目录
[1.1 整体架构](#1.1 整体架构)
[1.2 核心组件说明](#1.2 核心组件说明)
[2.1 状态机设计](#2.1 状态机设计)
[2.2 HttpContext------状态机类具体实现](#2.2 HttpContext——状态机类具体实现)
四、HttpRequest/HttpResponse类------HTTP请求和响应封装类
五、HttpServer类------Http服务器的核心类
[六、总结HTTP 服务器的工作流程](#六、总结HTTP 服务器的工作流程)
前言
作为一名C++后端的开发者,你是否曾对HTTP服务器的实现原理感到好奇?今天我将分享如何从零开始实现一个基于muduo库的高性能服务器。本文涵盖HTTP协议解析、网络编程等核心技术。我们将基于muduo网络库构建服务器,并实现完整的HTTP/1.1协议支持
希望看完能有所收获呀。什么是muduo库以及从0开始实现muduo库,可以看我的另一篇博客:【C++/Linux实战项目】仿muduo库实现高性能Reactor模式TCP服务器(深度解析)
项目源码有需要的可以去我的Gitee上下载,Gitee连接如:HTTP服务器
一、HTTP服务器架构设计
1.1 整体架构
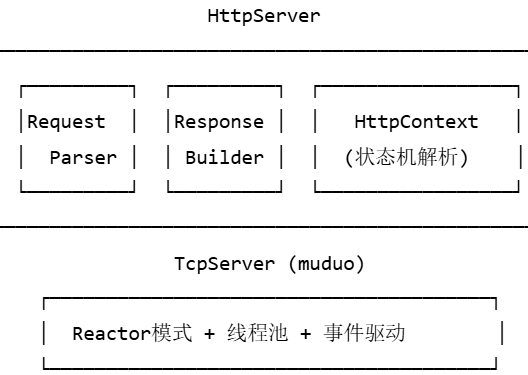
一句话就是四个类,其中主要运行http服务器类,其中把http格式的请求报文封装成HttpRequest类,把http格式的响应报文封装成HttpResponse类、把http格式的请求报文的解析封装成HttpContext类,最终把这三个类写到服务器类中,服务器类主要就是一个muduo服务器对象。
流程是,启动http服务器,浏览器发来http请求,使用HttpContext对象解析http格式的请求,填充HttpRequest对象,然后根据请求方法路由功能分析是请求静态请求(返回html,图片等静态服务器上的文件资源)还是功能性请求(使用服务器上的功能函数,比如登陆功能),通过HttpRequest对象填充HttpResponse对象,最后把httpResPonse响应报文,转换成http响应格式流发送给浏览器(请求方)。
1.2 核心组件说明
总共有五大组件:
|--------------|-----------------|----------------------|
| 组件 | 职责 | 关键特性 |
| HttpServer | 主服务器类,管理路由和请求分发 | 集成 muduo 服务器,处理客户端连接 |
| HttpRequest | HTTP 请求的封装 | 包含方法、路径、头部、参数、正文等 |
| HttpResponse | HTTP 响应的封装 | 包含状态码、头部、正文、重定向等 |
| HttpContext | HTTP 协议解析的状态机 | 按步骤解析请求,支持分片接收 |
| Util | 工具类 | URL 编解码、文件操作、路径验证等 |
二、HTTP协议解析实现
2.1 状态机设计
HTTP请求解析采用状态机模式,分为五个阶段:
cpp
typedef enum{
RECV_HTTP_ERROR,
RECV_HTTP_LINE,
RECV_HTTP_HEAD,
RECV_HTTP_BODY,
RECV_HTTP_OVER
}HttpRecvStatu;为什么使用状态机呢,目的是:把负责的HTTP请求报文的解析,拆成按"转态+规则转移"的简单逻辑,也就是说把负责的解析分成一个一个的转态,按步骤来一步一步的解析,这样的模式尤其适合HTTP请求(请求行、请求头部、空行、正文)、协议解析这类数据分批接收、按格式匹配的场景。
各状态含义:
|-----------------|----------------|
| 状态 | 描述 |
| RECV_HTTP_ERROR | 报文格式出错非HTTP格式 |
| RECV_HTTP_LINE | 服务器请求解析/接收请求行 |
| RECV_HTTP_HEAD | 服务器请求解析/接收请求头部 |
| RECV_HTTP_BODY | 服务器请求解析/接收正文 |
| RECV_HTTP_OVER | 服务器请求解析/接收完毕 |
2.2 HttpContext------状态机类具体实现
HttpContext类------HTTP请求解析类,具体流程是对外接口是RecvHttpRequest函数,在函数体内用状态机按序完成HTTP请求的解析------请求行,请求头部,请求正文。具体如下:
cpp
#define MAX_LINE 8192 //自定义一行的最长长度
class HttpContext{
private:
int _resp_statu; //响应状态码
HttpRecvStatu _recv_statu; //当前接收以及解析的阶段状态
HttpRequest _request; //已经解析得到的请求信息
private:
//参数分析的时候要注意Url参数的解码的操作!!!
