前提条件
确保已经安装了 ExecuTorch。安装教程:ExecuTorch 系列 1. 从源码构建 ExecuTorch
LLM 导出功能需要 pytorch_tokenizers 包。如果遇到 ModuleNotFoundError: No module named 'pytorch_tokenizers' 错误,请从 ExecutorTorch 源代码安装:
bash
pip install pytorch-tokenizers
# 从源码安装
pip install -e ./extension/llm/tokenizers/支持的模型列表
具体支持的 LLM 模型列表可以从这里找到。
- Llama 2/3/3.1/3.2
- Qwen 2.5/3
- Phi 3.5/4-mini
- SmolLM2
- ...
注: 如果需要导出不在列表中或其他模型架构(如 Gemma、Mistral、BERT、T5、Whisper 等)中的模型,请参阅 Exporting LLMs with Optimum,该页面支持 Hugging Face Hub 中更多种类的模型。
export_llm API
export_llm 是 ExecuTorch 为 LLM 提供的高级导出 API。我们重点介绍使用该 API 导出 Llama 3.2 1B 。export_llm 的参数可以通过CLI args或yaml 配置指定,Yaml 配置字段在 LlmConfig 中定义。调用export_llm :
bash
python -m executorch.examples.extension.llm.export.export_llm
--config <path-to-config-yaml>
+base.<additional-CLI-overrides>
# 例如
python -m extension.llm.export.export_llm --config ~/models/Llama/Llama-3.2-1B/config.yaml基础导出
要进行 Llama3.2 的基础导出,我们首先需要下载检查点文件(consolidated.00.pth)和参数文件(params.json)。可以在 Llama 官网 或 Hugging Face 上找到这些。
在 Llama 官网 或 Hugging Face 上下载 Llama 系列模型都需要申请,而填中国身份申请基本就是被拒绝,可以通过下面的方法下载:
bash
pip install modelscope
modelscope download --model LLM-Research/Llama-3.2-1B然后,指定 model_class、checkpoint(通往检查点文件的路径)和params(指向参数文件的路径)作为参数。此外,后续当使用 Runner APIs 运行导出的 .pte 时,Runner 需要知道该模型的 bos 和 eos ID,才能知道何时终止。这些方法通过 .pte 中的 bos 和 eos 获取方法暴露,我们可以通过在metadata参数中指定 bos 和 eos ID 来添加。这些 Tokens 的值通常可以在 HuggingFace 上模型的tokenizer_config.json 中找到。
yaml
# path/to/config.yaml
base:
model_class: llama3_2
checkpoint: path/to/consolidated.00.pth
params: path/to/params.json
metadata: '{"get_bos_id":128000, "get_eos_ids":[128009, 128001]}'
# export_llm
python -m extension.llm.export.export_llm \
--config path/to/config.yaml对于支持的其他 LLMs,checkpoint 将从 HuggingFace 自动下载,参数文件可在 executorch/examples/models 下各自的目录中找到,例如:executorch/examples/models/qwen3/config/0_6b_config.json。
导出设置
ExportConfig 包含导出 .pte 的设置,如 max_seq_length(提示词最大长度)和 max_context_length(模型内存/缓存的最大长度)。
添加优化
export_llm 会在导出前、导出过程中和降低(Lowering)过程中对模型进行多种优化。量化 和向加速器后端委派 是主要的优化方式,其他所有优化都可以在 ModelConfig 里找到。
yaml
# path/to/config.yaml
base:
model_class: llama3_2
checkpoint: path/to/consolidated.00.pth
params: path/to/params.json
metadata: '{"get_bos_id":128000, "get_eos_ids":[128009, 128001]}'
model:
use_kv_cache: True
use_sdpa_with_kv_cache: True
# export_llm
python -m extension.llm.export.export_llm \
--config path/to/config.yaml推荐使用 use_kv_cache 和 use_sdpa_with_kv_cache 来导出任何 LLM,其他选项则在特定情况下有用。例如:
use_shared_embedding对于具有绑定的输入/输出嵌入层的模型会有帮助,前提是你使用 TorchAO 低比特运算进行量化(quantization.qmode: torchao:8da(\\d+)w或quantization.qmode: torchao:fpa(\d+)w),详见这里。use_attention_sink当达到最大上下文长度时,通过从 KV cache 的开头移除内容来延长生成(过程)。quantize_kv_cache在 int8 中量化 KV cache。local_global_attention实现了 局部 - 全局注意力机制,使特定的注意力层能够使用小得多的局部滑动窗口 KV cache。
量化
量化选项由 QuantizationConfig 定义。ExecuTorch通过两种方式进行量化:
TorchAO (XNNPACK)
TorchAO 在源码层面进行量化,将线性模块替换为量化线性模块。 要在 XNNPACK 后端上进行量化,这是应遵循的量化路径。量化模式定义于此处。
常见的有:
8da4w:wint8 动态激活 + int4 权重量化的缩写。int8:int8 仅权重量化。
组大小的指定方式如下:
group_size:8、32、64 等。
对于 Arm CPU,也有用于 int8 动态激活 + int1-8 权重量化的 低比特内核。请注意,不应将其与 XNNPACK 一起使用,并且通过实验我们发现,对于等效的 8da4w,其性能有时甚至会更好。使用这些条件时,需将qmode指定为以下任一:
torchao:8da(\d+)w: int8 动态激活 + int1-8 权重,例如torchao:8da5wtorchao:fpa(\d+)w: 仅 int1-8 权重,例如torchao:fps4w
要量化 embeddings,可以指定 embedding_quantize: <bitwidth>,<groupsize>(bitwidth必须为 2、4 或 8),对于低比特内核则使用 embedding_quantize: torchao:<bitwidth>,<groupsize> (bitwidth可以是 1 到 8)。
yaml
# path/to/config.yaml
base:
model_class: llama3_2
checkpoint: path/to/consolidated.00.pth
params: path/to/params.json
metadata: '{"get_bos_id":128000, "get_eos_ids":[128009, 128001]}'
model:
use_kv_cache: True
use_sdpa_with_kv_cache: True
quantization:
embedding_quantize: 4,32
qmode: 8da4w
# export_llm
python -m extension.llm.export.export_llm \
--config path/to/config.yamlpt2e (QNN, CoreML, and Vulkan)
pt2e 在导出后图层面进行量化,交换节点并注入量化/解量化节点。 对于非 CPU 后端(QNN、CoreML、Vulkan)进行量化,这就是应遵循的量化路径。 阅读更多关于 pt2e 的内容请见此处,以及 ExecuTorch 如何使用 pt2e 请见此处。
后端支持
后端选项由 BackendConfig 定义。每个后端都有自己的后端配置选项。这里有一个将 LLM 降为 XNNPACK 以实现 CPU 加速的示例:
yaml
# path/to/config.yaml
base:
model_class: llama3_2
checkpoint: path/to/consolidated.00.pth
params: path/to/params.json
metadata: '{"get_bos_id":128000, "get_eos_ids":[128009, 128001]}'
model:
use_kv_cache: True
use_sdpa_withp_kv_cache: True
quantization:
embedding_quantize: 4,32
qmode: 8da4w
backend:
xnnpack:
enabled: True
extended_ops: True # Expand the selection of ops delegated to XNNPACK.性能分析和调试
要查看哪些操作被委派到后端,哪些没有,请指定verbose: True:
yaml
# path/to/config.yaml
...
