一:大模型对话之基 - Token
- 什么是Token?
- Token是怎么生成的?
- Token和字或者词到底是什么关系?
Token是模型处理自然语言的最小语义单元。每个大模型语言一个上下文窗口都有对应的上下文长度。
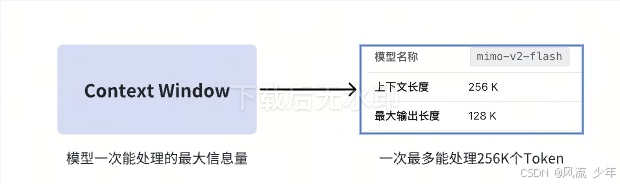
1.1 大模型的基本工作原理
大模型本质是一个巨大的"数学函数",内部全是矩阵运算,输入是数字(35,36,34,10),输出也是"数字"(36),根本不理解人类的文字。
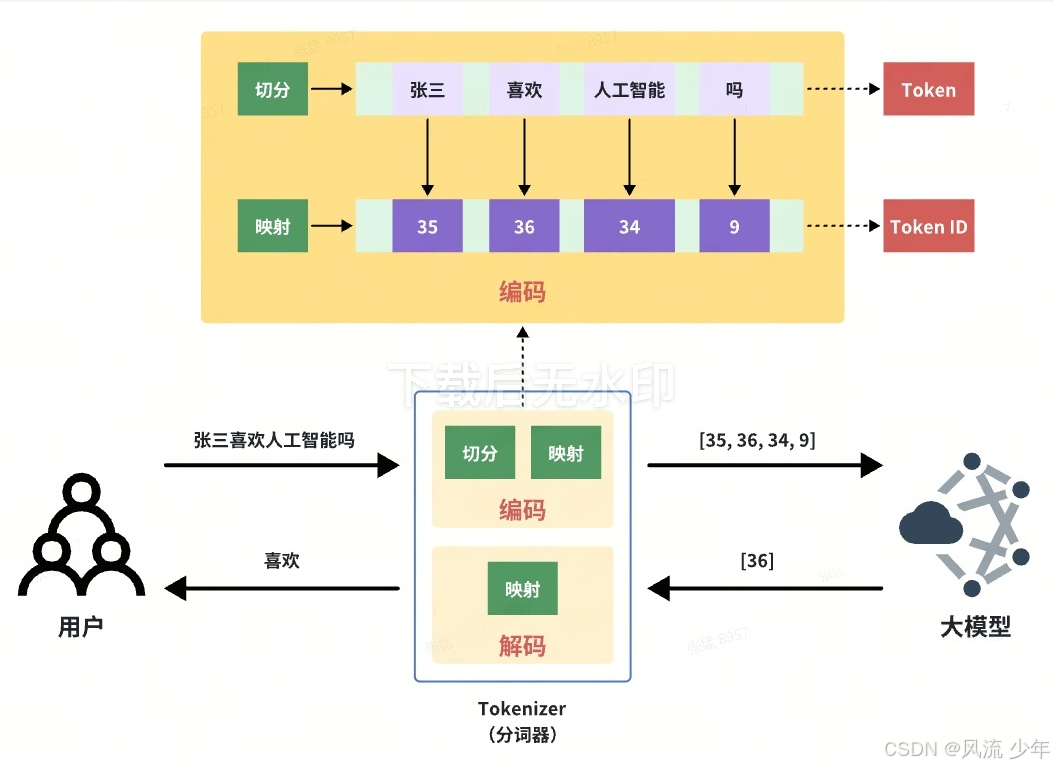
1.2 翻译官-Tokenizer
分词器负责"编码"和"解码"两个环节:
- 编码:文字->数字
- 解码:数字->文字
关键操作:
- 切分:将一个句子分成独立的词语。
- 映射:将每个词语对应一个数字ID。
1.3 Tokenizer的训练过程
Tokenizer是被训练出来的,业界目前有很多训练Tokenizer的算法,如:Unigram(元分词)- Google、BPE(字节对编码)- Open AI、Anthropic,以BPE为例,演示Tokenizer的训练流程。
BPE算法2016 年被 Rico Sennrich 等人引入 NLP 领域用于分词,核心是通过迭代合并高频相邻符号对构建子词表,在字符级细粒度与词级语义效率间取得平衡,能有效处理未登录词并控制词表大小,原理:经常一起出现的字------>Token。
训练材料:文章,产出:训练材料--->词表+合并规则。
张 三 喜 欢 人 工 智 能 吗
人 工 智 能 很 智 能
人 工 智 能 比 人 工 更 智 能
张 三 喜 欢 智 能
初始词表:记录Token 与 Token ID对应关系的表格,单字词表(Token与Token ID是一一对应的关系,Token ID无实际含义,只是个编号,没有特殊的语义在里面)
