我们已知,pod在创建时,调度器会根据预选和优选选择合适的节点调度pod运行。预选阶段过滤掉不满足条件的节点。预选策略通常考虑以下方面:
1、NodeSelector匹配
如果pod定义文件有的话,会检查node标签是否匹配
2、检查节点的CPU、内存等资源是否满足Pod请求。
3、端口是否有占用
4、检查节点是否满足pod的亲和性规则
5、检查节点是否有不被pod容忍的污点
前三条比较容易理解,本文探究pod中的亲和性规则和容忍规则如何书写。
一开始,我对pod的容忍机制不是很理解,为什么不是选择,而是容忍?后来豆包给我举了一个场景,这种容忍机制更灵活:假如我有一个pod不可用了,我只需要在pod上打一个污点,只要pod没有容忍这个污点那么pod就会被驱逐,而不需要修改每个pod。
所以容忍机制就像一对情侣,男方/女方(node)犯错(资源不可用、失联),另一半(pod)会开始计算分手(驱逐)时间,是一种原谅,即容忍行为,而不是对节点的选择行为。而选择伴侣(调度pod)的过程中就会看对方(node)有哪些缺点是不能容忍的,从而不会调度到该节点。
实例:
以下是kubectl get pod pod-name -o yaml的截取内容
tolerations: #这个"容忍"是pod级别的,这组容忍配置是默认配置
- effect: NoExecute #污点效果:立即驱逐
key: node.kubernetes.io/not-ready #污点键
operator: Exists #匹配方式,只要存在这个键就驱逐
tolerationSeconds: 300 #容忍时间
#当节点状态是not ready时,时间超过300s pod会被立即驱逐
- effect: NoExecute
key: node.kubernetes.io/unreachable
operator: Exists
tolerationSeconds: 300
#同上,节点失联这个默认规则的作用是防止节点短暂故障(如网络抖动)时pod被驱逐。
其他operator可能的值:
equal:key-value都匹配
exists:key为空时,容忍所有节点(不管你有什么缺点,我都原谅你)
DoesNotExist用的比较少
其他effect可能的值:
NoSchedule、PreferNoSchedule、NoExecute
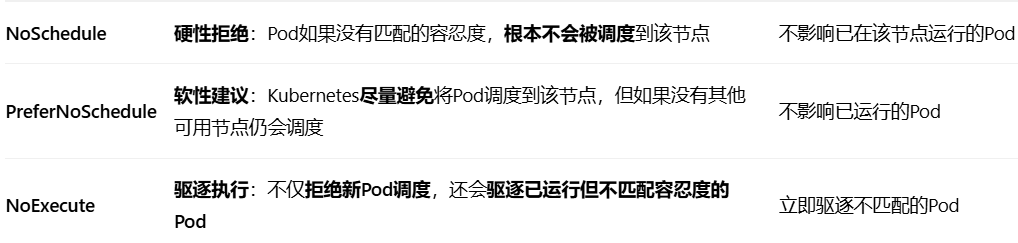
粘几张ai提供的实例更好理解:



