前言
作者:小蜗牛向前冲
如果觉的博主的文章还不错的话,还请
点赞,收藏,关注👀支持博主。如果发现有问题的地方欢迎❀大家在评论区指正
目录
[2、从 N-Gram 到 TF-IDF](#2、从 N-Gram 到 TF-IDF)
[3、Gensim 工具](#3、Gensim 工具)
一、Embedding
1、什么是Embedding
在计算机的世界中,可以通过特定的编码将文字进行影视,知道了苹果,香蕉怎么去表示,但是对于计算机来说,不能理解苹果和香蕉是什么关系,是属于水果吗?为了表示这种关系,人们将苹果和香蕉,转换为向量,在通过计算余弦相似度,来确认二者的相似度,这种将代码,图片,文字转换为向量的过程称为Embedding。


其中A和B计算的结果越是接近于1,那么就关系越相近。
2、从 N-Gram 到 TF-IDF
N-Gram
n表示n个词,gram表示单词的意思,他是给一个句子,进行分词,通过分词找到规律,从而理解语句,进行预测。
比如:
它通过观察一段文本中连续出现的 N个词来预测下一个词。
Unigram (1-gram): 单个词,比如 "我", "喜欢", "吃", "苹果"。
Bigram (2-gram): 两个连续词,比如 "我喜欢", "喜欢吃", "吃苹果"。
Trigram (3-gram): 三个连续词,比如 "我喜欢吃", "喜欢吃苹果"。
逻辑很简单: 如果语料库里,"我喜欢吃"后面紧跟着"苹果"的频率远高于"手机",那么模型就会认为,"我喜欢吃"后面接"苹果"的概率更大。
CountVectorizer:词频统计
他将文本中的词语转换为词频矩阵,通过fit_transform: 计算各个词语出现的次数。简单来说就是在一个词表中统计,某个词出现的次数
TF-IDF:加了"过滤算法"的统计
为了解决 CountVectorizer 偏向于"高频词"的问题,TF-IDF 应运而生。它的名字直接揭示了它的逻辑:
TF:指这个词在词库中出现多少次数
IDF:指这个词出现的频率是怎么样的
一个词出现的次数多,TF就高,但是IDF就低
TF-IDF 的目的是通过调低那些到处都有的虚词的权重,极大地突出了文章的"核心特征词"。
3、Gensim 工具
在python中Gensim 能把大量的文本数据"翻译"成计算机能理解的数学向量,并从中挖掘出隐藏的主题或语义关系。
bash
//安装
pip install gensim他支持TF-IDF, LDA, LSA, word2vec等多种主题模型算法
这里我们以word2vec模型的训练为例子