bool ParseHttpLine(const std::string& line){
std::smatch matches;
std::regex e("(GET|HEAD|POST|PUT|DELETE) ([^?]*)(?:\\?(.*))? (HTTP/1\\.[01])(?:\n|\r\n)?",std::regex::icase);//icase忽视大小写
bool ret = std::regex_match(line,matches,e);
if(!ret){
_recv_statu = RECV_HTTP_ERROR;
_resp_statu = 400;
return false;
}
//赋值的时候转换成大写就行了。用函数transform
_request._method = matches[1];
std::transform(_request._method.begin(),_request._method.end(),_request._method.begin(),::toupper);
_request._path = Util::UrlDecode(matches[2],false);
_request._version = matches[4];
std::vector<std::string> query_string_arry;
std::string query_string =matches[3];
Util::Split(query_string,"&",&query_string_arry);
for(auto& s:query_string_arry){
size_t pos = s.find("=");
if(pos == std::string::npos){
_recv_statu = RECV_HTTP_ERROR;
_resp_statu = 400;
return false;
}
std::string key = Util::UrlDecode(s.substr(0,pos),true);
std::string val = Util::UrlDecode(s.substr(pos+1),true);
_request.SetParam(key,val);
}
return true;
}
bool ParseHttpHead(std::string& line){
//要先把换行处理掉
if(line.back() == '\n')line.pop_back();
if(line.back() == '\r')line.pop_back();
size_t pos = line.find(": ");
if(pos == std::string::npos){
_recv_statu = RECV_HTTP_ERROR;
_resp_statu = 400;
return false;
}
std::string key = line.substr(0,pos);
std::string val = line.substr(pos+2);
_request.SetHeader(key,val);
return true;
}
bool RecvHttpLine(Buffer* buf){
if(_recv_statu != RECV_HTTP_LINE)return false;
//1.获取一行数据
std::string line = buf->GetLineAndPop();
//2.需要考虑的一些要素:缓冲区中的数据不足一行,获取的一行数据超大
if(line.size() == 0){
//没有内容缓冲区数据不足一行,则需要判断可读数据长度,如果很长不足一行,这是有问题的
if(buf->ReadAbleSize() > MAX_LINE ){
_recv_statu = RECV_HTTP_ERROR;
_resp_statu = 414;//414是URI TOO LONG的状态码
return false;
}
//这里代表没有超过我们规定的最长行那么久接着接收
return true;
}
else if(line.size() > MAX_LINE ){
_recv_statu = RECV_HTTP_ERROR;
_resp_statu = 414;//414是URI TOO LONG的状态码
return false;
}
bool ret = ParseHttpLine(line);
if(!ret)return false;
_recv_statu = RECV_HTTP_HEAD;
return true;
}
bool RecvHttpHead(Buffer* buf){
if(_recv_statu != RECV_HTTP_HEAD)return false;
//一行一行取出数据,直到遇到空行为止,头部的格式 key: val\r\nkey: val\r\n
while(1){
std::string line = buf->GetLineAndPop();
//2.需要考虑的一些要素:缓冲区中的数据不足一行,获取的一行数据超大
if(line.size() == 0){
//没有内容缓冲区数据不足一行,则需要判断可读数据长度,如果很长不足一行,这是有问题的
if(buf->ReadAbleSize() > MAX_LINE){
_recv_statu = RECV_HTTP_ERROR;
_resp_statu = 414;//414是URI TOO LONG的状态码
return false;
}
//这里代表没有超过我们规定的最长行那么久接着接收
return true;
}
else if(line.size() > MAX_LINE){
_recv_statu = RECV_HTTP_ERROR;
_resp_statu = 414;//414是URI TOO LONG的状态码
return false;
}
//进行解析
if(line == "\n" || line == "\r\n")break;//头部的结束
bool ret = ParseHttpHead(line);
if(!ret)return false;
}
_recv_statu = RECV_HTTP_BODY;
return true;
}
bool RecvHttpBody(Buffer* buf){
if(_recv_statu != RECV_HTTP_BODY)return false;
//1.获取正文长度
size_t content_length = _request.ContentLength();