| Token | Token ID |
|---|---|
| 张 | 1 |
| 三 | 2 |
| 喜 | 3 |
| 欢 | 4 |
| ... | N |
问题切分为Token,问题:张三喜欢人工智能吗
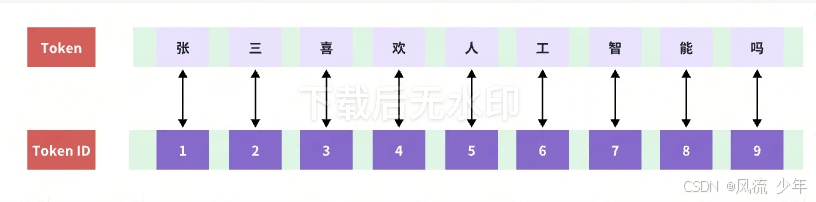
这种方式一个字就对应一个Token,缺陷效率低。
理想情况:将模型的输入从9个减少至4个,模型的推理速度也会更快。
找规律构建"高级"词表:算法扫描:智能x5、人工x4、人工智能x3、张三x2、喜欢x2

至此:Tokenizer训练完毕。
1.4 Tokenize的使用过程
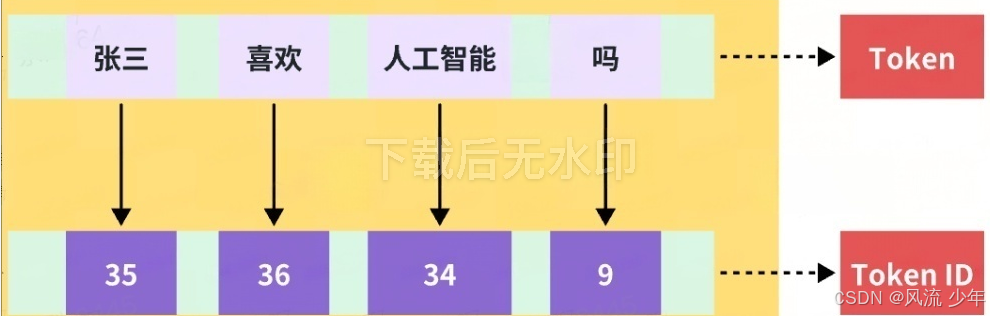
回到最初问题:"张三喜欢人工智能吗"
编码:根据合并规则切分结果
- 切分:张三 喜欢 人工智能 吗
- 映射:35 36 34 9
解码:模型输出 36
- 映射:36------>喜欢
1.5 Token与字数的换算关系
- 256K Token 不等于 256K字/词。
- 大致换算关系:一个token = 1.5 ~2 个汉字 or 4个英文字母或0.75个英文单词
Tokenizer不仅是一个翻译机,还是一个压缩机,将高频出现的字合并成一个Token,可以使得模型输入更少,提高模型训练和推理的效率。
二:大模型对话之度 - Temperature(采样温度)和Top-p(采样概率)
控制大模型回答的随机性和创造性。
- 高 ------> 随机、有创造力
- 低 ------> 确定、偏向保守
试想一下:
- 问题一:为什么需要两个参数?
- 问题二:如果把一个调高,一个调低,结果会中和吗?
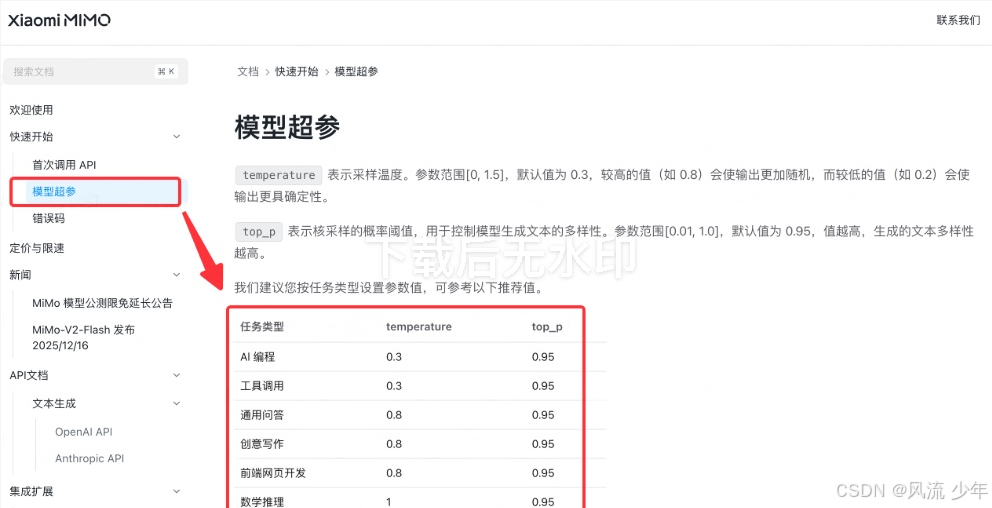
大模型是如何回答问题的?
