1.先安装 milvus 向量数据库,使用官方的docker compose 启动比较方便
2.编辑 dockerfile
# 使用带有mamba的轻量级镜像
FROM condaforge/mambaforge:latest AS builder
WORKDIR /tmp
# 复制优化后的环境文件
COPY environment_linux.yml .
# 配置国内镜像源(加速下载,可选)
#RUN mamba config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/ && \
# mamba config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/ && \
# mamba config --set channel_priority flexible
# 创建环境 - 使用详细输出便于调试
RUN mamba env create -p /opt/venv -f environment_linux.yml --verbose 2>&1 | tee /tmp/install.log && \
echo "=== 环境创建完成 ==="
# 2. 在已创建的环境中单独安装cn_clip
# 注意:使用环境的绝对路径调用pip
RUN /opt/venv/bin/pip install cn_clip==1.6.0 --no-deps
RUN /opt/venv/bin/pip install pymilvus==2.6.6
RUN /opt/venv/bin/pip install huggingface_hub==1.3.3
RUN /opt/venv/bin/python -c "import cn_clip; import pkg_resources; print('CN_CLIP验证开始...'); version = pkg_resources.get_distribution('cn_clip').version; print(f'CN_CLIP版本: {version}');"
# 简化的验证命令(避免复杂单行)
RUN echo "=== 验证Python ===" && \
/opt/venv/bin/python --version
RUN echo "=== 验证PyTorch ===" && \
/opt/venv/bin/python -c "import torch; print('PyTorch:', torch.__version__)" 2>/dev/null || echo "PyTorch未安装"
RUN echo "=== 验证Milvus ===" && \
/opt/venv/bin/python -c "import pymilvus; print('Milvus:', pymilvus.__version__)" 2>/dev/null || echo "Milvus未安装"
RUN echo "=== 验证NumPy ===" && \
/opt/venv/bin/python -c "import numpy; print('NumPy:', numpy.__version__)" 2>/dev/null || echo "NumPy未安装"
# 清理缓存
RUN mamba clean --all --yes && \
rm -rf /opt/conda/pkgs/*
# ===== 第二阶段:运行环境 =====
FROM debian:bullseye-slim
ENV HF_ENDPOINT=https://hf-mirror.com
ENV HF_HUB_DISABLE_TELEMETRY=1
# 安装系统依赖(根据实际需要调整)
RUN apt-get update && apt-get install -y --no-install-recommends \
ca-certificates \
libgl1-mesa-glx \
libglib2.0-0 \
libsm6 \
libxext6 \
libxrender-dev \
libgomp1 \
&& rm -rf /var/lib/apt/lists/*
# 从构建阶段复制conda环境
COPY --from=builder /opt/venv /opt/venv
# 设置环境变量
ENV PATH="/opt/venv/bin:$PATH" \
PYTHONUNBUFFERED="1" \
PYTHONPATH="/app"
WORKDIR /app
COPY ./appzh.py .