if(content_length == 0){
//没有正文,则请求接收解析完毕
_recv_statu = RECV_HTTP_OVER;
return true;
}
//2.当前已经接收了多少正文
size_t real_len = content_length - _request._body.size();//实际所需的长度
//3.接收正文放到body中,同时要考虑当前缓冲区的数据,是否是全部的正文
//多次tcp报文的情况下
if(buf->ReadAbleSize() >= real_len){
//足够了
_request._body.append(buf->ReadPosition(),(real_len));
buf->MoveReadOffset(real_len);
_recv_statu = RECV_HTTP_OVER;
return true;
}
//不足,只需要取出来就行了
_request._body.append(buf->ReadPosition(),(real_len));
return true;
}
public:
HttpContext():_resp_statu(200),_recv_statu(RECV_HTTP_LINE){}
void Reset(){
_resp_statu=200;
_recv_statu=RECV_HTTP_LINE;
_request.Reset();
}
int RespStatu(){return _resp_statu;}
HttpRecvStatu RecvStatu(){return _recv_statu;}
HttpRequest& Request(){return _request;}
void RecvHttpRequest(Buffer* buf){
switch(_recv_statu){
//这里不要break,因为每一步都需要只是按需进行
case RECV_HTTP_LINE: RecvHttpLine(buf);
case RECV_HTTP_HEAD: RecvHttpHead(buf);
case RECV_HTTP_BODY: RecvHttpBody(buf);
}
return ;
}//接收并解析HTTP请求
};在我的HttpServer类中只要调用RecvHttpRequest函数,就会完成队HTTP的解析,并填充HttpContext类中私有成员HttpRequest对象。
具体解析部分就是按照HTTP请求格式来解析,如下:
|----------|--------------------------------------|--------------------------------------------------------------------------------------------|
| HTTP格式 | 具体内容 | 举例 |
| 请求行(必选) | 请求方法 + 空格 + 请求 URL + 空格 + 协议版本\r\n | POST /api/user HTTP/1.1\r\n |
| 请求头部(必选) | 每行为「头字段名:头字段值」格式,行尾固定\r\n | Content-Length: 30\r\n Connection: keep-alive\r\n Accept: /\r\n |
| 空行(必选) | 仅由\r\n组成,是请求头部和请求正文的唯一分隔标记 | \r\n |
| 请求正文(可选) | 无固定格式,完全由请求头部的Content-Type声明解析规则 | {"name":"张三","age":20,"sex":"男"} username=zhangsan&password=123456 hello, my http server! |
三、Util类------底层工具类
Util的作用是负责:URL的编码解码、向文件读写数据、字符串分隔(适配HTTP报文)、转态响应码获取、获取文件mime拓展名、判断是否为文件/目录、判断文件是否合法。这个函数功能的封装。
cpp
class Util{
public:
//字符串分隔函数
static size_t Split(const std::string& src,const std::string& sep,std::vector<std::string> *arry){
size_t offset=0;
while(offset<src.size()){
size_t pos = src.find(sep,offset);
if(pos == std::string::npos){
//没有找到分隔符
arry->push_back(src.substr(offset));
return arry->size();
}
if(pos == offset){
offset = pos + sep.size();
continue;
}
arry->push_back(src.substr(offset,pos-offset));
offset = pos + sep.size();
}
return arry->size();
}
//读取文件内容,将读取的内容放到一个Buffer中
// static bool ReadFile(const std::string& filename,Buffer* buffer){//这有一个坏处read不支持Buffer只支持char*,这样会有double空间浪费,因为还要中间变量存储。下面直接优化
static bool ReadFile(const std::string& filename,std::string* buf){
//这里用二进制打开时为了什么------1.为了不遇到\r\n就直接转移成回车换行。2.为了音视屏和图片可以发送和接收
std::ifstream ifs(filename,std::ios::binary);
if(ifs.is_open() == false){
ERR_LOG("打开 %s 文件失败",filename.c_str());
return false;
}
size_t fsize=0;
//把
ifs.seekg(0,ifs.end);
//获取到当前指针位置,也就是开头到当前为止的文件字节数
fsize=ifs.tellg();
ifs.seekg(0,ifs.beg);
buf->resize(fsize);
//下面也可以用.data()函数------C++11及以上返回char*的函数c_str()是返回const char*
