选错调度框架团队加班两行泪!2026最新分布式任务调度选型决策树,再也不纠结
技术选型一时爽,维护升级火葬场。这份万字选型指南 + 决策树,帮你一次选对,告别加班。
前言
在分布式系统大行其道的今天,定时任务早已不是简单的 cron 表达式能覆盖的场景。随着业务复杂度的提升,任务调度面临着高并发、海量数据、复杂依赖、跨语言、云原生等多重挑战。选错一个调度框架,轻则性能瓶颈、维护困难,重则引发生产故障、团队加班不断。
笔者调研了市面上主流的 10+ 款调度框架,结合一线大厂的落地经验,从六大关键因素 出发,梳理出一套2026 年最新选型决策树 ,并给出详细的横向对比表 和典型场景组合建议,希望能帮你和你的团队一次选对,少走弯路。
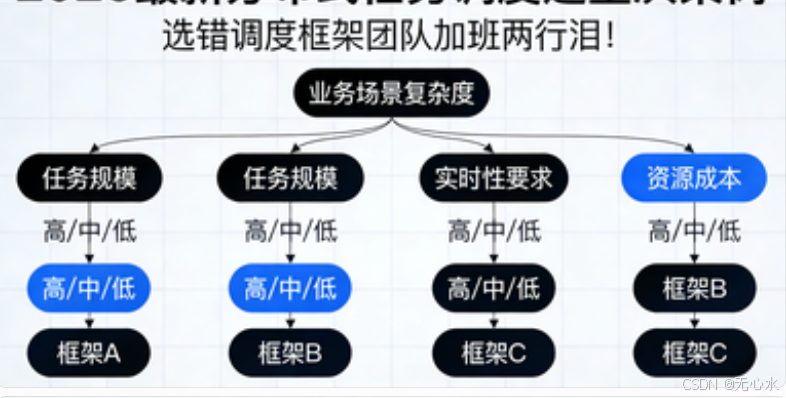
一、影响选型的六大关键因素
在翻开对比表格之前,请先对自身团队和业务做一个"体检",明确以下六个维度的现状和需求,这是选型决策的基石。
1. 技术栈(Java/Go/Python)
- 核心考量:调度框架最好与团队主力语言同栈,这样能最大化利用现有技术积累,降低学习成本和运维风险。如果团队是多语言混合,则需要考虑框架是否支持多语言任务(HTTP、Worker 多语言 SDK 等)。
- 典型场景 :
- 纯 Java 团队:优先考虑 Java 原生框架(XXL-JOB、PowerJob、Elastic-Job)。
- Go 团队:可考虑 K8s CronJob(原生支持)或支持多语言 Worker 的框架(如 DolphinScheduler 的 Go 任务)。
- Python/数据科学团队:Airflow、DolphinScheduler(Python 友好)。
2. 任务规模(每日任务量 & 并发度)
- 核心考量:任务量决定了调度器的吞吐能力和架构设计。小规模(日均万级以下)几乎任何框架都能胜任;大规模(日均百万级以上)则需要考虑无锁化设计、分片能力、调度器集群的水平扩展。
- 指标参考 :
- 小规模:< 1 万任务/天,并发 < 100
- 中规模:1 万 ~ 50 万任务/天,并发 100 ~ 1000
- 大规模:> 50 万任务/天,并发 > 1000
3. 是否上云(IDC / 云原生)
- 核心考量:部署环境直接决定基础设施的约束。在 IDC 机房,你可能需要自己维护注册中心、数据库;在云原生环境(K8s),则希望利用云原生能力(自动伸缩、服务发现、声明式 API),甚至直接购买云服务免运维。
- 趋势:2026 年,超过 80% 的新增任务调度系统部署在 K8s 环境,云原生适配能力成为重要加分项。
4. 团队规模与运维能力
- 核心考量:选型不仅要考虑功能,还要考虑团队是否有精力维护这套系统。小团队(< 10 人后端)应该选择"开箱即用、轻量级"的框架;大团队(有专门的中间件团队)则可以拥抱功能更强大、但运维复杂度稍高的框架,甚至自研。
- 运维复杂度指标:是否需要维护 ZK/ETCD?是否需要部署多个组件(API、Worker、Web)?是否有可视化控制台?升级是否平滑?