# 最终验证
RUN python -c "import sys; print(f'最终Python路径: {sys.executable}')"
EXPOSE 8000
# 启动命令(根据你的应用调整)
CMD ["python", "appzh.py"]3.编辑environment_linux.yml
# environment_linux.yml - 专为Docker优化
name: clip_milvus
channels:
- conda-forge # Linux首选,包更新更全
- pytorch # PyTorch官方频道
- defaults # 基础包
dependencies:
# ===== 核心包(移除Windows特有) =====
- python=3.11 # 只保留主版本
- pip=25.3
# ===== 数据处理与科学计算 =====
- numpy=1.26.4
- pandas=3.0.0
- scipy
# ===== PyTorch全家桶(Linux版本) =====
- pytorch=2.1.2
- torchvision=0.16.2
- torchaudio=2.1.2
# 注意:移除了 cpuonly 和 pytorch-mutex(Linux不需要)
# ===== 系统库(Linux版本) =====
- openssl=3.6.0
- libffi=3.5.2
- libpng=1.6.54
- libtiff=4.7.1
- libwebp-base=1.6.0
- lerc=4.0.0
- openjpeg=2.5.4
- freetype=2.14.1
- zstd=1.5.7
- bzip2=1.0.8
- libsqlite=3.51.2
- libzlib=1.3.1
# ===== Web框架 =====
- fastapi=0.109.0
- uvicorn=0.27.0
- starlette=0.35.0
- pydantic=2.5.3
- pydantic-core=2.14.6
- click=8.3.1
- jinja2=3.1.6
- markupsafe=3.0.3
# ===== 网络与HTTP =====
- requests=2.31.0
- urllib3=2.6.3
- charset-normalizer=3.4.4
- idna=3.11
- certifi=2026.1.4
- anyio=3.7.1
- sniffio=1.3.1
- h11=0.16.0
- h2=4.3.0
- hpack=4.1.0
- hyperframe=6.1.0
# ===== 数学与工具 =====
- sympy=1.14.0
- mpmath=1.3.0
- networkx=3.4.2
# ===== 图像处理 =====
- pillow=10.1.0
- lcms2=2.18
# ===== 其他工具 =====
- filelock=3.20.3
- packaging=26.0
- pyyaml=6.0.3
- tqdm=4.67.1
- typing-extensions=4.15.0
- typing_extensions=4.15.0
- tzdata=2025c
- ca-certificates=2026.1.4
# ===== pip包部分(大部分保持原样) =====
- pip:
- argon2-cffi==25.1.0
- argon2-cffi-bindings==25.1.0
- azure-core==1.38.0
- azure-storage-blob==12.28.0
- cffi==2.0.0
- cn-clip==1.6.0
- cryptography==46.0.3
- environs==9.5.0
- fsspec==2026.1.0
- grpcio==1.76.0
- hf-xet==1.2.0
- httpcore==1.0.9
- httpx==0.28.1
- huggingface_hub==1.3.3
- isodate==0.7.2
- lmdb==1.7.5
- marshmallow==3.26.2
- minio==7.2.20
- orjson==3.11.5
- patch-ng==1.19.0
- protobuf==6.33.4
- pyarrow==23.0.0
- pycparser==3.0
- pycryptodome==3.23.0
- pymilvus==2.6.6
- python-dateutil==2.9.0.post0
- python-dotenv==1.2.1
- safetensors==0.7.0
- shellingham==1.5.4
- six==1.17.0
- timm==1.0.24
- typer-slim==0.21.1
- ujson==5.11.0
# 注意:以下包已在conda部分安装,从pip中移除以避免冲突
# - numpy==1.26.4
# - pandas==3.0.0
# - packaging==26.0
# - typing_extensions==4.15.0
# - tzdata==2025.3import io
import requests
from PIL import Image
import torch
import cn_clip.clip as clip
from cn_clip.clip import load_from_name, available_models
import numpy as np
from pymilvus import connections, Collection, FieldSchema, CollectionSchema, DataType, utility
import pymilvus
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from typing import List, Optional
import hashlib
import traceback
from pymilvus.client.types import LoadState