ifs.read(&(*buf)[0],fsize);
// 偏移量off是正整数:向文件末尾方向(向后)移;
// 偏移量off是负整数:向文件开头方向(向前)移(仅dir为ios::cur/ios::end时可用);
// 偏移量off是0:不偏移,直接定位到dir这个原点本身。
if(ifs.good() == false){
ERR_LOG("读 %s 文件失败",filename.c_str());
ifs.close();
return false;
}
ifs.close();
return true;
}
//向文件写入数据
static bool WriteFile(const std::string& filename,const std::string& buf){
//现在只是一个壳子作为测试用trunc是合理的,但是作为http服务器应该保存客户端信息用app追加更好,所以这只是用来测试我的muduo服务器的一个样例
std::ofstream ofs(filename,std::ios::binary | std::ios::trunc);//trunc清零原有数据。
if(ofs.is_open() == false){
ERR_LOG("打开 %s 文件失败",filename.c_str());
return false;
}
ofs.write(buf.c_str(),buf.size());//这里write可以用buf.c_str()是因为c.str()返回一个const char*,write接受一个const char*
if(ofs.good() == false){
ERR_LOG("写 %s 文件失败",filename.c_str());
ofs.close();
return false;
}
ofs.close();
return true;
}
//URL编码------有个规定path路径里面空格转换成正常编码,但是在参数里面要转化成+------目的是让空格这种 "非法字符" 能在 URL 中安全传输,同时兼顾解析效率和历史兼容性
// 也就是说+本身是合法的,但是为了将空格符号原本的%20替换成一个字符的+,所以才把参数中的+用url编码来表示,这是因为空格符的评率远高于+号的评率
static std::string UrlEncode(const std::string& url, bool convert_space_to_plus){
std::string res;
for(auto&c: url){
if(c == '.' || c == '-' || c == '_' || c == '~' || isalnum(c)){
res+=c;
continue;
}
//在参数中的空格转化为+,在路径中的空格转化成%20---URL正常编码
if(c == ' ' && convert_space_to_plus){
res+='+';
continue;
}
char tmp[4]={0};
//snprintf是sprintf的更加安全版本控制了长度,没有溢出风险。
//下面是转成url编码格式,直接使用ASIIC码值隐式转换了
snprintf(tmp,sizeof(tmp),"%%%02X",c);
res+=tmp;
}
return res;
}
//URL解码
//辅助函数------字符变数字。但为什么返回值是char呢因为数字是0-10二进制最多只占4位用一个8bit也就是char一字节就够了吗,而且我的目的是变成ASIIC码值,我都用char来存储虽然我二进制是数值,但是我char的字面体现确实ASIIC码形式。
static char HEXTOI(char c){
if(c >= '0' && c <= '9'){
return c - '0';
}else if(c >= 'a' && c <= 'z'){
return c - 'a' + 10;
}else if(c >= 'A' && c <= 'Z'){
return c - 'A' + 10;
}
return -1;
}
//真正的解码函数convert_space_to_plus------是参数时的意思query
static std::string UrlDecode(const std::string& url, bool convert_space_to_plus){
std::string res;
for(int i=0;i<url.size();++i){
if(url[i]=='%'){
//防止越界
if(i + 2 >= len) {
res += url[i];
continue;
}
char v1 = HEXTOI(url[i+1]);
char v2 = HEXTOI(url[i+2]);
// char v = (v1 << 4) +v2;
// res += v;
// i += 2;
// continue;
// 合法性判断:v1/v2必须是0-15的合法值
if (v1 >= 0 && v1 <= 15 && v2 >=0 && v2 <=15) {
// 拼接为单个字节:高4位左移4位 + 低4位 = 0-255的ASCII码值
unsigned char v = (static_cast<unsigned char>(v1) << 4) | v2;//无符号的原因是可能会返回-1
res += static_cast<char>(v); // 安全的转转为char,兼容有符号/无符号char
i += 2; // 跳过后续2个16进制字符
continue;
}
// 非法%XX,直接保留%(避免乱码)------在后续请求中会因为请求无效返回错误
res += url[i];
continue;
}
if(url[i] == '+' && convert_space_to_plus){
res+=' ';
continue;
}
res+=url[i];
}
return res;
}
//响应转态码的描述信息获取
static std::string StatuDesc(int statu){
auto it = _statu_msg.find(statu);
if(it !=_statu_msg.end()) return it->second;
return "Unknow";
}
//根据文件后缀名获取文件mime,Extension------拓展名
//静态资源获取
static std::string ExtMime(const std::string& filename){
