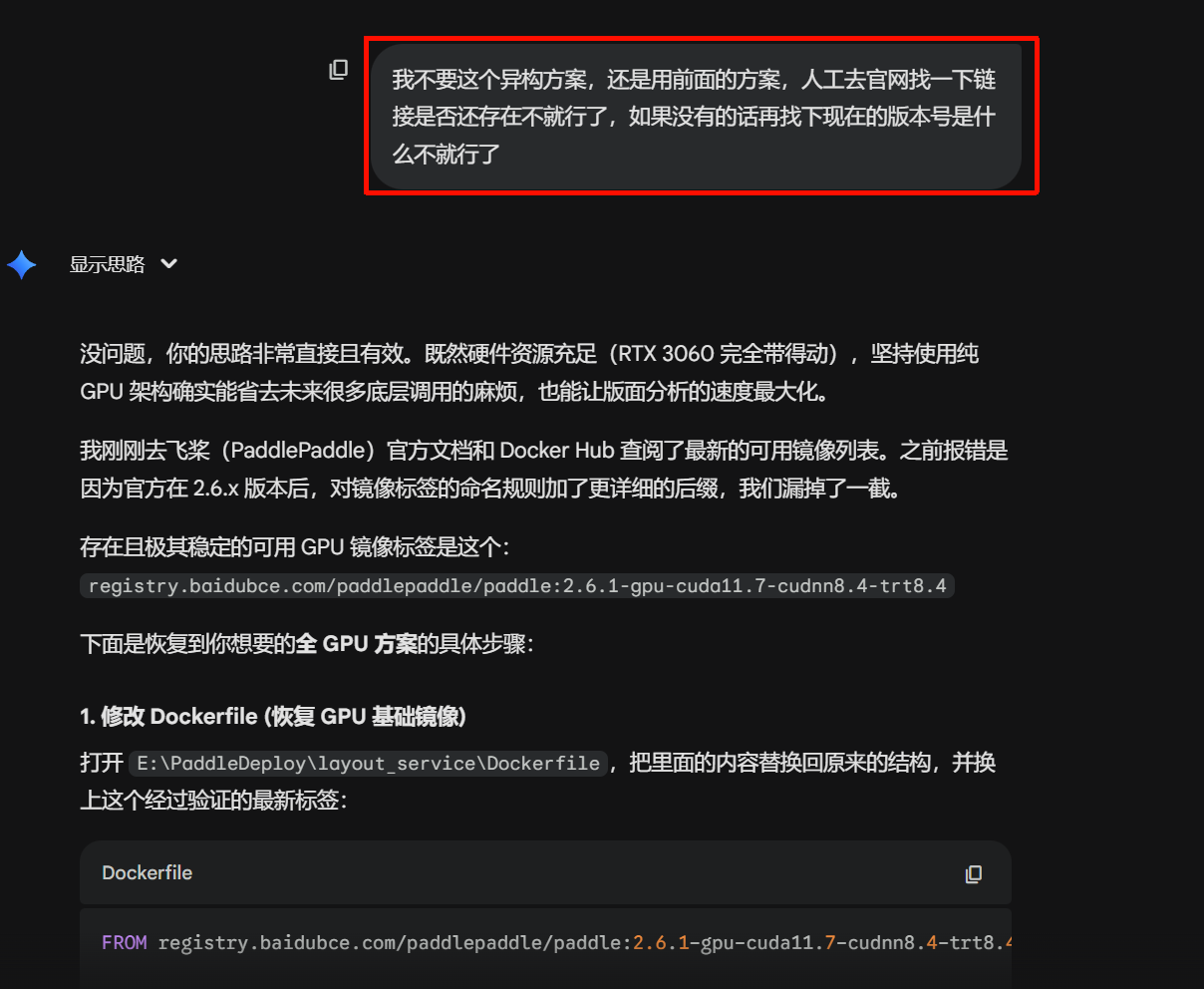
(图20)
对于我前面的配置文件,AI给出的修改有2处,一是文件Dockerfile,二是文件docker-compose.yml,分别对应下面这两个代码块。修改完以后继续在PowerShell中使用指令docker-compose up -d --build,最终得到了图17的成功安装画面!
