数据结构-图
🌟🌟hello,各位读者大大们你们好呀🌟🌟
🚀🚀系列专栏:【数据结构的学习】
📝📝本篇内容:图的基本概念;图的存储;邻接矩阵;邻接表;图的遍历;最小生成树;Kruskal算法;Prim算法
⬆⬆⬆⬆上一篇:数据结构-并查集
💖💖作者简介:轩情吖,请多多指教(>> •̀֊•́ ) ̖́-
1.图的基本概念
图是由顶点集合及顶点间的关系组成的一种数据结构:G = (V, E)
(x, y)表示x到y的一条双向通路,即(x, y)是无方向的;Path(x, y)表示从x到y的一条单向通路,即Path(x, y)是有方向的。
顶点和边 :图中结点称为顶点,第i个顶点记作vi。两个顶点vi和vj相关联称作顶点vi和顶点vj之间有一条边,图中的第k条边记作ek,ek = (vi,vj)或<vi,vj>
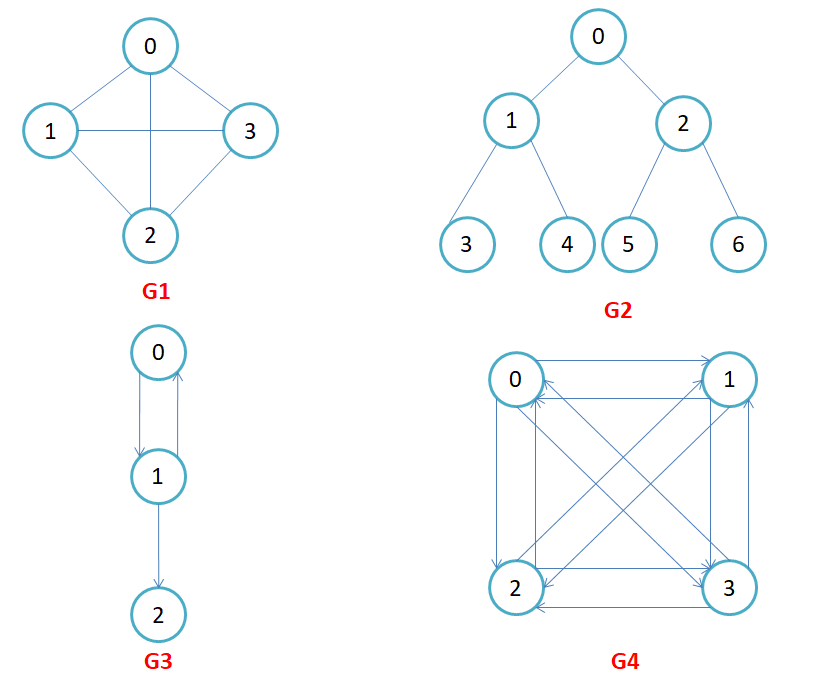
有向图和无向图 :在有向图中,顶点对<x, y>是有序的,顶点对<x,y>称为顶点x到顶点y的一条边(弧),<x, y>和<y, x>是两条不同的边,比如下图G3和G4为有向图。在无向图中,顶点对(x, y)是无序的,顶点对(x,y)称为顶点x和顶点y相关联的一条边,这条边没有特定方向,(x, y)和(y,x)是同一条边,比如下图G1和G2为无向图。注意:无向边(x, y)等于有向边<x, y>和<y, x>。
完全图 :在有n个顶点的无向图中,若有n * (n-1)/2条边,即任意两个顶点之间有且仅有一条边,则称此图为无向完全图,比如上图G1;在n个顶点的有向图中,若有n * (n-1)条边,即任意两个顶点之间有且仅有方向相反的边,则称此图为有向完全图,比如上图G4。
邻接顶点 :在无向图中G中,若(u, v)是E(G)中的一条边,则称u和v互为邻接顶点,并称边(u,v)依附于顶点u和v;在有向图G中,若<u, v>是E(G)中的一条边,则称顶点u邻接到v,顶点v邻接自顶点u,并称边<u, v>与顶点u和顶点v相关联。
顶点的度 :顶点v的度是指与它相关联的边的条数,记作deg(v)。在有向图中,顶点的度等于该顶点的入度与出度之和,其中顶点v的入度是以v为终点的有向边的条数,记作indev(v);顶点v的出度是以v为起始点的有向边的条数,记作outdev(v)。因此:dev(v) = indev(v) + outdev(v)。注意:对于无向图,顶点的度等于该顶点的入度和出度,即dev(v) = indev(v) = outdev(v)。
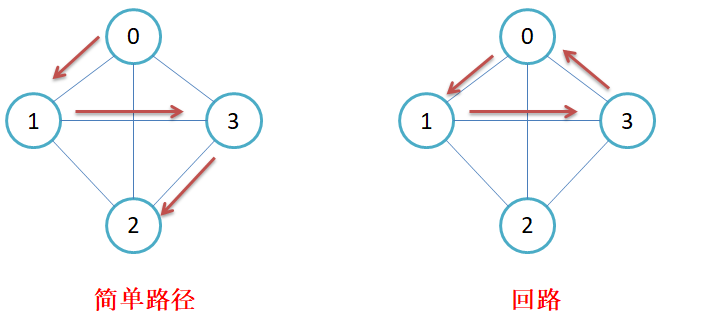
路径 :在图G = (V, E)中,若从顶点vi出发有一组边使其可到达顶点vj,则称顶点vi到顶点vj的顶点序列为从顶点vi到顶点vj的路径。
路径长度 :对于不带权的图,一条路径的路径长度是指该路径上的边的条数;对于带权的图,一条路径的路径长度是指该路径上各个边权值的总和。
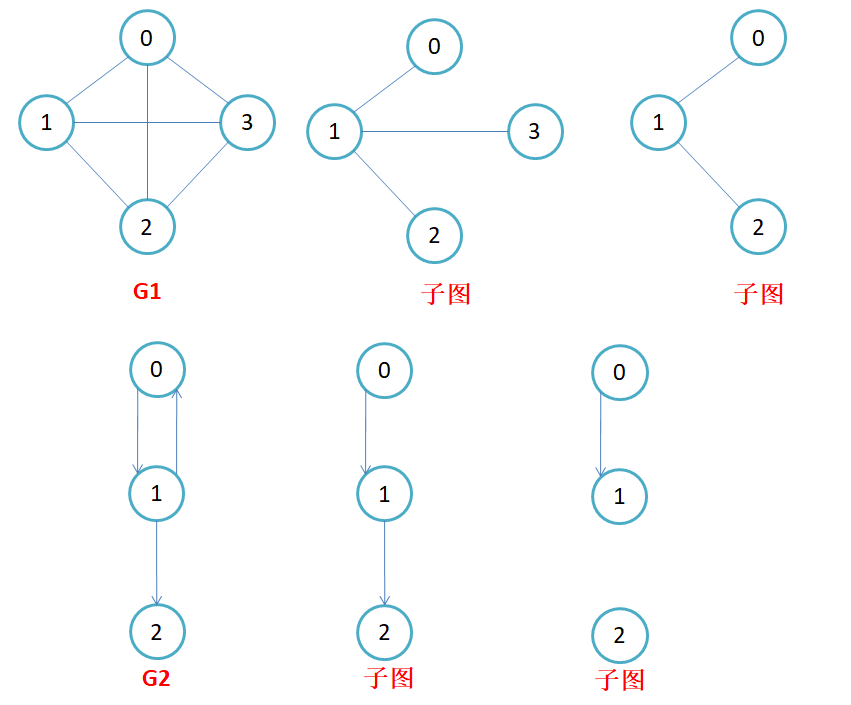
子图 :设图G = {V, E}和图G1 = {V1,E1},若V1属于V且E1属于E,则称G1是G的子图。
连通图 :在无向图中,若从顶点v1到顶点v2有路径,则称顶点v1与顶点v2是连通的。如果图中任意一对顶点都是连通的,则称此图为连通图。
强连通图 :在有向图中,若在每一对顶点vi和vj之间都存在一条从vi到vj的路径,也存在一条从vj到vi的路径,则称此图是强连通图。
