这是系列博客中的第二篇。我们将继续聚焦于自 2025 年 1 月 "DeepSeek 时刻" 以来中国开源社区所取得的历史性进展。(第一篇博客见:"DeepSeek 时刻" 一周年 )在本篇中,我们将讨论焦点正从模型本身,转向中国公司在架构设计与硬件层面的关键选择。
对于持续参与并依赖开源生态的 AI 研究者与开发者,以及试图理解这一快速演变环境的政策制定者而言,一些清晰的趋势正在浮现:技术架构选择日益多元,多模态能力持续扩展,开源许可愈发宽松,小模型逐渐走红,同时,中国本土硬件的采用速度明显加快。这些变化共同表明,AI 领域的 "领先" 优势,正在通过多种不同路径被塑造。而 DeepSeek R1 的技术特征本身,不仅加剧了生态内部的重叠与竞争,也在客观上强化了中国 AI 发展对国产硬件体系的关注与投入。
混合专家模型(MoE)作为默认选择
在过去一年中,中国社区的领先模型几乎一致地转向了混合专家(MoE)架构,包括 Kimi K2、MiniMax M2 以及 Qwen3。 尽管 R1 本身并非 MoE 模型,但它验证了一个关键事实:强推理能力可以是开源的、可复现的,并且能够在工程实践中实现。 在中国的现实约束条件下,要在控制成本的同时保持高能力,并确保模型能够被训练、部署并广泛采用,MoE 自然成为了一种解决方案。
MoE 类似于一种可控的算力分配系统;在统一的能力框架下,根据任务的复杂度与价值,动态激活不同数量的专家,从而在不同请求与部署环境中分配计算资源。更重要的是,它并不要求每一次推理都消耗全部资源,也不假设所有部署环境都具备相同的硬件条件。
2025 年中国开源模型的整体方向已经非常清晰:并非追求最强的性能,而是强调长期稳定运行、灵活部署和持续迭代的能力,从而实现最佳的性价比平衡。
以模态为中心的竞争格局
自 2025 年 2 月起,开源模型的类型已不再仅仅限于文本模型。 其迅速扩展至多模态与智能体方向:Any-to-Any 模型、文生图、图生视频、文生视频、语音合成(TTS)、三维建模以及智能体等方向几乎同步推进。
社区所推动的不仅是模型权重本身,而是一整套工程资产,包括推理部署、数据集与评测体系、工具链、工作流以及端到云的协同能力。 视频生成工具、三维组件、蒸馏数据集和智能体框架的并行涌现,表明这并非零散的技术突破,而是可复用的系统级能力正在形成。
在非文本模态中争夺类似 DeepSeek 式领导地位的竞争逐渐升温。StepFun 发布了高性能的多模态模型,在音频、视频和图像生成,以及处理和编辑等方面表现突出。 其最新的语音到语音模型 Step-Audio-R1.1 达到了当前最先进水平,性能超过了一些专有模型。
腾讯也通过其在视频与三维方向上的开源工作体现了这一转变。其 Hunyuan Video 系列模型以及 Hunyuan 3D 等项目,反映出围绕非文本模态展开的竞争正在不断加剧。
小模型明显增多
参数规模在 5 亿到 300 亿之间的模型更容易在本地运行、进行微调,并集成到业务系统和智能体工作流中。例如,在 Qwen 系列中,Qwen 1.5-0.5B 拥有最多的衍生模型(见下图)。在算力受限或合规要求严格的环境中,这类模型显然更适合长期运行。与此同时,领先机构通常会使用参数规模在 100B 到 700B 之间的大型 MoE 模型作为能力上限或"教师模型",再将其能力蒸馏到众多小模型中。这形成了一种清晰的结构:顶层是少数超大模型,下层则是大量实用模型。月度统计中小模型占比的上升,反映了社区中的真实使用需求。
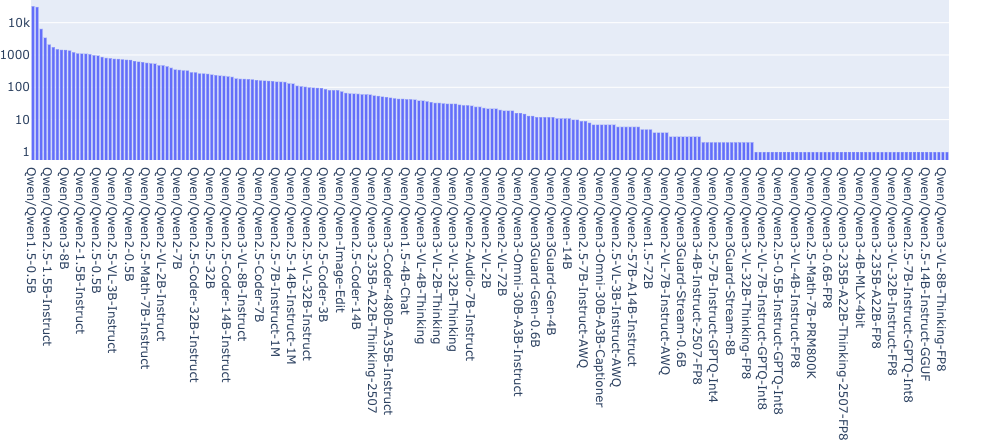
https://huggingface.co/spaces/cfahlgren1/hub-model-tree-stats