# -------------------- 1. 初始化 Chinese CLIP --------------------
app = FastAPI(title="Chinese CLIP向量检索服务")
# 检查可用模型
print("可用的 Chinese-CLIP 模型:", available_models())
# 选择模型 - 可以根据需求选择不同大小
MODEL_CONFIG = {
'name': 'ViT-B-16', # 可以选择: 'ViT-B-16', 'ViT-L-14', 'ViT-L-14-336', 'ViT-H-14'
'device': "cuda" if torch.cuda.is_available() else "cpu"
}
print(f"加载 Chinese-CLIP 模型: {MODEL_CONFIG['name']}")
print(f"使用设备: {MODEL_CONFIG['device']}")
# 加载 Chinese-CLIP 模型
model, preprocess = load_from_name(
MODEL_CONFIG['name'],
device=MODEL_CONFIG['device'],
download_root='./models'
)
model.eval()
# 模型维度映射
DIM_MAP = {
'ViT-B-16': 512,
'ViT-L-14': 768,
'ViT-L-14-336': 768,
'ViT-H-14': 1024,
'RN50': 1024
}
VECTOR_DIM = DIM_MAP.get(MODEL_CONFIG['name'], 512)
print(f"向量维度: {VECTOR_DIM}")
# 连接 Milvus
connections.connect(alias="default", host='192.168.1.166', port='19530')
collection_name = f"chinese_clip_{MODEL_CONFIG['name'].replace('-', '_').lower()}"
# -------------------- 2. 创建集合 --------------------
def setup_collection():
"""创建或加载 Milvus 集合"""
if not utility.has_collection(collection_name):
print(f"创建集合: {collection_name}")
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name="image_url", dtype=DataType.VARCHAR, max_length=1000),
FieldSchema(name="image_hash", dtype=DataType.VARCHAR, max_length=64), # 用于去重
FieldSchema(name="vector", dtype=DataType.FLOAT_VECTOR, dim=VECTOR_DIM),
FieldSchema(name="description", dtype=DataType.VARCHAR, max_length=1000, default_value="") # 可选描述
]
schema = CollectionSchema(fields, description="Chinese CLIP image vectors")
collection = Collection(name=collection_name, schema=schema)
# 创建索引 - 使用 IP(内积)距离,因为 Chinese-CLIP 向量已归一化
index_params = {
"metric_type": "IP", # 内积 = 余弦相似度(向量归一化后)
"index_type": "HNSW", # HNSW 通常有更好的召回率
"params": {
"M": 16,
"efConstruction": 200
}
}
collection.create_index(field_name="vector", index_params=index_params)
print(f"集合 '{collection_name}' 创建完成,使用 {MODEL_CONFIG['name']} 模型")
return collection
else:
collection = Collection(collection_name)
if not utility.load_state(collection_name) == LoadState.Loaded:
collection.load()
print(f"集合 '{collection_name}' 已加载,实体数量: {collection.num_entities}")
return collection
collection = setup_collection()
# -------------------- 3. 核心函数 --------------------
def get_image_vector(image_url: str, description: str = "") -> List[float]:
"""从图片URL下载图片并用 Chinese-CLIP 编码为向量"""
try:
# 下载图片
print(f"处理图片: {image_url[:50]}...")
response = requests.get(image_url, timeout=15)
response.raise_for_status()
image_data = io.BytesIO(response.content)
image = Image.open(image_data).convert('RGB')
# Chinese-CLIP 预处理
image_tensor = preprocess(image).unsqueeze(0).to(MODEL_CONFIG['device'])
with torch.no_grad():