5. 是否需要工作流 / 分片
- 核心考量 :这是区分"简单定时任务"和"复杂数据处理"的关键。
- 工作流(DAG):任务之间存在依赖关系,需要串行/并行执行。常见于 ETL、数据处理 Pipeline。
- 分片(Sharding):将一个大型任务拆分成多个子任务并行执行,提高处理效率。常见于海量数据批处理、日志清洗。
- 如果只需要简单的定时触发,Quartz、K8s CronJob 即可;如果有复杂依赖或分片需求,则必须选择支持 DAG 或分片的框架(如 PowerJob、DolphinScheduler、Elastic-Job)。
6. 预算(开源免费 vs 云服务付费)
- 核心考量:成本永远是企业绕不开的话题。开源免费意味着你可以自由定制,但需要投入人力维护;云服务(如阿里云 SchedulerX、AWS 的 Amazon MWAA)虽然付费,但能做到真正意义上的"免运维",并且提供企业级的安全和监控能力。
- 决策:初创公司 / 中小企业倾向开源;中大型企业如果预算充足,且对稳定性要求极高,可以考虑云服务+自研混合。
小结:以上六个因素相互交织,最终指向不同的框架。如果你已经对自身情况有了清晰认识,接下来我们直接进入主流框架的硬核对比。
二、主流框架横向对比表(10+ 维度)
下表涵盖了目前社区最活跃、企业应用最广泛的 8 款调度框架,从多个维度进行了深度剖析。为了方便阅读,我将其核心信息提炼如下:
| 框架 | 核心优势 | 技术栈 | 工作流(DAG) | 分片能力 | 学习成本 | 运维复杂度 | 任务规模 | 云原生友好 | 社区活跃度 | 典型适用场景 |
|---|---|---|---|---|---|---|---|---|---|---|
| XXL-JOB | 轻量、生态全(多语言支持好)、文档丰富 | Java | 弱(仅支持简单的子任务) | 中(静态分片) | 低 | 低(依赖MySQL,无外部组件) | 中小规模 | 中(可容器化,但需自行处理) | 极高 | 中小团队、常规定时任务、多语言任务 |
| PowerJob | 无锁化设计、性能强劲、支持 DAG 和工作流、多语言 | Java(核心),支持多语言 Worker | 强(可视化 DAG) | 强(动态分片 + MapReduce) | 中 | 中(需维护 MySQL/MongoDB + PowerJob 服务端) | 大规模 | 高(官方提供 Helm 部署) | 高(新兴,增长快) | 复杂工作流、大数据计算、需要分片的场景 |
| Elastic-Job | 分片能力强、基于 ZK 的弹性伸缩 | Java | 弱(无原生 DAG) | 强(分片策略丰富) | 中高 | 中高(需维护 ZK) | 中大规模 | 中(可容器化,但 ZK 是状态ful) | 中(维护状态,新功能少) | 海量数据批处理、需要精细化分片控制 |
| DolphinScheduler | 可视化 DAG 强大、与大数据生态无缝集成(Spark、Flink 等) | Java + Python(前端+后端),多语言任务 | 强(可视化拖拽) | 中(可通过开关实现并行) | 中高 | 高(组件多:API、Worker、Master、Alert、ZK/DB) | 大规模 | 高(官方支持 K8s 部署) | 高 | 数据平台 ETL、离线计算、大数据任务编排 |