python
# 先运行 word_seg进行中文分词,然后再进行word_similarity计算
# 将Word转换成Vec,然后计算相似度
from gensim.models import word2vec
import multiprocessing
# 如果目录中有多个文件,可以使用PathLineSentences
segment_folder = './journey_to_the_west/segment'
# 切分之后的句子合集
sentences = word2vec.PathLineSentences(segment_folder)
# 设置模型参数,进行训练
model = word2vec.Word2Vec(sentences, vector_size=100, window=3, min_count=1)
#print(model.wv['孙悟空'])
print(model.wv.similarity('孙悟空', '猪八戒'))
print(model.wv.similarity('孙悟空', '孙行者'))
print(model.wv.most_similar(positive=['孙悟空', '唐僧'], negative=['孙行者']))
# 设置模型参数,进行训练
model2 = word2vec.Word2Vec(sentences, vector_size=128, window=5, min_count=5, workers=multiprocessing.cpu_count())
# 保存模型
model2.save('./models/word2Vec.model')
print(model2.wv.similarity('孙悟空', '猪八戒'))
print(model2.wv.similarity('孙悟空', '孙行者'))
print(model2.wv.most_similar(positive=['孙悟空', '唐僧'], negative=['孙行者']))这里先给一个文件里面有大量语句,对这些语句进行分词,在将分好的给模型word2vcv训练,这样我们就能计算小说中的人物相似度, 比如孙悟空与猪八戒, 孙悟空与孙行者
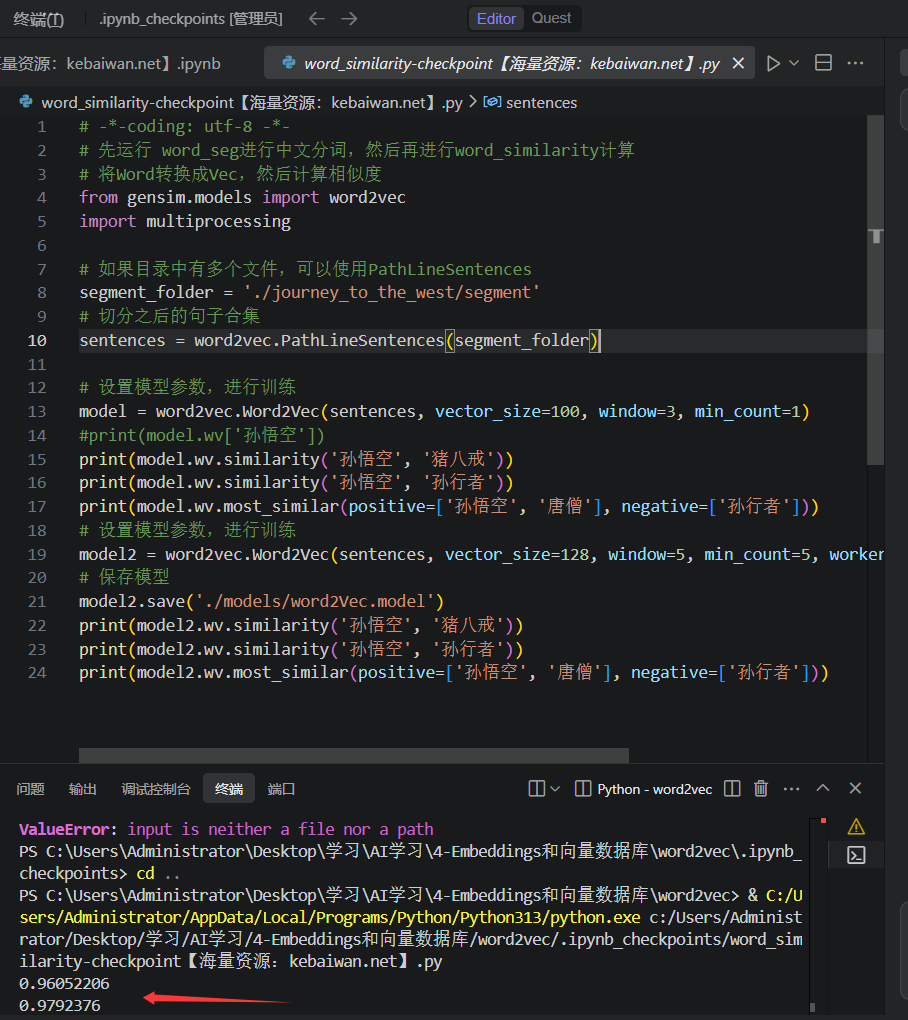
相似度越是接近1就认为关系越相近。
4、Embedding模型的选择
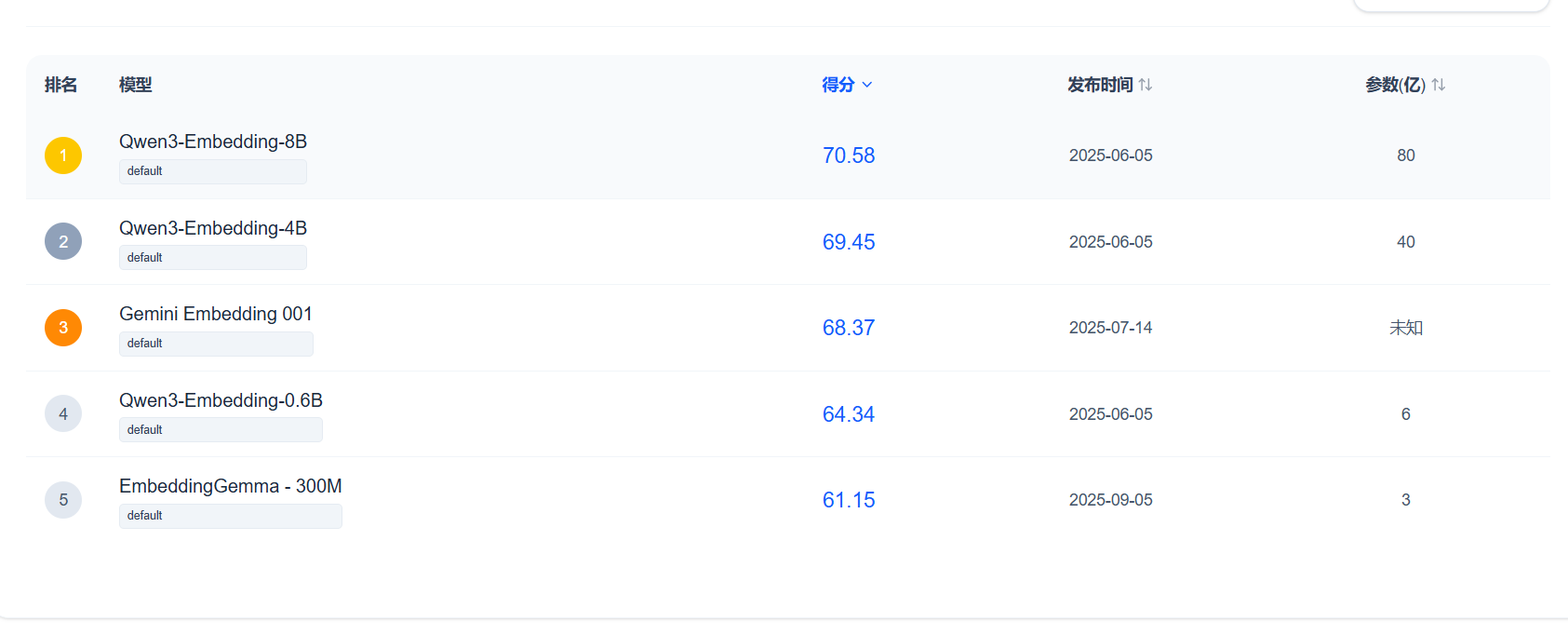