image_features = model.encode_image(image_tensor)
# Chinese-CLIP 输出已经归一化
image_features = image_features / image_features.norm(dim=-1, keepdim=True)
vector = image_features.cpu().numpy()[0]
# 验证归一化
norm = np.linalg.norm(vector)
if abs(norm - 1.0) > 0.01:
print(f"警告: 图片向量范数异常: {norm:.6f},重新归一化")
vector = vector / norm
print(f"图片向量生成完成,范数: {norm:.6f}")
return vector.tolist()
except Exception as e:
print(f"图片处理失败: {e}")
traceback.print_exc()
raise HTTPException(status_code=400, detail=f"图片处理失败: {str(e)}")
def get_text_vector(text: str, use_prompts: bool = True) -> List[float]:
"""将中文文本用 Chinese-CLIP 编码为向量"""
try:
print(f"编码文本: '{text}'")
# Chinese-CLIP 中文提示词模板
chinese_prompts = [
'{}',
'一张{}的照片',
'{}的图片',
'{}的图像',
'高清{}图片',
'{}特写',
'{}在自然光下',
]
if use_prompts:
# 使用多个提示词集成
prompts = [prompt.format(text) for prompt in chinese_prompts]
print(f"使用的提示词: {prompts}")
text_tokens = clip.tokenize(prompts).to(MODEL_CONFIG['device'])
with torch.no_grad():
features_list = []
for i in range(len(prompts)):
features = model.encode_text(text_tokens[i:i+1])
features = features / features.norm(dim=-1, keepdim=True)
features_list.append(features)
# 平均多个提示词的特征
ensemble_features = torch.stack(features_list).mean(dim=0)
ensemble_features = ensemble_features / ensemble_features.norm(dim=-1, keepdim=True)
text_features = ensemble_features
else:
# 直接编码
text_tokens = clip.tokenize([text]).to(MODEL_CONFIG['device'])
with torch.no_grad():
text_features = model.encode_text(text_tokens)
text_features = text_features / text_features.norm(dim=-1, keepdim=True)
vector = text_features.cpu().numpy()[0]
# 验证归一化
norm = np.linalg.norm(vector)
if abs(norm - 1.0) > 0.01:
print(f"警告: 文本向量范数异常: {norm:.6f},重新归一化")
vector = vector / norm
print(f"文本向量生成完成,范数: {norm:.6f}")
return vector.tolist()
except Exception as e:
print(f"文本编码失败: {e}")
traceback.print_exc()
raise HTTPException(status_code=400, detail=f"文本编码失败: {str(e)}")
# -------------------- 4. 请求模型 --------------------
class ImageIngestRequest(BaseModel):
image_url: str
description: Optional[str] = "" # 图片描述(可选)
skip_duplicate: bool = True # 是否跳过重复图片
class TextSearchRequest(BaseModel):
text: str
top_k: int = 5
threshold: Optional[float] = 0.2 # 相似度阈值,可选
use_prompts: bool = True # 是否使用提示词工程
# -------------------- 5. HTTP接口 --------------------
@app.post("/ingest")
async def ingest_image(req: ImageIngestRequest):
"""入库接口:输入图片URL,提取向量并存入Milvus"""
try:
# 生成图片哈希用于去重
image_hash = hashlib.sha256(req.image_url.encode()).hexdigest()
if req.skip_duplicate:
# 检查是否已存在
try:
existing = collection.query(
expr=f'image_hash == "{image_hash}"',
output_fields=["id", "image_url"]
)
if existing:
print(f"图片已存在: {req.image_url}")
return {
"status": "skipped",
