MegaFlow:面向Agent时代的大规模分布式编排系统
随着交互式和自主AI系统的快速发展,我们正步入Agent时代。在软件工程和计算机使用等复杂任务上训练智能体,不仅需要高效的模型计算能力,更需要能够协调大量Agent-环境交互的复杂基础设施。MegaFlow作为大规模分布式编排系统,为Agent训练工作负载提供高效的调度、资源分配和细粒度任务管理能力,成功实现了数万个并发Agent任务的协调执行,同时保持高系统稳定性和高效的资源利用率。
论文标题:MegaFlow: Large-Scale Distributed Orchestration System for the Agentic Era
来源:arXiv:2601.07526v2 + https://arxiv.org/abs/2601.07526
PS: 整理了LLM、量化投资、机器学习方向的学习资料,关注同名公众号 「 AI极客熊 」 即刻免费解锁
文章核心
研究背景
Agent时代标志着AI系统从对话模型向执行复杂多步任务的自主智能体转变。训练这类Agent需要在现实世界任务上进行大规模交互式学习,依赖于大语言模型、强化学习和多Agent协调技术的突破。传统方法虽然适合简单任务,但无法满足复杂多步任务大规模训练所需的Agent-环境交互编排需求。核心挑战不在于计算能力,而在于大规模Agent训练工作负载涉及的动态、相互依赖进程的复杂协调。
研究问题
- 安全与隔离约束:复杂Agent训练需要容器化环境,但训练集群的安全策略禁止执行任意容器,导致需求与基础设施不兼容。