| Airflow | Python 原生、可扩展性强(Operator 丰富)、调度器成熟 | Python | 强(代码定义 DAG) | 弱(需结合第三方或自定义) | 中高 | 中(需维护元数据库、调度器、Worker) | 中大规模 | 中(可部署在 K8s,但官方 Helm 较复杂) | 极高 | AI/机器学习 Pipeline、Python 数据工程 |
| Quartz | 灵活、底层能力强、纯 Java 库 | Java | 无(需二次开发) | 无(需二次开发) | 中(库级别) | 中(需集成到应用,自行管理集群) | 小规模 | 低(需自行容器化) | 中(稳定,但生态停滞) | 小型项目、作为底层依赖(如 Spring 默认) |
| SchedulerX | 免运维、兼容开源(XXL-JOB、Quartz 无缝迁移)、企业级功能(任务观测、限流、降级) | 多语言 SDK | 强(支持 DAG 和工作流) | 强(分片) | 低 | 极低(云服务) | 任何规模(云弹性) | 极强(原生云服务) | N/A(商业产品) | 企业级、云原生环境、希望免运维 |
| K8s CronJob | 原生、无额外组件、声明式 API | 不限(容器化) | 无 | 无 | 中(需熟悉 K8s) | 中(依赖 K8s 基础) | 中小规模 | 极强(K8s 原生) | 极高(云原生生态) | 容器化、简单定时任务、微服务配套 |
表格解读:
- XXL-JOB 凭借"轻量 + 文档全"依然是中小团队的首选,但其 DAG 功能较弱,不适合复杂工作流。
- PowerJob 作为后起之秀,在性能和功能上非常均衡,尤其适合需要 DAG 和分片的 Java 技术栈团队。
- DolphinScheduler 在大数据领域地位稳固,如果团队已经重度使用 Spark/Flink,它是最佳拍档。
- Airflow 在 Python/ML 圈的地位无可撼动,如果你团队全是 Python 工程师,无脑选 Airflow。
- SchedulerX 是云上的"终极答案",特别适合那些不想维护基础设施、又需要兼容开源框架的企业。
- K8s CronJob 适合简单的容器化任务,比如定时清理日志、触发 Jenkins Job 等,复杂场景需要搭配其他工具。
三、选型决策树(Mermaid)
为了方便你快速定位,我绘制了一张选型决策树。请从左上角的"开始"进入,根据你的实际情况依次回答关键问题,最终会指向一个或多个推荐框架。这张图涵盖了六大关键因素的逻辑组合。
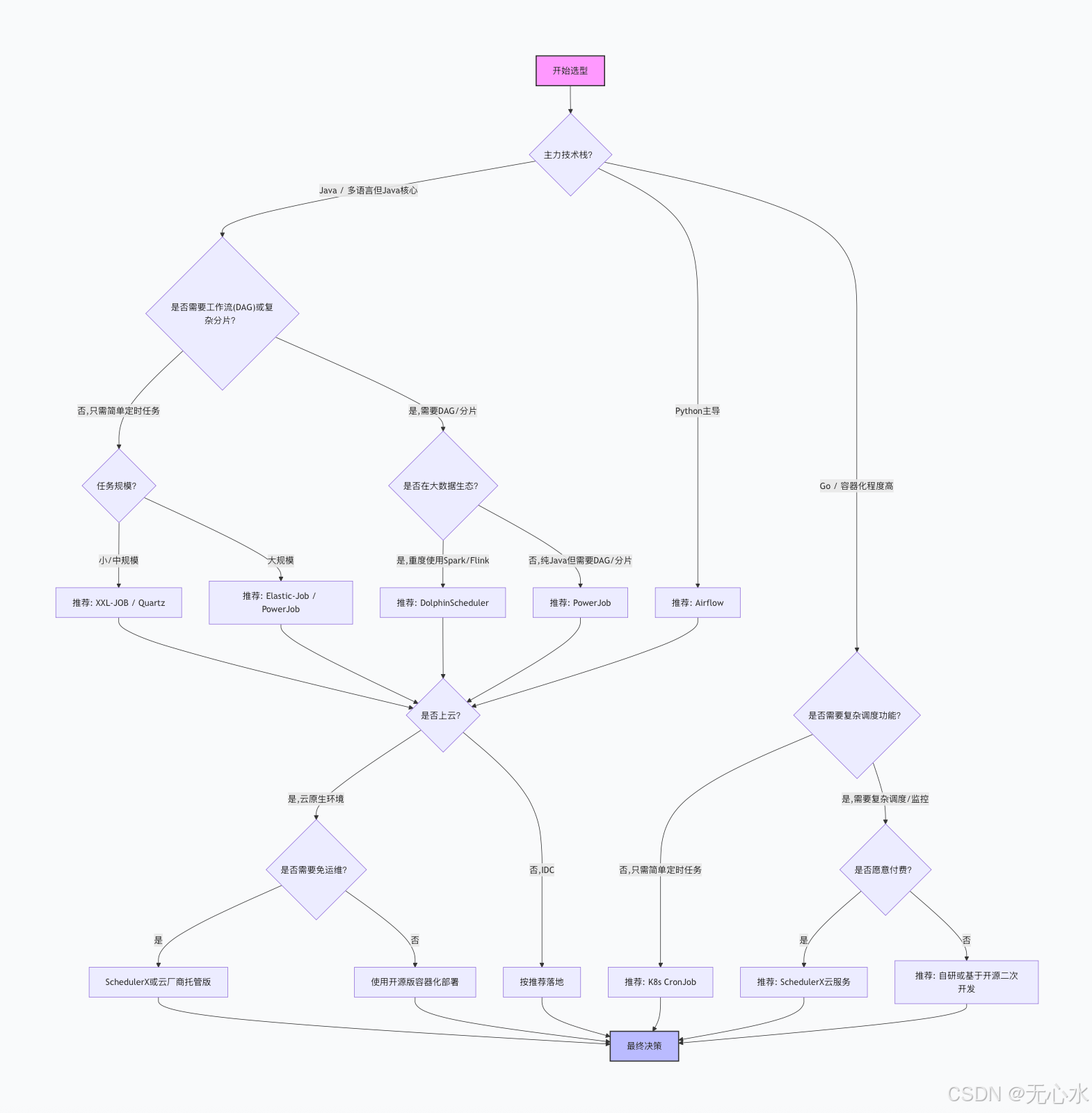
决策树使用说明:
- 首先根据主力技术栈分流:Java 栈 向下深入;Python 栈 直奔 Airflow;Go/容器化走向 K8s 原生或云服务。