虽然大模型的内部结构无比复杂,但是它执行的核心任务其实非常朴素,那就是"预测下一个最有可能出现的词"
2.1 预测过程拆解
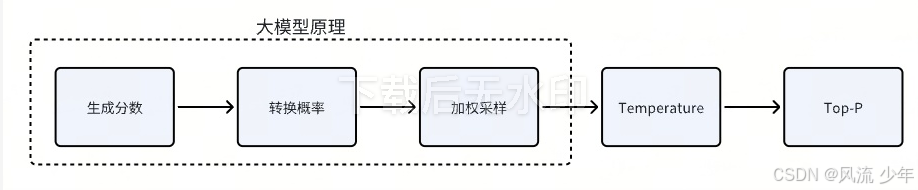
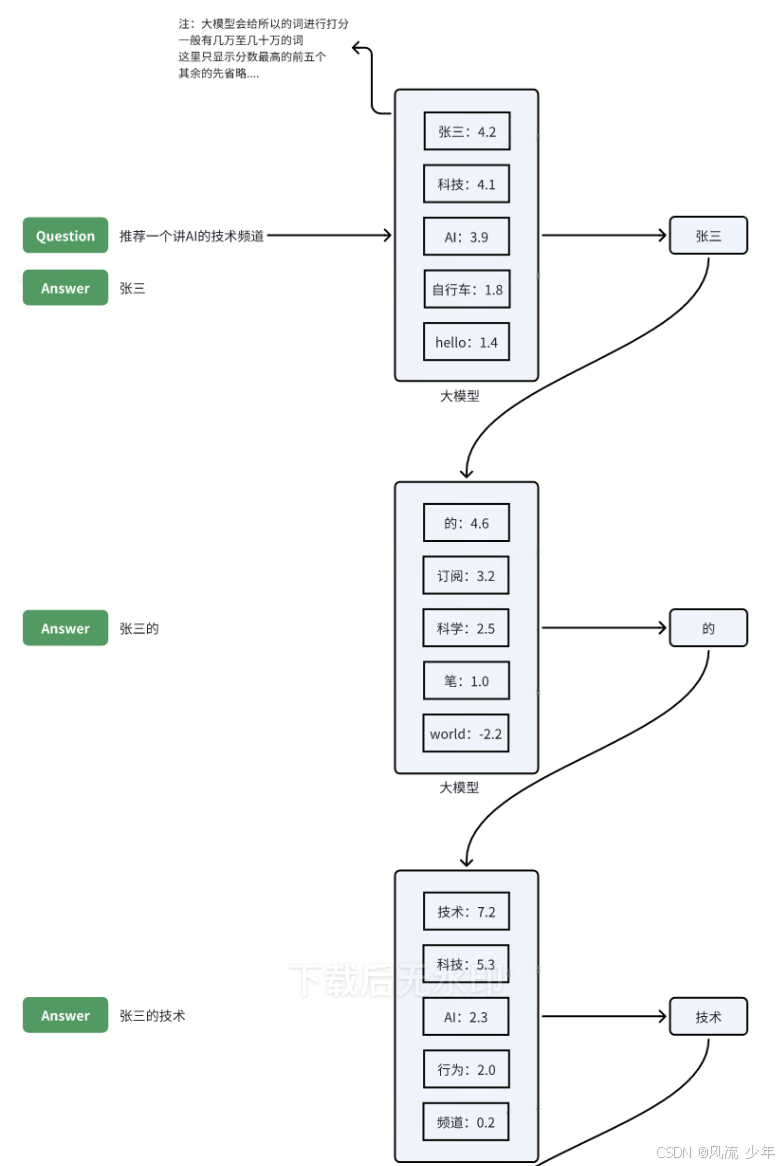
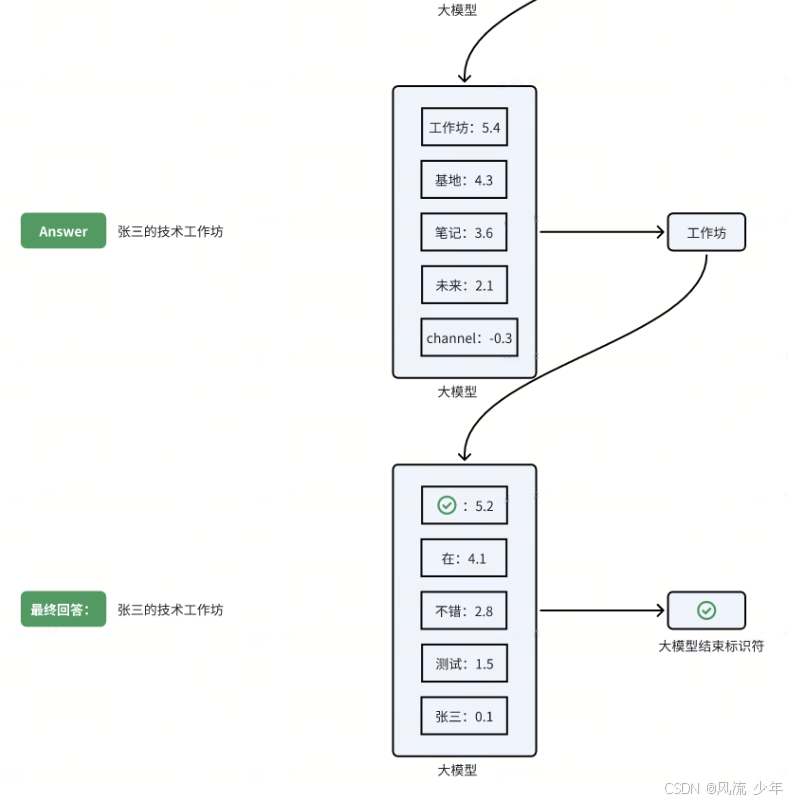
转换概率
Softmax函数
S o f t m a x ( z i ) = e z i ∑ j = 1 K e z j = e z i e z 1 + e z 2 + e z 3 + e z 4 + e z 5 Softmax(z_i) = \frac{e^{z_i}}{\sum_{j=1}^K e^{z_j}} = \frac{e^{z_i}}{e^{z_1} + e^{z_2} + e^{z_3} + e^{z_4} + e^{z_5}} Softmax(zi)=∑j=1Kezjezi=ez1+ez2+ez3+ez4+ez5ezi
- z i z_i zi: 第 i 个词的分数
- K K K:词的总量
- S o f t m a x ( z i ) Softmax(z_i) Softmax(zi):第i个词的输出概率
实际案例运用

加权采样
通过概率来生成预测词的过程
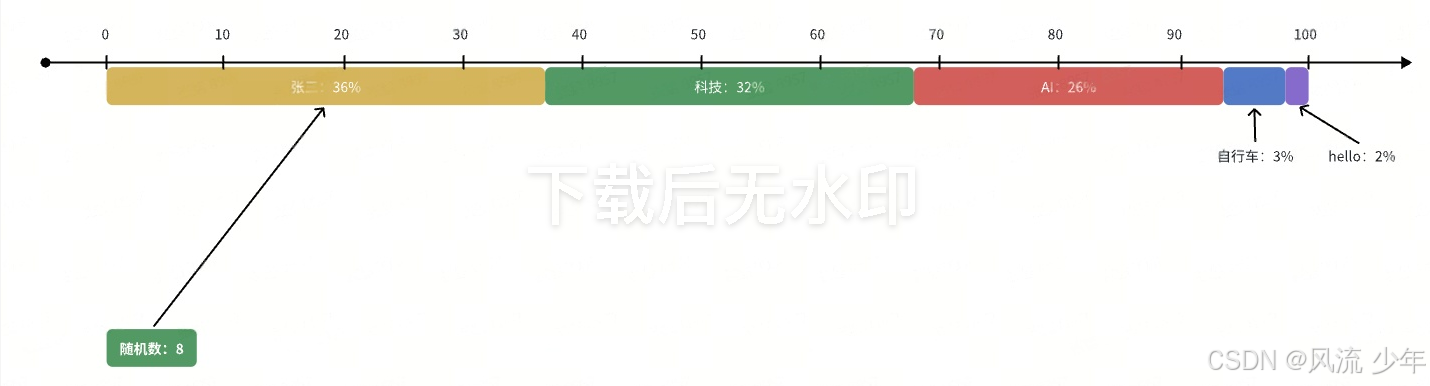
2.2 Temperature(采样温度)
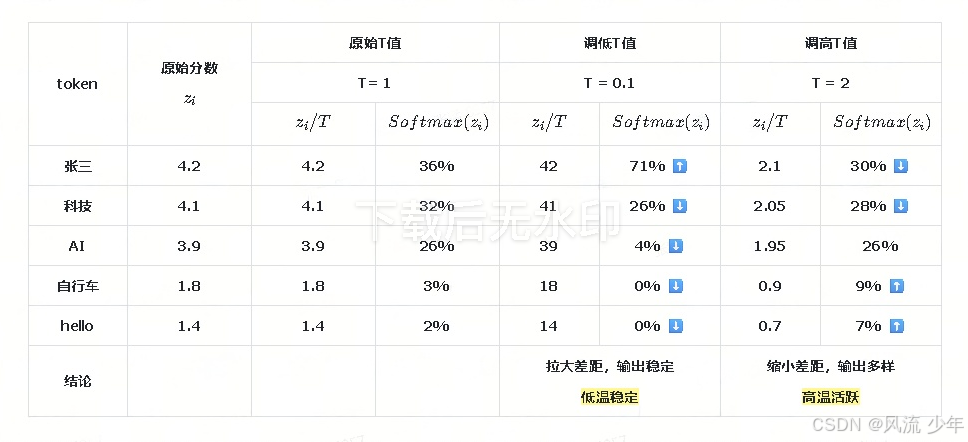
Softmax函数完整版本:其中T就是"Temperature",只不过最开始设置成了 T=1 ;T的作用:改变不同词的概率差距
Softmax ( z i ) = e z i ∑ j = 1 K e z j ⟶ 完整版本 Softmax ( z i ) = e z i / T ∑ j = 1 K e z j / T \text{Softmax}(z_i) = \frac{e^{z_i}}{\sum_{j=1}^K e^{z_j}} \quad\stackrel{\text{完整版本}}{\longrightarrow} \quad\text{Softmax}(z_i) = \frac{e^{z_i/T}}{\sum_{j=1}^K e^{z_j/T}} Softmax(zi)=∑j=1Kezjezi⟶完整版本Softmax(zi)=∑j=1Kezj/Tezi/T