- 存储可扩展性限制:每个Agent任务需要容器化环境,SWE-bench等数据集需要超过25TB存储,存储需求随规模扩展呈指数级增长。
- 计算吞吐量瓶颈:容器化Agent-环境交互的资源密集型特性严重限制并发训练吞吐量。
主要贡献
- 解决安全与隔离约束:将容器化工作负载迁移到弹性云计算服务,实现安全、隔离的Agent执行。
- 解决存储可扩展性限制:通过云注册服务实现按需容器镜像供应,将存储需求转换为弹性模型。
- 突破计算吞吐量瓶颈:引入分布式编排系统,协调数千个轻量级实例而非高规格机器。
- 系统性能验证 :实现32%成本降低,扩展到数千个并发任务,在超过200万次Agent训练执行中验证。
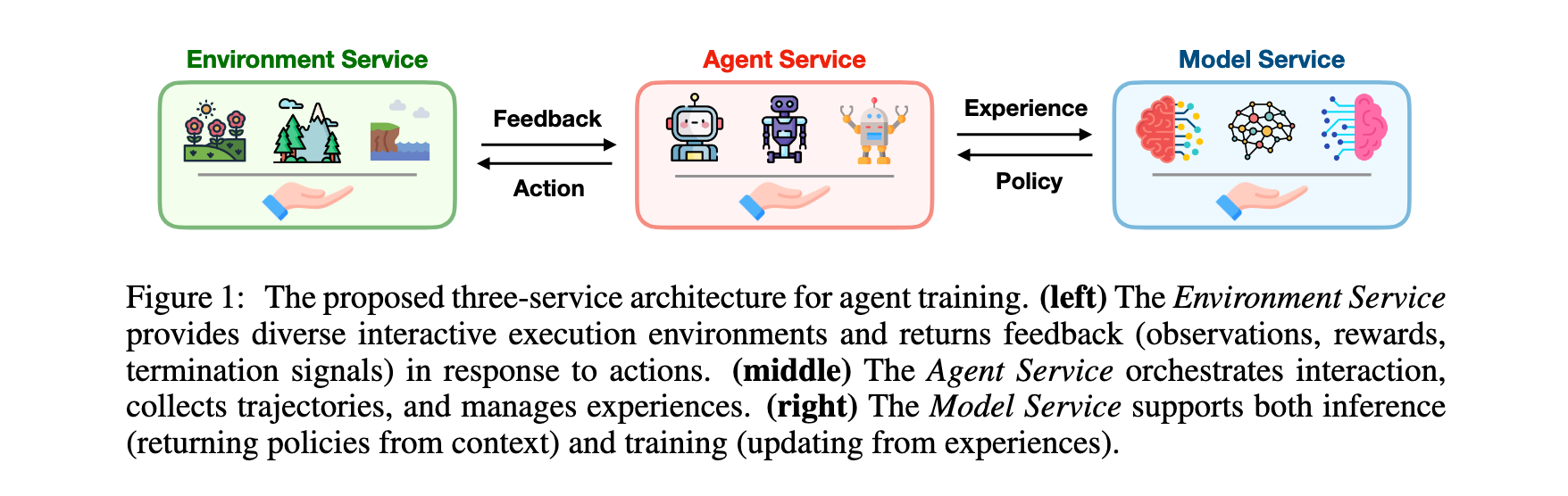
方法论精要
MegaFlow的核心创新在于将Agent训练基础设施抽象为三个独立服务(Model Service、Agent Service、Environment Service),通过统一接口交互,实现独立扩展和灵活资源分配。图2详细展示了MegaFlow的完整系统架构,从底部的Model Service提供推理和训练能力,通过中间的Agent Service协调执行策略,到顶部的Environment Service提供容器化执行环境和分布式任务调度。
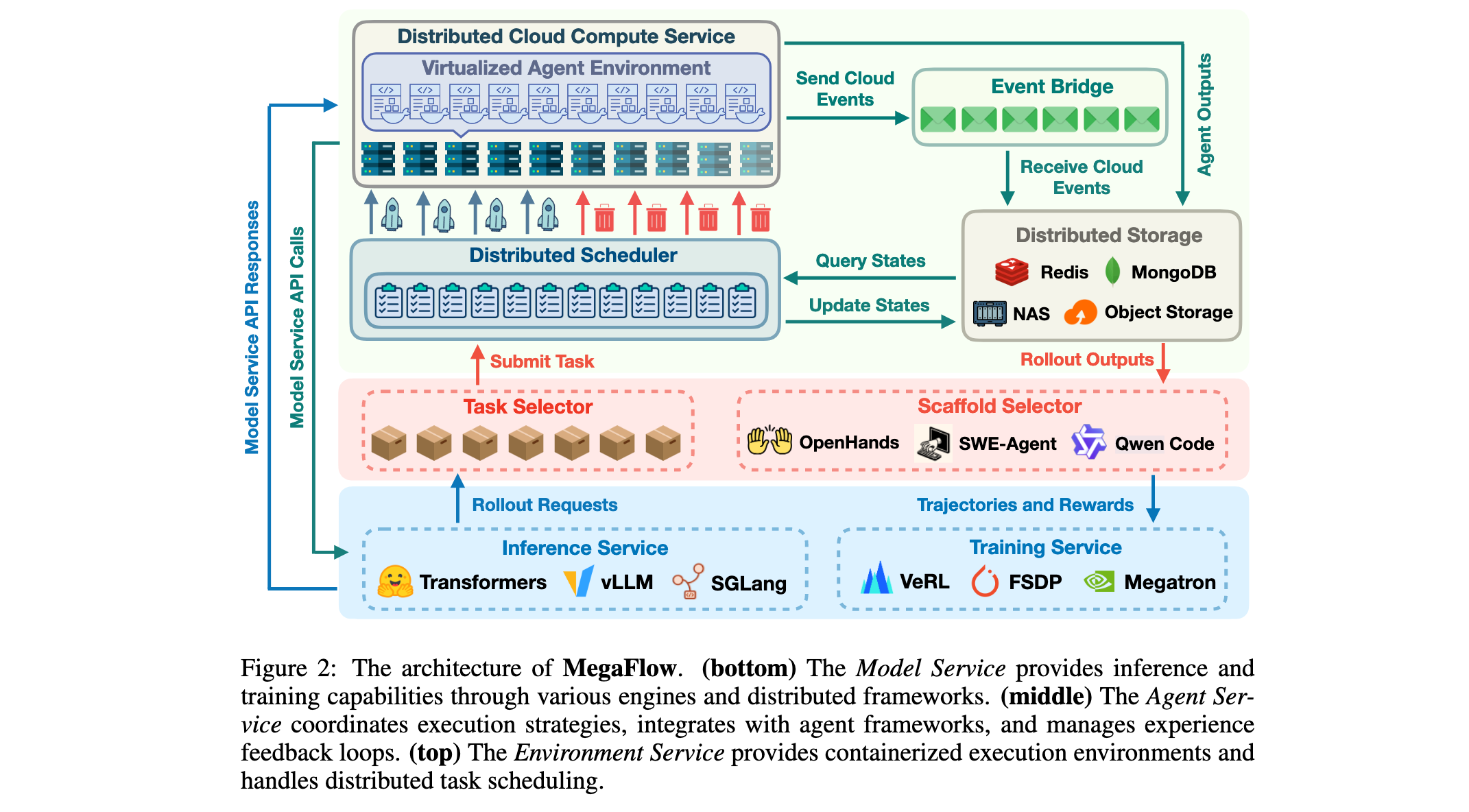