bash
FROM registry.baidubce.com/paddlepaddle/paddle:2.6.1-gpu-cuda11.7-cudnn8.4-trt8.4
# 使用清华源加速安装
RUN pip install --no-cache-dir paddleocr fastapi uvicorn python-multipart -i https://pypi.tuna.tsinghua.edu.cn/simple
COPY layout_api.py /app/layout_api.py
WORKDIR /app
CMD ["uvicorn", "layout_api:app", "--host", "0.0.0.0", "--port", "8001"]
bash
# 服务 2: 版面分析服务 (使用 PaddlePaddle GPU)
layout-service:
build:
context: ./layout_service
dockerfile: Dockerfile
container_name: ocr_layout_node
ports:
- "8001:8001"
volumes:
- ./models:/models
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]- 问题3-问题n。PaddleOCR-VL-1.5部署完成后,我拿他做了本地测试(写一个test_ocr.py文件来识别本地图片),没想到各种出现了各种设置问题,图21是我让AI帮我总结的部分问题,过程中改了很多次Dockerfile、docker-compose.yml、test_ocr.py,我将最新版的配置文件以及我的测试py文件放到下面,有需自取。

(图21)
文件1- Docker
bash
FROM registry.baidubce.com/paddlepaddle/paddle:2.6.1-gpu-cuda11.7-cudnn8.4-trt8.4
# 1. 修复底层环境:安装 OpenCV 强依赖的系统级动态链接库
RUN apt-get update && apt-get install -y libgl1 libglib2.0-0 && rm -rf /var/lib/apt/lists/*
# 2. 安装 Python 库:严格锁死 paddleocr==2.8.1 经典稳定版,避免 3.x 版本 API 报错
RUN pip install --no-cache-dir "paddleocr==2.8.1" fastapi uvicorn python-multipart -i https://pypi.tuna.tsinghua.edu.cn/simple
COPY layout_api.py /app/layout_api.py
WORKDIR /app
# 启动 FastAPI 服务
CMD ["uvicorn", "layout_api:app", "--host", "0.0.0.0", "--port", "8001"]文件2- docker-compose.yml
bash
services:
# 服务 1: 视觉大模型 (vLLM)
vlm-service:
image: vllm/vllm-openai:latest
container_name: ocr_vlm_node
ipc: host
ports:
- "8000:8000"
volumes:
- ./models:/models
environment:
# 解决 Windows WSL2 环境下的 PyTorch 多进程崩溃问题
- VLLM_WORKER_MULTIPROC_METHOD=spawn
- VLLM_USE_V1=0
command: >
--model /models/PaddleOCR-VL
--trust-remote-code
--max-model-len 4096
--enforce-eager
--gpu-memory-utilization 0.5
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
# 服务 2: 版面分析服务
layout-service:
build:
context: ./layout_service
dockerfile: Dockerfile
container_name: ocr_layout_node
ports:
- "8001:8001"
volumes:
- ./models:/models
environment:
# 限制 Paddle 显存占用
- FLAGS_fraction_of_gpu_memory_to_use=0.1
- FLAGS_allocator_strategy=naive_best_fit
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]文件3- layout_api.py
bash
from fastapi import FastAPI, UploadFile, File
from paddleocr import PPStructure
import cv2
import numpy as np
app = FastAPI()
# 初始化版面分析
layout_engine = PPStructure(show_log=True, image_dir=None)
@app.post("/analyze_layout")
async def analyze_layout(file: UploadFile = File(...)):
contents = await file.read()
nparr = np.frombuffer(contents, np.uint8)
img = cv2.imdecode(nparr, cv2.IMREAD_COLOR)
result = layout_engine(img)
regions = []
for region in result:
regions.append({
"type": region['type'],
"bbox": region['bbox']
})
return {"status": "success", "regions": regions}文件4- test_ocr.py
bash
import requests
import cv2
import base64
import sys
# ====== 配置区 ======
IMAGE_PATH = "test.png"
LAYOUT_URL = "http://localhost:8001/analyze_layout"
VLM_URL = "http://localhost:8000/v1/chat/completions"
# ====================
def main():
print(f"👀 1. 正在读取图片: {IMAGE_PATH}")
img = cv2.imread(IMAGE_PATH)
if img is None:
print("❌ 找不到图片,请检查图片路径和名称是否正确!")
sys.exit(1)
print("🚀 2. 正在请求版面分析服务 (Port 8001)...")
proxies = {"http": None, "https": None}
with open(IMAGE_PATH, "rb") as f:
try:
res_layout = requests.post(LAYOUT_URL, files={"file": f}, proxies=proxies)
if res_layout.status_code != 200:
print(f"❌ 8001 返回错误!状态码: {res_layout.status_code}, 内容: {res_layout.text}")
sys.exit(1)
layout_data = res_layout.json()
except Exception as e:
print(f"❌ 版面分析失败: {e}")
sys.exit(1)
regions = layout_data.get("regions", [])
print(f"✅ 版面分析完成,发现 {len(regions)} 个目标区域。")
if not regions:
regions = [{"bbox": [0, 0, img.shape[1], img.shape[0]], "type": "Text"}]
print("🧠 3. 开始调用 0.9B 大模型进行高精度识别 (Port 8000)...")