2.3 Top-p(采样概率)
在加权采样时,上面根据每一个词的分数,给它们分配了对等的区间,然后生成一个随机数,来确认预测词。
隐患:虽然"自行车"和"hello"只有很小的概率,但是理论上试的次数足够多,或者运气足够好,大模型最后还是有可能输出这两个词;最终可能获得回答:"自行车的维修和保养"?
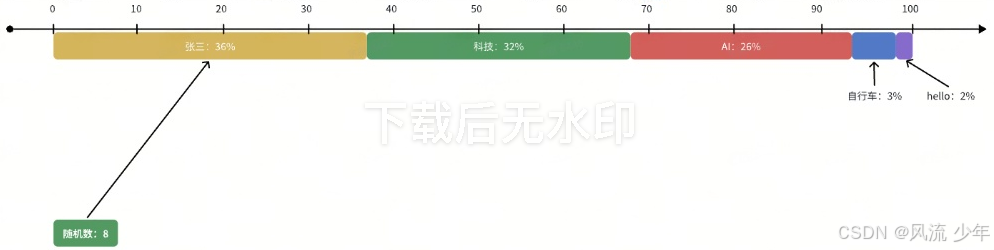
长尾词
大模型的词汇表里有几十万个词,每次回答问题,除了头部的几个合理词,后面基本上都是拖着长长的一串低概率的垃圾词------长尾词;而在上面的例子中"自行车"和"hello"就是与用户毫无关系的长尾垃圾词。
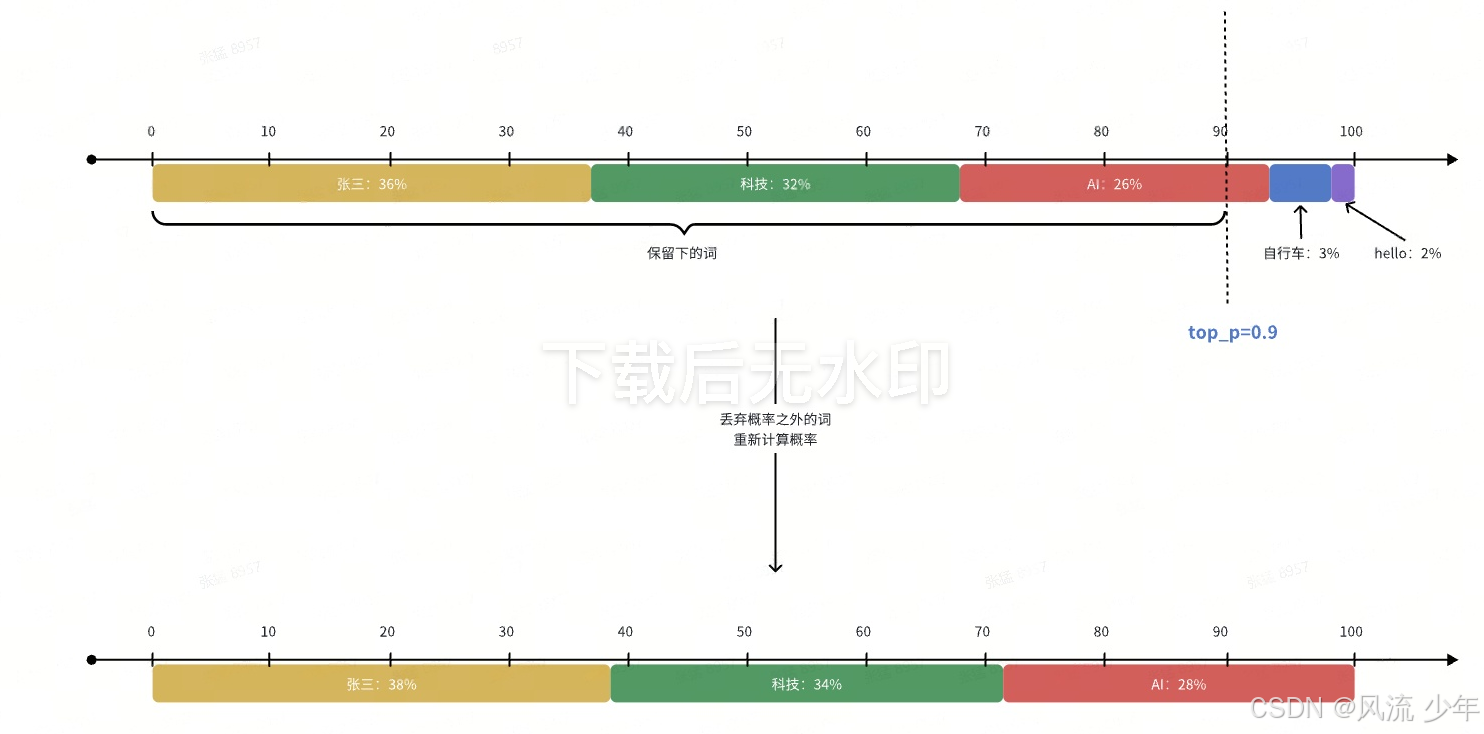
防止模型去选择长尾词,需要一个保安,将这些离谱的选项都拦在门外------Top-p(Top Cumulative Probability):最高累加概率;其中p就是指的一个概率阈值。
Top-p相当于一个动态的入门门槛,主要用来切断尾部的那些不靠谱的长尾词,保证回答不跑题。
2.4 总结
Temperature:控制不同词的概率差距
- 调低:拉大差距,输出稳定
- 调高:缩小差距,输出多样
Top-p:控制长尾词的概率阈值
- 调低:去掉长尾,输出稳定
- 调高:放宽门槛,输出多样
越大越多样------写小说,头脑风暴
越小越稳定------写代码,做数学题
三:大模型对话之钥:提示词工程(Prompt Engineering)
3.1 如何应用和激发大预言模型的能力
三种关键方法与应用
- 提示词工程(Prompt Engineering): 通过精心设计的提示语,引导模型按照我们的意图生成内容或完成任务。
- 微调(Fine Tuning): 在预训练模型的基础上,使用特定领域的数据进行训练,使模型在特定任务上表现更好。
- 构建智能机器人代理(Agent):以大语言模型为大脑驱动的系统,具备自主理解、感知、规划、记忆和使用工具的能力,能够自动化执行完成复杂任务的系统。
3.2 提示词工程简介
定义
- 提示词工程(Prompt Engineering)就是一门关于如何构造和精炼你的提示词的艺术和科学,目的是最大化 AI 模型的性能,让它产出更符合你需求的、高质量的输出。