Embedding模型将文本等离散数据转换为低维、稠密的向量,捕捉其语义信息。在训练的模型进行分词的时候,我们不需要自己去训练Embedding模型,可以直接在MTEB榜单中选择自己合适的模型。
MTEB (Massive Text Embedding Benchmark) 是一个全面的评测基准,它涵盖了分类、聚类、检索、排序等8大类任务和58个数据集。可以清晰地看到不同模型(如 BGE系列, GTE, Jina 等)在不同任务类型上的性能表现。
型选型是一个系统的过程,不能仅依赖于公开榜单。包括以下关键步骤:
• 明确业务场景与评估指标: 首先定义核心任务是检索、分类还是聚类?并确定衡量业务成功的关键指标,如
搜索召回率 (Recall@K)、准确率 (Accuracy) 或 NDCG。
• 构建"黄金"测试集: 准备一套能真实反映您业务场景和数据分布的高质量小规模测试集。
比如,构建一系列"问题-标准答案"对 => 评估模型好坏的"金标准"。
• 小范围对比测试 (Benchmark): 从MTEB榜单中挑选几款排名靠前且符合需求(如语言、维度)的候选模型。使用 "黄金"测试集,对这些模型进行评测
二、向量数据库
1、向量数据量
对于大模型,前面的Emdedding模型解决,让模型理解文字,图片,代码的能力,但是理解这些的基础,是自己有足够的知识库,那这些知识是怎么存储,这些都是非结构化的,不能像一些结构化的数据可以存入MYSQL等数据库,于是就有了向量数据库。
向量数据库用于存储和查询 由非结构化数据(如文本、图片、音视频)转化而来 的高维向量嵌入(Embeddings )。 这些向量在多维空间中的距离代表了原始数据的语义相似度。
常见的向量数据库
1. FAISS
特点:由 Facebook 开发,专注于高性能的相似性搜索,
适合大规模静态数据集。
优势:检索速度快,支持多种索引类型。
局限性:主要用于静态数据,更新和删除操作较复杂。
2. Elasticsearch
特点: 强大的分布式搜索和分析引擎,将向量搜索
( k-NN )作为其众多功能之一。
优势:具备业界领先的混合搜索能力,可以无缝结合
传统的关键词搜索和向量语义搜索。
3. Milvus
特点:开源,支持分布式架构和动态数据更新。
优势:具备强大的扩展性和灵活的数据管理功能。
4. Pinecone
特点:托管的云原生向量数据库,支持高性能的向量搜索。
优势:完全托管,易于部署,适合大规模生产环境。
2、导入向量数据库
那如何将Emdedding处理好的高纬度向量导入到向量数据库中呢?直接像传统数据库调用insert的接口吗?