生成树 :一个连通图的最小连通子图称作该图的生成树。有n个顶点的连通图的生成树有n个顶点和n-1条边。生成树就是也就是最少边(n-1条边)连通起来
最小生成树 :构成的生成树的这些边加起来权值是最小的,最小的成本让这N个顶点连通
树和图的区别 :树是一种特殊的无环连通图,但是图不一定是树;树关注的是结点中存的值,而图关注的是顶点及边的权值。无向图可以想象成我们的微信和QQ关系,两个人是好友就代表着我有你的好友,你有我的好友;而微博和抖音可以想象成我们的有向图,我关注了你,你不一定关注我
2.图的存储
在图中,最主要的就是顶点和边的关系,也就是想办法将它们保存起来即可。
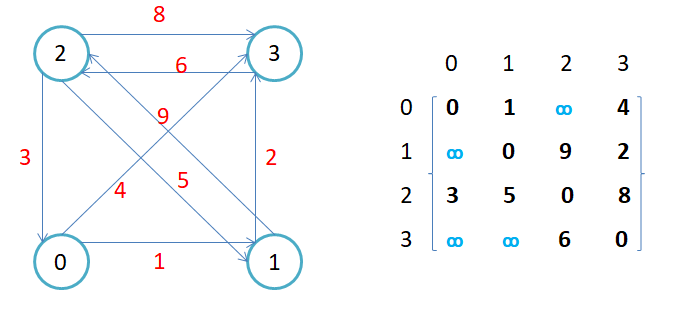
2.1.邻接矩阵
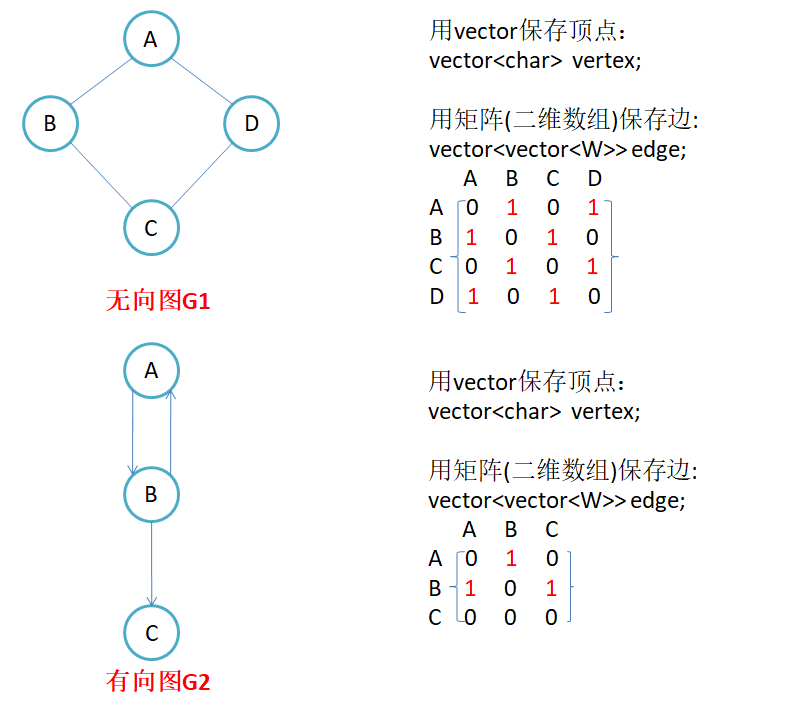
通过一个vector来存储顶点,再使用一个vector<vector>来存储顶点和顶点之间边的情况
无向图的邻接矩阵是对称的,第i行(列)元素之和,就是顶点i的度。有向图的邻接矩阵则不一定是对称的,第i行(列)元素之后就是顶点i 的出(入)度。
如果边带有权值,并且两个节点之间是连通的,上图中的边的关系就用权值代替,如果两个顶点不通,则使用无穷大代替
用邻接矩阵存储图的优点是能够快速知道两个顶点是否连通,并且取到权值,时间复杂度是O(1),并且这种存储方式非常适合稠密图;但是缺点是不方便查找一个顶点链接的所有边,需要把一整行都遍历一遍,时间复杂度是O(N)
cpp
namespace Matrix
{
template<class V,class W, W MAX_W = INT_MAX, bool Direction = false>
class Graph
{
public:
typedef Graph<V, W, INT_MAX, false> Self;
Graph()
{}
Graph(const V* vertexs, int n)
{
//先初始化所有的顶点
//先提前开辟内存
_vertexs.resize(n,V());
for (int i = 0; i < n; i++)
{
_vertexs[i] = vertexs[i];
//建立映射关系
_VIndexMap[vertexs[i]] = i;
}
//初始化邻接矩阵
_matrix.resize(n);
for (auto& m: _matrix)
{
m.resize(n, MAX_W);
}
}
//获取顶点的下标
int GetVertexIndex(const V& v)
{
auto iterator=_VIndexMap.find(v);
if (iterator!=_VIndexMap.end())
{
return iterator->second;
}
else
{
assert(false);
throw invalid_argument("v is not a normal vertex");
}
}
void AddEdge(const V& src, const V& dest, const W& w)
{
int srci = GetVertexIndex(src);
int desti = GetVertexIndex(dest);
_matrix[srci][desti] = w;//边的权值
if (Direction == false)//当图为无向图时,边的关系是相互的
{
_matrix[desti][srci] = w;
}