- 在人工智能,特别是大语言模型(如 ChatGPT、Claude、DeepSeek)的时代,提示词工程已经成为一项至关重要的技能,它不再是简单的输入问题,而是一种与 AI 高效协作、精准激发其潜能的新型编程。
- 提示词工程就像是你在和人工智能(AI)聊天或下指令时,学习如何更好地提问和表达,从而让 AI 更准确、更有效地给出你想要的答案或结果。
为什么学习提示词工程
- 提高准确性:不好的提示词可能导致 AI 给出错误、跑题或无用的回答。好的提示词能让 AI 直击核心。
- 节省时间:通过一次到位的指令,减少你和 AI 之间的来回修改和尝试。
- 解锁能力:有些复杂的任务,如总结长文、扮演特定角色、或进行复杂的推理,需要特殊的提示词技巧才能激发 AI 的潜力。
提示词对比
优化前:
- 模糊的指令:"写一篇关于猫的文章。"
- 结果:生成一篇泛泛而谈、没有重点的文章。

使用提示词工程优化后: - 经过工程化的指令:你是一位宠物科普作家。请以轻松幽默的口吻,为养猫新手写一篇 200 字左右的文章,重点介绍如何选择第一只猫和接猫回家前三天的必备准备。文章需要包含三个小标题,并在结尾给出一个简洁的 checklist。
- 结果:回答更具针对性、结构清晰,且符合具体需求。

3.4 提示词工程的关键要素与基础技巧
一个有效的提示词通常包含以下几个要素(并非唯一标准,但很有帮助)
# 提示词要素说明| 要素 | 英文 | 说明 | 示例 |
|---|---|---|---|
| 角色与背景 | Capacity & Role | 为 AI 设定一个身份或场景,引导其使用特定的知识体系和表达方式。 | "你是一位经验丰富的 Python 编程导师。" |
| 任务与指令 | Insight & Statement | 清晰、具体地说明你要 AI 完成什么任务。这是提示词的核心。 | "请解释 列表推导式 的概念,并给出三个由易到难的例子。" |
| 步骤与约束 | Procedure & Steps | 将复杂任务分解为步骤,或添加格式、长度、风格等限制条件。 | "请按以下步骤回答:1. 一句话定义。2. 语法说明。3. 示例代码及注释。" |