1、数据清洗与准备
确保原始数据(如文本文档、图片)的质量,进行必要的预处理。
2、 数据向量化(Embedding)
使用预训练的 Embedding Model 将原始数据转换成向量。
文本: 可使用 bge-m, Qwen3-Embedding, Jina-Embedding 等模型。
图片: 可使用 CLIP, ResNet 等模型。
选择合适的模型至关重要, 它直接决定了向量的质量和后续检索的效果。
3、 数据与元数据一同导入
在存放向量数据库的时候,不仅仅要把Embedding生成向量导入。还要将元数据一起导入
唯一iD: 用于唯一标识每个数据点,方便后续的更新或删除。
**元数据:**描述向量的附加信息,是实现高级检索的关键。
例如:
文本来源的文件名、章节、 URL
商品的类别、品牌、价格
图片的创建日期、作者
这里先用embedding计算文字的向量
python
import os
from openai import OpenAI
client = OpenAI(
api_key="sk-1253a03c92644575a6c5d158353ba312", # 如果您没有配置环境变量,请在此处用您的API Key进行替换
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" # 百炼服务的base_url
)
completion = client.embeddings.create(
model="text-embedding-v4",
input='我想知道迪士尼的退票政策',
dimensions=1024, # 指定向量维度(仅 text-embedding-v3及 text-embedding-v4支持该参数)
encoding_format="float"
)
print(completion.model_dump_json())这里演示通过导入FAISS
但是对于FAISS数据库本身只提供存储和检索向量,所以我们需要在在 FAISS 之外维护一个元数据的"查找表",并通过向量在 FAISS 中的唯一ID将两者关联起来。
最直接有效的方法是使用 FAISS 的 IndexIDMap => 允许我们为每个向量指定一个自定义的、唯一的 64 位整数 ID 。 然后,可以用这个ID 作为元数据存储的键。
python
import os
import numpy as np
import faiss
from openai import OpenAI
# Step1. 初始化 API 客户端
try:
client = OpenAI(
api_key="sk-1253a03c92644575a6c5d158353ba312",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
except Exception as e:
print("初始化OpenAI客户端失败,请检查环境变量'DASHSCOPE_API_KEY'是否已设置。")
print(f"错误信息: {e}")
exit()
# Step2. 准备示例文本和元数据
# 在实际应用中,这些数据可能来自数据库、文件等
documents = [
{
"id": "doc1",
"text": "迪士尼乐园的门票一经售出,原则上不予退换。但在特殊情况下,如恶劣天气导致园区关闭,可在官方指引下进行改期或退款。",
"metadata": {"source": "official_faq_v1.pdf", "category": "退票政策", "author": "Admin"}
},
{
"id": "doc2",
"text": "购买"奇妙年卡"的用户,可以享受一年内多次入园的特权,并且在餐饮和购物时有折扣。",
"metadata": {"source": "annual_pass_rules.docx", "category": "会员权益", "author": "MarketingDept"}
},
{
"id": "doc3",
"text": "对于在线购买的迪士尼门票,如果需要退票,必须在票面日期前48小时通过原购买渠道提交申请,并可能收取手续费。",
"metadata": {"source": "online_policy.html", "category": "退票政策", "author": "E-commerceTeam"}
},
{
"id": "doc4",
"text": "园区内的"加勒比海盗"项目因年度维护,将于下周暂停开放。",
"metadata": {"source": "maintenance_notice.txt", "category": "园区公告", "author": "OpsDept"}
}
]
# Step3. 创建元数据存储和向量列表
# 我们使用一个简单的列表来存储元数据。列表的索引将作为FAISS的ID。
# 这种方式简单直接,适用于中小型数据集。
# 对于大型数据集,可以考虑使用字典或数据库(如Redis, SQLite)
metadata_store = []
vectors_list = []
vector_ids = []
print("正在为文档生成向量...")
for i, doc in enumerate(documents):
try:
# 调用API生成向量
completion = client.embeddings.create(
model="text-embedding-v4",
input=doc["text"],
dimensions=1024,
encoding_format="float"
)
# 获取向量
vector = completion.data[0].embedding
vectors_list.append(vector)
# 存储元数据,并使用列表索引作为唯一ID
metadata_store.append(doc)
vector_ids.append(i) # 自定义ID与列表索引一致
print(f" - 已处理文档 {i+1}/{len(documents)}")
except Exception as e:
print(f"处理文档 '{doc['id']}' 时出错: {e}")
continue
# 将向量列表转换为NumPy数组,FAISS需要这种格式
vectors_np = np.array(vectors_list).astype('float32')
vector_ids_np = np.array(vector_ids)
# Step4. 构建并填充 FAISS 索引
dimension = 1024 # 向量维度
k = 3 # 查找最近的3个邻居
# 创建一个基础的L2距离索引
index_flat_l2 = faiss.IndexFlatL2(dimension)