}
//void Print()
//{
// //打印顶点
// cout << "vertexs:"<<endl;
// for (int i = 0; i < _vertexs.size(); i++)
// {
// cout << "[" <<i<< "]="<<_vertexs[i] << endl;
// }
// cout << endl;
// //打印矩阵
// //先打印矩阵行列表示的内容
// cout << " ";
// for (int i = 0; i < _vertexs.size(); i++)
// {
// cout<< _vertexs[i] << " ";
// }
// cout << endl;
// for (int i = 0; i < _matrix.size(); i++)
// {
// cout << _vertexs[i] << " ";
// for (int j = 0; j < _matrix[i].size(); j++)
// {
// if (_matrix[i][j] == MAX_W)
// {
// cout << "*" << " ";
// }
// else
// {
// cout << _matrix[i][j] << " ";
// }
// }
// cout << endl;
// }
//}
void Print()
{
//打印顶点
cout << "vertexs:" << endl;
for (int i = 0; i < _vertexs.size(); i++)
{
cout << "[" << i << "]=" << _vertexs[i] << endl;
}
cout << endl;
//打印矩阵
//先打印矩阵行列表示的内容
cout << " ";
for (int i = 0; i < _vertexs.size(); i++)
{
printf("%4d", i);
}
cout << endl;
for (int i = 0; i < _matrix.size(); i++)
{
cout << i << " ";
for (int j = 0; j < _matrix[i].size(); j++)
{
if (_matrix[i][j] == MAX_W)
{
printf("%4c", '*');
}
else
{
printf("%4d",_matrix[i][j]);
}
}
cout << endl;
}
}
private:
vector<V> _vertexs;//顶点集合
map<V, int> _VIndexMap;//映射关系,通过顶点找下标
vector<vector<W>> _matrix;//存储边集合的矩阵
};
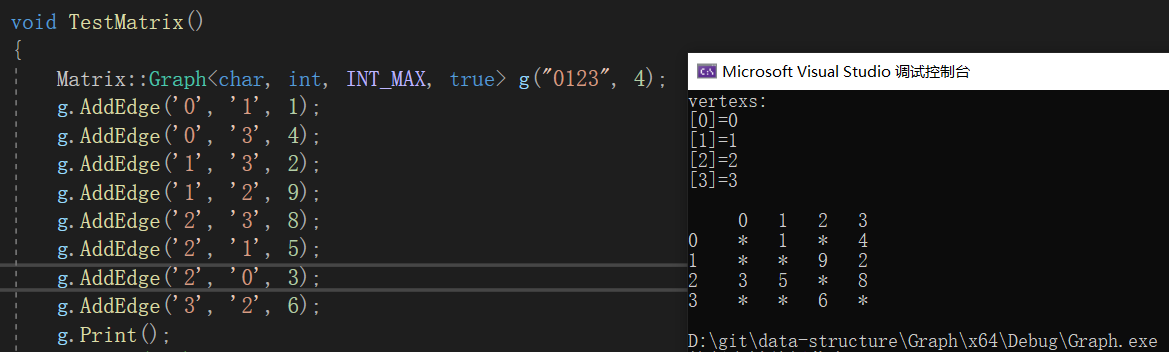
void TestMatrix()
{
/*Matrix::Graph<char, int, INT_MAX, true> g("0123", 4);
g.AddEdge('0', '1', 1);
g.AddEdge('0', '3', 4);
g.AddEdge('1', '3', 2);
g.AddEdge('1', '2', 9);
g.AddEdge('2', '3', 8);
g.AddEdge('2', '1', 5);
g.AddEdge('2', '0', 3);
g.AddEdge('3', '2', 6);