更宽松的开源许可证
在 R1 之后,Apache 2.0 几乎成为中国社区开源模型的默认许可证选择。更宽松的许可证降低了模型在生产环境中使用、修改和部署的摩擦,使企业更容易将开源模型真正引入实际系统。 对 Apache 2.0 和 MIT 等标准许可证的熟悉程度同样降低了使用门槛;相比之下,定制化和约束性更强的许可证因为不被熟知、理解成本高,增加了新的法律风险,在实际使用中显著增加了摩擦成本,从而降低了采用意愿,这也直接导致了图中所显示的整体下滑。
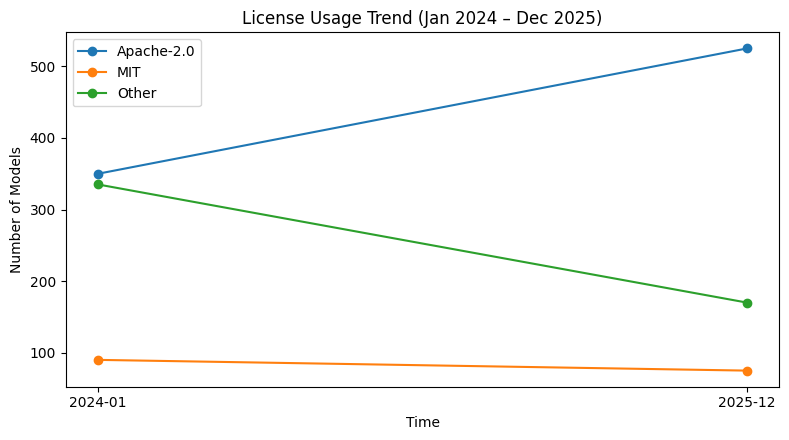
基于中国开源热力图中所列全部机构的发布情况
从模型优先到硬件优先
2025 年,模型发布越来越多地与推理框架、量化格式、服务引擎以及边缘运行时保持对齐。一个突出的目标已不再只是让模型权重可下载,而是确保模型能够直接在目标国产硬件上运行,并且稳定高效。
这一变化在推理侧体现得尤为明显。例如,在 DeepSeek-V3.2-Exp 发布时,华为昇腾与寒武纪芯片实现了"首日支持",并非云端演示,而是与模型权重一同发布的可复现推理流水线,使开发者能够直接验证真实世界中的性能表现。
与此同时,训练侧的信号也开始显现。蚂蚁集团的 Ling 开源模型通过在国产 AI 芯片上进行优化训练,实现了接近 NVIDIA H800 的性能,并将训练一万亿 token 的成本降低了约 20%。百度的开源 Qianfan-VL 模型明确披露,其训练使用了由 5000 多张百度昆仑 P800 加速卡组成的集群,并提供了并行化和效率方面的详细信息。2026 年初,智谱的 GLM-Image 以及中国电信最新的开源模型 TeleChat3 均宣布完全在国产芯片上完成训练。这些披露表明,国产计算设备已不再局限于推理阶段,而是开始进入训练流程中的关键环节。
在服务与基础设施层面,工程能力也正在被系统性地开源。 月之暗面 (Moonshot AI) 发布了其服务系统 Mooncake,并明确支持诸如预填充/解码分离等特性。通过将生产级经验开源,这些举措显著抬高了整个社区在部署与运维方面的基础水平,使模型能够在规模化场景中更加稳定、可靠地运行。 这一方向在整个生态中得到了呼应。百度的 FastDeploy 2.0 强调通过极限量化和集群级优化,在算力预算高度受限的情况下降低推理成本。阿里的 Qwen 生态则走向全栈整合路径,将模型、推理框架、量化策略和云端部署流程紧密对齐,以最大程度减少从开发到生产的摩擦。然而,有关中国算力受限的报道仍对扩张构成威胁;据称,智谱 AI 已在算力紧张的情况下开始限制使用。
当模型、工具与工程能力被一并交付时,生态不再通过简单增加项目来增长,而是通过在共同基础上的结构性分化,开始形成自我演进。随着 NVIDIA 开始销售 H200,中国将如何应对美国的硬件销售与出口管制,仍然是一个悬而未决的问题。(更多关于全球算力格局变化的内容,可参考:
https://huggingface.co/blog/huggingface/shifting-compute-landscape)
重构正在进行中
2025 年 1 月的"DeepSeek 时刻"不仅引发了一波新的开源模型发布。它迫使行业重新思考:当开源不再是可选项而是基础设施时,AI 系统应当如何构建,以及这些底层选择为何如今具有战略意义。
中国公司已不再仅仅优化孤立的模型。相反,它们正在探索不同的架构路径,旨在构建适配开源世界的完整生态体系。在模型日益商品化的背景下,这些决策清晰地表明,竞争正在从模型性能转向系统设计。
我们的下一篇博客将进一步探讨组织层面的胜出者,并分享我们对 2026 年趋势的部分预期。