三服务架构设计:Model Service通过Transformers、vLLM和SGLang等推理引擎提供推理能力,支持从上下文返回策略;通过VeRL、FSDP和Megatron等分布式训练框架支持训练,从收集的经验更新模型参数。该服务纯粹专注于模型计算和参数更新,抽象化了Agent-环境交互的复杂性。Agent Service作为智能协调器,集成OpenHands、SWE-Agent和Qwen Code等框架,管理不同任务类型(训练、评估或数据合成)的rollout执行,在指定数据集上协调执行,处理rollout输出,聚合评估指标,并将经验数据反馈给Model Service进行训练迭代。Environment Service负责Agent任务的物理执行,在分布式系统中排队任务,采用复杂调度监控资源可用性,调度任务到云计算实例,每个实例通过容器化环境执行多个并发Agent任务,为Agent-环境交互提供隔离的执行上下文。
关键设计原则:MegaFlow采用"多小实例"弹性资源策略,优于"少大实例"模型。系统实现混合执行模型:短暂执行用于任务隔离,持久执行用于资源效率。采用事件驱动协调而非复杂共识协议,通过分布式状态管理消除轮询开销。战略性地将特定领域操作委托给专门系统,专注于Agent-环境协调的独特挑战。
架构组件实现:Task Scheduler实现高性能异步调度器,采用FIFO调度策略。对于短暂任务,配置专用实例执行单个任务后立即释放;对于持久任务,维护实例池并采用基于池的分配。