
【作者主页】Francek Chen
【专栏介绍】⌈ ⌈ ⌈大数据技术原理与应用 ⌋ ⌋ ⌋专栏系统介绍大数据的相关知识,分为大数据基础篇、大数据存储与管理篇、大数据处理与分析篇、大数据应用篇。内容包含大数据概述、大数据处理架构Hadoop、分布式文件系统HDFS、分布式数据库HBase、NoSQL数据库、云数据库、MapReduce、Hadoop再探讨、数据仓库Hive、Spark、流计算、Flink、图计算、数据可视化,以及大数据在互联网领域、生物医学领域的应用和大数据的其他应用。
【GitCode】专栏资源保存在我的GitCode仓库:https://gitcode.com/Morse_Chen/BigData_principle_application。
文章目录
-
- [一、HBase 的功能组件](#一、HBase 的功能组件)
- 二、表和Region
- 三、Region的定位
- 总结
一、HBase 的功能组件
HBase 的实现包括 3 个主要的功能组件:库函数,链接到每个客户端;一个 Master 主服务器(也称为 Master);许多个 Region 服务器。Region 服务器负责存储和维护分配给自己的 Region,处理来自客户端的读写请求。Master 主服务器负责管理和维护 HBase 表的分区信息,比如一个表被分成了哪些 Region,每个 Region 被存放在哪台 Region 服务器上,同时也负责维护 Region 服务器列表。因此,如果 Master 主服务器死机,那么整个系统都会无效。Master 会实时监测集群中的 Region 服务器,把特定的 Region 分配到可用的 Region 服务器上,并确保整个集群内部不同 Region 服务器之间的负载均衡。当某个 Region 服务器因出现故障而失效时,Master 会把该故障服务器上存储的 Region 重新分配给其他可用的 Region 服务器。除此以外,Master 还处理模式变化,如表和列族的创建。
客户端并不是直接从 Master 主服务器上读取数据,而是在获得 Region 的存储位置信息后,直接从 Region 服务器上读取数据。尤其需要指出的是,HBase 客户端并不依赖于 Master 而是借助于 ZooKeeper 来获得 Region 的位置信息的,所以大多数客户端从来不和 Master 主服务器通信,这种设计方式使 Master 的负载很小。
二、表和Region
在一个 HBase 中,存储了许多表。对于每个 HBase 表而言,表中的行是根据行键的值的字典序进行维护的,表中包含的行的数量可能非常庞大,无法存储在一台机器上,需要分布存储到多台机器上。因此,需要根据行键的值对表中的行进行分区(见图1)。每个行区间构成一个分区,被称为"Region"。Region 包含了位于某个值域区间内的所有数据,是负载均衡和数据分发的基本单位。这些 Region 会被分发到不同的 Region 服务器上。
