一、背景:多源站全球访问质量如何持续监控?
在多源站架构中(CN / US / EU 等区域部署源站),常见挑战包括:
- 用户访问存在明显地域差异
- CDN 回源质量不稳定
- 灰度、流量调度缺乏实时依据
传统方案通常依赖:
- 单点服务器定时探测
- cron + 数据库轮询调度
但在全球化场景下:
❌ 探测点单一,数据失真
❌ 调度性能瓶颈明显
❌ 扩展成本高
因此,本系统目标是构建:
一个基于 Serverless 的高性能分布式测速调度系统
低成本、可扩展、全球覆盖
二、核心设计思想:Heartbeat + KV 驱动调度模型
我们采用一种云原生常用模式:
👉 Cron 只负责唤醒(心跳)
👉 KV 负责调度中枢
👉 Worker 负责执行编排
👉 数据库存结果
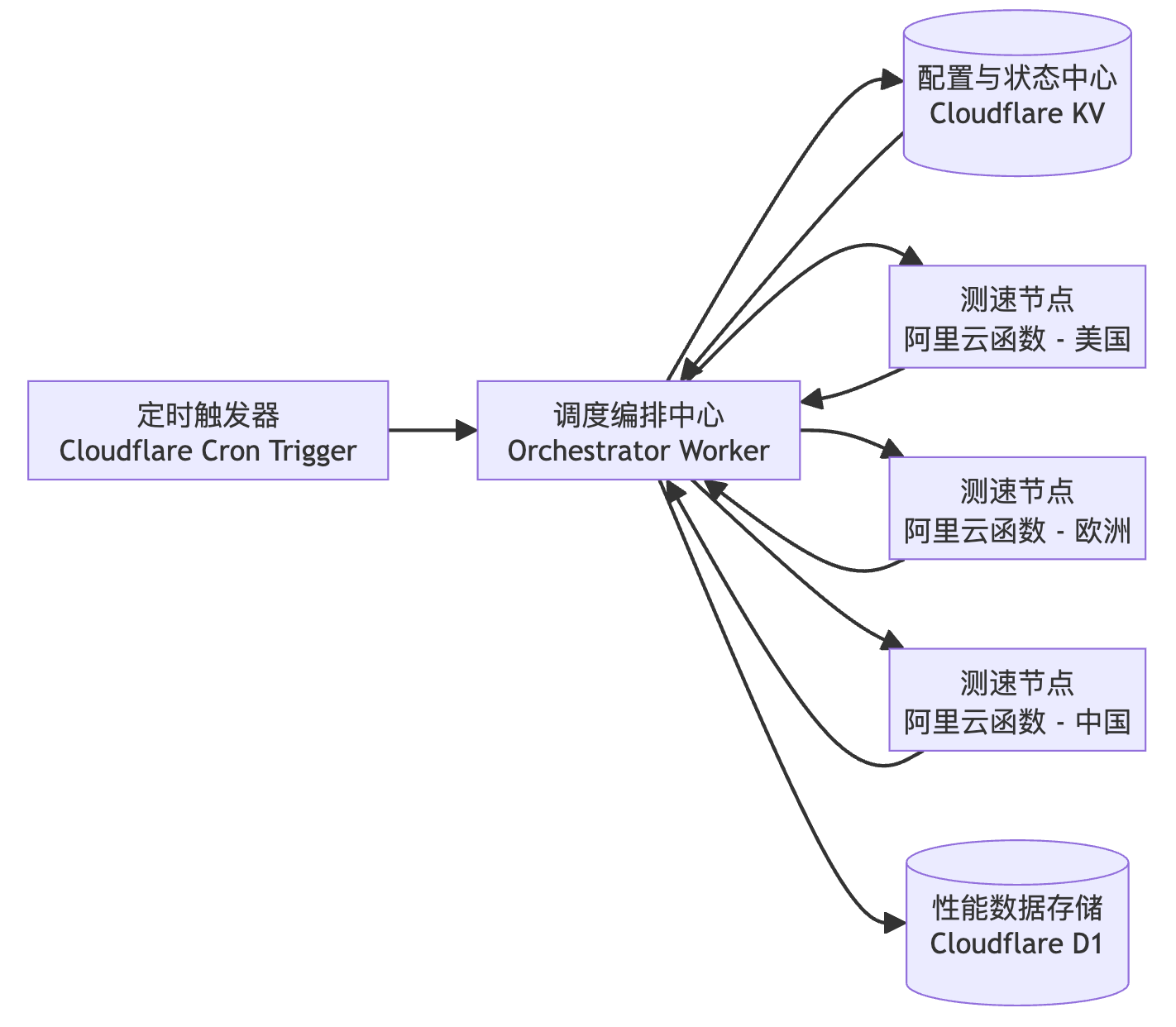
架构组件:
| 组件 | 职责 |
|---|---|
| Cloudflare Cron Trigger | 每分钟触发 Worker |
| Cloudflare Worker | 调度与任务编排 |
| Cloudflare KV | 配置 + 状态机 |
| 阿里云函数计算 | 多区域测速节点 |
| Cloudflare D1 | 存储测速数据 |
三、总体架构图
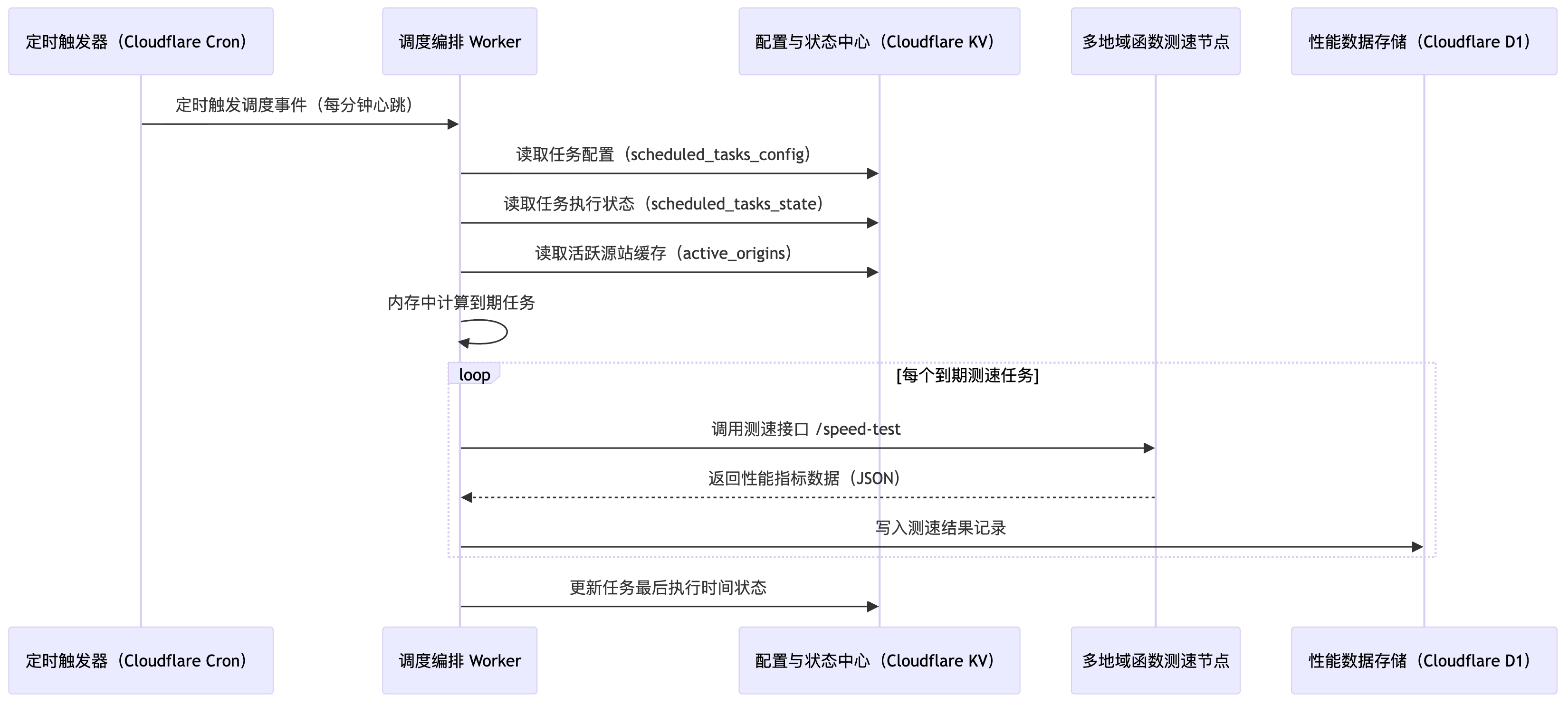
四、调度时序图
五、KV 数据模型设计
1️⃣ 任务配置
plain
[
{
"id": "task_all_origins",
"origin_id": null,
"interval_minutes": 60,
"target_path": "/speed-test",