g.Print();*/
}
}
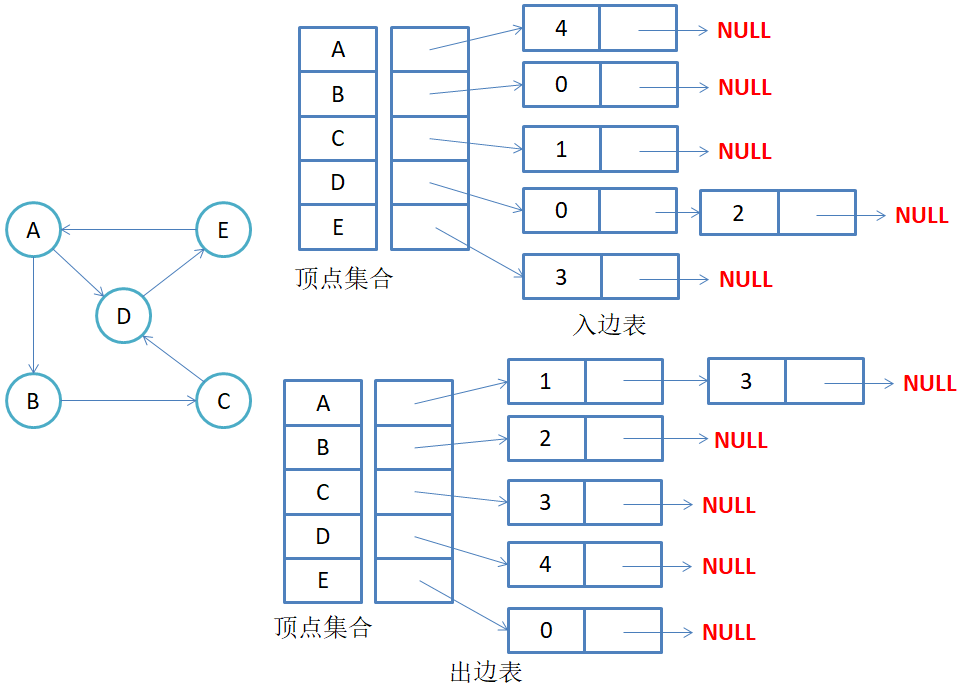
2.2.邻接表
邻接表是使用vector表示顶点的集合,使用链表来表示顶点和边的关系
无向图中同一条边在邻接表中出现了两次。如果想知道顶点vi的度,只需要知道顶点vi边链表集合中结点的数目即可。
有向图中每条边在邻接表中只出现一次,与顶点vi对应的邻接表所含结点的个数,就是该顶点的出度,也称出度表,要得到vi顶点的入度,必须检测其他所有顶点对应的边链表,看有多少边顶点的dst取值是i。
邻接表的优点是适合存储稀疏图,适合查找一个顶点连接出去的边,不适合确定两个顶点是否相连以及它们的权值
下面代码中只实现了有向图的出度情况

cpp
//邻接表
namespace AdjList
{
//边的情况
template<class W>
struct Edge
{
W _w;//权值
int _desti;//目标位置的下标
Edge<W>* _next;
Edge(int desti,W w,Edge<W>* next)
:_desti(desti),
_w(w),
_next(next)
{}
};
template<class V, class W,bool Direction = false>
class Graph
{
public:
Graph(const V* vertexs, int n)
{
//先初始化所有的顶点
//先提前开辟内存
_vertexs.resize(n, V());
for (int i = 0; i < n; i++)
{
_vertexs[i] = vertexs[i];
//建立映射关系
_VIndexMap[vertexs[i]] = i;
}
//初始化邻接表
_AdjTable.resize(n, nullptr);
}
//获取顶点的下标
int GetVertexIndex(const V& v)
{
auto iterator = _VIndexMap.find(v);
if (iterator != _VIndexMap.end())
{
return iterator->second;
}
else
{
assert(false);
throw invalid_argument("v is not a normal vertex");
}
}
void AddEdge(const V& src, const V& dest, const W& w)
{
int srci = GetVertexIndex(src);
int desti = GetVertexIndex(dest);
//创建新边
Edge<W>* newEdge = new Edge<W>(desti,w,_AdjTable[srci]);
//进行链接
_AdjTable[srci] = newEdge;
if (Direction == false)//当图为无向图时,边的关系是相互的
{
Edge<W>* newEdge = new Edge<W>(srci, w, _AdjTable[desti]);
_AdjTable[desti] = newEdge;
}
}
void Print()
{
//打印顶点
cout << "vertexs:" << endl;
for (int i = 0; i < _vertexs.size(); i++)
{
cout << "[" << i << "]=" << _vertexs[i] << endl;