初始时,每个表只包含一个 Region,随着数据的不断插入,Region 会持续增大。当一个 Region 中包含的行数量达到一个阈值时,就会被自动等分成两个新的 Region(图2),随着表中行的数量继续增加,就会分裂出越来越多的 Region。
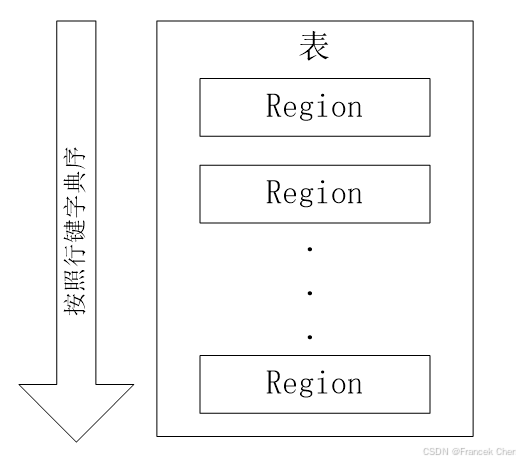
图1 一个HBase表被划分成多个Region
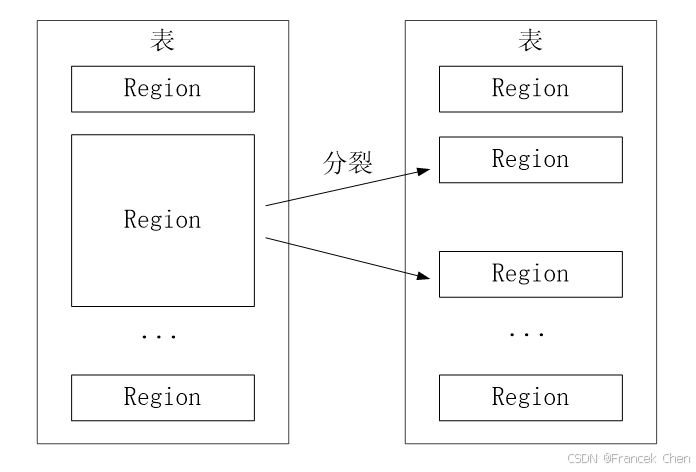
图2 一个Region会分裂成多个新的Region
每个 Region 的默认大小是 100~200 MB,是 HBase中负载均衡和数据分发的基本单位。Master 主服务器会把不同的 Region 分配到不同的 Region 服务器上(见图3),但是同一个 Region 不会被拆分到多个 Region 服务器上。每个 Region 服务器负责管理一个 Region 集合,通常在每个 Region服务器上会放置 10~1000 个 Region。
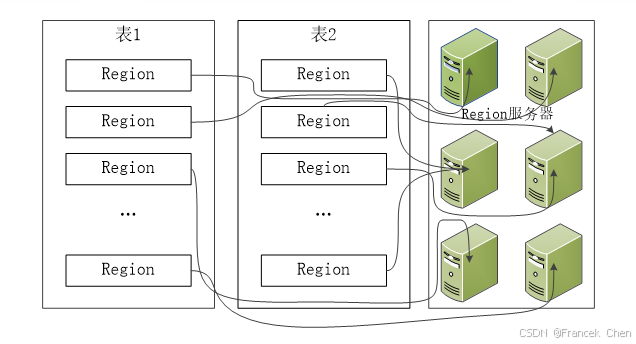
图3 不同的Region可以分布在不同的Region服务器上
三、Region的定位
一个 HBase 的表可能非常庞大,会被分裂成很多个 Region,这些 Region 可被分发到不同的 Region 服务器上。因此,必须设计相应的 Region 定位机制,保证客户端知道到可以在哪里找到自己所需要的数据。
- 元数据表,又名 .META. 表,存储了 Region 和 Region 服务器的映射关系,当 HBase 表很大时,.META. 表也会被分裂成多个 Region。
- 根数据表,又名 -ROOT- 表,记录所有元数据的具体位置。
- -ROOT- 表只有唯一一个 Region,名字是在程序中被写死的。
- Zookeeper 文件记录了 -ROOT- 表的位置。
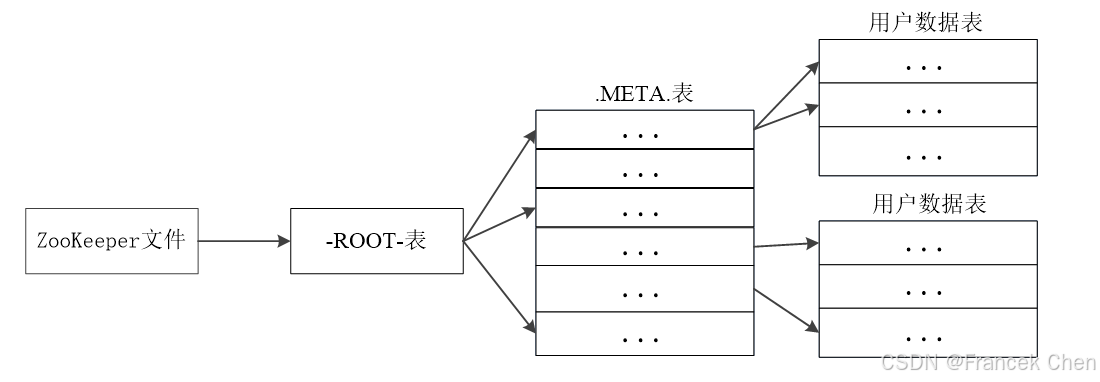
图4 HBase的三层结构
表1 HBase三层结构中各层次的名称和作用
| 层次 | 名称 | 作用 |
|---|---|---|
| 第一层 | Zookeeper文件 | 记录了-ROOT-表的位置信息 |
| 第二层 | -ROOT-表 | 记录了.META.表的Region位置信息,-ROOT-表只能有一个Region。通过-ROOT-表,就可以访问.META.表中的数据 |
| 第三层 | .META.表 | 记录了用户数据表的Region位置信息,.META.表可以有多个Region,保存了HBase中所有用户数据表的Region位置信息 |