"message": "图片已存在",
"id": existing[0]["id"],
"existing_url": existing[0]["image_url"]
}
except Exception as e:
print(f"检查重复时出错: {e}")
# 编码图片
vector = get_image_vector(req.image_url, req.description)
# 入库
data = [
[req.image_url],
[image_hash],
[vector],
[req.description or ""]
]
insert_result = collection.insert(data)
collection.flush()
print(f"图片入库成功: {req.image_url[:50]}...")
return {
"status": "success",
"message": "图片向量已入库",
"id": insert_result.primary_keys[0],
"hash": image_hash,
"vector_dim": len(vector)
}
except Exception as e:
print(f"入库失败: {e}")
traceback.print_exc()
raise HTTPException(status_code=500, detail=f"入库失败: {str(e)}")
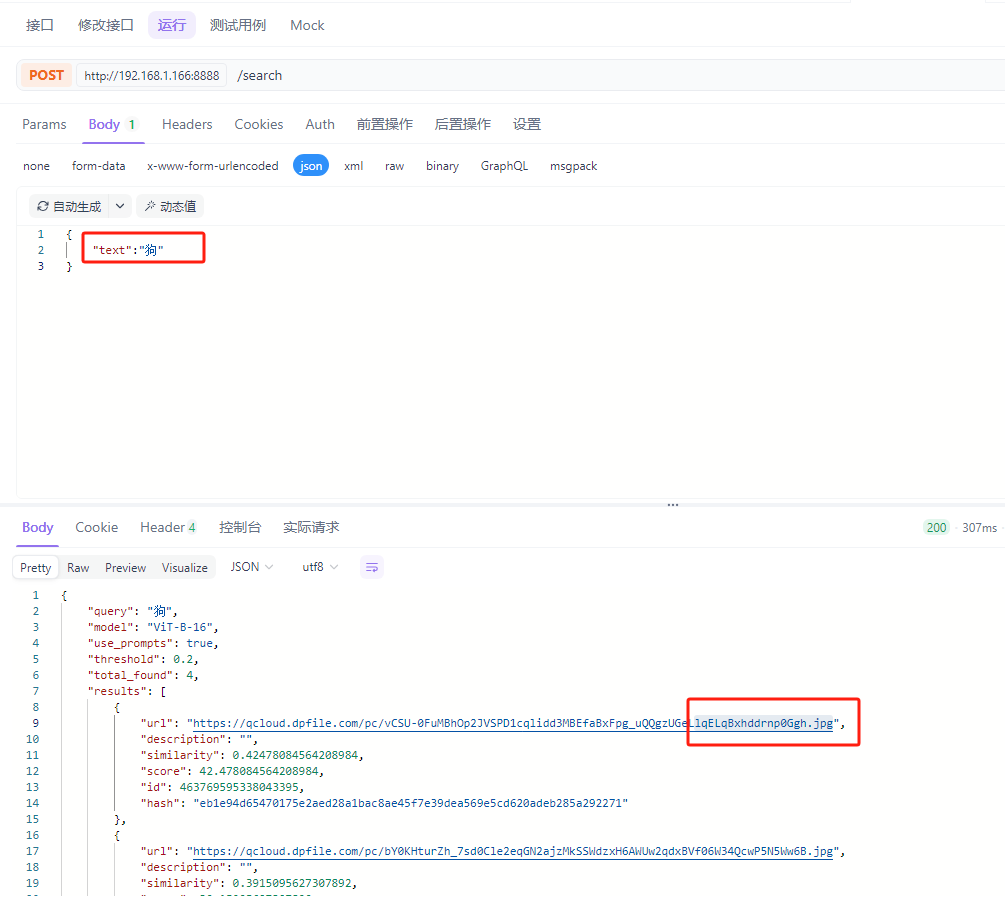
@app.post("/search")
async def search_images(req: TextSearchRequest):
"""检索接口:输入中文文本,返回最相似的图片"""
try:
print(f"\n{'='*50}")
print(f"搜索请求: '{req.text}'")
print(f"返回数量: {req.top_k}, 阈值: {req.threshold}")
# 编码查询文本
query_vector = get_text_vector(req.text, req.use_prompts)
# 搜索参数 - 使用 HNSW 索引
search_params = {
"metric_type": "IP",
"params": {"ef": 64} # HNSW 使用 ef 参数
}
# 计算搜索数量(考虑阈值过滤)
search_limit = req.top_k * 3 if req.threshold else req.top_k
search_limit = min(search_limit, 100)
print(f"搜索参数: {search_params}")
print(f"搜索数量: {search_limit}")
# 执行搜索
results = collection.search(
data=[query_vector],
anns_field="vector",
param=search_params,
limit=search_limit,
output_fields=["image_url", "description", "image_hash"],
consistency_level="Strong"
)
# 处理结果
ret_results = []
if results:
for hits in results:
for hit in hits:
similarity = hit.distance # IP距离 = 余弦相似度
# 应用阈值过滤
if req.threshold and similarity < req.threshold:
continue
# 转换为百分比分数(余弦相似度通常在0-1之间)
score_percent = similarity * 100 if similarity <= 1 else similarity
ret_results.append({
"url": hit.entity.get('image_url', ''),
"description": hit.entity.get('description', ''),
"similarity": float(similarity), # 余弦相似度
"score": float(score_percent), # 百分比
"id": int(hit.id),
"hash": hit.entity.get('image_hash', '')
})
# 按相似度从高到低排序
ret_results.sort(key=lambda x: x["similarity"], reverse=True)
ret_results = ret_results[:req.top_k]
print(f"找到 {len(ret_results)} 个结果")
for i, r in enumerate(ret_results):
print(f" {i+1}. 相似度: {r['similarity']:.4f} - {r['url'][:60]}...")
return {
"query": req.text,
"model": MODEL_CONFIG['name'],
"use_prompts": req.use_prompts,
"threshold": req.threshold,
"total_found": len(ret_results),
"results": ret_results
}
except Exception as e:
print(f"搜索失败: {e}")
traceback.print_exc()
raise HTTPException(status_code=500, detail=f"搜索失败: {str(e)}")
@app.post("/batch_ingest")
async def batch_ingest(images: List[ImageIngestRequest]):
"""批量入库接口"""
results = []
for i, img_req in enumerate(images):
try:
print(f"处理第 {i+1}/{len(images)} 张图片...")