}
cout << endl;
//打印邻接表
for (int i = 0; i < _vertexs.size(); i++)
{
cout << _vertexs[i] << ":";
Edge<W>* cur = _AdjTable[i];
while (cur)
{
cout << "[" << _vertexs[cur->_desti] << ":" << cur->_w << "]->";
cur = cur->_next;
}
cout << "nullptr" << endl;
}
}
private:
vector<V> _vertexs;//顶点集合
map<V, int> _VIndexMap;//映射关系,通过顶点找下标
vector<Edge<W>*> _AdjTable;//邻接表
};
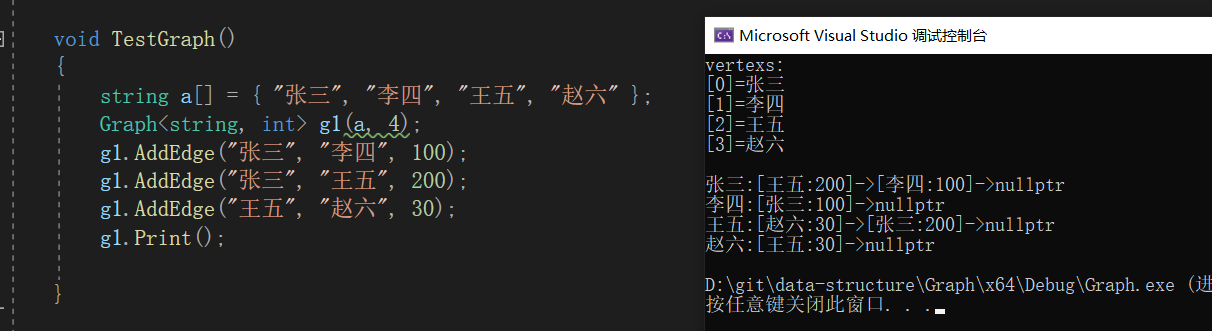
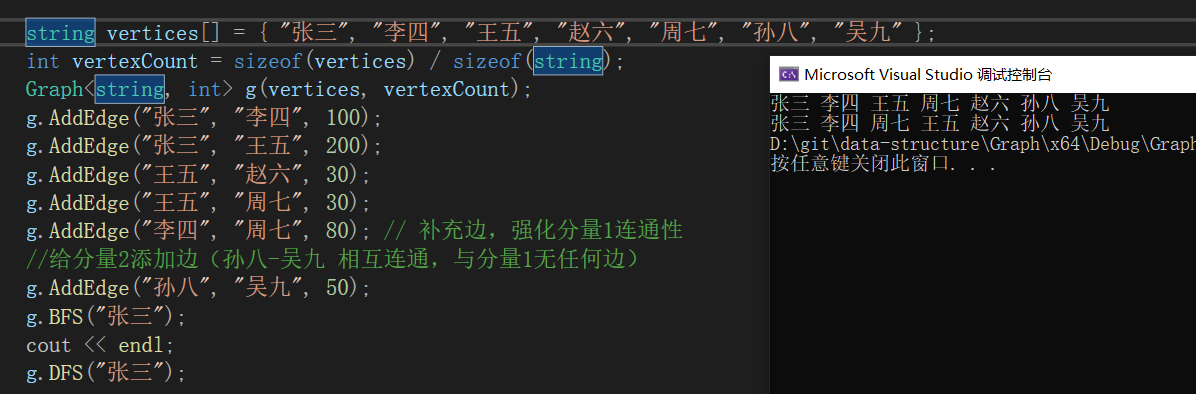
void TestGraph()
{
string a[] = { "张三", "李四", "王五", "赵六" };
Graph<string, int> g1(a, 4);
g1.AddEdge("张三", "李四", 100);
g1.AddEdge("张三", "王五", 200);
g1.AddEdge("王五", "赵六", 30);
g1.Print();
}
}
3.图的遍历
图的遍历方式一共有两种,分别是广度优先遍历和深度优先遍历
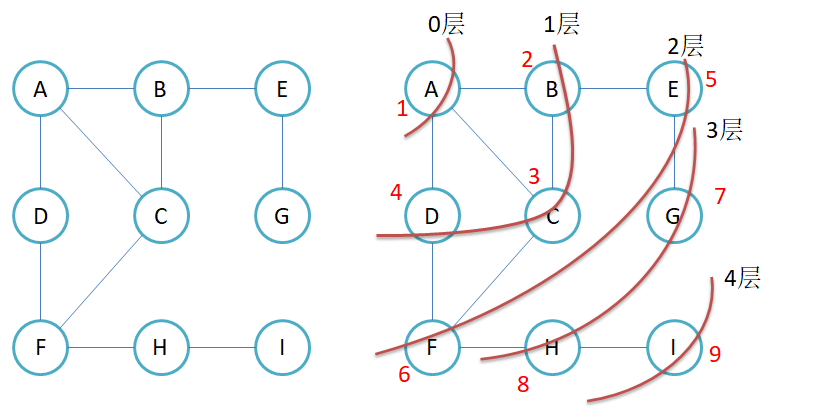
先说广度优先遍历:从起始节点开始,逐层访问所有相邻节点,再依次访问下一层节点。该算法通常借助队列实现,保证按层级顺序访问节点 。在二叉树中,层序遍历就是广度优先遍历
在图中进行广度优先遍历需要先确定从哪一个顶点开始遍历,并且我们需要一个队列和一个标记容器
之所以需要标记容器是因为防止重复顶点进入到队列中。当我们将顶点入队列后就进行标记一下,这样就可以保证当A出的时候将BCD入队列,但当B出的时候只会将E入队列,而不会将AC放入队列
cpp
//广度优先遍历
void _BFS(const V& src, queue<int>& q, vector<bool>& visited)//从一个顶点开始遍历
{
visited.resize(_vertexs.size(), false);//默认是没有标记过的
int index = GetVertexIndex(src);//获取顶点下标
q.push(index);
visited[index] = true;//访问过了就设为true
while (!q.empty())//不为空就一直遍历下去
{
index = q.front();//取队头
q.pop();
cout << _vertexs[index] << " ";
for (int j = 0; j < _vertexs.size(); j++)//继续将后续的顶点入队列
{
if (_matrix[index][j] != MAX_W)
{
if (visited[j] == false)//判断是否已经标记过
{
q.push(j);
visited[j] = true;
}
}
}
}
}
void BFS(const V& src)
{
queue<int> q;//用来存放顶点下标