- 对于 Java 栈,如果只需要简单定时,根据任务规模在 XXL-JOB/Quartz 和 Elastic-Job/PowerJob 之间选择;如果需要 DAG/分片,再判断是否重度依赖大数据生态,是则选 DolphinScheduler,否则选 PowerJob。
- 对于 Go/容器化,如果简单任务选 K8s CronJob;如果复杂,根据预算选择 SchedulerX 或自研。
- 最后统一考虑部署环境:是否上云?是否希望免运维?云上且预算充足可考虑 SchedulerX,否则用开源版容器化部署。
四、典型场景组合建议
理论结合实践,这里给出 6 个最常见的业务场景组合,以及对应的推荐框架和理由。
场景 1:中小电商 Java 团队(任务以业务触发、报表统计为主)
- 特征:团队 5-10 人,Java 技术栈,日均任务量 5000 左右,偶尔有跨任务依赖(如下单后延迟 30 分钟发券),大部分是独立定时任务。
- 推荐框架 :XXL-JOB
- 理由 :
- 轻量级,学习成本极低,Java 工程师一天上手。
- 提供简单的子任务功能,能满足轻度依赖需求。
- 社区文档丰富,遇到问题容易搜到解决方案。
- 无需额外维护 ZK,只需 MySQL,运维简单。
- 部署建议:使用 Docker 部署调度中心,任务处理器以 Spring Boot 应用接入,利用其自带的失败告警和日志功能。
场景 2:大数据平台(ETL 离线计算)
- 特征:团队有大数据专员,每天跑数百个 Spark/Flink 作业,作业之间存在复杂的 DAG 依赖(如 A 任务完成后触发 B、C 并行,B、C 完成后触发 D)。
- 推荐框架 :DolphinScheduler
- 理由 :
- 可视化拖拽 DAG,数据开发人员无需写代码即可编排任务。
- 原生支持 Spark、Flink、Hive、MR 等大数据组件,集成方便。
- 支持补数、重跑等大数据场景常用功能。
- 社区在大数据领域活跃,问题响应快。
- 部署建议:使用官方 K8s 部署方案,将 Master、Worker 等组件容器化,利用 K8s 的伸缩能力应对任务高峰期。
场景 3:Python / 数据科学团队(机器学习 Pipeline)
- 特征:团队全是 Python 工程师,每天需要运行模型训练、数据清洗、特征工程等任务,任务间依赖复杂,希望用代码定义工作流。
- 推荐框架 :Airflow
- 理由 :
- Python 原生,与数据科学工具链(Pandas、Scikit-learn、TensorFlow)无缝衔接。
- DAG 通过 Python 代码定义,版本可控,灵活性强。
- 丰富的 Operator 生态,可对接各种外部系统(如 AWS S3、GCP BigQuery)。
- 社区庞大,是业界的 Python 调度事实标准。
- 部署建议:可使用官方 Helm Chart 部署在 K8s 上,或使用云托管服务如 Amazon MWAA 减少运维负担。
场景 4:高并发分片任务(海量数据批处理)
- 特征:每天需要处理上亿级别的数据(如用户积分计算、账单生成),单机无法承载,需要将任务分片并行处理,并且要求高可用、弹性伸缩。
- 推荐框架 :Elastic-Job 或 PowerJob
- 理由 :