# 使用IndexIDMap来包装基础索引,能够映射我们自定义的ID
# 这就是关联向量和元数据的关键!
index = faiss.IndexIDMap(index_flat_l2)
# 将向量和它们对应的ID添加到索引中
index.add_with_ids(vectors_np, vector_ids_np)
print(f"\nFAISS 索引已成功创建,共包含 {index.ntotal} 个向量。")
# Step5. 执行搜索并检索元数据
query_text = "我想了解一下迪士尼门票的退款流程"
print(f"\n正在为查询文本生成向量: '{query_text}'")
try:
# 为查询文本生成向量
query_completion = client.embeddings.create(
model="text-embedding-v4",
input=query_text,
dimensions=1024,
encoding_format="float"
)
query_vector = np.array([query_completion.data[0].embedding]).astype('float32')
# 在FAISS索引中执行搜索
# search方法返回两个NumPy数组:
# D: 距离 (distances)
# I: 索引/ID (indices/IDs)
distances, retrieved_ids = index.search(query_vector, k)
# Step6. 展示结果
print("\n--- 搜索结果 ---")
# `retrieved_ids[0]` 包含与查询最相似的k个向量的ID
for i in range(k):
doc_id = retrieved_ids[0][i]
# 检查ID是否有效
if doc_id == -1:
print(f"\n排名 {i+1}: 未找到更多结果。")
continue
# 使用ID从我们的元数据存储中检索信息
retrieved_doc = metadata_store[doc_id]
print(f"\n--- 排名 {i+1} (相似度得分/距离: {distances[0][i]:.4f}) ---")
print(f"ID: {doc_id}")
print(f"原始文本: {retrieved_doc['text']}")
print(f"元数据: {retrieved_doc['metadata']}")
except Exception as e:
print(f"执行搜索时发生错误: {e}")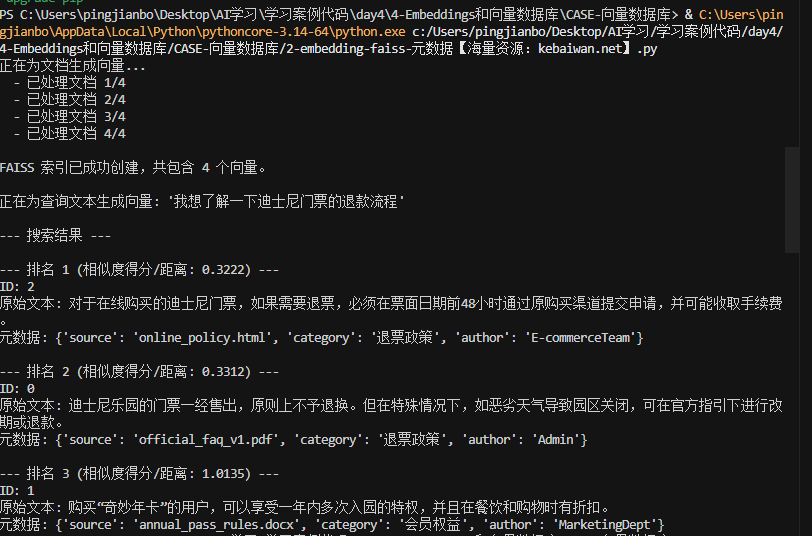
导入总结:
1、准备好数据,文本,元数据
2、把数据生成向量
3、创建元数据存储,Python中可以用列表,列表的索引当做唯一ID。在某些场景一下,可以将列表换为键值数据库(如 Redis)或者关系型数据库(如 PostgreSQL)或者文档数据库(如 MongoDB)。
4、创建FAISSS索引:
•用faiss.indexFlatL2创建一个基础的索引 => 这里使用L2距离(欧氏距离)进行精确搜索.
• 用 faiss.IndexIDMap 将基础索引包装起来 => 这样就可以添加带有自定义ID的向量了.
5、添加数据到索引:将生成的向量和对应的ID(即元数据列表的索引)添加到 IndexIDMap 中。
6、执行搜索:
• 对一个新的查询文本生成向量。
• 在 FAISS 索引中搜索最相似的向量。
• FAISS 会返回最相似向量的ID。
7、检索元数据:使用返回的ID,从元数据存储中查找到原始文本和元数据。