debug:
verbose: True
...在日志中,会有一个表格,包含图中的所有运算操作,以及哪些被委派了,哪些没有被委派。
例如:
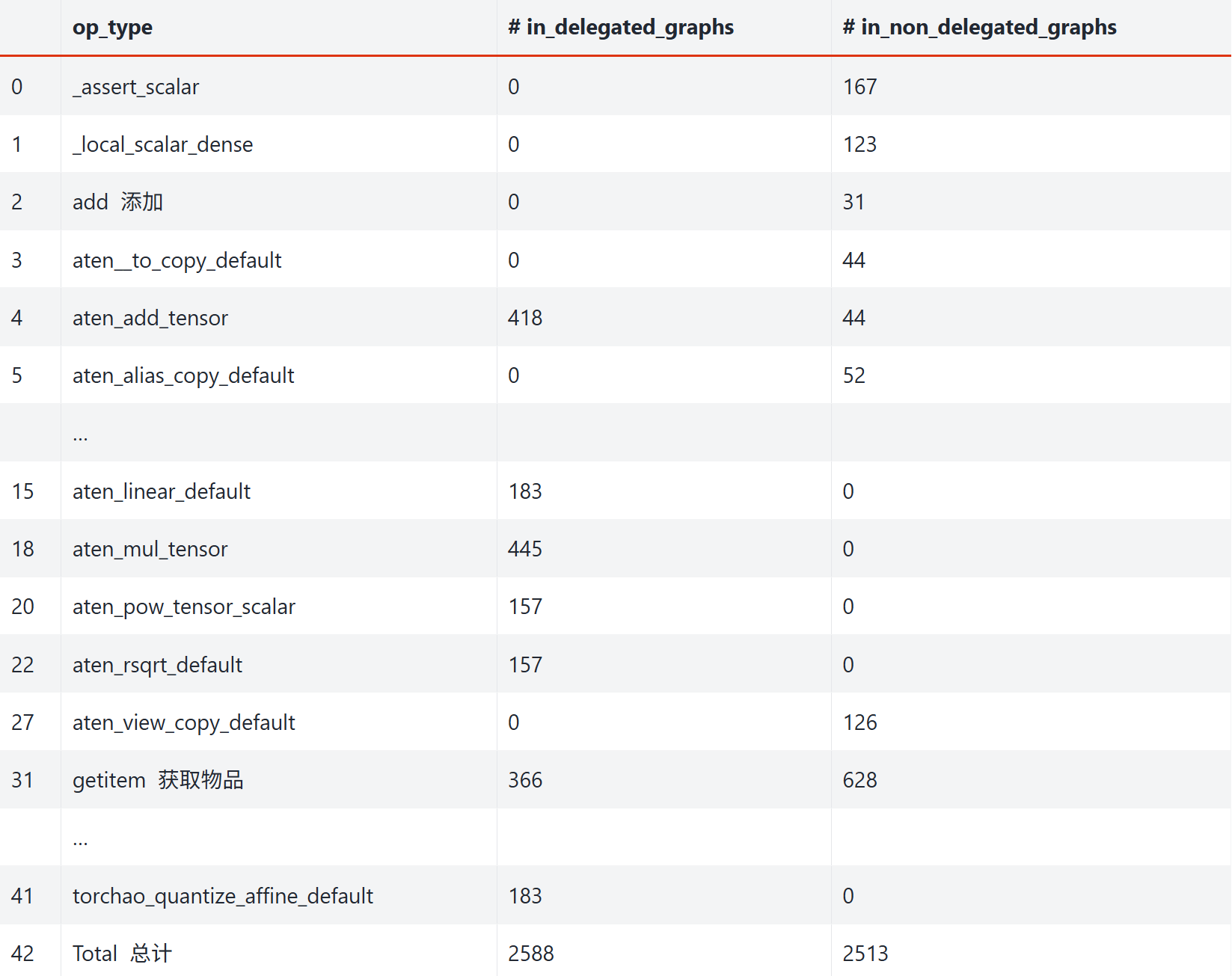
更具体的信息,参见 此处。