- Elastic-Job:分片能力极强,支持多种分片策略,与 ZK 结合实现作业注册和 leader 选举,适合长期稳定的分片需求。但 DAG 能力弱,适合纯分片场景。
- PowerJob:同样支持动态分片,且内置 MapReduce 模型,适合更复杂的分布式计算,同时提供可视化 DAG,如果后续需要引入工作流,扩展性更强。
- 选型建议:如果团队已有 ZK 基础设施,且对 DAG 无需求,选 Elastic-Job;如果希望一揽子解决分片 + 工作流,选 PowerJob。
场景 5:复杂工作流 / 大数据计算(Java 栈,不含大数据生态)
- 特征:Java 技术栈,但任务包含复杂的 DAG 依赖(如微服务调用链)、需要子任务并行处理,且任务量中等偏上。
- 推荐框架 :PowerJob
- 理由 :
- 无锁化设计,性能优于基于数据库轮询的框架,支持秒级调度。
- 自带可视化控制台,可在线编排 DAG,降低开发成本。
- 支持多语言(通过 HTTP 任务),方便非 Java 模块接入。
- 运维相对简单,只需部署 server 端 + 数据库。
- 部署建议:使用官方提供的 Docker 镜像或 Helm 部署,建议使用 MySQL 存储,PV 持久化日志。
场景 6:云原生环境(K8s 集群,希望最大化利用云能力)
- 特征:基础设施全面容器化,应用以微服务方式运行在 K8s 上,希望任务调度也能融入云原生体系,尽可能减少维护额外组件。
- 推荐框架 :K8s CronJob + SchedulerX 混合
- 理由 :
- 简单任务:直接使用 K8s CronJob,通过 YAML 声明式定义,完全融入 K8s 生态,无需额外学习。
- 复杂任务:使用 SchedulerX 云服务,它兼容 XXL-JOB 等开源协议,可以实现平滑迁移,并提供云上的任务编排、分片、监控能力,且无需维护任何组件。
- 混合优势:既享受了云原生的简洁,又获得了企业级任务的完备功能,且 SchedulerX 支持弹性伸缩,能够应对突发流量。
- 注意:如果预算有限且需要复杂功能,可以考虑在 K8s 上部署 PowerJob 或 DolphinScheduler,但需要自行维护其组件的高可用。
五、迁移方案:如何从自研 / 老旧框架平滑迁移
选定了目标框架,如何从现有的自研调度系统或老旧框架(如 Quartz 集群、简单的 cron 脚本)迁移过来?直接切换风险极高,必须遵循双跑 + 灰度 + 全量的策略。
1. 迁移前的准备工作
- 梳理存量任务:盘点现有所有定时任务,包括任务名称、cron 表达式、执行逻辑、依赖关系、告警配置。这是迁移的基础数据。
- 目标框架学习:团队成员对新框架进行培训,熟悉其 API 和运维方式。
- 搭建新集群:在测试环境搭建目标框架,并完成基本的稳定性测试。
2. 双跑阶段(数据比对,确保一致性)
- 概念:新旧两个调度系统同时运行,但只有旧系统负责实际业务执行,新系统仅用于"监听"或"模拟执行",验证结果是否一致。
- 操作步骤 :
- 将所有任务在新系统中注册,但设置为"暂停"或"仅记录"模式(大部分框架支持暂停任务)。
- 利用旧系统的执行记录,触发新系统的模拟执行(或通过截获日志),对比两者的执行结果(如返回值、影响的数据条数)。