for idx, region in enumerate(regions):
x1, y1, x2, y2 = region["bbox"]
region_type = region["type"]
crop_img = img[int(y1):int(y2), int(x1):int(x2)]
# 【核心改进 1】:动态压缩长边,防止视觉 Token 超出 vLLM 的 3600 预算
max_size = 960 # 锁定长边最大 960 像素
h, w = crop_img.shape[:2]
if max(h, w) > max_size:
scale = max_size / max(h, w)
crop_img = cv2.resize(crop_img, (int(w * scale), int(h * scale)))
# 【核心改进 2】:使用 85 质量的 JPEG 编码,把 Base64 体积缩小 70% 以上
_, buffer = cv2.imencode('.jpg', crop_img, [int(cv2.IMWRITE_JPEG_QUALITY), 85])
img_base64 = base64.b64encode(buffer).decode('utf-8')
prompt = "请精准识别这张图中的所有文字。"
if region_type == "Table":
prompt = "请识别图中的表格,并以 Markdown 格式严格输出。"
payload = {
"model": "/models/PaddleOCR-VL",
"messages": [
{
"role": "user",
"content": [
{"type": "text", "text": prompt},
{"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{img_base64}"}}
]
}
],
"temperature": 0.0
}
print(f" -> 正在识别第 {idx + 1} 个区域 [{region_type}],请稍候...", end="", flush=True)
try:
# 【核心改进 3】:加入 timeout=120,允许大模型在第一次加载图片时有充足的预热时间
res_vlm = requests.post(VLM_URL, json=payload, proxies=proxies, timeout=120)
if res_vlm.status_code != 200:
print(f" ❌ 8000 返回错误!状态码: {res_vlm.status_code}, 内容: {res_vlm.text}")
continue
text = res_vlm.json()["choices"][0]["message"]["content"]
print(" 完成!")
print(f"\n【识别结果】:\n{text}\n" + "-" * 40)
except requests.exceptions.Timeout:
print(" ❌ 识别超时,初次加载较慢,请再运行一次重试!")
except Exception as e:
print(f" ❌ 识别失败: {e}")
if __name__ == "__main__":
main()下面,以一张成功OCR的图收尾,纪念我做了一晚上的工作~

后面每次需要使用OCR服务时,直接打开Docker Desktop的启动面板,然后在PowerShell中运行py脚本执行识别任务即可~
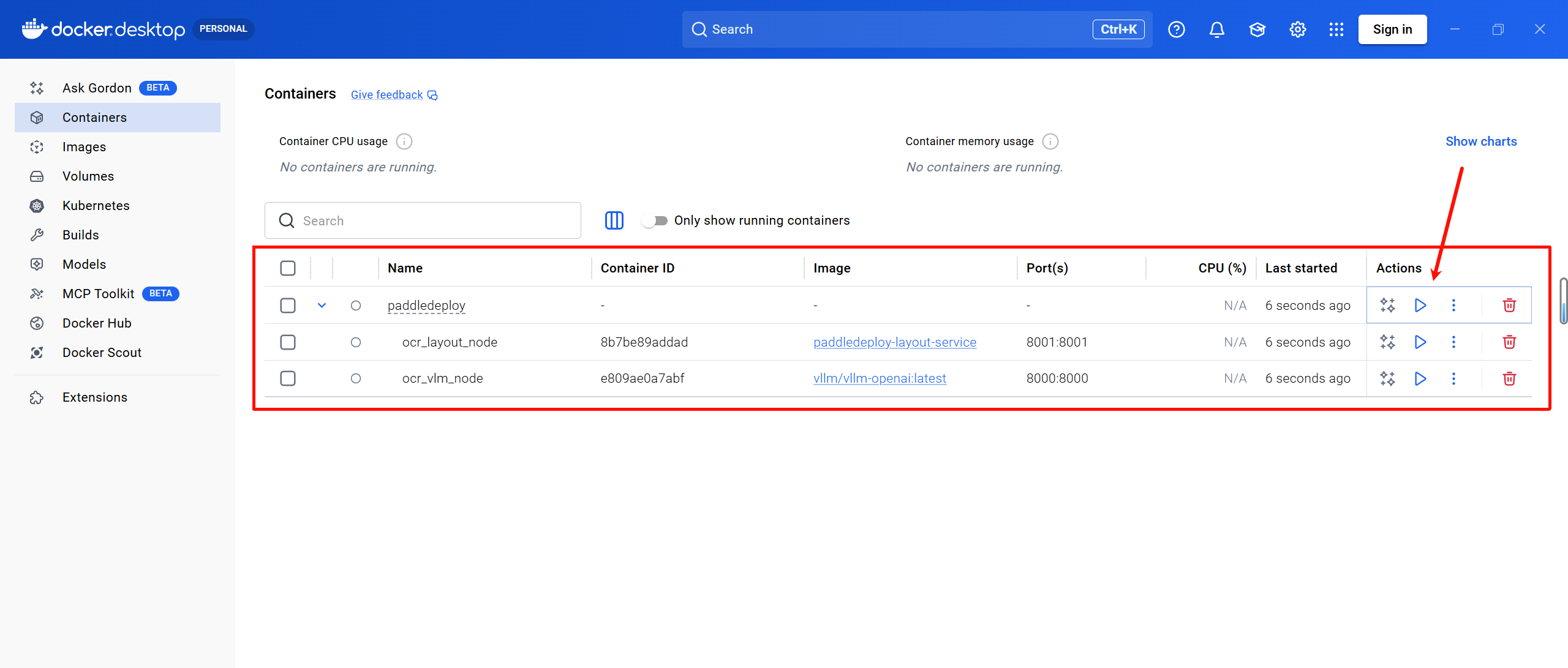
flag is all you need !!!