最初被设计用于图像渲染的图形处理器(GPU),因其架构具备高度并行状态,所以在通用计算范畴呈现出卓越性能。现代的GPU一般含有数千个计算核心,这些计算核心能够同时处理大量的数据线程,而这种特性刚好符合人工智能、科学计算等数据密集型任务的要求。
从架构的层面去做分析来看,GPU跟中央处理器也就是CPU,是存在着本质方面的差异的。CPU一般情况下是拥有少量的,不过功能却很强大的核心的,它是比较擅长用来处理复杂的串行任务以及逻辑控制的;然而GPU却是集成了数千个比较相对简单一些的核心的,它是专门为了并行处理大量的相似计算而进行优化设计的范畴。就比如说的架构的A100 GPU,它是包含了6912个CUDA核心的,其单精度这方面的浮点性能是达到了19.5 的,这样的一种计算密度是传统CPU很难能够达到企及的程度的。
现阶段,处于流行状态的GPU算力能够划分成几个最为主要的类别。像RTX 4090这样的消费级GPU,有着16384个CUDA核心,还有24GB 显存,在推理任务以及中小规模训练里展现出突出表现。诸如H100的以架构为采用架构的专业级计算卡,配备了18432个CUDA核心以及80GB HBM3显存,显存带宽达到3.35TB/s。而于云端常能见到的那种A100 GPU,提供40GB和80GB这两种显存配置,它的第三代张量核心能够让混合精度计算得到明显加速。
在人工智能这个领域当中,GPU算力对从模型训练一直到推理部署的整个流程起到支撑作用。开展大规模语言模型的训练,通常情况下是需要数千张GPU持续运行,运行时间会长达数周,甚至是数月。就拿拥有1750亿参数的模型来说,要是使用8张A100 GPU来展开全参数训练,预计大概需要34天能够完成。然而推理阶段对于延迟方面的要求更为严格,在边缘计算那个场景里,端到端推理延迟必须控制在20毫秒以内,这样才可以满足实时性需求。
同样非常深度地依赖GPU加速来进行科学计算,在气候模拟领域里,就是传统的CPU集群所用时数月去完成的百年气候模拟,借助GPU加速能把时间缩短到数周,在分子动力学模拟当中,GPU可以将计算速度提升超过50倍,致使原本要数年的蛋白质折叠模拟能够在数周内完成,在天文数据处理方面,平方公里阵列望远镜每天所产生的数据量达到数PB,必然得依靠GPU阵列来进行实时处理。
GPU算力获取方式,历经了从本地部署朝着弹性服务的演进进程,早期不少机构,多借助自建数据中心的形式,一次性投入数额,可达数十万乃至数百万,各不相同,并且有着资源利用率不均衡的状况,据相关统计显示,传统自建方案里的GPU资源,日均利用率常常低于40%,存在着明显的资源闲置现象,伴随云计算技术的发展,按需付费的算力服务,渐渐得到普及,用户能够依照实际需求,弹性地调配资源,规避了前期大量固定资产投入。

在技术架构领域,异构计算平台正逐渐演变成主流发展趋向,现代计算系统常常会整合诸如 GPU、CPU、NPU 等多样的处理单元,经由统一的软件栈达成任务调度以及资源分配,容器化技术进一步提高了算力资源的运用效率,借助轻量级虚拟化达成环境隔离以及快速部署,在边缘计算场景里面,分布式节点能够把计算任务下沉至数据产生的地方,切实降低网络传输延迟。