//a.b.txt------只获取到.txt扩展名
size_t pos = filename.find_last_of('.');//string中自带的函数从后找找第一个字符
if(pos == std::string::npos){
return "application/octet-stream";//没找到就返回二进制流
}
//根据扩展名,获取mime
std::string ext = filename.substr(pos);
auto it = _mine_msg.find(ext);
if(it == _mine_msg.end()){
return "application/octet-stream";
}
return it->second;
}
//判断一个文件是否是一个目录
static bool IsDirectory(const std::string& filename){
struct stat st;
int ret = stat(filename.c_str(),&st);
if(ret<0){
return false;
}
return S_ISDIR(st.st_mode);
}
//判断一个文件是否是一个普通文件
static bool IsRegular(const std::string& filename){
//stat中包含了文件/目录属性------类型、大小、创建时间、权限等------是文件属性结构体
struct stat st;
int ret = stat(filename.c_str(),&st);
if(ret<0){
return false;
}
//st_mode------标识文件类型和访问权限
return S_ISREG(st.st_mode);//是系统提供的宏函数
}
//http请求的资源路径是否有效
static bool ValidPath(const std::string& path){
std::vector<std::string> subdir;
Split(path,"/",&subdir);
int level=0;
for(auto &dir :subdir){
if(dir == ".."){
level--;
if(level < 0 )return false;//任意一层走出相对根目录,就认为有问题,因为即使后面能回来,但是也有回不来的可能啊,为了安全防止用户的恶意输入我就直接切死。
continue;
}
level++;
}
return true;
}
};四、HttpRequest/HttpResponse类------HTTP请求和响应封装类
这两个类,没有额外的功能就是按照HTTP的请求格式和响应格式的封装。如下:
cpp
//http的请求字段
class HttpRequest{
public:
std::string _method; //请求方法
std::string _path; //资源路径
std::string _version; //协议版本
std::string _body; //请求正文
std::smatch _matches; //资源路径的正则提取数据
std::unordered_map<std::string,std::string> _headers; //头部字段
std::unordered_map<std::string,std::string> _params; //查询(参数)字符串
public:
HttpRequest():_version("HTTP/1.1"){}
//重置,每次上下文请求处理完了就要重置,清空
void Reset(){
_method.clear();
_path.clear();
_body.clear();
_headers.clear();
_params.clear();
_version="HTTP/1.1";//默认1.1版本
//smatch没有clear成员函数,只能用swap空match来交换,然后局部的match出作用域自动调用析构函数。
std::smatch match;
_matches.swap(match);
}
//插入头部字段
void SetHeader(const std::string& key, const std::string& val){
_headers.insert(std::make_pair(key,val));
}
//判断是否存在指定头部字段
bool HashHeader(const std::string& key)const{
auto it = _headers.find(key);
if (it != _headers.end()) {
return true;
}
return false;
}
//获取指定头部字段的值
std::string GetHeader(const std::string& key)const{
auto it = _headers.find(key);
if (it != _headers.end()) {
return it->second; // 迭代器有效,安全取值
}
return ""; // key不存在,返回空字符串
}
//插入查询(参数)字符串
void SetParam(std::string& key,std::string& val){
_params.insert(std::make_pair(key,val));
}
//判断是否有某个指定的查询(参数)字符串
bool HashParam(std::string& key)const{
auto it = _params.find(key);
if (it != _params.end()) {
return true;
}
return false;
}
//获取指定的查询(参数)字符串
std::string GetParam(const std::string& key)const{
auto it = _params.find(key);
if (it != _params.end()) {
return it->second; // 迭代器有效,安全取值
}
return ""; // key不存在,返回空字符串
}
//获取正文长度
size_t ContentLength(){
//Content-Length:1234\r\n
bool ret = HashHeader("Content-Length");