vector<bool> visited;//标记容器,已经入过队列的就进行设置,保证不会用重复的元素进入队列
_BFS(src,q,visited);
for (int i = 0; i < visited.size(); i++)
{
if (visited[i] ==false)
{
_BFS(_vertexs[i], q, visited);
}
}
}并且还要注意一个点就是遍历的这个图可能不是一个连通的,因此最后需要一个循环来遍历所有的顶点,将没有遍历的顶点进行遍历
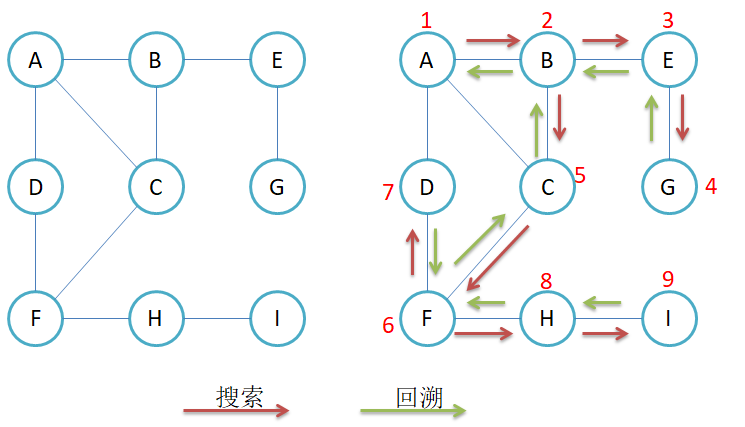
接下来就是深度优先遍历:尽可能深地探索分支,直到无法继续为止,再回溯到上一个节点继续探索其他分支。DFS通常通过递归或显式栈实现 。在二叉树中,前序中序后序就是深度优先遍历
cpp
void _DFS(int index, vector<bool>& visited)
{
cout << _vertexs[index] << " ";
visited[index] = true;//进行标记
for (int i = 0; i < _vertexs.size(); i++)
{
if (_matrix[index][i] != MAX_W&& visited[i] == false)
{
_DFS(i, visited);
}
}
}
//深度优先遍历
void DFS(const V& src)
{
int index=GetVertexIndex(src);
vector<bool> visited;//用来防止重复访问
visited.resize(_vertexs.size(), false);
_DFS(index, visited);
for (int i=0;i<visited.size();i++)
{
if (visited[i]==false)
{
_DFS(i, visited);
}
}
}在深度优先遍历中也是需要有一个标记容器来保证不会进行重复访问,并且也要关注一下不连通图时,也要访问到所有的结点。它的深度优先遍历其实和二叉树一样,需要使用递归来实现的
4.最小生成树
连通图中的每一棵生成树,都是原图的一个极大无环子图,即:从其中删去任何一条边,生成树就不在连通;反之,在其中引入任何一条新边,都会形成一条回路。
若连通图由n个顶点组成,则其生成树必含n个顶点和n-1条边。因此构造最小生成树的准则有三条:
①只能使用图中权值最小的边来构造最小生成树
② 只能使用恰好n-1条边来连接图中的n个顶点
③ 选用的n-1条边不能构成回路
构造最小生成树的方法:Kruskal算法和Prim算法。这两个算法都采用了逐步求解的贪心策略。
贪心算法:是指在问题求解时,总是做出当前看起来最好的选择。也就是说贪心算法做出的不是整体最优的的选择,而是某种意义上的局部最优解。贪心算法不是对所有的问题都能得到整体最优解。
4.1.Kruskal算法
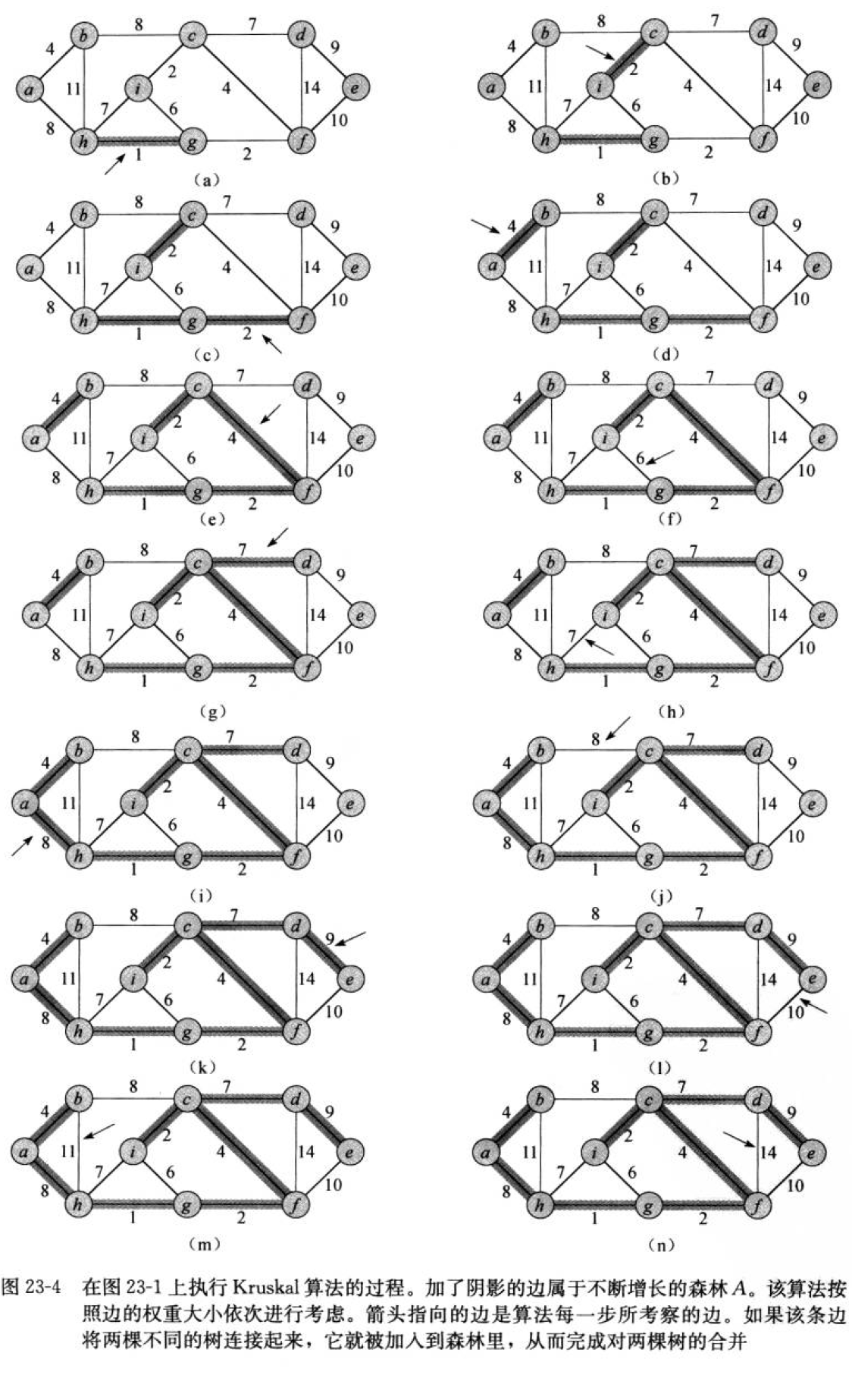
首先构造一个由这n个顶点组成、不含任何边的图G={V,NULL},其中每个顶点自成一个连通分量,其次不断从E中取出权值最小的一条边(若有多条任取其一),若该边的两个顶点来自不同的连通分量,则将此边加入到G中。如此重复,直到所有顶点在同一个连通分量上为止。
核心:每次迭代时,选出一条具有最小权值,且两端点不在同一连通分量上的边(不能构成环),加入生成树。