分布式 GPU 计算中,网络性能至关重要。大规模模型训练里,GPU 间通信延迟直接影响训练效率。 网络技术提供高达 400Gb/s 的带宽以及亚微秒级延迟,进而成为高性能计算集群的标准配置。推理服务场景下,内容分发网络与边缘节点的结合可将响应时间降低 80%以上,以此提升终端用户体验。
由产业发展这个角度去看,全球算力需求呈现出指数级增长的态势来了。在2023年到2025年这期间,人工智能训练所需要的算力预计每年增长大概3倍。这种增长不仅推动着硬件技术快速地迭代,还促进了算力调度以及管理软件的发展。智能调度算法能够依据任务特性、资源状态还有成本因素,动态地分配计算资源,提升整体利用率大约30%。
日益愈受关注的是能耗问题,高性能GPU的单卡功耗能够达到300至700瓦,大规模集群的能耗是颇为可观的,新型液冷技术可把散热效率提高50%,与此同时能耗降低约30%,可再生能源于数据中心的应用比例在持续上升,部分先进数据中心已将电源使用效率优化到1.2以下。
未来发展呈现出这样的趋势,专用计算芯片必将越发充满多样化。在通用GPU之外,针对特定场景予以优化的处理器持续地不断涌现,像是图像处理专门用的VPU,神经网络推理专门用的NPU等等这一类。然而软件生态的完善也是同等重要不可或缺的关键所在,统一的那个编程模型以及优化库能够把开发门槛降低,进而使得研究人员能够更加侧重于专注算法自身本身而并非底层实现方面。
全球化布局里,算力基础设施得去思量数据传输之时合规性以及效率,不同国家还有地区针对数据跨境流动存有各异的法律要求,此情形对算力资源部署策略产生了影响,与此同时,网络拓扑进行优化能把跨国数据传输延迟控制在可接受范围以内,进而支持分布式协作研究。
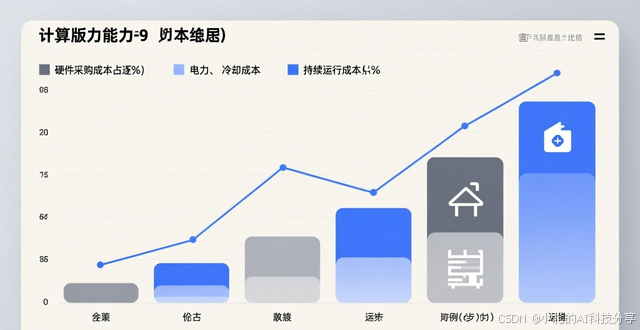
在经济层面予以剖析,算力成本的构成正出现改变,硬件采购成本所占比例正渐渐降低,然而电力、冷却以及运维等持续运营成本的占比却在上升,弹性算力模式借由精细化的资源管理,可使综合使用成本降低大概40%,格外适配需求波动较大的应用场景。
对于算力服务而言,质量保障体系是极其重要的,完善的监控系统能够针对GPU利用率、温度、错误率等关键指标进行实时追踪,从而提前发现潜在问题,自动化运维平台能处理常见的硬件故障以及软件异常,进而把系统可用性维持在99.9%以上,灾难恢复机制可确保在极端状况下业务连续性不受到影响。
算力生态能健康发展,人才培养是重要基础,这其中,既要有熟悉算法模型以及业务场景的应用开发者,又得存在精通硬件架构和并行编程的底层工程师,当下,学术界跟产业界正在日益紧密合作,开源社区贡献了大量优化工具以及最佳实践后,加速了技术创新和知识传播。
短期内仍将是的人工智能和科学计算主力算力来源的GPU,随着芯片制造工艺逼近物理极限,架构创新和软件优化重要性进一步凸显时,量子计算与经典计算可能相融开辟新方向,三维堆叠、光计算这类新兴技术有望打破现有瓶颈推动计算效率实现新飞跃。
于数字化时代当中,GPU算力已然成为关键的基础设施要素了,其发展水平直接对人工智能、科学研究、工业仿真等前沿领域的进步速度造成影响。伴随技术不断成熟以及生态日益完善,高效、普惠的算力服务将会赋能更多创新应用,促使社会各行业的智能化转型得以推进。这一进程不但需要硬件技术的突破,还需要算法优化、系统架构、人才培养等多方面的协同发展。