"status": "active"
},
{
"id": "task_us_high_freq",
"origin_id": 101,
"interval_minutes": 5,
"target_path": "/speed-test",
"status": "active"
}
]2️⃣ 执行状态
plain
{
"task_all_origins": 1700000000000,
"task_us_high_freq": 1700000300000
}3️⃣ 活跃源站缓存
plain
[
{ "id": 101, "base_url": "https://origin-us.example.com", "region": "us" },
{ "id": 102, "base_url": "https://origin-eu.example.com", "region": "eu" }
]六、测速接口规范
所有函数节点统一暴露接口:
请求:
plain
GET /speed-test返回:
plain
{
"dnsLookup": 5,
"tcpConnect": 79,
"tlsHandshake": 5,
"ttfb": 80,
"download": 16,
"total": 185,
"statusCode": 200,
"remoteIp": "104.21.14.63",
"remotePort": 443,
"cdn": {
"provider": "cloudflare",
"cacheStatus": "HIT",
"node": "IAD"
},
"size": 32204
}七、性能模型分析
传统方案:
plain
cron -> DB scan -> execute性能复杂度:
O(n) 数据库轮询
KV 驱动方案:
plain
cron -> KV read -> memory filter -> execute性能复杂度:
O(1) 配置读取
O(m) 到期任务执行(m ≪ n)
延迟对比(实测经验值):
| 操作 | 延迟 |
|---|---|
| D1 查询 | 20~50ms |
| KV 读取 | 1~5ms |
| 内存判断 | <1ms |
👉 调度性能提升一个数量级以上
八、关键工程权衡
✅ 使用 KV 最终一致性
允许:
- 偶发重复执行
- 偶发延迟执行
换取:
- 极低延迟
- 高吞吐
- 简化架构
✅ Cron 粗粒度 + 软件调度
避免:
- 数百个 cron 配置
- 运维复杂度爆炸
九、扩展方案设计(规模化演进)
🚀 方案一:调度分片(水平扩展)
plain
{
"id": "task_1",
"shard": 0
}Worker 只处理所属 shard。
支持:
👉 百万级任务调度
🚀 方案二:状态拆 Key
plain
state:task_1
state:task_2提升并发安全性。
🚀 方案三:智能频率调整
基于历史波动自动调整测速频率:
- 稳定 → 降频
- 抖动 → 高频
🚀 方案四:异常自愈
- 连续失败自动暂停
- 触发告警
十、总结
通过:
✅ Cloudflare Cron 心跳
✅ KV 作为调度大脑
✅ Worker 编排执行
✅ 多区域函数探测
构建了一个:
🌍 全球分布式
⚡ 高性能
📈 可扩展
💰 低成本
的测速调度系统。
该架构非常适合:
- 多源站监控
- CDN 回源质量评估
- 灰度流量决策支持
- 全球链路可观测性建设