在查找最小权值路径的过程中,不能出现环,因此我们在编写代码的过程中,需要想办法判别有没有构成环。这个时候就用到了我们之前讲的并查集,将选出的最小权值的边的两个顶点放入到并查集中,在后续的选择过程中,一旦出现有顶点是在同一个集合里面,说明有环,就不能选择。并且我们需要选出最权值最小的边就需要使用到优先级队列。
cpp
//最小生成树算法
W Kruskal(Self& minTree)
{
int size = _vertexs.size();
minTree._vertexs = _vertexs;
minTree._VIndexMap = _VIndexMap;
minTree._matrix.resize(size);
for (int i = 0; i < size; i++)
{
minTree._matrix[i].resize(size,MAX_W);
}
//使用优先级队列来依次选择最小的边
priority_queue<Edge<W>, deque<Edge<W>>, greater<Edge<W>>> pquemin;
for (int i = 0; i < size; i++)
{
for (int j = 0; j < i; j++)//无向图的邻接矩阵是对称的,只取一半就可以了
{
if (_matrix[i][j] != MAX_W)
{
pquemin.push(Edge<W>(i, j, _matrix[i][j]));
}
}
}
int edge_count = 0;//记录边数
UnionFindSet<int> ufs(_vertexs.size());
W totalW = W();
while (!pquemin.empty())
{
Edge<W> e=pquemin.top();//选出权值最小的边
pquemin.pop();
if (!ufs.InSet(e._srci, e._desti))//判断是否出现环
{
cout << _vertexs[e._srci]<< "->" << _vertexs[e._desti] << ":" << e._w << endl;
ufs.Union(e._srci, e._desti);
minTree.AddEdge(_vertexs[e._srci], _vertexs[e._desti],e._w);
totalW += e._w;
edge_count++;//边数+1
}
else
{
cout <<"构成环:" << _vertexs[e._srci] << "->" << _vertexs[e._desti] << ":" << e._w << endl;
}
}
if (edge_count == size - 1)
{
return totalW;
}
else
{
return W();
}
}4.2.Prim算法
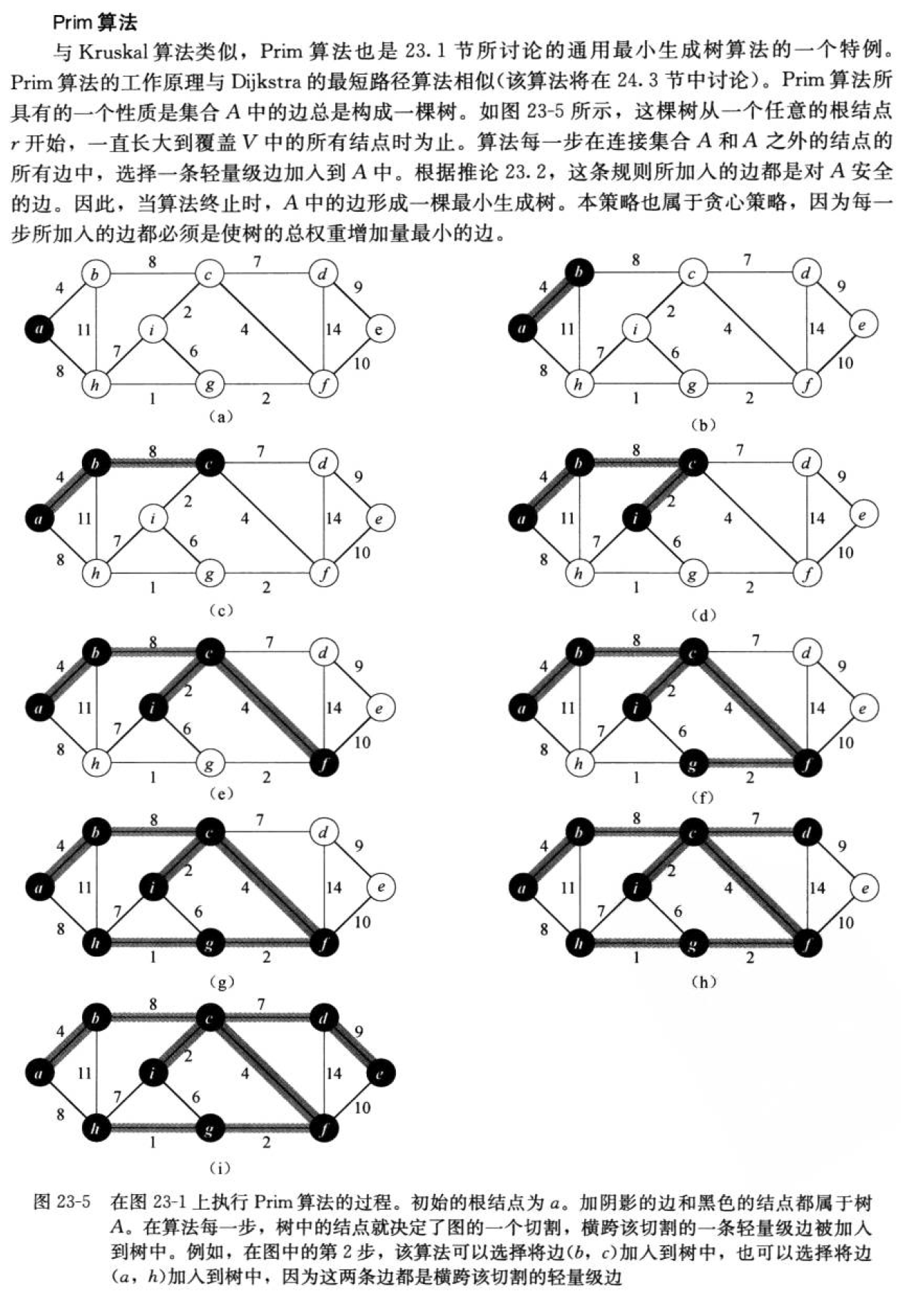
Prim算法简单来说从一个起始顶点出发,每次只选「已连通顶点和未连通顶点之间权重最小的边」,把未连通顶点纳入连通集合,重复直到所有顶点都连通 ------ 最终形成无环、总权重最小的生成树。
在实现的Prim算法中,使用了vector X 和 vector Y,它们是一对互补的顶点状态标记容器,核心作用是「跟踪每个顶点是否已加入最小生成树(MST)」------ 本质是用两个数组直观区分「已选顶点集合」和「未选顶点集合」,配合算法流程实现「无环连通」的核心目标。
cpp
//最小生成树算法