| 输出格式 | Format & Output | 明确指定你希望的回答格式,如 JSON、Markdown、表格、代码块等。 | "请将对比结果以表格形式呈现,包含'方法'、'优点'、'缺点'三列。" |
| 输入示例 | Examples | 提供一两个输入-输出的例子,让 AI 更准确地模仿你想要的模式(少样本学习)。 | "例如,如果我问'苹果',你应该回答'它是一种水果'。那么,当我问'香蕉'时..." |
基础技巧实践
场景:让 AI 生成产品特点描述。
-
基础版(效果一般):
写一下我们这个新款"HydraTech 智能保温杯"的特点。

- 优化版(应用提示词工程):
javascript
# 角色
你是一位顶尖的电子产品营销文案写手。
# 任务
为我公司的新款"HydraTech 智能保温杯"撰写一段吸引人的产品特点描述。
# 约束
描述需面向都市白领群体,突出"健康提醒"、"长效保温"、"设计简约"三大核心卖点,语言简洁有力,充满科技感。
# 格式
最终输出为一段不超过 150 字的文案,并额外用 - 列出三个最突出的技术参数。
显然,优化后的提示词能引导 AI 生成更符合商业用途的高质量文案。
提示词工程的核心就是:像教一个新员工一样,清晰、完整、有结构地给出指令。
记住四要素:角色、指令、背景、限制。
提示词工程的核心原则
- 明确的角色定位(Personal)
让 AI 扮演一个特定的"专家"或"角色"。这能帮助 AI 调整它的语气、知识范围和输出格式。
| 元素 | 示例 | 作用 |
|---|---|---|
| 角色 | "你是一位资深的历史学家。" | 确保回答专业、严谨。 |
| 角色 | "你是一位幽默的朋友。" | 确保回答轻松、口语化。 |
- 清晰的任务指令(Task/Goal)
准确地告诉 AI 你想让它做什么。使用动词和明确的结果要求。
| 元素 | 示例 | 作用 |
|---|---|---|
| 指令 | "总结以下文章的三个核心要点。" | 明确数量和动作。 |
| 指令 | "列出一个包含步骤和材料的食谱。" | 明确格式要求。 |
- 提供足够的背景信息(Context)
AI 不是神,它需要知道更多关于你的情况才能给出个性化的答案。
| 元素 | 示例 | 作用 |
|---|---|---|
| 背景 | "我正在为五年级的学生准备一堂课。" | AI 会使用简单易懂的语言。 |