为了加快访问速度,.META. 表的全部 Region 都会被保存在内存中。假设 .META. 表的每行(一个映射条目)在内存中大约占用 1 KB,并且每个 Region 限制为 128 MB,那么,上面的三层结构可以保存的用户数据表的 Region 数目的计算方法是:(-ROOT- 表能够寻址的 .META. 表的 Region 个数)×(每个 .META. 表的 Region 可以寻址的用户数据表的 Region 个数)。一个 -ROOT- 表最多只能有一个 Region,也就是最多只能有 128 MB,按照每行(一个映射条目)占用 1 KB 内存计算,128 MB 空间可以容纳 128 MB/1 KB=217行,也就是说,一个 -ROOT- 表可以寻址 217 个.META. 表的 Region。同理,每个 .META. 表的 Region 可以寻址的用户数据表的 Region 数目是 128 MB/1KB=217。最终,三层结构可以保存的 Region 数目是 (128 MB/1 KB)×(128 MB/1 KB) = 234个 Region。可以看出,这种数量已经可以满足实际应用中的用户数据存储需求。
客户端访问用户数据之前,需要首先访问 ZooKeeper,获取 -ROOT- 表的位置信息,然后访问 -ROOT- 表,获得 .META. 表的信息,接着访问 .META. 表,找到所需的 Region 具体位于哪个 Region 服务器,最后才会到该 Region 服务器读取数据。该过程需要多次网络操作,为了加速寻址过程,一般会在客户端把查询过的位置信息缓存起来,这样以后访问相同的数据时,就可以直接从客户端缓存中获取 Region 的位置信息,而不需要每次都经历一个"三级寻址"过程。需要注意的是,随着 HBase 中表的不断更新,Region 的位置信息可能会发生变化,但是客户端缓存并不会自己检测 Region 位置信息是否失效,而是在需要访问数据时,从缓存中获取 Region 位置信息却发现不存在的时候,才会判断出缓存失效。这时,客户端就需要再次经历上述的"三级寻址"过程,重新获取最新的 Region 位置信息去访问数据,并用最新的 Region 位置信息替换缓存中失效的信息。
当一个客户端从 ZooKeeper 服务器上拿到-ROOT-表的地址以后,就可以通过"三级寻址"找到用户数据表所在的 Region 服务器,并直接访问该 Region 服务器获得数据,没有必要再连接 Master 主服务器。因此,Master 主服务器的负载相对就小了很多。
总结
HBase 有库函数、Master 主服务器、Region 服务器三大功能组件。表按行键分区成 Region,随数据增多会分裂。为定位 Region,设计了三层结构,包括 Zookeeper 文件、-ROOT- 表、.META. 表。客户端先经"三级寻址"找数据位置,为加速会缓存信息,位置变化致缓存失效时再重新寻址。客户端获-ROOT-表地址后可直接访问 Region 服务器,减轻 Master 负载。
欢迎 点赞👍 | 收藏⭐ | 评论✍ | 关注🤗