- 持续一段时间(建议 1-2 周),确保新系统能够正确解析任务参数、执行逻辑,且无功能缺失。
- 工具建议:可编写简单的比对脚本,每天检查新旧系统的执行日志差异。
3. 灰度阶段(逐步切换流量)
- 概念:将部分业务线或部分低风险任务切换到新系统执行,实时监控成功率、延迟、错误。
- 操作步骤 :
- 选择非核心业务(如报表任务、数据清理)作为第一批灰度对象。
- 在新系统中启用这些任务,同时暂停它们在旧系统中的执行。
- 增加监控告警,重点关注任务失败率、执行时长、资源消耗。
- 如果稳定运行 3-7 天,扩大灰度范围,逐步覆盖更多任务。
- 回滚机制:一旦发现异常,立即切回旧系统(将任务在旧系统中恢复,新系统暂停),确保业务连续性。
4. 全量切换 + 旧系统下线
- 操作步骤 :
- 所有任务均切换到新系统后,继续并行观察一段时间(例如 1 个月),确保无隐藏问题。
- 关闭旧系统的调度器,但保留数据备份一段时间(如 3 个月),以备查证。
- 逐步清理旧系统的代码和配置,更新文档。
- 注意 :部分框架(如 SchedulerX)提供了从 XXL-JOB 或 Quartz 的一键迁移工具,可以自动导入任务配置,大幅降低迁移成本。如果采用此类商业服务,可直接使用官方工具完成大部分工作。
5. 迁移过程中的常见坑
- 任务幂等性:新旧系统同时运行时,可能会重复执行任务,务必确保任务逻辑本身支持幂等(或通过分布式锁控制)。
- 时间窗口:如果任务执行时间较长,新系统可能在同一时间点触发,造成资源竞争,建议错峰迁移。
- 依赖外部资源:比如数据库连接、文件路径、IP 白名单等,新系统的 Worker 可能 IP 不同,需提前配置。
结语
分布式任务调度选型没有银弹,关键在于认清自身现状 + 理解框架特性。本文从六大关键因素出发,给出了主流框架的深度对比,并构建了决策树帮你理清思路。最后,无论你选择哪款框架,请务必重视迁移过程的平滑性和安全性。
在 2026 年的技术浪潮中,云原生和免运维是两大趋势。如果你的团队还在为老旧调度系统频繁故障而烦恼,不妨考虑 SchedulerX 等云服务,将运维压力交给云厂商,让团队更聚焦于业务本身。
如果你觉得这份指南对你有帮助,欢迎收藏、转发,也欢迎在评论区留言你的选型困惑,我会尽力解答。祝大家选型顺利,永不加班!
附录:参考资料
- XXL-JOB 官方文档:https://www.xuxueli.com/xxl-job/
- PowerJob 官方文档:https://powerjob.tech/
- DolphinScheduler 官方文档:https://dolphinscheduler.apache.org/
- Airflow 官方文档:https://airflow.apache.org/
- Elastic-Job GitHub:https://github.com/elasticjob
- SchedulerX 产品页:https://www.aliyun.com/product/schedulerx
(注:本文基于 2026 年各框架的最新版本撰写,后续如有重大更新,请以官方文档为准。)