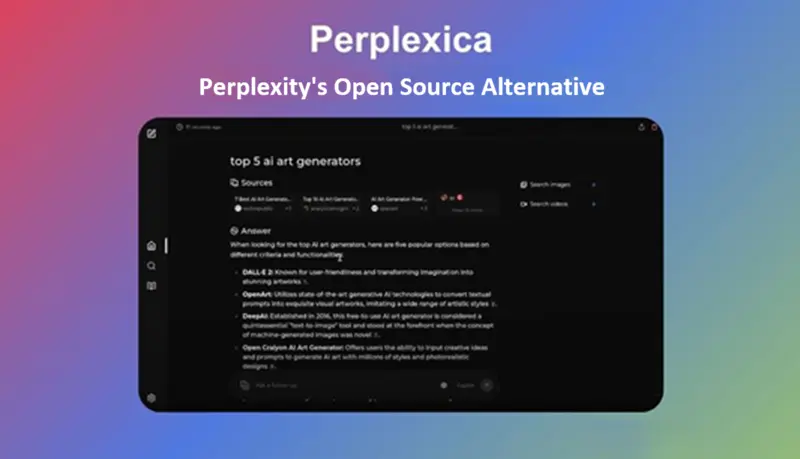
Perplexica通过 SearXNG 搜索网络,可选地使用嵌入/相似性重新排序结果,然后使用 LLM 生成带引用的响应。
SearXNG 是一个免费的互联网元搜索引擎,聚合了多达 245 个搜索服务的结果。用户不会被跟踪或建立画像。此外,SearXNG 可以通过 Tor 使用以实现在线匿名。
Perplexica 提供几个很酷的功能:
- 提供商无关: 随附 Ollama 或可插入 OpenAI/Claude/Gemini/Groq。
- 模式: 速度、平衡、质量,以权衡延迟、深度和成本。
- 源控制: 根据任务使用网络、讨论或学术搜索。
- 小部件: 用于快速查找的即时卡片(天气、计算、股票)。
- 私有网络搜索: 目前是 SearxNG,稍后会有更多检索集成。
- 图像 + 视频: 答案不仅仅是文章。
- 文件问答: 上传文档并查询它们。
- 域范围搜索: 针对特定站点/文档。
- 智能建议: 更好的查询,更快的响应。
- 本地历史: 随时回顾研究。
在开始之前,请务必获取2026 年获胜的智能体 SaaS 模式 ***https://stan.store/agentnative***我们每周都会发送这里显示的每一层的详细分析。
让我们看看如何快速设置 Perplexica。
1、Perplexica 入门
你有两个选项来运行 Perplexica。
(1) Docker Compose
git clone https://github.com/ItzCrazyKns/Perplexica.git
cd Perplexica
# 创建配置
cp sample.config.toml config.toml
# 使用所需的密钥/端点编辑 config.toml
docker compose up -d
# 打开 http://localhost:3000对于 Docker + Ollama,通常使用 http://host.docker.internal:11434 作为 Ollama API URL。
你可以在 UI 的"设置对话框"中稍后更改模型密钥/设置
(2) 非 Docker
-
安装 SearXNG 并在 SearXNG 设置中允许 JSON 格式。
-
克隆存储库并将 sample.config.toml 文件重命名为根目录中的 config.toml。
-
(确保完成此文件中的所有必填字段)
-
然后运行:
npm i
npm run build
npm run start
如果有任何问题,你可以在这里找到更多信息。
2、架构和请求流程
Perplexica 将系统描述为:
-
UI
-
智能体/链
-
SearXNG 用于网络源
-
LLM 用于推理/回答/引用
-
嵌入模型用于重新排序
概念流程是:(1) 请求
(2) 链决定是否需要网络搜索 + 生成查询
(3) SearXNG 搜索
(4) 嵌入 + 相似性重新排序
(5) 响应生成器流式传输到 UI
这通过特定焦点模式处理器和可重用的智能体实现。
src/lib/search/index.ts 是最重要的"产品地图"文件之一。
它将焦点模式注册为 MetaSearchAgent 的实例,设置包括:
-
activeEngines(例如,学术使用 arxiv/scholar/pubmed;youtube 使用 youtube;reddit 使用 reddit) -
rerank和rerankThreshold -
searchWeb对比"不搜索网络"(writingAssistant 设置searchWeb: false) -
summarizer(为 webSearch 启用)
src/lib/search/metaSearchAgent.ts是编排器,它: -
构建"搜索检索器链"(温度为 0 的 LLM 用于查询生成)
-
可以摄取"直接链接"输出(当启用
summarizer时,获取并总结页面),按 URL 对文档进行分组,并使用结构化的系统提示将它们总结为 2-4 段 -
使用 SearXNG 搜索(
searchSearxng),然后使用相似性评分(computeSimilarity)重新排序/选择源(如文档中所述)
3、服务器 API
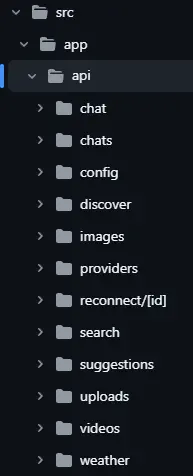
由于 Perplexica 是一个 Next.js App Router 项目,端点位于 src/app/api/* 下。
/api/search(文档化的"搜索 API"),其 POST 主体包括:
-
focusMode、optimizationMode、query、history -
chatModel和embeddingModel(提供商 + 模型名称) -
可选的
systemInstructions -
可选的
stream
Perplexica/src/app/api/search/route.tsimport ModelRegistry from '@/lib/models/registry';
import { ModelWithProvider } from '@/lib/models/types';
import SessionManager from '@/lib/session';
import { ChatTurnMessage } from '@/lib/types';
import { SearchSources } from '@/lib/agents/search/types';
import APISearchAgent from '@/lib/agents/search/api';interface ChatRequestBody {
optimizationMode: 'speed' | 'balanced' | 'quality';
sources: SearchSources[];
chatModel: ModelWithProvider;
embeddingModel: ModelWithProvider;
query: string;
history: Array<[string, string]>;
stream?: boolean;
systemInstructions?: string;
}export const POST = async (req: Request) => {
try {
const body: ChatRequestBody = await req.json();if (!body.sources || !body.query) { return Response.json( { message: 'Missing sources or query' }, { status: 400 }, ); } body.history = body.history || []; body.optimizationMode = body.optimizationMode || 'speed'; body.stream = body.stream || false; const registry = new ModelRegistry(); const [llm, embeddings] = await Promise.all([ registry.loadChatModel(body.chatModel.providerId, body.chatModel.key), registry.loadEmbeddingModel( body.embeddingModel.providerId, body.embeddingModel.key, ), ]); const history: ChatTurnMessage[] = body.history.map((msg) => { return msg[0] === 'human' ? { role: 'user', content: msg[1] } : { role: 'assistant', content: msg[1] }; }); const session = SessionManager.createSession(); const agent = new APISearchAgent(); agent.searchAsync(session, { chatHistory: history, config: { embedding: embeddings, llm: llm, sources: body.sources, mode: body.optimizationMode, fileIds: [], systemInstructions: body.systemInstructions || '', }, followUp: body.query, chatId: crypto.randomUUID(), messageId: crypto.randomUUID(), }); if (!body.stream) { return new Promise( ( resolve: (value: Response) => void, reject: (value: Response) => void, ) => { let message = ''; let sources: any[] = []; session.subscribe((event: string, data: Record<string, any>) => { if (event === 'data') { try { if (data.type === 'response') { message += data.data; } else if (data.type === 'searchResults') { sources = data.data; } } catch (error) { reject( Response.json( { message: 'Error parsing data' }, { status: 500 }, ), ); } } if (event === 'end') { resolve(Response.json({ message, sources }, { status: 200 })); } if (event === 'error') { reject( Response.json( { message: 'Search error', error: data }, { status: 500 }, ), ); } }); }, ); } const encoder = new TextEncoder(); const abortController = new AbortController(); const { signal } = abortController; const stream = new ReadableStream({ start(controller) { let sources: any[] = []; controller.enqueue( encoder.encode( JSON.stringify({ type: 'init', data: 'Stream connected', }) + '\n', ), ); signal.addEventListener('abort', () => { session.removeAllListeners(); try { controller.close(); } catch (error) {} }); session.subscribe((event: string, data: Record<string, any>) => { if (event === 'data') { if (signal.aborted) return; try { if (data.type === 'response') { controller.enqueue( encoder.encode( JSON.stringify({ type: 'response', data: data.data, }) + '\n', ), ); } else if (data.type === 'searchResults') { sources = data.data; controller.enqueue( encoder.encode( JSON.stringify({ type: 'sources', data: sources, }) + '\n', ), ); } } catch (error) { controller.error(error); } } if (event === 'end') { if (signal.aborted) return; controller.enqueue( encoder.encode( JSON.stringify({ type: 'done', }) + '\n', ), ); controller.close(); } if (event === 'error') { if (signal.aborted) return; controller.error(data); } }); }, cancel() { abortController.abort(); }, }); return new Response(stream, { headers: { 'Content-Type': 'text/event-stream', 'Cache-Control': 'no-cache, no-transform', Connection: 'keep-alive', }, }); } catch (err: any) { console.error(`Error in getting search results: ${err.message}`); return Response.json( { message: 'An error has occurred.' }, { status: 500 }, ); }};
src/app/api/chat/route.ts 是"聊天运行时":
-
接受
message、history、files、模型选择、焦点模式、优化模式、systemInstructions -
使用相同的
searchHandlers[focusMode].searchAndAnswer(...)机制流式传输的事件如:
-
{ type: "message", data: "...", messageId } -
{ type: "sources", data: [...], messageId } -
{ type: "messageEnd", messageId }它还通过 Drizzle 持久化聊天/消息(
chats、messages架构),并在存在时将源存储在消息元数据中。
你可能接触的其他 API 路由来自 src/app/api 文件夹列表:models、config、suggestions、images、videos、uploads、weather 等。
4、模型提供商和选择
Perplexica 将模型抽象在"提供商"之后,路由处理器请求:
- "可用的聊天模型提供商"
- "可用的嵌入模型提供商"
提供商的配置密钥位于config.toml(MODELS.*)中,并通过辅助函数如getOpenaiApiKey()、getGroqApiKey()等读取。
支持的提供商通过以下方式反映:
-
配置模板(
sample.config.toml) -
提供商目录列表(OpenAI、Ollama、Groq、Anthropic、Gemini、DeepSeek、LM Studio、自定义端点、AI/ML API、transformers)
这是非流式搜索的最小"API 使用"示例:curl -X POST http://localhost:3000/api/search
-H "Content-Type: application/json"
-d '{
"focusMode": "webSearch",
"optimizationMode": "balanced",
"query": "What is Perplexica?",
"history": [],
"stream": false
}'
以及流式搜索:
curl -N -X POST http://localhost:3000/api/search \
-H "Content-Type: application/json" \
-d '{
"focusMode": "webSearch",
"optimizationMode": "balanced",
"query": "Explain how Perplexica reranks sources",
"history": [],
"stream": true
}'如果你正在构建搜索或深度研究智能体,一定要试试看,我很乐意在评论中听到你的经验。