一、DeepSeek-OCR-2 在做什么:从"扫描图像"到"阅读理解"
如果把之前的 OCR 系统比作"只会拍照的机器",那 DeepSeek-OCR-2 更像是"先看整页结构,再按语义顺序把字抠出来"的"有策略阅读者"。
官方论文里给了一个清晰的结构:DeepSeek-OCR-2 使用了一种叫 Visual Causal Flow(视觉因果流)的新编码方式,核心是:
先用类似"注意力扫描"的机制看全图,先定位标题、段落、表格、图片、公式等区域;
再根据语义,决定"接下来该读哪里""先读哪个 token、后读哪个 token",按人类阅读顺序生成一条因果流序列(causal flow tokens)。
与传统模型从左到右、逐像素或逐块扫描不同,DeepSeek-OCR-2 在 OmniDocBench v1.5 基准中,只用更少的视觉 token(256--1120 个)就拿到了 91.09% 的综合得分,比上一代提升约 3.73%;阅读顺序编辑距离从 0.085 降到 0.057,说明它对"逻辑结构"的理解明显更贴近人类。
此外,官方还给出了很夸张的吞吐指标:单张 A100 就能做到每天约 20 万页文档,推理时 token 生成速度可达 2500 tokens/s,这为大规模文档数字化与知识抽取提供了一个非常实用的技术基础。
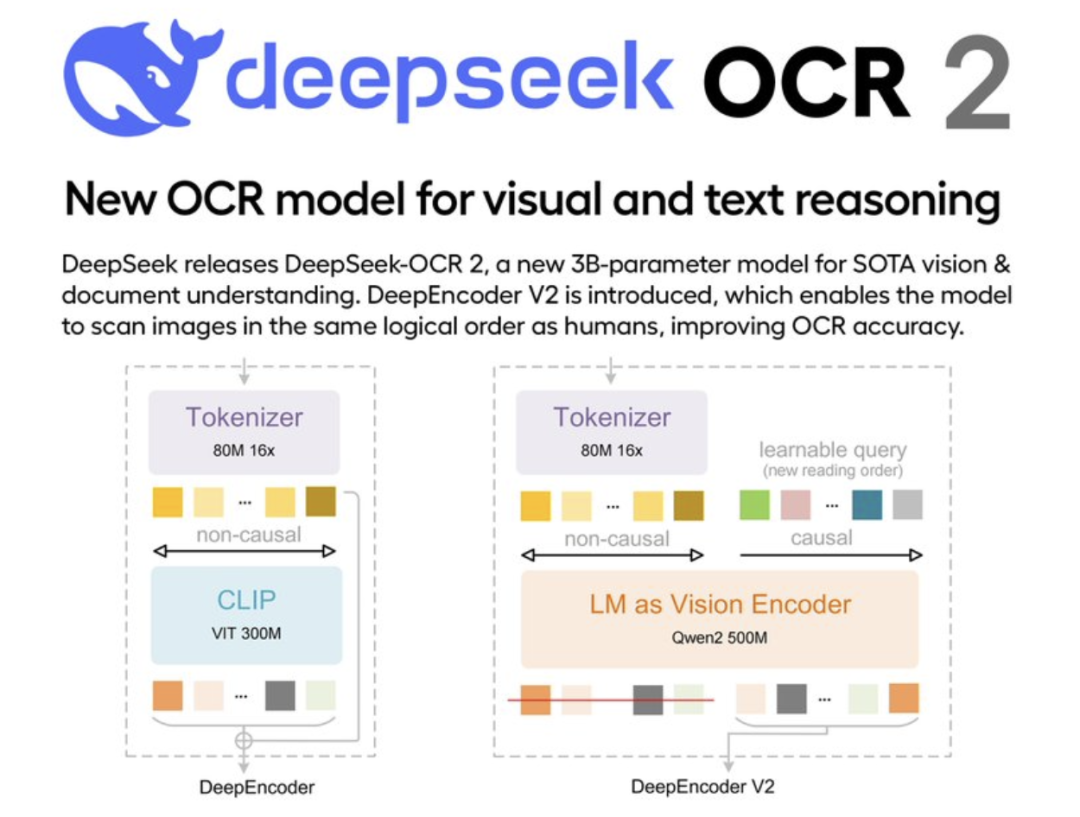
二、核心创新:Visual Causal Flow + DeepEncoder V2
DeepSeek-OCR-2 的最大创新在于"让模型学会'怎么读',而不是'按顺序扫'"。这主要体现在:
视觉编码器升级:从 CLIP ViT-300M 换成 Qwen2-0.5B(约 500M 参数)的 DeepEncoder V2;
可学习的"因果查询"(learnable causal flow queries)作为视觉 token 之后的"后缀",指导模型按合理顺序阅读文档。
官方论文与博文中把这种机制概括为:
先通过双向注意力机制做全局感知,明确"页面上有哪些块""各自大概在哪儿";
再生成"因果流 token",模拟人类"扫视 → 定位 → 深入细节"的阅读路径;
即便面对报纸、教材、论文、报告等复杂排版,也能更好地还原出合理的阅读顺序。
三、性能提升: OmniDocBench 91.09%,编辑距离大幅降低
权威文档理解基准 OmniDocBench v1.5 的测试结果,是这次发布最被引用的一组数据:
综合得分:91.09%,较前代提升约 3.73 个百分点;
阅读顺序编辑距离:从 0.085 降到 0.057;
在更少的视觉 token 预算下,实现更高精度的结构还原。
DeepSeek 团队也在官方博客与 GitHub 仓库中展示了吞吐与延迟结果:单卡 A100 环境下,每秒能生成约 2500 个 token,换算成整页文档处理能力,大概是一天 20 万页文档的级别。这对要同时兼顾"精度"和"成本"的工程化落地非常关键。

四、能力边界:它能做什么、还有哪里需要补位?
结合 DeepSeek 官方的功能介绍与 Demo,可以大致勾勒出它的能力边界:
更擅长:学术 PDF / 技术报告 / 论文 / 教材 / 说明书 / 报纸 / 周刊;
更擅长:版面结构清晰、图表与文字共存、公式与表格较多的场景;
更擅长:将多模态文档(PDF)转成结构化文本或 Markdown,方便接大模型做问答与检索;
目前仍需要人介入:手写、严重模糊、极度复杂嵌套的公式与图表、跨页跨栏的极端布局仍需人工兜底。
五、工程与开源:论文、模型与 Demo 都已公开
为了让人员尽快上手,DeepSeek 团队同步做了三件事:
论文:发布了《DeepSeek-OCR-2: Visual Causal Flow》,对架构与实验细节做了系统说明;
模型:开源了 DeepSeek-OCR-2 权重与推理代码,并给出完整运行与微调指南;
Demo:提供了一个快速试用 Demo,让用户直接在 Hugging Face 页面体验"像人一样读文档"的效果。
整体来看,DeepSeek-OCR-2 的意义不仅是一个 OCR 模型的迭代,而是让"文档理解"从"识别文字"升级到"按逻辑阅读",这对知识库构建、企业档案数字化、科研数据清洗等场景都是一个非常有力的新基座。
相关链接:
Github:https://github.com/deepseek-ai/DeepSeek-OCR-2
HF:https://huggingface.co/deepseek-ai/DeepSeek-OCR-2
论文:https://github.com/deepseek-ai/DeepSeek-OCR-2/blob/main/DeepSeek_OCR2_paper.pdf