W Prim(Self& minTree, const V& src)
{
int srci =GetVertexIndex(src);//找到开始结点的下标
//先对最小生成树进行基本初始化
minTree._vertexs = _vertexs;
minTree._VIndexMap = _VIndexMap;
int n = _matrix.size();
minTree._matrix.resize(n);
for (int i = 0; i < n; i++)
{
minTree._matrix[i].resize(n, MAX_W);
}
//创建两个标记容器,X代表已经被选择,Y代表没有被选择
vector<bool> X(n, false);//出队时判环,避免加入环边
vector<bool> Y(n, true);//入队时过滤无效边,减少队列冗余
//需要优先级队列来选择权值
priority_queue<Edge<W>, vector<Edge<W>>, greater<Edge<W>>> pq;
//先处理给的初始顶点
X[srci] = true;
Y[srci] = false;
//通过优先级队列找局部最小权值,先进行存储
for (int i = 0; i < n; i++)
{
if (_matrix[srci][i] != MAX_W)
{
pq.push(Edge<W>(srci, i, _matrix[srci][i]));
}
}
W totalW = W();
int size = 0;
//正式开始找最小生成树
while (!pq.empty())
{
Edge<W> min = pq.top();
pq.pop();
//入队和出队有时间差------ 可能某条边入队时,目标顶点还在 Y(未加入 MST),
//但等它从队列弹出时,目标顶点已经被「其他权重更小的边」提前加入了 X(MST)
if (X[min._desti])
{
cout << "构成环:";
cout << _vertexs[min._srci] << "->" << _vertexs[min._desti] << ":" << min._w << endl;
}
else
{
//构建最小生成树
minTree.AddEdge(_vertexs[min._srci], _vertexs[min._desti], min._w);
X[min._desti] = true;
Y[min._desti] = false;
totalW += min._w;
size++;
if (size == n - 1)
{
break;
}
//继续放入顶点到优先级队列
for (int i = 0; i < n; i++)
{
if (_matrix[min._desti][i] != MAX_W && Y[i])
//Y即防止了另一个方向的无效边;适当的减少从_desti出发造成的环
{
pq.push(Edge<W>(min._desti, i, _matrix[min._desti][i]));
}
}
}
}
if (size == n - 1)
{
return totalW;
}
else
{
return W();
}
}🌸🌸数据结构-图大概就讲到这里啦,博主后续会继续更新更多Qt的相关知识,干货满满,如果觉得博主写的还不错的话,希望各位小伙伴不要吝啬手中的三连哦!如有小伙伴需要Qt的安装包可以私信我,你们的支持是博主坚持创作的动力!💪💪