| 背景 | "我的预算是5000元,地点在上海。" | AI 会基于这些限制条件提供建议。 |
- 限制条件和格式要求(Constraints/Format)
告诉 AI 不要说什么,或者必须以什么形式呈现结果。
| 元素 | 示例 | 作用 | 格式 |
|---|---|---|---|
| 强制使用结构化数据 | "请用Markdown表格输出。" | 限制 | "回答长度不超过100字。" |
| 避免冗长,保持简洁 | "回答长度不超过100字。" | 限制 | "请用Markdown表格输出。" |
3.5 实战场景
- 场景一:写一封感谢信
| 类型 | 内容 |
|---|---|
| 坏提示词(模糊、无要求) | 帮我写一封感谢信。 |
| 好提示词(遵循原则) | 角色/Persona:请扮演一位专业的公关人员。 指令/Task:为我的老板写一封简短的感谢信,感谢他批准了我的年假。 格式/Format:信件语气要正式且诚恳,长度控制在五行以内。 |
- 场景二:学习了一个新概念
| 坏提示词(空泛) | 好提示词(提供背景和限制) |
|---|---|
| 什么是黑洞? | 角色/Persona:请扮演一名高中物理老师。 背景/Context:我是一个对科学感兴趣的高中生,刚接触天文学。 指令/Task:请用生活中的比喻来解释黑洞是什么。 格式/Format:请确保解释清晰易懂,并避免复杂的数学公式。 |
从理论到实践:一个完整的提示词工作流
提示词工程往往不是一蹴而就的,而是一个"编写 - 测试 - 分析 - 迭代"的循环过程。
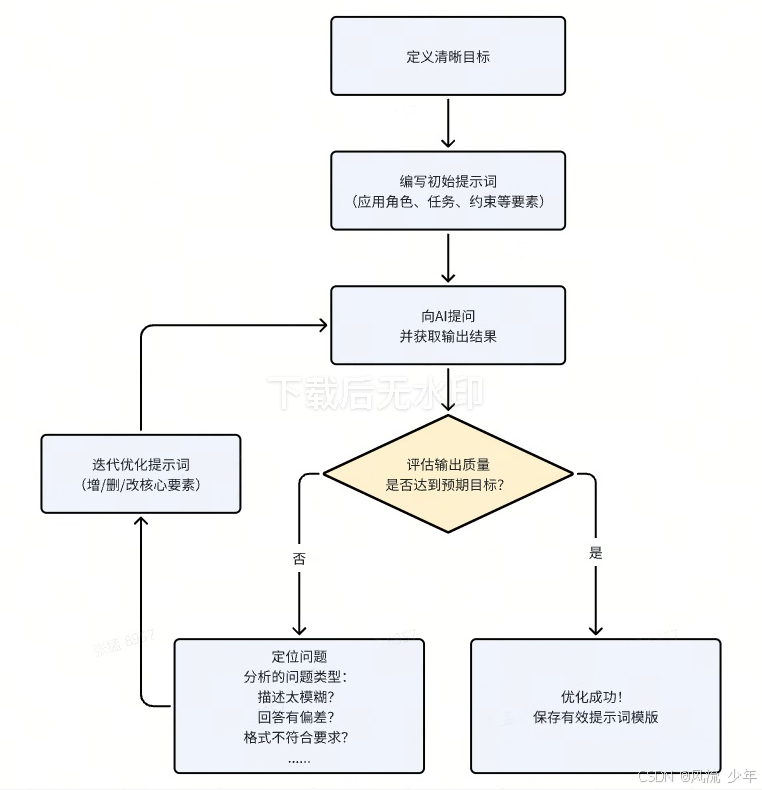
迭代示例:
- 第一轮:你让 AI "总结一篇文章",结果太笼统。
- 第二轮:你修改为"用三个要点总结这篇文章的核心论点",结果好一些,但要点是原文片段的复述。
- 第三轮:你再次优化为"假设你是中学生,用通俗易懂的语言,分三个部分总结这篇文章的主要观点,并每部分举一个生活中的例子",这次你得到了一个结构清晰、易于理解的总结。
总结:
提示词工程不是魔法,而是一种可学习的、结构化的沟通技能。 它的本质是 降低模糊性,提升对齐度,确保你的意图被 AI 精准理解。
使用建议:
- 从模仿开始:多观察和分析优秀的提示词案例(如 GitHub 上的 Awesome-Prompts 项目)。