ResourceManager采用统一资源分配策略和标准化计算实例,通过三层限制机制实现并发控制:用户参数控制API调用速率、分布式信号量确保不超过计算容量、管理配额控制资源使用。Environment Manager通过云注册服务预供应容器镜像,通过分层方法实现环境隔离。Event-Driven Monitoring通过实例生命周期事件和任务完成事件实现反应式系统行为。Data Persistence分离操作数据和结果制品,操作元数据通过文档数据库管理,任务队列使用内存存储,Agent执行制品持久化到云对象存储。
实验洞察
实验使用需要容器化环境的软件工程Agent训练任务评估MegaFlow性能,利用SWE-bench、SWE-Gym等大规模数据集,进行数万个并发任务的工作负载扩展实验。MegaFlow支持SWE-Agent、OpenHands、Qwen Code等主要Agent框架。
由于没有可比较基础设施,通过系统比较执行策略建立基线:高规格集中式方法(208核CPU、3TB内存,每实例50个并发任务)和MegaFlow分布式方法(8核、16GB实例,每实例1个并发任务)。评估基于超过130,000个短暂执行任务和200万个持久执行任务的生产部署记录。
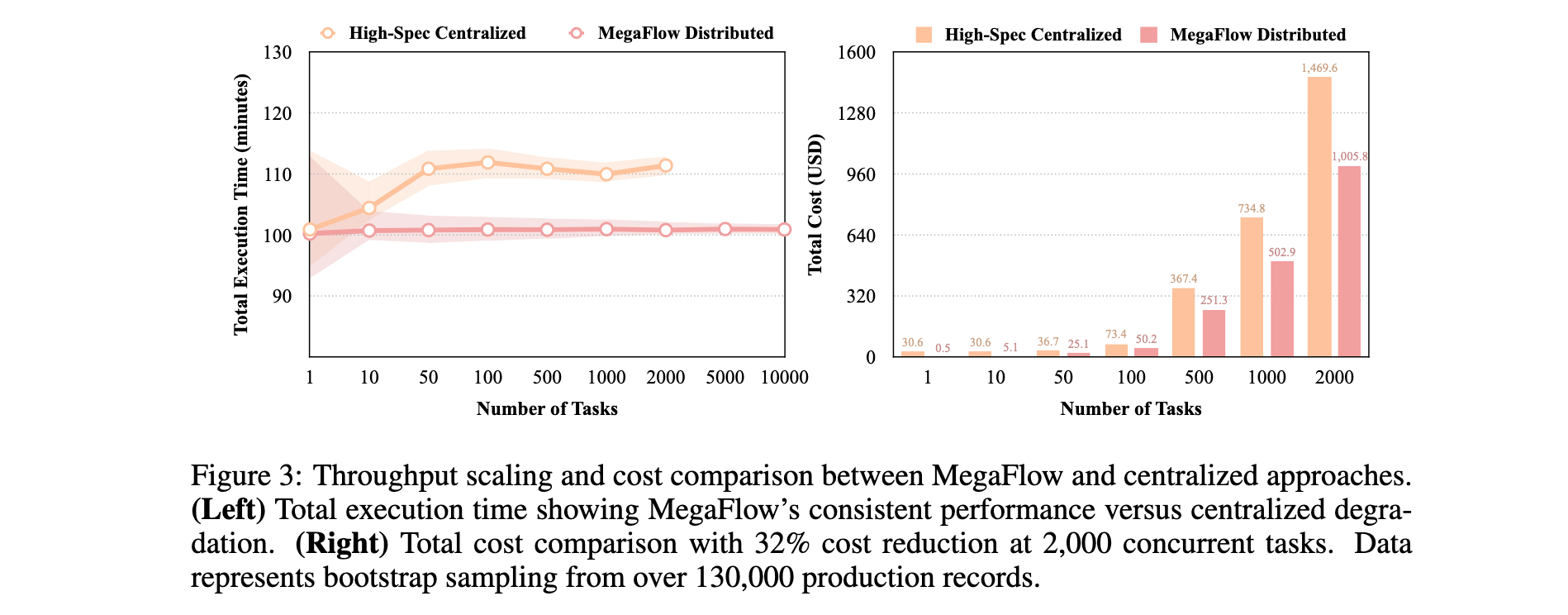
吞吐量和可扩展性分析:如图3所示,MegaFlow在1到10,000个任务中保持约100分钟的一致执行时间,高规格集中式方法由于资源争用从100分钟退化到110分钟。集中式方法受实例可用性限制在2,000个并发任务,MegaFlow能够配置10,000个实例。在2,000个任务时,MegaFlow实现32%成本降低(1,005美元对1,470美元)。