if(ret == false)return 0;
std::string clen = GetHeader("Content-Length");
return std::stol(clen);//string转长整形
}
//判断是否是短链接------这次通信后是否关闭它
bool Close()const{
//没有Connection字段,或者有Connection但是值是close。则都是短连接,否则就是长连接
if(HashHeader("Connection")==true && GetHeader("Connection") == "keep-alive")return false;
return true;
}
};
//http的回复字段
class HttpResponse{
public:
int _statu;
bool _redirect_flag;//重定向标志
std::string _body;
std::string _redirect_url;
std::unordered_map<std::string, std::string> _headers;
public:
HttpResponse():_redirect_flag(false), _statu(200) {}
HttpResponse(int statu):_redirect_flag(false), _statu(statu) {}
//重置
void Reset(){
_statu = 200;
_redirect_flag = false;
_body.clear();
_redirect_url.clear();
_headers.clear();
}
//插入头部字段
void SetHeader(const std::string& key, const std::string& val){
_headers.insert(std::make_pair(key,val));
}
//判断是否存在指定头部字段
bool HashHeader(const std::string& key)const{
auto it = _headers.find(key);
if (it != _headers.end()) {
return true;
}
return false;
}
//获取指定头部字段的值
std::string GetHeader(const std::string& key)const{
auto it = _headers.find(key);
if (it != _headers.end()) {
return it->second;
}
return "";
}
//设置消息体
void SetContent(const std::string& body,const std::string& type){
_body = body;
SetHeader("Content-Type",type);
}
//设置重定向标识
void SetRedirect(std::string& url,int statu = 302){
_statu = statu;
_redirect_flag = true;
_redirect_url = url;
}
//判断是否是短链接------这次通信后是否关闭它
bool Close()const{
//没有Connection字段,或者有Connection但是值是close。则都是短连接,否则就是长连接
if(HashHeader("Connection")==true && GetHeader("Connection") == "keep-alive")return false;
return true;
}
};五、HttpServer类------Http服务器的核心类
HttpServer中的私有成员函数有:4个基础的请求方法功能:GET、POST、PUT、DELETE请求封装的路由函数使用Handlers类型,具体如下:
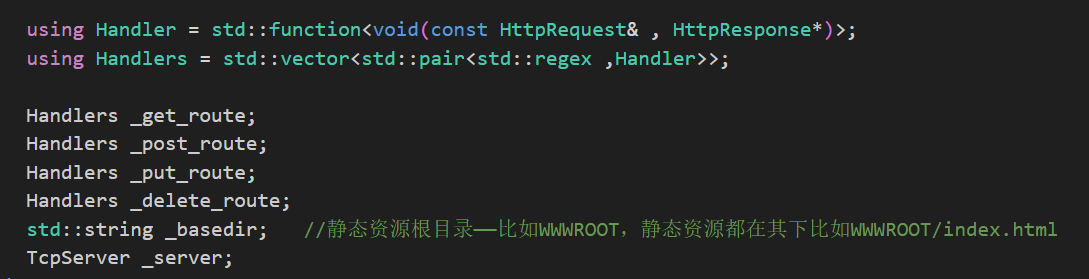
其中regex类时四个请求方法的请求参数。
成员函数有很多都是来分析处理请求的,其中主要的核心函数有OnMessage、Onconnected、Route。这三个函数,具体如下:
|-------------|-----------------------------------------------------------------------------------|
| 函数名 | 作用 |
| OnMessage | 注册到muduo服务器中的OnMessage回调事件中 当浏览器发送消息给服务器时调用回调处理HTTP请求。 |
| Onconnected | 注册到muduo服务器中的OnMessage回调事件中 当浏览器建立连接时,给连接初始化协议报文 |
| Route | HTTP服务器中使用 当浏览器发来请求时,调用Route函数,在Route函数中进行功能分发,判断是哪种请求。 静态请求返回静态资源,功能性请求调用服务器中的函数 |
[HttpServer中的核心函数]
OnMessage在HttpServer类的构造函数中,注册到TcpServer也就是我的muduo服务器的OnMessage回调函数中,Onconnected也是,数据一来我就会自动处理。这样就是一个完整的HTTP服务器的流程。
六、总结HTTP 服务器的工作流程
我们再来完整的总结一下从启动到响应的完整流程:
1.启动服务器 :调用 HttpServer::Listen启动 muduo 事件循环,监听指定端口。
2.连接建立 :客户端发起连接,触发 OnConnected 回调,为连接创建 **HttpContext**对象。
3.请求到达 :客户端发送 HTTP 请求报文,触发 **OnMessage**回调。
4.解析请求 :通过 HttpContext::RecvHttpRequest 按状态机解析请求,填充 **HttpRequest**对象。
5.路由分发 :调用 **Route()**根据请求方法和路径分发到对应的处理函数。
6.生成响应 :处理函数根据请求填充 **HttpResponse**对象。
7.发送响应 :将**HttpResponse**格式化为 HTTP 响应报文,通过 muduo服务器 发送给客户端。
8.连接管理 :根据 **Connection: keep-alive**头部决定是否关闭连接。
以上就是基于已有的muduo高性能服务器搭载的HTTP服务器。希望对你有帮助。