result = await ingest_image(img_req)
results.append({
"url": img_req.image_url,
"status": "success",
"result": result
})
except Exception as e:
results.append({
"url": img_req.image_url,
"status": "error",
"error": str(e)
})
success_count = sum(1 for r in results if r["status"] == "success")
print(f"批量入库完成: {success_count}/{len(images)} 成功")
return {
"total": len(images),
"success": success_count,
"failed": len(images) - success_count,
"results": results
}
@app.post("/search_batch")
async def search_batch(queries: List[TextSearchRequest]):
"""批量搜索接口"""
batch_results = []
for i, query_req in enumerate(queries):
try:
print(f"处理第 {i+1}/{len(queries)} 个查询...")
result = await search_images(query_req)
batch_results.append({
"query": query_req.text,
"status": "success",
"result": result
})
except Exception as e:
batch_results.append({
"query": query_req.text,
"status": "error",
"error": str(e)
})
return {"batch_results": batch_results}
@app.get("/collection/info")
async def get_collection_info():
"""获取集合信息"""
try:
if not utility.has_collection(collection_name):
return {"error": "集合不存在"}
collection = Collection(collection_name)
#stats = collection.get_collection_stats()
# 获取索引信息
index_info = collection.index()
return {
"collection_name": collection_name,
"model": MODEL_CONFIG['name'],
"vector_dimension": VECTOR_DIM,
"total_images": collection.num_entities
}
except Exception as e:
return {"error": str(e)}
@app.get("/test/chinese")
async def test_chinese_search():
"""测试中文搜索准确性"""
test_cases = [
{"query": "猫", "description": "搜索猫咪图片"},
{"query": "狗", "description": "搜索狗狗图片"},
{"query": "红色的水果", "description": "搜索红色水果"},
{"query": "可爱的动物", "description": "搜索可爱动物"},
{"query": "风景", "description": "搜索风景图片"},
{"query": "美食", "description": "搜索美食图片"},
{"query": "城市夜景", "description": "搜索城市夜景"},
{"query": "海滩", "description": "搜索海滩图片"},
]
results = []
for test in test_cases:
try:
search_req = TextSearchRequest(text=test["query"], top_k=3)
search_result = await search_images(search_req)
results.append({
"query": test["query"],
"description": test["description"],
"found": len(search_result["results"]),
"top_results": [
{
"url": r["url"],
"similarity": r["similarity"],
"score": r["score"]
}
for r in search_result["results"][:2]
] if search_result["results"] else []
})
except Exception as e:
results.append({
"query": test["query"],
"error": str(e)
})
return {
"model": MODEL_CONFIG['name'],
"test_cases": results
}
@app.get("/test/compare")
async def compare_search():
"""对比中英文搜索效果"""
comparison_cases = [
{"chinese": "猫", "english": "cat"},
{"chinese": "狗", "english": "dog"},
{"chinese": "苹果", "english": "apple"},
{"chinese": "汽车", "english": "car"},
{"chinese": "太阳", "english": "sun"},
]
results = []
for case in comparison_cases:
try:
# 中文搜索
chinese_req = TextSearchRequest(text=case["chinese"], top_k=2)
chinese_result = await search_images(chinese_req)
# 英文搜索(使用中文CLIP也支持英文)
english_req = TextSearchRequest(text=case["english"], top_k=2)
english_result = await search_images(english_req)
results.append({
"chinese_query": case["chinese"],
"english_query": case["english"],
"chinese_results": [
r["url"] for r in chinese_result["results"]
] if chinese_result["results"] else [],
"english_results": [
r["url"] for r in english_result["results"]
] if english_result["results"] else []
})
except Exception as e:
results.append({
"chinese": case["chinese"],
"english": case["english"],
"error": str(e)
})
return {"comparison": results}
@app.delete("/collection/reset")
async def reset_collection(confirm: bool = False):
"""重置集合(删除所有数据)"""
if not confirm:
return {
"warning": "此操作将删除所有数据!",
"instruction": "添加 ?confirm=true 参数来确认重置"
}
try:
if utility.has_collection(collection_name):
utility.drop_collection(collection_name)
# 重新创建集合
global collection
collection = setup_collection()
return {
"status": "success",
"message": f"集合 '{collection_name}' 已重置"
}
else:
return {"error": "集合不存在"}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
@app.get("/health")
async def health_check():
"""健康检查"""
return {
"status": "healthy",
"service": "Chinese CLIP Vector Search",
"model": MODEL_CONFIG['name'],
"device": MODEL_CONFIG['device'],
"milvus_connected": True,
"collection": collection_name,
"collection_exists": utility.has_collection(collection_name)
}
# -------------------- 6. 启动服务 --------------------
if __name__ == "__main__":
import uvicorn
print(f"\n{'='*60}")
print("Chinese CLIP 向量检索服务")
print(f"{'='*60}")
print(f"模型: {MODEL_CONFIG['name']}")
print(f"向量维度: {VECTOR_DIM}")
print(f"设备: {MODEL_CONFIG['device']}")
print(f"集合: {collection_name}")
print(f"接口地址: http://localhost:8000")
print(f"文档地址: http://localhost:8000/docs")
print(f"{'='*60}\n")
uvicorn.run(app, host="0.0.0.0", port=8000)打包 运行 和 删除重来
docker build -t my-mamba-app .