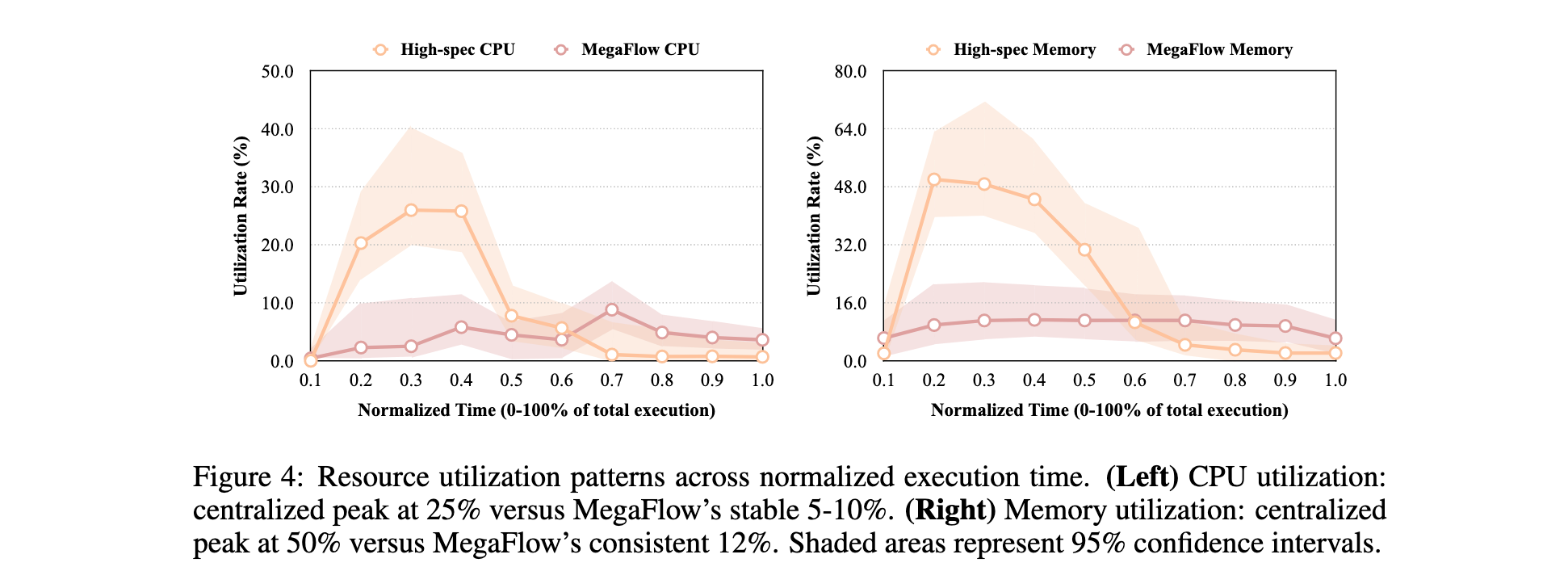
资源利用率分析 :图4展示了资源利用率对比。高规格集中式实例CPU利用率在初始30%期间达到25%峰值后下降,内存利用率在执行中期达到50%峰值后急剧下降。MegaFlow的分布式架构CPU利用率稳定在5-10%,内存利用率保持约12%。对比模式突显了效率差异,集中式方法表现出"突发性"资源消耗和大量空闲期。
端到端延迟分析 :图5的延迟分解显示,MegaFlow的持久执行模式总延迟约75分钟,短暂模式约90分钟,高规格集中式方法约110分钟。环境启动时间方面,高规格集中式方法从1分钟退化到13分钟,MegaFlow短暂模式从1分钟增长到6分钟,持久执行保持低于1分钟。图5右侧清晰展示了这种可扩展性差异。
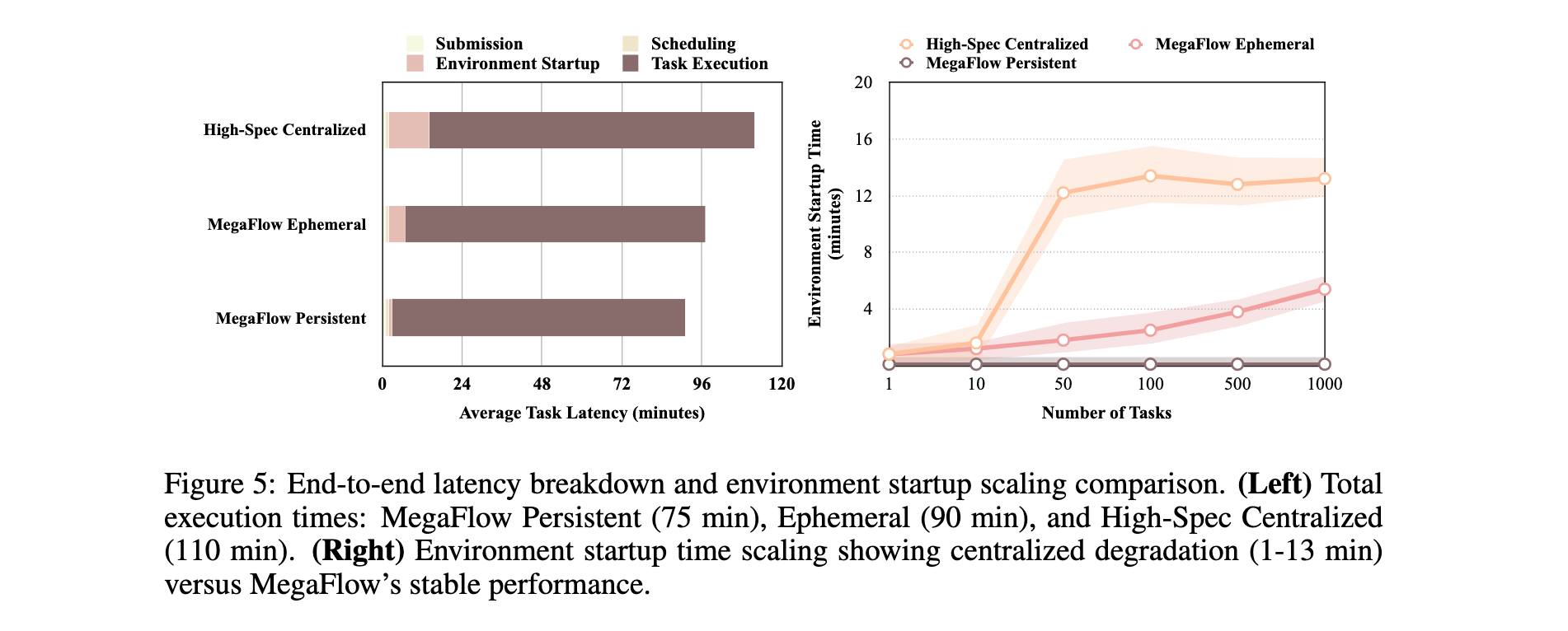
这些结果验证了混合执行模型设计原则。持久执行通过环境重用为持续工作负载提供最佳性能,短暂执行提供更好的隔离保证。评估表明MegaFlow通过分布式编排和混合执行模型成功解决了大规模Agent训练的可扩展性挑战。"多小实例"方法在保持一致性能的同时实现了卓越的成本效率。生产环境验证显示,MegaFlow成功协调了每个训练步骤1024个并行SWE环境,在异构Agent框架中维持稳定、容错和高吞吐量分布式rollout。