- 实践并迭代:不要满足于 AI 的第一次回答。多问自己"如何能让它更好?",然后修改提示词再试。
- 建立自己的工具箱:将工作中常用的有效提示词(如邮件润色、周报生成、代码调试)保存下来,形成个人生产力工具箱。
四:其他
-
提示词进阶可以参看:https://www.promptingguide.ai/zh
-
最后
内容核心就是一句话:Token 是底层逻辑,参数是调控手段,提示词是实战武器。
三点结合起来,从 "只会用大模型" 变成 "会驾驭大模型" 。
-
各模型的擅长领域
| 阶段 | 侧重模型 | 模型特点 |
|---|---|---|
| 技术方案 | 深度推理与复杂问题解决专家 | |
| GPT-5.1 Pro | 侧重点是平衡的指令理解与清晰的结构化输出 | |
| Claude Opus 4.5 | 侧重点在于战略设计与复杂系统分析 | |
| 代码开发 | 高效、可靠的代码生成与集成专家 | |
| GPT-5.1-Codex-Max | 侧重点在于生产级代码的可靠集成,生产开发首选 | |
| Gemini 3 Pro | 侧重点在快速原型开发与绿色场构建,适合快速验证想法和构建原型,多模态、前端。生产级代码的"加固"方面可能稍弱 | |
| Claude Opus 4.5 | 侧重点在复杂算法与详尽实现。极其详细、带有大量注释的代码,会导致代码量膨胀,个别情况下可能引入不易察觉的逻辑缺陷 | |
| composer-1 | Free 免费 | |
| 代码评审 | 上下文感知与精准规则检查专家 | |
| Claude Sonnet 4.5 | 侧重点在于基于语义的深度理解与逻辑漏洞发现 | |
| GPT-5.1-Codex-Max | 专精代码模型,侧重点是语法规范与最佳实践审查 | |
| 单元测试 | 高覆盖率测试用例生成专家 | |
| GPT-5.1 以上 | ||
| 测试方案 | 系统化思维与场景构建专家 | |
| Claude Opus 4.5 | 侧重点在于构建全面、多维度的测试体系 | |
| GPT-5.1 Pro | 侧重点是设计可执行、贴合业务场景的测试用例 | |
| 上线方案 | 工程化与性能优化顾问 | |
| 结合知识库的通用模型(如GPT-5.1 Pro) | 侧重点在于生成部署清单、回滚方案和运维手册 |