docker run -p 8888:8000 --name my-mamba-app my-mamba-app
docker stop my-mamba-app && docker rm my-mamba-app && docker rmi my-mamba-app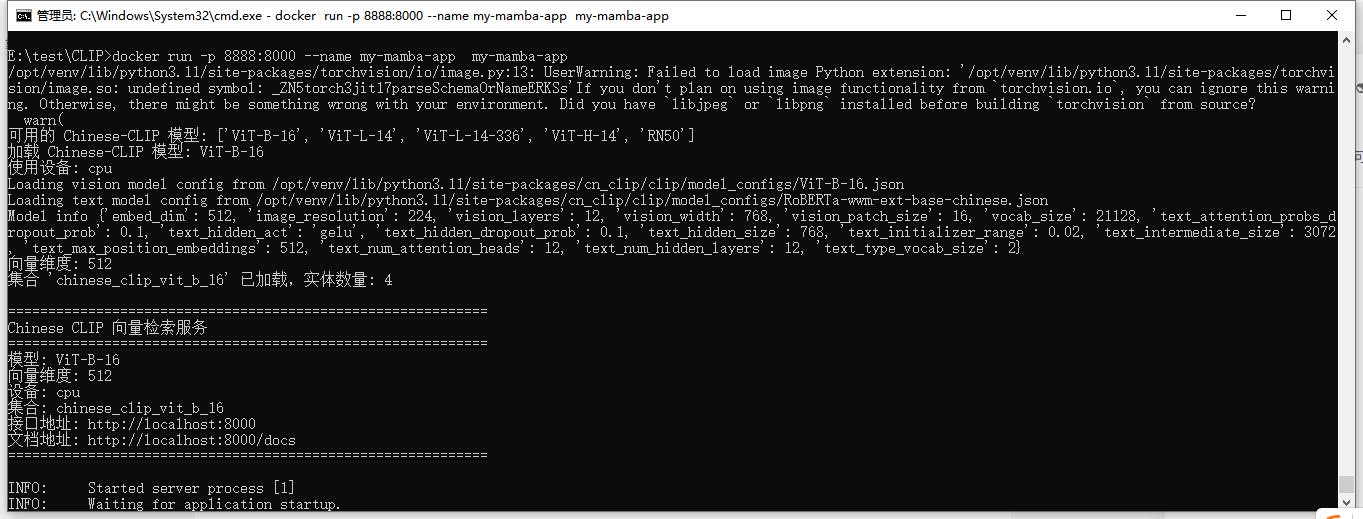
插入图片
猫
https://qcloud.dpfile.com/pc/bY0KHturZh_7sd0Cle2eqGN2ajzMkSSWdzxH6AWUw2qdxBVf06W34QcwP5N5Ww6B.jpg
狗
https://qcloud.dpfile.com/pc/vCSU-0FuMBhOp2JVSPD1cqlidd3MBEfaBxFpg_uQQgzUGeLlqELqBxhddrnp0Ggh.jpg
鱼
https://pic.rmb.bdstatic.com/bjh/down/wzzXSRV6iDrYtpW_cYifoQ621c2281fb3ace4fb45da7769238b10d.jpg?for=bg
老虎
https://pics1.baidu.com/feed/8c1001e93901213fb78b24b6896f04c12e2e95bc.jpeg@f_auto?token=624bfe05947d1e08aab19f04e8c2fbc4