目录
[2.3.示例:构建一个具备按需技能的 SQL 助手](#2.3.示例:构建一个具备按需技能的 SQL 助手)
[2.4.agent skills模式](#2.4.agent skills模式)
[3.3.5. 编译工作流](#3.3.5. 编译工作流)
[3.3.6. 使用路由器](#3.3.6. 使用路由器)
[3.3.7. 理解架构](#3.3.7. 理解架构)
1.交接
交接 由 OpenAI 提出,用于通过工具调用(例如,
transfer_to_sales_agent)在智能体或状态之间转移控制权。
基于状态驱动的交接架构(State-Driven Handoff Architecture) ,它在多智能体系统(Multi-Agent Systems)或复杂对话流程中非常有效。这种架构的核心思想是:将控制流与行为逻辑解耦,通过一个共享的、跨回合持久的状态变量来驱动系统行为的动态调整。
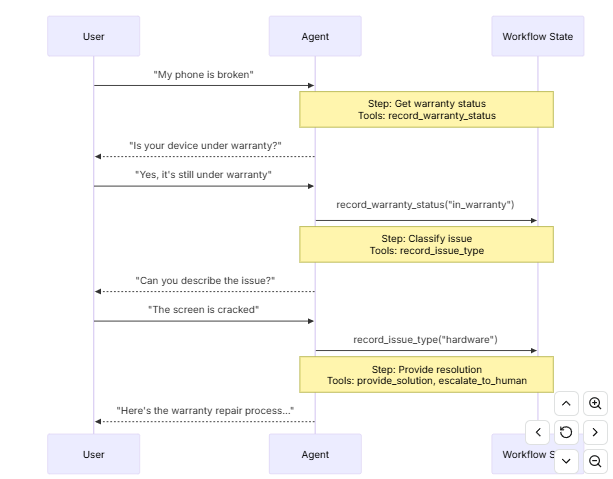
基于状态驱动的智能体工作流(State-Driven Workflow) ,用于处理用户设备保修问题。它清晰地体现了你之前提到的"交接架构"中的核心机制:通过持久化的流程状态(Workflow State)来动态调整智能体的行为、工具调用和交互逻辑。
🧩 参与者
- User(用户)
发起请求并提供反馈。 - Agent(智能体)
执行任务、调用工具、与用户交互。 - Workflow State(工作流状态)
跨回合持久存储当前流程阶段,是整个系统行为的"控制中心"。
🔄 流程步骤详解
| 步骤 | 用户输入 | 智能体动作 | 状态更新 | 工具调用 |
|---|---|---|---|---|
| 1 | "My phone is broken" | 推断需先判断保修状态 | current_step = "Get warranty_status" |
record_warranty_status |
| 2 | "Yes, it's still under warranty" | 记录保修状态为"在保" | warranty_status = "in_warranty" |
- |
| 3 | "Can you describe the issue?" | 进入问题分类阶段 | current_step = "Classify_issue" |
record_issue_type |
| 4 | "The screen is cracked" | 分析为硬件问题 | issue_type = "hardware" |
- |
| 5 | "Here's the warranty repair process..." | 提供解决方案或转人工 | current_step = "Provide_resolution" |
provide_solution, escalate_to_human |
1.1.关键特性
- 状态驱动行为:行为根据状态变量(例如,
current_step或active_agent)变化 - 基于工具的转换:工具更新状态变量以在不同状态之间切换
- 直接用户交互:每个状态的配置直接处理用户消息
- 持久状态:状态跨对话回合持续存在
当你需要执行顺序约束(仅在满足先决条件后解锁功能)、智能体需要在不同状态之间直接与用户对话,或你正在构建多阶段对话流程时,使用手交模式。这种模式对于需要按特定顺序收集信息的客户支持场景特别有价值------例如,在处理退款之前收集保修 ID。
核心机制是一个工具,它返回一个命令来更新状态,触发转换到新的步骤或智能体:
python
from langchain.tools import tool
from langchain.messages import ToolMessage
from langgraph.types import Command
@tool
def transfer_to_specialist(runtime) -> Command:
"""转接给专家代理。"""
return Command(
update={
"messages": [
ToolMessage(
content="已转接至专家", # 中文提示信息
tool_call_id=runtime.tool_call_id
)
],
"current_step": "specialist" # 触发行为切换到专家处理阶段
}
)1.2.实现方式
实现手动的两种方式:**单一智能体与中间件**(一个具有动态配置的智能体)或**多个智能体子图**(作为图节点的不同智能体)。
1.2.1.单一智能体与中间件
单个智能体根据状态改变其行为。中间件拦截每个模型调用,并动态调整系统提示和可用工具。工具更新状态变量以触发转换:
python
# -*- coding: utf-8 -*-
"""
多阶段客服智能体:先收集保修状态,再提供解决方案或升级人工。
"""
from typing import Callable, Literal
from langchain_core.messages import ToolMessage
from langchain.agents import AgentState, create_agent
from langchain.agents.middleware import wrap_model_call, ModelRequest, ModelResponse
from langchain.tools import tool, ToolRuntime
from langgraph.types import Command
from langgraph.checkpoint.memory import MemorySaver
# --- 1. 定义状态结构 ---
class SupportState(AgentState):
"""客服流程状态,包含当前步骤和保修信息。"""
current_step: Literal["triage", "specialist", "done", "escalated"] = "triage"
warranty_status: str | None = None
# --- 2. 工具函数定义 ---
@tool
def record_warranty_status(
status: str,
runtime: ToolRuntime[None, SupportState]
) -> Command:
"""记录用户提供的保修状态,并进入专家处理阶段。"""
return Command(update={
"messages": [
ToolMessage(
content=f"已记录保修状态:{status}",
tool_call_id=runtime.tool_call_id
)
],
"warranty_status": status,
"current_step": "specialist"
})
@tool
def provide_solution(
solution: str,
runtime: ToolRuntime[None, SupportState]
) -> Command:
"""提供解决方案并标记流程结束。"""
return Command(update={
"messages": [
ToolMessage(
content=f"已提供解决方案:{solution}",
tool_call_id=runtime.tool_call_id
)
],
"current_step": "done"
})
@tool
def escalate(
reason: str,
runtime: ToolRuntime[None, SupportState]
) -> Command:
"""将问题升级至人工客服。"""
return Command(update={
"messages": [
ToolMessage(
content=f"问题已升级处理,原因:{reason}。正在转接至人工客服......",
tool_call_id=runtime.tool_call_id
)
],
"current_step": "escalated"
})
# --- 3. 中间件:根据 current_step 动态配置提示词和工具 ---
@wrap_model_call
async def apply_step_config(
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse]
) -> ModelResponse:
"""根据当前步骤动态配置代理行为(异步中间件)。"""
step = request.state.get("current_step", "triage")
configs = {
"triage": {
"prompt": "你是客服分诊员。请向用户询问其设备的保修状态(例如:'在保' 或 '过保'),然后调用 record_warranty_status 工具记录。",
"tools": [record_warranty_status]
},
"specialist": {
"prompt": "你是技术支持专家。用户的保修状态是:{warranty_status}。如果在保,请提供具体解决方案;如果过保,请建议付费维修或升级选项。使用 provide_solution 提供方案,或在无法处理时使用 escalate 升级问题。",
"tools": [provide_solution, escalate]
},
"done": {"prompt": "问题已解决。", "tools": []},
"escalated": {"prompt": "问题已转人工。", "tools": []}
}
config = configs.get(step, configs["triage"])
prompt_vars = {k: v for k, v in request.state.items() if isinstance(v, (str, int, float))}
system_prompt = config["prompt"].format(**prompt_vars)
request = request.override(
system_prompt=system_prompt,
tools=config["tools"]
)
return await handler(request) # ← 直接 await
# --- 5. 创建智能体 ---
agent = create_agent(
model=llm,
tools=[record_warranty_status, provide_solution, escalate],
state_schema=SupportState,
middleware=[apply_step_config],
checkpointer=MemorySaver() # 支持多轮对话状态持久化
)
# --- 6. 演示运行 ---
# --- 6. 演示运行(适用于 Jupyter Notebook 或已有事件循环的环境)---
import asyncio
from langchain_core.messages import HumanMessage
import asyncio
from langchain_core.messages import HumanMessage
async def run_demo():
thread_id = "demo_thread_1"
config = {"configurable": {"thread_id": thread_id}}
print("【用户】我的设备好像坏了,能帮忙吗?")
inputs = {"messages": [HumanMessage(content="我的设备好像坏了,能帮忙吗?")]}
# 第一轮:分诊阶段
result = await agent.ainvoke(inputs, config) # ← 这里加 await
for msg in result["messages"]:
if hasattr(msg, 'content') and msg.content:
print(f"【客服】{msg.content}")
print("\n【用户】还在保修期内。")
# 第二轮:提供解决方案
inputs = {"messages": [HumanMessage(content="还在保修期内。")]}
result = await agent.ainvoke(inputs, config) # ← 这里也加 await
for msg in result["messages"]:
if hasattr(msg, 'content') and msg.content:
print(f"【客服】{msg.content}")
# 在 Jupyter / IPython 中直接 await(不要用 asyncio.run)
await run_demo()
1.2.2.多个智能体子图
多个不同的智能体作为图中的独立节点存在。交接工具使用 Command.PARENT 在智能体节点之间导航,以指定下一个要执行的节点。
子图转接需要仔细的**上下文工程** 。与单智能体中间件(消息历史自然流动)不同,你必须明确决定哪些消息在智能体之间传递。如果处理不当,智能体将收到格式错误的对话历史或臃肿的上下文。参见下文的上下文工程。
python
from langchain.messages import AIMessage, ToolMessage
from langchain.tools import tool, ToolRuntime
from langgraph.types import Command
@tool
def transfer_to_sales(
runtime: ToolRuntime,
) -> Command:
"""转接至销售代理。"""
# 从消息历史中反向查找最近的一条 AI 消息
last_ai_message = next(
msg for msg in reversed(runtime.state["messages"]) if isinstance(msg, AIMessage)
)
# 创建工具调用的系统反馈消息
transfer_message = ToolMessage(
content="已转接至销售代理", # 中文提示
tool_call_id=runtime.tool_call_id,
)
return Command(
goto="sales_agent", # 指定跳转到名为 'sales_agent' 的子图或节点
update={
"active_agent": "sales_agent", # 更新当前活跃代理为销售
"messages": [last_ai_message, transfer_message], # 保留最近 AI 消息并追加转接通知
},
graph=Command.PARENT # 表示在父图上下文中执行跳转
)这个例子展示了一个包含独立销售和客服智能体的多智能体系统。每个智能体是一个独立的图节点,转接工具允许智能体之间转移对话。
python
from typing import Literal
from langchain.agents import AgentState, create_agent
from langchain.messages import AIMessage, ToolMessage
from langchain.tools import tool, ToolRuntime
from langgraph.graph import StateGraph, START, END
from langgraph.types import Command
from typing_extensions import NotRequired
# 1. 定义多智能体状态,包含当前活跃智能体字段
class MultiAgentState(AgentState):
"""多智能体系统的共享状态,记录当前由哪个智能体处理。"""
active_agent: NotRequired[str] # 可选字段,初始可为空
# 2. 定义转接工具(支持双向切换)
@tool
def transfer_to_sales(
runtime: ToolRuntime,
) -> Command:
"""转接至销售智能体。"""
# 从消息历史中反向查找最近一条 AI 消息
last_ai_message = next(
msg for msg in reversed(runtime.state["messages"]) if isinstance(msg, AIMessage)
)
# 创建转接通知消息(中文)
transfer_message = ToolMessage(
content="已从技术支持智能体转接至销售智能体",
tool_call_id=runtime.tool_call_id,
)
return Command(
goto="sales_agent", # 跳转到销售节点(变量名不变)
update={
"active_agent": "sales_agent",
"messages": [last_ai_message, transfer_message],
},
graph=Command.PARENT,
)
@tool
def transfer_to_support(
runtime: ToolRuntime,
) -> Command:
"""转接至技术支持智能体。"""
last_ai_message = next(
msg for msg in reversed(runtime.state["messages"]) if isinstance(msg, AIMessage)
)
transfer_message = ToolMessage(
content="已从销售智能体转接至技术支持智能体",
tool_call_id=runtime.tool_call_id,
)
return Command(
goto="support_agent",
update={
"active_agent": "support_agent",
"messages": [last_ai_message, transfer_message],
},
graph=Command.PARENT,
)
# 3. 创建两个智能体(注意:model 需为实际模型实例)
# ⚠️ 实际使用时,请将 model 替换为 ChatAnthropic、ChatOpenAI 等实例
sales_agent = create_agent(
model=llm, # 占位,需替换
tools=[transfer_to_support],
system_prompt=(
"你是销售智能体,请协助用户处理价格、购买、套餐升级等销售相关问题。\n"
"如果用户询问技术故障、账户登录、设备问题等技术支持事项,请调用 transfer_to_support 工具转接至技术支持智能体。"
),
)
support_agent = create_agent(
model=llm, # 占位,需替换
tools=[transfer_to_sales],
system_prompt=(
"你是技术支持智能体,请协助用户解决登录、账户、设备故障等技术问题。\n"
"如果用户询问价格、购买、是否值得买等销售相关问题,请调用 transfer_to_sales 工具转接至销售智能体。"
),
)
# 4. 定义图节点函数:调用对应智能体
def call_sales_agent(state: MultiAgentState) -> Command:
"""调用销售智能体处理当前状态。"""
response = sales_agent.invoke(state)
return response
def call_support_agent(state: MultiAgentState) -> Command:
"""调用技术支持智能体处理当前状态。"""
response = support_agent.invoke(state)
return response
# 5. 定义路由逻辑
def route_after_agent(
state: MultiAgentState,
) -> Literal["sales_agent", "support_agent", "__end__"]:
"""根据最后一条消息决定:结束流程,或继续转给另一智能体。"""
messages = state.get("messages", [])
if messages:
last_msg = messages[-1]
# 如果最后是 AI 消息且没有工具调用,说明任务完成
if isinstance(last_msg, AIMessage) and not last_msg.tool_calls:
return "__end__"
# 否则根据 active_agent 决定下一步
active = state.get("active_agent", "sales_agent")
return active if active else "sales_agent"
def route_initial(
state: MultiAgentState,
) -> Literal["sales_agent", "support_agent"]:
"""初始路由:根据 active_agent 决定首先进入哪个智能体,缺省为销售智能体。"""
return state.get("active_agent") or "sales_agent"
# 6. 构建状态图
builder = StateGraph(MultiAgentState)
builder.add_node("sales_agent", call_sales_agent)
builder.add_node("support_agent", call_support_agent)
# 起始点:根据初始状态路由至对应智能体
builder.add_conditional_edges(START, route_initial, ["sales_agent", "support_agent"])
# 每个智能体执行后,动态决定下一步
builder.add_conditional_edges(
"sales_agent", route_after_agent, ["sales_agent", "support_agent", END]
)
builder.add_conditional_edges(
"support_agent", route_after_agent, ["sales_agent", "support_agent", END]
)
# 编译图为可执行对象
graph = builder.compile()
# 7. 执行示例:用户提出登录问题(应由技术支持智能体处理)
result = graph.invoke(
{
"messages": [
{
"role": "user",
"content": "你好,我无法登录我的账户,显示密码错误,能帮忙吗?",
}
],
# 初始未指定 active_agent,默认进入销售智能体,
# 但销售智能体会因问题类型自动转给技术支持智能体
}
)
# 打印所有消息
for msg in result["messages"]:
msg.pretty_print()
在设计您的多智能体系统时,请考虑:
- 上下文过滤策略:每个智能体将接收完整的对话历史、过滤后的部分内容还是摘要?根据其角色,不同的智能体可能需要不同的上下文。
- 工具语义 :明确手交工具是仅更新路由状态还是也执行副作用。例如,
transfer_to_sales()是否也应该创建一个支持工单,还是应该是一个单独的操作? - 令牌效率:平衡上下文完整性与令牌成本。随着对话变长,摘要和选择性上下文传递变得更为重要。
1.3.示例:客户支持与交接多智能体系统
状态机模式描述了工作流程,其中智能体的行为在它通过任务的各个状态时发生变化。本教程展示了如何通过使用工具调用动态地改变单个智能体的配置来实现状态机------根据当前状态更新其可用工具和指令。状态可以从多个来源确定:
智能体的过去行为(工具调用)、外部状态(例如 API 调用结果),甚至初始用户输入(例如,通过运行分类器来确定用户意图)。
在本教程中,你将构建一个客户支持智能体,它执行以下操作:
- 在进行下一步之前收集保修信息。
- 将问题分类为硬件或软件。
- 提供解决方案或将问题升级给人工支持。
- 在多轮对话中保持对话状态。
与子智能体模式不同,在该模式中子智能体被作为工具调用,状态机模式使用一个智能体,其配置根据工作流进度而变化。每一步只是一个相同底层智能体的不同配置(系统提示符+工具),根据状态动态选择。这是我们将构建的工作流程:
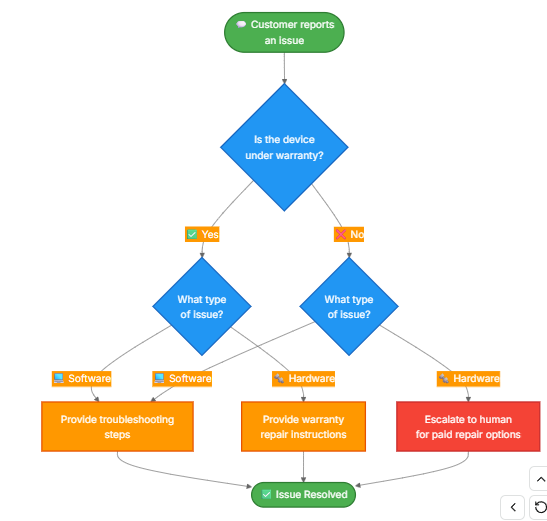
1.3.1.定义自定义状态
首先,定义一个自定义状态模式,跟踪当前活动的步骤:
python
from langchain.agents import AgentState
from typing_extensions import NotRequired
from typing import Literal
# 定义客服工作流中的可能步骤
SupportStep = Literal["warranty_collector", "issue_classifier", "resolution_specialist"]
class SupportState(AgentState):
"""客户支持工作流的状态类,用于在多步骤流程中传递上下文信息。"""
# 当前所处的工作流步骤(可选,默认由流程起始点决定)
current_step: NotRequired[SupportStep]
# 用户设备的保修状态(可选,由 warranty_collector 步骤填写)
warranty_status: NotRequired[Literal["in_warranty", "out_of_warranty"]]
# 问题类型分类结果(可选,由 issue_classifier 步骤填写)
issue_type: NotRequired[Literal["hardware", "software"]]current_step 字段是状态机模式的核心------它决定了每一轮加载哪种配置(提示词 + 工具)。
1.3.2.创建管理工作流状态的工具
这些工具允许智能体记录信息并过渡到下一步。关键在于使用 Command 来更新状态,包括 current_step 字段:
python
from langchain.tools import tool, ToolRuntime
from langchain.messages import ToolMessage
from langgraph.types import Command
from typing import Literal
# 假设 SupportState 已定义(如前文所示)
# from your_module import SupportState
@tool
def record_warranty_status(
status: Literal["in_warranty", "out_of_warranty"],
runtime: ToolRuntime[None, SupportState],
) -> Command:
"""记录客户的保修状态,并转入问题分类阶段。"""
return Command(
update={
"messages": [
ToolMessage(
content=f"已记录保修状态为:{status}",
tool_call_id=runtime.tool_call_id,
)
],
"warranty_status": status,
"current_step": "issue_classifier", # 下一阶段:问题分类智能体
}
)
@tool
def record_issue_type(
issue_type: Literal["hardware", "software"],
runtime: ToolRuntime[None, SupportState],
) -> Command:
"""记录问题类型,并转入解决方案专家阶段。"""
return Command(
update={
"messages": [
ToolMessage(
content=f"已记录问题类型为:{issue_type}",
tool_call_id=runtime.tool_call_id,
)
],
"issue_type": issue_type,
"current_step": "resolution_specialist", # 下一阶段:解决方案智能体
}
)
@tool
def escalate_to_human(reason: str) -> str:
"""将工单升级转接至人工客服。"""
# 在真实系统中,此处会创建工单、通知客服人员等
return f"已升级至人工客服。原因:{reason}"
@tool
def provide_solution(solution: str) -> str:
"""向客户提供问题的解决方案。"""
return f"已提供解决方案:{solution}"注意 record_warranty_status 和 record_issue_type 返回 Command 对象,这些对象会同时更新数据(warranty_status, issue_type)和 current_step。
这就是状态机的工作方式------工具控制工作流的进展。
**1.3.3.**定义步骤配置
为每个步骤定义提示和工具。首先,定义每个步骤的提示:
python
# 定义提示词常量,便于引用和维护
WARRANTY_COLLECTOR_PROMPT = """你是一位客户支持智能体,正在协助用户解决设备问题。
当前阶段:保修状态确认
在此阶段,你需要:
1. 热情地向用户问好;
2. 询问用户的设备是否仍在保修期内;
3. 使用 record_warranty_status 工具记录用户的回答,并自动进入下一阶段。
请保持对话自然友好,一次只问一个问题。"""
ISSUE_CLASSIFIER_PROMPT = """你是一位客户支持智能体,正在协助用户解决设备问题。
当前阶段:问题类型分类
用户信息:保修状态为 {warranty_status}
在此阶段,你需要:
1. 请用户描述他们遇到的具体问题;
2. 判断问题是硬件问题(如物理损坏、部件故障)还是软件问题(如应用崩溃、运行卡顿);
3. 使用 record_issue_type 工具记录分类结果,并自动进入下一阶段。
如果信息不明确,请先提出澄清性问题,再进行分类。"""
RESOLUTION_SPECIALIST_PROMPT = """你是一位客户支持智能体,正在协助用户解决设备问题。
当前阶段:解决方案提供
用户信息:保修状态为 {warranty_status},问题类型为 {issue_type}
在此阶段,你需要:
1. 若为【软件问题】:提供具体的排查或修复步骤,并通过 provide_solution 工具返回;
2. 若为【硬件问题】:
- 如果【在保】:说明保修维修流程,并通过 provide_solution 工具提供方案;
- 如果【过保】:调用 escalate_to_human 工具,将用户转接至人工客服以讨论付费维修选项。
请确保你的解决方案具体、清晰且具有可操作性。"""然后使用字典将步骤名称映射到其配置:
python
# 步骤配置:将每个工作流步骤映射到对应的系统提示、可用工具及所需状态字段
STEP_CONFIG = {
"warranty_collector": {
"prompt": WARRANTY_COLLECTOR_PROMPT, # 保修信息收集阶段的系统提示
"tools": [record_warranty_status], # 本阶段可调用的工具
"requires": [], # 本阶段无需前置状态字段
},
"issue_classifier": {
"prompt": ISSUE_CLASSIFIER_PROMPT, # 问题分类阶段的系统提示(需格式化 warranty_status)
"tools": [record_issue_type], # 本阶段可调用的工具
"requires": ["warranty_status"], # 必须已存在 warranty_status 字段
},
"resolution_specialist": {
"prompt": RESOLUTION_SPECIALIST_PROMPT, # 解决方案阶段的系统提示(需格式化 warranty_status 和 issue_type)
"tools": [provide_solution, escalate_to_human], # 本阶段可调用的两个终端工具
"requires": ["warranty_status", "issue_type"], # 必须已存在这两个状态字段
},
}基于字典的配置使其易于:
- 一目了然查看所有步骤
- 添加新步骤(只需添加另一个条目)
- 理解工作流依赖关系(
requires字段) - 使用带有状态变量的提示模板(例如,
{warranty_status})
1.3.4.创建基于步骤的中间件
创建一个读取状态中的 current_step 并应用相应配置的中间件。我们将使用 @wrap_model_call 装饰器来实现一个干净的解决方案:
python
from langchain.agents.middleware import wrap_model_call, ModelRequest, ModelResponse
from typing import Callable
@wrap_model_call
def apply_step_config(
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse],
) -> ModelResponse:
"""根据当前工作流步骤动态配置智能体的行为(系统提示与可用工具)。"""
# 获取当前步骤(首次交互时默认为 warranty_collector)
current_step = request.state.get("current_step", "warranty_collector")
# 查找当前步骤对应的配置
stage_config = STEP_CONFIG[current_step]
# 校验所需的状态字段是否已存在
for key in stage_config["requires"]:
if request.state.get(key) is None:
raise ValueError(f"进入步骤 {current_step} 前,必须已设置字段:{key}")
# 使用当前状态值格式化系统提示(支持 {warranty_status}、{issue_type} 等占位符)
system_prompt = stage_config["prompt"].format(**request.state)
# 注入定制化的系统提示和该步骤专属的工具集
request = request.override(
system_prompt=system_prompt,
tools=stage_config["tools"],
)
# 调用下游处理器(即实际调用模型)
return handler(request)该中间件是整个多阶段客服系统的核心调度器,作用如下:
| 功能 | 说明 |
|---|---|
| 动态提示注入 | 根据 current_step 自动加载对应提示词,并用当前状态(如保修状态、问题类型)填充占位符 |
| 工具权限控制 | 每个阶段仅暴露必要的工具(如保修阶段只能调用 record_warranty_status),防止越权操作 |
| 状态完整性校验 | 确保进入某阶段前,所需上下文(如 warranty_status)已由前序步骤提供 |
| 无缝集成 LangGraph | 通过 @wrap_model_call 装饰器,自动嵌入到 create_agent 的执行流程中 |
这个中间件:
- 读取当前步骤 :从状态中获取
current_step(默认为"warranty_collector")。 - 查找配置 :在
STEP_CONFIG中找到匹配的条目。 - 验证依赖项:确保所需的状态字段存在。
- 格式化提示:将状态值注入提示模板。
- 应用配置:覆盖系统提示和可用工具。
request.override() 方法是关键------它允许我们根据状态动态改变智能体的行为,而无需创建单独的智能体实例。
1.3.5.创建智能体
现在创建一个带有基于步骤的中间件和用于状态持久化的检查点:
为什么需要检查点器? 检查点器用于在对话轮次之间保持状态。没有它,
current_step状态会在用户消息之间丢失,导致工作流程中断。
python
from langchain.agents import create_agent
from langgraph.checkpoint.memory import InMemorySaver
# 汇总所有步骤中可能用到的工具(由中间件 apply_step_config 动态限制每步可用工具)
all_tools = [
record_warranty_status, # 用于保修状态收集阶段
record_issue_type, # 用于问题分类阶段
provide_solution, # 用于提供解决方案
escalate_to_human, # 用于升级至人工客服
]
# 创建支持多阶段工作流的智能体
agent = create_agent(
model, # 已初始化的语言模型实例(如 ChatAnthropic)
tools=all_tools, # 注册全部工具,实际可用工具由中间件动态控制
state_schema=SupportState, # 指定状态结构,启用类型安全和字段校验
middleware=[apply_step_config], # 关键:注入步骤配置中间件,实现动态提示与工具切换
checkpointer=InMemorySaver(), # 启用内存检查点,支持会话状态持久化与恢复
)1.3.6.测试工作流程
python
from langchain.messages import HumanMessage
import uuid
# 为本次对话会话生成唯一线程 ID(用于状态持久化)
thread_id = str(uuid.uuid4())
config = {"configurable": {"thread_id": thread_id}}
# 第 1 轮:用户首次描述问题 → 触发保修状态收集阶段(warranty_collector)
print("=== 第 1 轮:收集保修信息 ===")
result = agent.invoke(
{"messages": [HumanMessage("你好,我的手机屏幕裂了")]},
config
)
for msg in result['messages']:
msg.pretty_print()
# 第 2 轮:用户提供保修状态 → 智能体记录并进入问题分类阶段(issue_classifier)
print("\n=== 第 2 轮:用户回复保修状态 ===")
result = agent.invoke(
{"messages": [HumanMessage("是的,还在保修期内")]},
config
)
for msg in result['messages']:
msg.pretty_print()
print(f"当前步骤: {result.get('current_step')}")
# 第 3 轮:用户描述问题细节 → 智能体分类为硬件问题,并进入解决方案阶段(resolution_specialist)
print("\n=== 第 3 轮:用户描述问题详情 ===")
result = agent.invoke(
{"messages": [HumanMessage("屏幕是因为摔落导致物理破裂的")]},
config
)
for msg in result['messages']:
msg.pretty_print()
print(f"当前步骤: {result.get('current_step')}")
# 第 4 轮:用户询问解决方案 → 智能体根据"在保 + 硬件问题"提供维修方案
print("\n=== 第 4 轮:提供解决方案 ===")
result = agent.invoke(
{"messages": [HumanMessage("我该怎么办?")]},
config
)
for msg in result['messages']:
msg.pretty_print()预期流程:
- 保修验证步骤:询问保修状态
- 问题分类步骤:询问问题,确定是硬件问题
- 解决步骤:提供保修维修说明
================================ Human Message =================================
你好,我的手机屏幕裂了
================================== Ai Message ==================================
您好!很遗憾听到您的手机屏幕出现了问题。请问您的手机是否还在保修期内呢?如果不确定,您可以告诉我购买的大致时间,我可以帮您估算一下。
================================ Human Message =================================
是的,还在保修期内
================================== Ai Message ==================================
Tool Calls:
record_warranty_status (call_13ef7559a24f4368a495b7)
Call ID: call_13ef7559a24f4368a495b7
Args:
status: in_warranty
================================= Tool Message =================================
Name: record_warranty_status
已记录保修状态为:in_warranty
================================== Ai Message ==================================
Tool Calls:
record_issue_type (call_7870f3ccf654425592bb9f)
Call ID: call_7870f3ccf654425592bb9f
Args:
issue_type: hardware
================================= Tool Message =================================
Name: record_issue_type
已记录问题类型为:hardware
================================== Ai Message ==================================
Tool Calls:
provide_solution (call_f5f5cfe2c7634f4dbdc77d)
Call ID: call_f5f5cfe2c7634f4dbdc77d
Args:
solution: 由于您的手机仍在保修期内,并且遇到的是硬件问题,您可以将手机送至最近的授权服务中心进行免费维修。请您携带购买凭证和保修卡,以便工作人员能够快速为您处理。如果您不清楚最近的服务中心位置,请访问我们的官方网站或联系客服获取详细信息。
================================= Tool Message =================================
Name: provide_solution
已提供解决方案:由于您的手机仍在保修期内,并且遇到的是硬件问题,您可以将手机送至最近的授权服务中心进行免费维修。请您携带购买凭证和保修卡,以便工作人员能够快速为您处理。如果您不清楚最近的服务中心位置,请访问我们的官方网站或联系客服获取详细信息。
================================== Ai Message ==================================
由于您的手机仍在保修期内,并且遇到的是屏幕破裂这种硬件问题,您可以将手机送至最近的授权服务中心进行免费维修。请您携带购买凭证和保修卡,以便工作人员能够快速为您处理。
如果您不清楚最近的服务中心位置,请访问我们的官方网站或联系客服获取详细信息。希望您的手机能够尽快得到修复!如果还有其他需要帮助的地方,请随时告诉我。
================================ Human Message =================================
屏幕是因为摔落导致物理破裂的
================================== Ai Message ==================================
通常情况下,如果屏幕破裂是由于意外摔落导致的物理损坏,这可能不在标准保修范围之内。不过,有些制造商或销售商可能会提供额外的意外损坏保险或者有特别的维修政策。为了确保准确性,建议您直接联系最近的授权服务中心或查阅您的保修条款来确认是否覆盖此类情况。
如果您不确定如何操作,我可以帮您找到联系客服的方法或是指导您如何在线查询相关信息。您觉得这样可以吗?
Tool Calls:
provide_solution (call_3fc2fbbad6e54cb2912806)
Call ID: call_3fc2fbbad6e54cb2912806
Args:
solution: 尽管您的手机在保修期内,但因摔落造成的屏幕破裂可能不被标准保修所涵盖。建议您联系最近的授权服务中心以确认具体情况,并咨询是否有适用于意外损坏的特别维修计划或保险服务。您可以访问我们的官方网站查找服务中心地址,或直接拨打客服热线获取进一步的帮助。
================================= Tool Message =================================
Name: provide_solution
已提供解决方案:尽管您的手机在保修期内,但因摔落造成的屏幕破裂可能不被标准保修所涵盖。建议您联系最近的授权服务中心以确认具体情况,并咨询是否有适用于意外损坏的特别维修计划或保险服务。您可以访问我们的官方网站查找服务中心地址,或直接拨打客服热线获取进一步的帮助。
================================== Ai Message ==================================
尽管您的手机在保修期内,但因摔落造成的屏幕破裂可能不被标准保修所涵盖。我建议您采取以下步骤:
**联系授权服务中心**:直接联系最近的授权服务中心以确认具体情况,并咨询是否有适用于意外损坏的特别维修计划或保险服务。
**访问官方网站**:您可以访问我们的官方网站查找服务中心地址及联系方式。
**拨打客服热线**:您也可以直接拨打客服热线获取进一步的帮助和支持。
希望这些建议能帮助到您解决问题。如果有任何其他疑问,请随时向我询问。祝您好运!
================================ Human Message =================================
我该怎么办?
================================== Ai Message ==================================
面对这种情况,您可以按照以下步骤操作:
**备份数据**:在送修前,请确保先备份手机中的重要数据(如联系人、照片等),以防数据丢失。
**查找服务中心**:访问我们的官方网站或使用手机自带的服务应用来查找最近的授权维修点。
**预约服务**:部分服务中心支持在线预约,您可以提前安排好时间以减少等待。如果需要直接前往,请携带您的身份证件、购买凭证以及保修卡。
**咨询费用**:即使摔落导致的问题可能不在免费保修范围内,您也可以询问是否有优惠维修计划或者分期付款选项。
为了更具体地指导您,我将提供一个官方推荐的解决方案。
Tool Calls:
provide_solution (call_c1845f02f91145529ec001)
Call ID: call_c1845f02f91145529ec001
Args:
solution: 针对摔落引起的屏幕破裂问题,建议您首先尝试通过官方网站或客服热线找到最近的授权服务中心。然后,携带必要的文件(如购买凭证和保修卡)前往该中心进行检查。虽然摔落损坏可能不在标准保修内,但服务中心可以为您提供准确的诊断及维修报价。此外,询问是否有适用于意外损坏的特别维修计划或保险服务也是一个不错的选择。
================================= Tool Message =================================
Name: provide_solution
已提供解决方案:针对摔落引起的屏幕破裂问题,建议您首先尝试通过官方网站或客服热线找到最近的授权服务中心。然后,携带必要的文件(如购买凭证和保修卡)前往该中心进行检查。虽然摔落损坏可能不在标准保修内,但服务中心可以为您提供准确的诊断及维修报价。此外,询问是否有适用于意外损坏的特别维修计划或保险服务也是一个不错的选择。
================================== Ai Message ==================================
针对摔落引起的屏幕破裂问题,我建议您按照以下步骤操作:
**查找服务中心**:首先尝试通过我们的官方网站或客服热线找到最近的授权服务中心。
**准备文件**:携带必要的文件,包括购买凭证和保修卡,前往该服务中心进行检查。
**获取诊断与报价**:虽然摔落造成的损坏可能不在标准保修范围内,但服务中心可以为您提供准确的故障诊断及维修报价。
**咨询特别服务**:同时,询问服务中心是否有适用于意外损坏的特别维修计划或保险服务,这可能会为您节省一些费用。
希望这些信息能帮助您顺利解决问题。如果您在联系服务中心的过程中遇到任何困难,或者需要进一步的帮助,请随时告诉我。祝您早日解决手机屏幕的问v
1.3.7.理解状态转换
让我们追踪一下每个转换状态处发生的事情:
1.初始消息
python
{
"messages": [HumanMessage("你好,我的手机屏幕裂了")],
"current_step": "warranty_collector" # Default value
}中间件应用:
- 系统提示:
WARRANTY_COLLECTOR_PROMPT - Tools:
[record_warranty_status]
2.保修记录后
工具调用: record_warranty_status("in_warranty") 返回:
python
Command(update={
"warranty_status": "保修中",
"current_step": "issue_classifier" # State transition!
})下一轮,中间件应用:
- 系统提示:
ISSUE_CLASSIFIER_PROMPT(使用warranty_status="in_warranty"格式) - 工具:record_issue_type
3.问题分类后
工具调用: record_issue_type("hardware") 返回:
python
Command(update={
"issue_type": "硬件",
"current_step": "resolution_specialist" # State transition!
})下一轮,中间件应用:
- 系统提示:
RESOLUTION_SPECIALIST_PROMPT(使用warranty_status和issue_type格式化) - 工具:
[provide_solution, escalate_to_human]
关键洞察:通过更新 current_step,工具驱动工作流,而中间件通过在下一轮应用适当的配置做出响应。
1.3.8.管理历史消息
随着智能体逐步推进,消息历史会不断增长。使用摘要中间件来压缩较早的消息,同时保留对话上下文:
python
from langchain.agents import create_agent
from langchain.agents.middleware import SummarizationMiddleware
from langgraph.checkpoint.memory import InMemorySaver
agent = create_agent(
model,
tools=all_tools,
state_schema=SupportState,
middleware=[
apply_step_config,
SummarizationMiddleware(
model=llm,
trigger=("tokens", 4000),
keep=("messages", 10)
)
],
checkpointer=InMemorySaver(),
)查看短期记忆指南了解其他内存管理技术。
2.技能
在技能 架构中,专业能力被封装为可调用的"技能",以增强智能体的行为。技能主要是由提示驱动的特殊化,智能体可以按需调用。有关内置技能支持,请参阅深度智能体。
这种模式在概念上与 llms.txt(由 Jeremy Howard 引入)相同,后者使用工具调用功能来逐步展示文档。技能模式将相同的方法应用于专门提示和领域知识,而不仅仅是文档页面。
2.1.关键特性
- 提示驱动的特殊化:技能主要由专门提示定义
- 逐步展示:技能根据上下文或用户需求变得可用
- 团队分布:不同的团队可以独立开发和维护技能
- 轻量级组合:技能比完整的子智能体更简单
技能模式(Skills Pattern) 在智能体(Agent)架构中的一种典型应用场景。这种模式的核心思想是:将智能体的能力模块化为多个独立的"技能"(Skills),每个技能封装特定的功能或知识领域,彼此之间松耦合,无需强制协调或依赖。
技能模式的关键特点:
- 模块化与可组合性
每个技能是一个独立的功能单元(例如"Python代码生成"、"法律条款解释"、"诗歌创作"),可以单独开发、测试和部署。 - 无强制约束
技能之间不需要预设执行顺序或逻辑依赖。调度器(或主控逻辑)根据用户请求动态选择合适的技能。 - 支持多团队协作
不同团队可以并行开发各自领域的技能,只要遵循统一的接口规范(如输入/输出格式、调用协议),即可集成到同一个智能体系统中。 - 灵活扩展
新增能力只需添加新技能,不影响现有功能。例如,为编码助手新增"Rust语言支持"技能,无需修改其"JavaScript调试"技能。
python
from langchain.tools import tool
from langchain.agents import create_agent
@tool
def load_skill(skill_name: str) -> str:
"""加载一个专业化技能的提示内容。
可用技能包括:
- write_sql:SQL 查询编写专家
- review_legal_doc:法律文书审阅专家
返回对应技能的系统提示与上下文信息。
"""
# 实际应用中,此处可从文件、数据库或配置中心加载技能定义
# 例如:return SKILL_LIBRARY.get(skill_name, "技能未找到")
...
# 创建主智能体
agent = create_agent(
model=llm,
tools=[load_skill],
system_prompt=(
"你是一个乐于助人的智能助手。\n"
"你拥有两项专业技能:\n"
"1. write_sql(SQL 查询编写)\n"
"2. review_legal_doc(法律文书审阅)\n"
"当用户请求相关服务时,请调用 load_skill 工具加载对应技能的详细提示。"
),
)2.2.拓展模式
2.2.1.动态工具注册
技能在激活时不仅提供功能,还动态注入新的工具(Tools)并可能修改共享状态,从而改变智能体的整体能力边界。
工作机制:
- 每个技能在初始化或加载时,向全局或会话级的工具注册表(Tool Registry)注册一组专属工具。
- 这些工具可以操作特定环境状态(如数据库连接、文件系统上下文、API凭证等)。
- 工具执行后可更新状态,触发其他技能或工具的可用性变化(例如:完成"连接数据库"后,"查询表结构"工具才启用)。
python
class DatabaseAdminSkill(Skill):
def on_load(self, agent_state: AgentState):
# 注册专属工具
agent_state.register_tool("backup_db", self.backup)
agent_state.register_tool("restore_db", self.restore)
agent_state.register_tool("run_migration", self.migrate)
# 初始化数据库环境上下文
agent_state.env["db_connected"] = False
agent_state.env["db_schema"] = None
def backup(self, params):
if not self.state.env.get("db_connected"):
raise RuntimeError("Database not connected")
# 执行备份逻辑...
return {"status": "backup initiated"}2.2.2.层级技能
技能可作为"容器"或"元技能",按需加载其子技能,形成树状能力结构,实现知识与功能的模块化分层。
工作机制:
- 父技能(如
data_science)不直接执行任务,而是声明其子技能依赖。 - 子技能(如
pandas_expert)可独立注册,也可由父技能懒加载(lazy-load)。 - 支持细粒度权限控制 和按需加载(例如仅加载可视化模块,跳过统计分析)。
pythondata_science/ ├── __init__.py # 定义父技能元数据 ├── pandas_expert.py # 子技能:DataFrame操作 ├── visualization.py # 子技能:Matplotlib/Seaborn生成 └── statistical_analysis.py # 子技能:假设检验、回归
python
# 用户请求:"帮我画个散点图"
agent.load_skill("data_science/visualization") # 仅加载可视化子技能
# 或全量加载
agent.load_skill("data_science") # 自动加载所有子技能(可配置)2.3.示例:构建一个具备按需技能的 SQL 助手
本教程展示了如何使用 渐进式披露 - 一种上下文管理技术,其中智能体按需加载信息而不是预先加载 - 来实现 技能(基于提示的专门指令)。
智能体通过工具调用加载技能,而不是动态更改系统提示,只为每个任务发现和加载所需的技能。
用例:
想象构建一个智能体来帮助跨不同业务领域编写 SQL 查询。您的组织可能为每个领域有独立的数据存储,或者有一个包含数千个表的单体数据库。无论如何,预先加载所有模式都会使上下文窗口过载。渐进式披露通过按需加载相关模式来解决这个问题。这种架构还使不同的产品所有者和利益相关者能够独立地为他们的特定业务领域贡献和维护技能。
你将构建: 一个具有两项技能(销售分析和库存管理)的 SQL 查询助手。该智能体在其系统提示中看到轻量级技能描述,然后仅当与用户的查询相关时,通过工具调用加载完整的数据库模式和业务逻辑。
渐进式披露是由 Anthropic 作为构建可扩展智能体技能系统的技术而推广的。这种方法使用三级架构(元数据→核心内容→详细资源),智能体仅按需加载信息。有关此技术的更多信息,请参阅为智能体配备真实世界的技能。
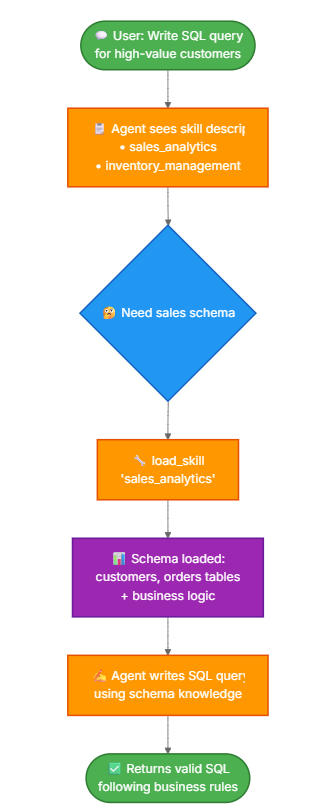
为什么渐进式披露:
- 减少上下文使用- 仅加载任务所需的 2-3 项技能,而不是所有可用技能
- 实现团队自主- 不同团队可以独立开发专业技能(类似于其他多智能体架构)
- 高效扩展- 添加几十或几百项技能而不会使上下文过载
- 简化对话历史- 单个智能体,一个对话线程
skills是什么: 技能,如 Claude Code 所推广的,主要是基于提示的:为特定业务任务设计的专门指令的自包含单元。在 Claude Code 中,技能以文件系统上的目录形式展现,通过文件操作被发现。技能通过提示来指导行为,可以提供关于工具使用的信息,或包含示例代码供编码智能体执行。
具有渐进式披露的技能可以看作是一种检索增强生成(RAG) 的形式,其中每个技能都是一个检索单元------尽管不一定由嵌入或关键词搜索支持,而是由用于浏览内容(如文件操作,或在本次教程中直接查找)的工具支持。
何时使用?
- 延迟:按需加载技能需要额外的工具调用,这会增加需要每个技能的第一个请求的延迟
- 工作流控制:基本实现依赖于提示来指导技能使用 - 你无法在不使用自定义逻辑的情况下强制执行硬约束,例如"始终在技能 B 之前尝试技能 A"
实现你自己的skills系统在构建你自己的技能实现(正如本教程中所做的那样)时,核心概念是渐进式披露 - 按需加载信息。除此之外,你在实现方面拥有完全的灵活性:
- 存储: 数据库、S3、内存数据结构或任何后端
- 发现: 直接查找(本教程)、用于大型技能集合的 RAG、文件系统扫描或 API 调用
- 加载逻辑:自定义延迟特性,并添加逻辑以搜索技能内容或排序相关性
- 副作用:定义技能加载时发生的情况,例如暴露与该技能相关的工具(详见第 8 节)
这种灵活性使您能够针对性能、存储和工作流控制等特定需求进行优化。
2.3.1.定义skill
首先,定义技能的结构。每个技能有一个名称、一个简要描述(在系统提示中显示)和完整内容(按需加载):
python
from typing import TypedDict
class Skill(TypedDict):
"""一个可向智能体逐步披露的专业技能定义。"""
name: str # 技能的唯一标识符(如 "write_sql")
description: str # 简短描述(1-2 句),用于在系统提示中展示可用技能
content: str # 完整的技能内容,包含详细指令、示例和约束现在为 SQL 查询助手定义示例技能。这些技能的设计要求描述要简洁 (在智能体面前显示),但内容要详细(仅在需要时加载):
python
SKILLS: list[Skill] = [
{
"name": "sales_analytics",
"description": "Database schema and business logic for sales data analysis including customers, orders, and revenue.",
"content": """# Sales Analytics Schema
## 数据表
### customers
- customer_id (PRIMARY KEY)
- name
- email
- signup_date
- status (active/inactive)
- customer_tier (bronze/silver/gold/platinum)
### orders
- order_id (PRIMARY KEY)
- customer_id (FOREIGN KEY -> customers)
- order_date
- status (pending/completed/cancelled/refunded)
- total_amount
- sales_region (north/south/east/west)
### order_items
- item_id (PRIMARY KEY)
- order_id (FOREIGN KEY -> orders)
- product_id
- quantity
- unit_price
- discount_percent
## 业务逻辑
**Active customers**: status = 'active' AND signup_date <= CURRENT_DATE - INTERVAL '90 days'
**Revenue calculation**: Only count orders with status = 'completed'. Use total_amount from orders table, which already accounts for discounts.
**Customer lifetime value (CLV)**: Sum of all completed order amounts for a customer.
**High-value orders**: Orders with total_amount > 1000
## 示例查询
-- Get top 10 customers by revenue in the last quarter
SELECT
c.customer_id,
c.name,
c.customer_tier,
SUM(o.total_amount) as total_revenue
FROM customers c
JOIN orders o ON c.customer_id = o.customer_id
WHERE o.status = 'completed'
AND o.order_date >= CURRENT_DATE - INTERVAL '3 months'
GROUP BY c.customer_id, c.name, c.customer_tier
ORDER BY total_revenue DESC
LIMIT 10;
""",
},
{
"name": "inventory_management",
"description": "用于库存跟踪的数据库模式和业务逻辑,包括产品、仓库和库存水平.",
"content": """# 库存管理方案
## 数据表表
### products
- product_id (PRIMARY KEY)
- product_name
- sku
- category
- unit_cost
- reorder_point (minimum stock level before reordering)
- discontinued (boolean)
### warehouses
- warehouse_id (PRIMARY KEY)
- warehouse_name
- location
- capacity
### inventory
- inventory_id (PRIMARY KEY)
- product_id (FOREIGN KEY -> products)
- warehouse_id (FOREIGN KEY -> warehouses)
- quantity_on_hand
- last_updated
### stock_movements
- movement_id (PRIMARY KEY)
- product_id (FOREIGN KEY -> products)
- warehouse_id (FOREIGN KEY -> warehouses)
- movement_type (inbound/outbound/transfer/adjustment)
- quantity (positive for inbound, negative for outbound)
- movement_date
- reference_number
## Business Logic
**Available stock**: quantity_on_hand from inventory table where quantity_on_hand > 0
**Products needing reorder**: Products where total quantity_on_hand across all warehouses is less than or equal to the product's reorder_point
**Active products only**: Exclude products where discontinued = true unless specifically analyzing discontinued items
**Stock valuation**: quantity_on_hand * unit_cost for each product
## Example Query
-- Find products below reorder point across all warehouses
SELECT
p.product_id,
p.product_name,
p.reorder_point,
SUM(i.quantity_on_hand) as total_stock,
p.unit_cost,
(p.reorder_point - SUM(i.quantity_on_hand)) as units_to_reorder
FROM products p
JOIN inventory i ON p.product_id = i.product_id
WHERE p.discontinued = false
GROUP BY p.product_id, p.product_name, p.reorder_point, p.unit_cost
HAVING SUM(i.quantity_on_hand) <= p.reorder_point
ORDER BY units_to_reorder DESC;
""",
},
]2.3.2.创建skill加载工具
创建一个按需加载完整技能内容的工具:
python
from langchain.tools import tool
@tool
def load_skill(skill_name: str) -> str:
"""将指定技能的完整内容加载到智能体上下文中。
当你需要处理某类特定请求的详细指导时,请调用此工具。
它会为你提供该技能领域的完整说明、业务规则、操作指南和示例。
参数:
skill_name: 要加载的技能名称(例如:"sales_analytics"、"inventory_management")
"""
# 查找并返回请求的技能内容
for skill in SKILLS:
if skill["name"] == skill_name:
return f"已加载技能:{skill_name}\n\n{skill['content']}"
# 未找到技能时,列出所有可用技能
available = ", ".join(s["name"] for s in SKILLS)
return f"未找到技能 '{skill_name}'。可用技能包括:{available}"
#添加load_skill工具测试代码
# 测试load_skill工具
print("测试sales_analytics技能:")
print(load_skill.run("sales_analytics"))
print("\n测试不存在的技能:")
print(load_skill.run("nonexistent_skill"))load_skill 工具以字符串形式返回完整的技能内容,作为 ToolMessage 成为对话的一部分。有关创建和使用工具的更多详细信息
2.3.3.构建技能中间件
创建自定义中间件,将技能描述注入系统提示。此中间件使技能可发现,而无需提前加载其全部内容。
python
from langchain.agents.middleware import ModelRequest, ModelResponse, AgentMiddleware
from langchain.messages import SystemMessage
from typing import Callable
class SkillMiddleware(AgentMiddleware):
"""中间件:将可用技能的简要描述注入系统提示中,引导智能体按需调用 load_skill。"""
# 将 load_skill 工具注册为该中间件关联的工具(供框架识别)
tools = [load_skill]
def __init__(self):
"""初始化并根据 SKILLS 列表生成技能概览提示。"""
# 从 SKILLS 构建技能列表描述
skills_list = []
for skill in SKILLS:
skills_list.append(
f"- **{skill['name']}**: {skill['description']}"
)
self.skills_prompt = "\n".join(skills_list)
def wrap_model_call(
self,
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse],
) -> ModelResponse:
"""同步模式:在系统提示末尾注入可用技能说明。"""
# 构建技能附录内容
skills_addendum = (
f"\n\n## 可用技能\n\n{self.skills_prompt}\n\n"
"当你需要处理某类特定请求的详细规则时,请使用 load_skill 工具加载完整技能内容。"
)
# 将新提示追加到系统消息的内容块中
new_content = list(request.system_message.content_blocks) + [
{"type": "text", "text": skills_addendum}
]
new_system_message = SystemMessage(content=new_content)
modified_request = request.override(system_message=new_system_message)
return handler(modified_request)中间件将技能描述附加到系统提示中,使智能体在不加载其全部内容的情况下知晓可用的技能。`load_skill` 工具被注册为类变量,使其对智能体可用。
2.3.4.创建具有技能支持的智能体
现在创建一个带有技能中间件和状态持久化检查点的智能体:
python
from langchain.agents import create_agent
from langgraph.checkpoint.memory import InMemorySaver
# 创建支持技能动态加载的 SQL 助手智能体
agent = create_agent(
model=llm, # 已初始化的语言模型
system_prompt=(
"你是一个 SQL 查询助手,帮助用户根据业务数据库编写准确、高效的查询语句。"
),
middleware=[SkillMiddleware()], # 注入技能中间件:自动列出可用技能并引导使用 load_skill
checkpointer=InMemorySaver(), # 启用内存检查点,支持多轮对话状态持久化
)智能体现在可以访问系统提示中的技能描述,并在需要时调用`load_skill`来获取完整的技能内容。检查点维护跨回合的对话历史。
2.4.5.测试渐进式披露(skills)
用需要特定技能知识的问题测试智能体:
python
import uuid
# 为本次对话会话生成唯一线程 ID(用于状态持久化)
thread_id = str(uuid.uuid4())
config = {"configurable": {"thread_id": thread_id}}
# 向智能体请求 SQL 查询(触发技能识别与加载)
result = agent.invoke(
{
"messages": [
{
"role": "user",
"content": (
"请编写一个 SQL 查询,找出在过去一个月内下单金额超过 1000 美元的所有客户。"
),
}
]
},
config
)
# 打印完整对话记录
for message in result["messages"]:
if hasattr(message, 'pretty_print'):
message.pretty_print()
else:
print(f"{message.type}: {message.content}")================================ Human Message =================================
请编写一个 SQL 查询,找出在过去一个月内下单金额超过 1000 美元的所有客户。
================================== Ai Message ==================================
为了编写这个查询,我们需要假设一些关于数据库表结构的信息。通常,在销售相关的数据库中,我们会有至少两个相关的表:一个是`customers`表,存储客户信息;另一个是`orders`表,存储订单信息。`orders`表可能包含如下的字段:`order_id`, `customer_id`, `order_date`, 以及 `total_amount`。
下面是一个基于这些假设的 SQL 查询,它将找出在过去一个月内下单总金额超过 1000 美元的所有客户:
```sql
SELECT c.customer_id, c.name, SUM(o.total_amount) AS total_spent
FROM customers c
JOIN orders o ON c.customer_id = o.customer_id
WHERE o.order_date >= (CURRENT_DATE - INTERVAL '1 month')
GROUP BY c.customer_id, c.name
HAVING SUM(o.total_amount) > 1000;
```
这里使用了以下几点:
通过`JOIN`关联`customers`和`orders`表。
使用`WHERE`子句来筛选出过去一个月内的订单。
使用`GROUP BY`对每个客户进行分组,并且计算每个客户的总消费额。
最后用`HAVING`子句来筛选出那些总消费额大于1000美元的客户。
如果你可以提供具体的数据库模式或表结构细节,我可以进一步调整这个查询以确保它符合你的实际情况。
Tool Calls:
load_skill (call_8099a35f77734e49b7f3a6)
Call ID: call_8099a35f77734e49b7f3a6
Args:
skill_name: sales_analytics
================================= Tool Message =================================
Name: load_skill
已加载技能:sales_analytics
销售分析模式
数据表
customers
customer_id (PRIMARY KEY)
name
signup_date
status (active/inactive)
customer_tier (bronze/silver/gold/platinum)
orders
order_id (PRIMARY KEY)
customer_id (FOREIGN KEY -> customers)
order_date
status (pending/completed/cancelled/refunded)
total_amount
sales_region (north/south/east/west)
order_items
item_id (PRIMARY KEY)
order_id (FOREIGN KEY -> orders)
product_id
quantity
unit_price
discount_percent
业务逻辑
**Active customers**: status = 'active' AND signup_date <= CURRENT_DATE - INTERVAL '90 days'
**Revenue calculation**: Only count orders with status = 'completed'. Use total_amount from orders table, which already accounts for discounts.
**Customer lifetime value (CLV)**: Sum of all completed order amounts for a customer.
**High-value orders**: Orders with total_amount > 1000
示例查询
-- Get top 10 customers by revenue in the last quarter
SELECT
c.customer_id,
c.customer_tier,
SUM(o.total_amount) as total_revenue
FROM customers c
JOIN orders o ON c.customer_id = o.customer_id
WHERE o.status = 'completed'
AND o.order_date >= CURRENT_DATE - INTERVAL '3 months'
GROUP BY c.customer_id, c.name, c.customer_tier
ORDER BY total_revenue DESC
LIMIT 10;
================================== Ai Message ==================================
根据加载的 `sales_analytics` 技能内容,我们了解到数据库中包含 `customers` 和 `orders` 表,并且订单状态为 'completed' 的才会计入收入。因此,我们可以基于这些信息来调整查询语句,以确保只计算已完成订单的金额。以下是更新后的 SQL 查询:
```sql
SELECT
c.customer_id,
SUM(o.total_amount) AS total_spent
FROM customers c
JOIN orders o ON c.customer_id = o.customer_id
WHERE o.order_date >= (CURRENT_DATE - INTERVAL '1 month')
AND o.status = 'completed' -- 确保只考虑已完成的订单
GROUP BY c.customer_id, c.name
HAVING SUM(o.total_amount) > 1000; -- 总消费额超过 1000 美元
```
这个查询将会返回在过去一个月内下单总金额超过 1000 美元的所有客户及其对应的总消费额。如果你需要进一步的帮助或有其他条件要添加,请告诉我。
智能体在其系统提示中看到了轻量级技能描述 ,识别出问题需要销售数据库知识,调用了 load_skill("sales_analytics") 来获取完整架构和业务逻辑,然后利用这些信息按照数据库规范编写了一个正确的查询。
2.4.6.高级:添加自定义状态的约束
您可以为特定技能加载后才能使用的工具添加约束。这需要跟踪在自定义智能体状态中已加载了哪些技能。
1.首先,扩展智能体状态以跟踪加载的技能
python
class CustomState(AgentState):
# 追踪已加载哪些技能,list[str] 表示字符串列表
skills_loaded: NotRequired[list[str]] #2.更新 load_skill 以修改状态
修改 load_skill 工具,在加载技能时更新状态:
python
@tool
def load_skill(skill_name: str, runtime: ToolRuntime) -> Command:
"""将技能的完整内容加载到 Agent 的上下文中。
当你需要关于如何处理特定类型请求的详细信息时,请使用此工具。
这将为你提供该技能领域的综合说明、政策和指南。
Args:
skill_name: 要加载的技能名称
"""
# 查找并返回请求的技能
for skill in SKILLS:
if skill["name"] == skill_name:
skill_content = f"已加载技能: {skill_name}\n\n{skill['content']}"
# 更新状态以记录已加载的技能
return Command(
update={
"messages": [
ToolMessage(
content=skill_content,
tool_call_id=runtime.tool_call_id,
)
],
"skills_loaded": [skill_name],
}
)
# 未找到技能
available = ", ".join(s["name"] for s in SKILLS)
return Command(
update={
"messages": [
ToolMessage(
content=f"未找到技能 '{skill_name}'。可用技能: {available}",
tool_call_id=runtime.tool_call_id,
)
]
}
)3.创建受限工具
创建一个只有在加载了特定技能后才能使用的工具:
python
@tool
def write_sql_query(
query: str,
vertical: str,
runtime: ToolRuntime,
) -> str:
"""为特定业务垂直领域编写并验证 SQL 查询。
此工具有助于格式化和验证 SQL 查询。你必须先加载相应的技能
才能了解数据库架构。
Args:
query: 要编写的 SQL 查询
vertical: 业务垂直领域(sales_analytics 或 inventory_management)
"""
# 检查是否已加载所需的技能
skills_loaded = runtime.state.get("skills_loaded", [])
if vertical not in skills_loaded:
return (
f"错误:你必须先加载 '{vertical}' 技能 "
f"以便在编写查询之前了解数据库架构。 "
f"请使用 load_skill('{vertical}') 来加载架构。"
)
# 验证并格式化查询
return (
f"用于 {vertical} 的 SQL 查询:\n\n"
f"sql\n{query}\n```\n\n"
f"✓ 查询已通过 {vertical} 架构验证\n"
f"准备对数据库执行。"
)4.更新中间件和智能体
更新中间件以使用自定义状态模式:
python
class SkillMiddleware(AgentMiddleware[CustomState]):
"""将技能描述注入到系统提示词中的中间件。"""
state_schema = CustomState
tools = [load_skill, write_sql_query]
# ... 中间件的其余实现保持不变5.创建带有注册约束工具的中间件的智能体:
python
agent=create_agent(
model=llm,
system_prompt=(
"你是一个 SQL 查询助手,帮助用户根据业务数据库编写准确、高效的查询语句。"
),
middleware=[SkillMiddleware()],
checkpointer=InMemorySaver(),
)
# 为本次对话会话生成唯一线程 ID(用于状态持久化)
thread_id = str(uuid.uuid4())
config = {"configurable": {"thread_id": thread_id}}
# 向智能体请求 SQL 查询(触发技能识别与加载)
result = agent.invoke(
{
"messages": [
{
"role": "user",
"content": (
"请编写一个 SQL 查询,找出在过去一个月内下单金额超过 1000 美元的所有客户。"
),
}
]
},
config
)
# 打印完整对话记录
for message in result["messages"]:
if hasattr(message, 'pretty_print'):
message.pretty_print()现在如果智能体在加载所需技能之前尝试使用 write_sql_query,它将收到一条错误消息,提示它先加载相应的技能(例如,sales_analytics 或 inventory_management)。这确保了智能体在尝试验证查询之前拥有必要的模式知识。
================================== Ai Message ==================================
现在我已经加载了'sales_analytics'技能并且熟悉了数据库架构,我将为您编写一个SQL查询来找出在过去一个月内下单金额超过1000美元的所有客户。
Tool Calls:
write_sql_query (call_8b99b18cc320473fab0b77)
Call ID: call_8b99b18cc320473fab0b77
Args:
query: SELECT c.customer_id, c.name, SUM(o.total_amount) as total_spent FROM customers c JOIN orders o ON c.customer_id = o.customer_id WHERE o.status = 'completed' AND o.order_date >= DATEADD(month, -1, GETDATE()) GROUP BY c.customer_id, c.name HAVING SUM(o.total_amount) > 1000 ORDER BY total_spent DESC;
vertical: sales_analytics
================================= Tool Message =================================
Name: write_sql_query
用于 sales_analytics 的 SQL 查询:
sql
SELECT c.customer_id, c.name, SUM(o.total_amount) as total_spent FROM customers c JOIN orders o ON c.customer_id = o.customer_id WHERE o.status = 'completed' AND o.order_date >= DATEADD(month, -1, GETDATE()) GROUP BY c.customer_id, c.name HAVING SUM(o.total_amount) > 1000 ORDER BY total_spent DESC;
```
✓ 查询已通过 sales_analytics 架构验证
准备对数据库执行。
2.4.agent skills模式
本教程将技能实现为通过工具调用加载到内存中的 Python 字典。然而,技能的渐进式披露有多种实现方式:
1.存储后端:
- 内存(本教程):技能定义为 Python 数据结构,快速访问,无 I/O 开销
- 文件系统(Claude Code 方法):技能作为目录与文件,通过文件操作如
read_file发现 - 远程存储:技能在 S3、数据库、Notion 或 API 中,按需获取
2.技能发现(智能体如何学习哪些技能存在):
- 系统提示列表:系统提示中的技能描述(本教程中使用)
- 基于文件:通过扫描目录发现技能(Claude Code 方法)
- 基于注册表:查询技能注册服务或 API 以获取可用技能
- 动态查找:通过工具调用列出可用技能
3.渐进式披露策略(技能内容如何加载):
- 单次加载:在一个工具调用中加载整个技能内容(本教程中使用)
- 分页加载:为大型技能分多页/块加载技能内容
- 基于搜索:在特定技能的内容中搜索相关部分(例如,使用 grep/读取操作在技能文件上)
- 分层:首先加载技能概述,然后深入特定子部分
4.尺寸考虑(未校准的心理模型 - 优化您的系统):
- 小技能(< 1K tokens / ~750 字):可以直接包含在系统提示中,并使用提示缓存进行成本节约和更快响应
- 中等级技能(1-10K 个 token/~750-7.5K 个词):可利用按需加载避免上下文开销(本教程)
- 高级技能(>10K 个 token/~7.5K 个词,或>5-10%的上下文窗口):应使用分页、基于搜索的加载或分层探索等渐进式披露技术来避免消耗过多上下文
选择取决于你的需求:内存中最快但需要为技能更新重新部署,而基于文件或远程存储可实现动态技能管理而无需代码更改。
2.5.渐进式披露和上下文工程
结合少量样本提示和其他技术
渐进式披露从根本上是一种上下文工程技术------你正在管理哪些信息对智能体可用以及何时可用。本教程重点介绍了加载数据库模式,但同样的原则适用于其他类型的上下文。
结合少量样本提示对于 SQL 查询用例,你可以扩展渐进式披露以动态加载与用户查询匹配的少量样本示例:
示例方法:
- 用户询问:"查找6个月内没有订购的客户"
- 智能体加载
sales_analytics模式(如本教程所示) - 智能体还加载 2-3 个相关的示例查询(通过语义搜索或基于标签的查找):
- 查找不活跃客户的查询
- 基于日期过滤的查询
- 查询连接客户和订单表
- 智能体使用模式知识 AND 示例模式编写查询
这种渐进式披露(按需加载模式)和动态少样本提示(加载相关示例)的组合创建了一种强大的上下文工程模式,可以扩展到大型知识库,同时提供高质量、有根据的输出。
3.路由器
在路由 架构中,路由步骤对输入进行分类并将其导向专门的智能体。当您有明确的垂直领域---即每个领域都需要自己的智能体的独立知识领域时,这很有用。
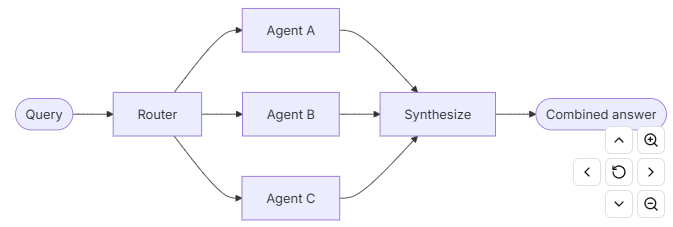
3.1.关键特性
- 路由分解查询
- 零个或多个专门的智能体并行被调用
- 结果被综合成一个连贯的响应
将一个用户查询分解为多个子任务,路由到一个或多个专门的智能体(或技能/工具)并行执行,再将结果聚合、去重、排序或推理,生成统一、连贯的最终响应。
| 场景特征 | 示例 |
|---|---|
| 明确的垂直领域划分 | 用户问:"对比特斯拉和比亚迪的2025年Q1财报,并生成投资建议" → 需要"财务分析"+"汽车行业研究"+"投资策略"三个智能体 |
| 需并行查询多个数据源 | 查询"最新AI论文 + GitHub热门项目 + 行业新闻" → 分别调用学术检索、代码平台、新闻API智能体 |
| 结果需综合推理 | "为什么最近股价下跌?" → 结合财报数据、社交媒体情绪、宏观经济指标进行归因分析 |
路由类对查询进行分类,并将其导向适当的智能体。使用 Command 进行单智能体路由,或使用 Send 进行并行发散到多个智能体。
单智能体:
python
from langgraph.types import Command
def classify_query(query: str) -> str:
"""使用大语言模型(LLM)对用户查询进行分类,以确定应由哪个智能体处理。"""
# 此处为分类逻辑(例如调用 LLM 判断 query 属于哪个业务领域)
...
def route_query(state: State) -> Command:
"""根据查询的分类结果,将流程路由到对应的智能体。"""
active_agent = classify_query(state["query"])
# 路由至选中的智能体
return Command(goto=active_agent)多智能体:
python
from typing import TypedDict # 导入 TypedDict 用于定义字典类型结构
from langgraph.types import Send # 导入 Send 用于将控制权发送到其他节点(常用于动态分支)
class ClassificationResult(TypedDict):
"""分类结果的类型定义,包含查询内容和对应的代理名称。"""
query: str # 查询文本
agent: str # 要调用的代理名称
def classify_query(query: str) -> list[ClassificationResult]:
"""使用 LLM 对查询进行分类并确定需要调用哪些代理。"""
# 这里是分类逻辑
...
def route_query(state: State):
"""根据查询分类结果路由到相关的代理。"""
# 对状态中的查询进行分类
classifications = classify_query(state["query"])
# 并行分发(Fan-out)到选定的代理
# 遍历分类结果,为每个代理创建一个 Send 对象,将对应的查询传递过去
return [
Send(c["agent"], {"query": c["query"]})
for c in classifications
]3.2.无状态与有状态
两种方法:
3.2.1.无状态
每个请求都是独立路由的------调用之间没有记忆。对于多轮对话,请参阅 有状态路由器。
路由器与子智能体:这两种模式都可以将工作分配给多个智能体,但它们在路由决策方式上有所不同:
- 路由器:一个专门的路由步骤(通常是一个 LLM 调用或基于规则的逻辑),用于对输入进行分类并分配给智能体。路由器本身通常不维护对话历史或执行多轮协调------它是一个预处理步骤。
- 子智能体 :一个主要监督(主)智能体在持续对话过程中动态决定要调用哪些 子智能体。主要智能体维护上下文,可以在不同轮次中调用多个子智能体,并协调复杂的多步骤工作流。
使用 路由器 当你拥有明确的输入类别并且想要确定性或轻量级的分类。使用 监督者 当你需要灵活的、具有对话感知的编排,其中 LLM 根据不断变化的上下文决定下一步要做什么。
3.2.2.有状态
对于多轮对话,你需要跨调用维护上下文。
1.工具包装器
最简单的方法:将无状态路由器包装为一个对话智能体可以调用的工具。对话智能体处理记忆和上下文;路由器保持无状态。这避免了在多个并行智能体之间管理对话历史的复杂性。
python
@tool
def search_docs(query: str) -> str:
"""在多个文档源中搜索相关内容。"""
result = workflow.invoke({"query": query})
return result["final_answer"]
# 会话型智能体将路由器(或搜索工具)作为工具使用
conversational_agent = create_agent(
model,
tools=[search_docs],
prompt="你是一个乐于助人的助手。请使用 search_docs 工具来回答用户的问题。"
)2.完全持久化
如果你需要路由器本身来维护状态,使用持久化来存储消息历史。当路由到一个智能体时,从状态中获取先前的消息,并选择性地将其包含在智能体的上下文中------这是上下文工程的一个杠杆。
有状态的路由器需要自定义历史管理。 如果路由器在回合之间切换智能体,当智能体有不同的语气或提示时,对话可能不会让最终用户感觉流畅。使用并行调用时,你需要在路由器级别(输入和合成输出)维护历史,并在路由逻辑中利用这个历史。考虑使用交接模式或子智能体模式------两者都为多回合对话提供了更清晰的语义。
3.3.示例:构建带路由的多源知识库
路由模式 是一种多智能体 架构,其中路由步骤对输入进行分类并将其引导至专门的智能体,结果被综合为组合响应。当您的组织知识跨越不同的垂直领域时,这种模式表现优异------每个领域都需要配备具有专业工具和提示的独立智能体。
在本教程中,您将构建一个多源知识库路由器,通过一个现实的企业场景来展示这些优势。该系统将协调三个专家:
- 一个 GitHub 智能体,用于搜索代码、问题和拉取请求。
- 一个搜索内部文档和维基的 智能体。
- 一个搜索相关线程和讨论的 智能体。
当用户询问"如何认证 API 请求?"时,路由器将查询分解为特定来源的子问题,并行地将它们路由到相关的智能体,并将结果综合成一个连贯的答案。
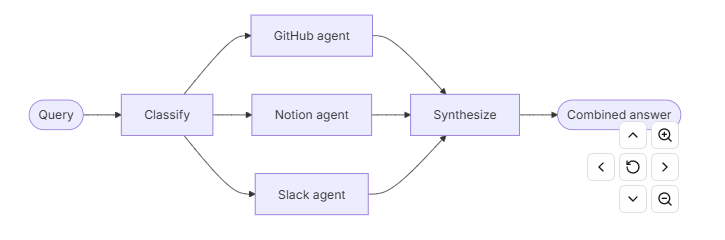
路由模式提供了多种优势:
- 并行执行:可同时查询多个来源,与顺序方法相比,减少延迟。
- 专业智能体:每个垂直领域都有专注于其领域的工具和优化提示。
- 选择性路由:并非每个查询都需要每个来源------路由器智能地选择相关的垂直领域。
- 针对性子问题:每个智能体都接收到一个与其领域相关的定制问题,从而提高结果质量。
- 清洁合成:来自多个来源的结果被合并为一个连贯的响应。
3.3.1.定义状态
首先定义状态模式。我们使用三种类型:
AgentInput:传递给每个子智能体的简单状态(只是一个查询)AgentOutput:每个子智能体返回的结果(源名称+结果)RouterState:主要工作流状态,跟踪查询、分类、结果和最终答案
python
from typing import Annotated, Literal, TypedDict
import operator
class AgentInput(TypedDict):
"""每个子智能体的简单输入状态。"""
query: str
class AgentOutput(TypedDict):
"""每个子智能体的输出结果。"""
source: str# 智能体来源
result: str# 智能体输出
class Classification(TypedDict):
"""单个路由决策:指定调用哪个智能体以及对应的查询内容。"""
source: Literal["github", "notion", "slack"]
query: str
class RouterState(TypedDict):
"""路由状态类,用于管理多智能体路由过程中的状态信息"""
# 原始查询字符串
query: str
# 路由决策列表,包含每个智能体的来源和对应的查询内容
classifications: list[Classification]
# 使用 operator.add 作为归约器,用于收集并合并并行执行的结果
results: Annotated[list[AgentOutput], operator.add]
# 最终整合后的答案
final_answer: strresults 字段使用一个 reducer (Python 中的 operator.add,JS 中的 concat 函数)来收集并行智能体执行的结果到一个列表中。
3.3.2.为每个垂直领域定义工具
为每个知识领域创建工具。在一个生产系统中,这些工具会调用实际的 API。在这个教程中,我们使用返回模拟数据的存根实现。我们在 3 个垂直领域中定义了 7 个工具:GitHub(搜索代码、问题、PR)、Notion(搜索文档、获取页面)和 Slack(搜索消息、获取线程)。
python
from langchain.tools import tool
@tool
def search_code(query: str, repo: str = "main") -> str:
"""在 GitHub 仓库中搜索代码。"""
return f"在 {repo} 中找到匹配 '{query}' 的代码:src/auth.py 中的身份验证中间件"
@tool
def search_issues(query: str) -> str:
"""搜索 GitHub 的 issue 和拉取请求(PR)。"""
return f"找到 3 个匹配 '{query}' 的 issue:#142(API 认证文档),#89(OAuth 流程),#203(令牌刷新)"
@tool
def search_prs(query: str) -> str:
"""搜索拉取请求以获取实现细节。"""
return f"PR #156 添加了 JWT 身份验证,PR #178 更新了 OAuth 权限范围"
@tool
def search_notion(query: str) -> str:
"""在 Notion 工作区中搜索文档。"""
return f"找到文档:《API 身份验证指南》------涵盖 OAuth2 流程、API 密钥和 JWT 令牌"
@tool
def get_page(page_id: str) -> str:
"""根据 ID 获取指定的 Notion 页面内容。"""
return f"页面内容:身份验证设置的分步操作说明"
@tool
def search_slack(query: str) -> str:
"""搜索 Slack 消息和讨论线程。"""
return f"在 #engineering 频道发现讨论:'API 认证请使用 Bearer 令牌,刷新流程详见文档'"
@tool
def get_thread(thread_id: str) -> str:
"""获取指定的 Slack 线程内容。"""
return f"该线程讨论了 API 密钥轮换的最佳实践"3.3.3.创建专业智能体
为每个垂直领域创建一个智能体。每个智能体都有特定领域的工具,以及针对其知识源的优化提示。这三个都遵循相同的模式------只有工具和系统提示不同。
python
from langchain.agents import create_agent
from langchain.chat_models import init_chat_model
model = llm
# 创建 GitHub 智能体:用于回答与代码、API 和实现细节相关的问题
github_agent = create_agent(
model,
tools=[search_code, search_issues, search_prs],
system_prompt=(
"你是一位 GitHub 专家。请通过搜索代码仓库、issue 和拉取请求(PR),"
"回答有关代码、API 文档和实现细节的问题。"
),
)
# 创建 Notion 智能体:用于回答与内部流程、政策和团队文档相关的问题
notion_agent = create_agent(
model,
tools=[search_notion, get_page],
system_prompt=(
"你是一位 Notion 专家。请通过搜索组织的 Notion 工作区,"
"回答有关内部流程、政策和团队文档的问题。"
),
)
# 创建 Slack 智能体:用于回答基于团队讨论和知识分享的问题
slack_agent = create_agent(
model,
tools=[search_slack, get_thread],
system_prompt=(
"你是一位 Slack 专家。请通过搜索相关的消息线程和讨论,"
"回答团队成员曾分享过解决方案或经验的问题。"
),
)3.3.4.构建路由器工作流
现在使用 StateGraph 构建路由器工作流。该工作流有四个主要步骤:
- 分类:分析查询并确定调用哪些智能体以及使用什么子问题
- 路由 :使用
发送并行地分发到选定的智能体 - 查询智能体 :每个智能体接收一个简单的
智能体输入并返回一个智能体输出 - 综合:将收集到的结果组合成一个连贯的响应
python
from pydantic import BaseModel, Field
from langgraph.graph import StateGraph, START, END
from langgraph.types import Send
from typing_extensions import TypedDict
router_llm = llm
# 定义分类器的结构化输出格式
class ClassificationResult(BaseModel):
"""将用户查询分类为针对不同智能体的子问题的结果。"""
classifications: list[Classification] = Field(
description="需要调用的智能体列表,每个包含其对应的针对性子问题"
)
def classify_query(state: RouterState) -> dict:
"""对用户查询进行分类,并决定应调用哪些智能体。"""
structured_llm = router_llm.with_structured_output(ClassificationResult)
result = structured_llm.invoke([
{
"role": "system",
"content": """请分析以下查询,并判断需要咨询哪些知识库。
对于每个相关来源,请生成一个针对该来源优化的子问题。
可用来源:
- github:代码、API 文档、实现细节、issue、拉取请求(PR)
- notion:内部文档、流程、政策、团队 Wiki
- slack:团队讨论、非正式知识分享、近期对话
仅返回与查询相关的来源。每个来源都应配有一个针对其知识领域的精准子问题。
示例(查询:"如何对 API 请求进行身份验证?"):
- github:"是否存在身份验证相关代码?搜索 auth 中间件、JWT 处理逻辑"
- notion:"是否有身份验证相关文档?查找 API 身份验证指南"
(未包含 slack,因为该技术问题在 Slack 中不相关)"""
},
{"role": "user", "content": state["query"]}
])
return {"classifications": result.classifications}
def route_to_agents(state: RouterState) -> list[Send]:
"""根据分类结果,将任务分发给对应的智能体(扇出执行)。"""
return [
Send(c["source"], {"query": c["query"]})
for c in state["classifications"]
]
def query_github(state: AgentInput) -> dict:
"""调用 GitHub 智能体进行查询。"""
result = github_agent.invoke({
"messages": [{"role": "user", "content": state["query"]}]
})
return {"results": [{"source": "github", "result": result["messages"][-1].content}]}
def query_notion(state: AgentInput) -> dict:
"""调用 Notion 智能体进行查询。"""
result = notion_agent.invoke({
"messages": [{"role": "user", "content": state["query"]}]
})
return {"results": [{"source": "notion", "result": result["messages"][-1].content}]}
def query_slack(state: AgentInput) -> dict:
"""调用 Slack 智能体进行查询。"""
result = slack_agent.invoke({
"messages": [{"role": "user", "content": state["query"]}]
})
return {"results": [{"source": "slack", "result": result["messages"][-1].content}]}
def synthesize_results(state: RouterState) -> dict:
"""将所有智能体的查询结果整合为一个连贯、简洁的最终回答。"""
if not state["results"]:
return {"final_answer": "未从任何知识源中找到相关信息。"}
# 格式化各来源的结果,便于整合
formatted = [
f"**来自 {r['source'].title()}:**\n{r['result']}"
for r in state["results"]
]
synthesis_response = router_llm.invoke([
{
"role": "system",
"content": f"""请综合以下搜索结果,回答原始问题:"{state['query']}"
- 融合多个来源的信息,避免重复
- 突出最相关且可操作的内容
- 如有信息冲突,请指出差异
- 保持回答简洁、条理清晰"""
},
{"role": "user", "content": "\n\n".join(formatted)}
])
return {"final_answer": synthesis_response.content}3.3.5. 编译工作流
现在通过连接节点与边来组装工作流。关键是使用 add_conditional_edges 与路由函数来启用并行执行:
python
workflow = (
StateGraph(RouterState)
.add_node("classify", classify_query)
.add_node("github", query_github)
.add_node("notion", query_notion)
.add_node("slack", query_slack)
.add_node("synthesize", synthesize_results)
.add_edge(START, "classify")
.add_conditional_edges("classify", route_to_agents, ["github", "notion", "slack"])
.add_edge("github", "synthesize")
.add_edge("notion", "synthesize")
.add_edge("slack", "synthesize")
.add_edge("synthesize", END)
.compile()
)add_conditional_edges 调用通过 route_to_agents 函数将分类节点连接到智能体节点。当 route_to_agents 返回多个 Send 对象时,这些节点并行执行。
3.3.6. 使用路由器
用跨越多个知识领域的查询测试你的路由器:
python
result = workflow.invoke({
"query": "如何验证API请求?"
})
# 打印原始查询
print("原始查询:", result["query"])
print("\n分类结果:")
for c in result["classifications"]:
print(f" {c['source']}: {c['query']}")
print("\n" + "=" * 60 + "\n")
# 打印最终整合后的答案
print("最终回答:")
print(result["final_answer"])路由器分析了查询,将其分类以确定要调用的智能体(对于这个技术问题,是 GitHub 和 Notion,而不是 Slack),并行查询了这两个智能体,并将结果综合成一个连贯的答案。
原始查询: 如何验证API请求?
分类结果:
github: 是否存在身份验证相关代码?搜索 auth 中间件、JWT 处理逻辑
notion: 是否有身份验证相关文档?查找 API 身份验证指南
============================================================
最终回答:
要验证 API 请求,您可以结合代码实现与组织文档两方面的信息进行操作。以下是综合 Github 代码仓库和 Notion 文档的关键要点:
✅ 验证 API 请求的核心方法
1. **使用 JWT(JSON Web Token)**
**实现位置**:`src/auth.py` 中包含完整的 JWT 生成、解析和验证逻辑。
**典型流程**:
客户端在登录后获取 JWT(通常通过 `/token` 端点)。
后续请求在 `Authorization` 头中携带该令牌,格式为:
```http
Authorization: Bearer <your-jwt-token>
```
- 服务端通过 `Auth 中间件` 自动验证令牌有效性(签名、过期时间等)。
2. **OAuth2 流程支持**
根据 Notion 的《API 身份验证指南》,系统支持标准 OAuth2 授权流程(如授权码模式或客户端凭证模式)。
适用于第三方应用集成场景,需配置客户端 ID 和密钥。
3. **API 密钥(备用方案)**
某些内部或低敏感度接口可能接受 API 密钥作为身份凭证。
通常通过请求头(如 `X-API-Key`)传递。
具体是否启用及密钥管理方式,请参考 Notion 文档中的"API 密钥管理"章节。
🔍 建议操作步骤
- **查阅 `src/auth.py`**
确认中间件如何拦截请求、验证 JWT 结构及处理异常(如过期或无效令牌)。
- **阅读 Notion《API 身份验证指南》**
获取:
开发者如何注册应用并获取凭证
不同认证方式的适用场景
错误码说明(如 `401 Unauthorized`、`403 Forbidden`)
- **测试验证逻辑**
使用工具(如 Postman 或 curl)发送带/不带令牌的请求,观察响应行为。
如需我进一步分析 `src/auth.py` 的具体代码逻辑(例如如何解析 token、依赖哪些库、是否集成用户数据库等),请提供该文件内容或关键片段。
3.3.7. 理解架构
路由工作流遵循一个清晰的模式:
分类阶段
classify_query 函数使用 结构化输出来分析用户的查询并确定要调用的智能体。这就是路由智能所在的地方:

- 使用 Pydantic 模型(Python)或 Zod 模式(JS)来确保有效输出
- 返回一个
Classification对象列表,每个对象都有一个source和目标query - 仅包含相关源------不相关的源会被简单地省略
这种结构化方法比自由形式的 JSON 解析更可靠,并使路由逻辑显式化。
并行执行与发送
route_to_agents 函数将分类映射到 Send 对象。每个 Send 指定了目标节点和要传递的状态:
python
# 分类结果示例:[{"source": "github", "query": "..."}, {"source": "notion", "query": "..."}]
# 被转换为以下形式:
[Send("github", {"query": "..."}), Send("notion", {"query": "..."})]
# 上述 Send 指令将使两个智能体同时执行,每个智能体仅接收到其对应的子查询每个智能体节点只接收一个简单的 AgentInput,其中只包含一个 query 字段------而不是完整的路由器状态。这使接口保持简洁和明确。
使用 reducer 收集结果
智能体结果通过一个 reducer 流回主状态。每个智能体返回:
python
{"results": [{"source": "github", "result": "..."}]}
# 上述结构表示一个或多个智能体返回的查询结果:
# - "source" 指明结果来源(如 github、notion 或 slack)
# - "result" 包含该来源返回的具体回答内容
# 整个列表通过 Annotated[list[AgentOutput], operator.add] 在 RouterState 中自动聚合智能体(Python 中的 operator.add)将这些列表连接起来,将所有并行结果收集到 state["results"] 中。
合成阶段
所有智能体完成后,synthesize_results 函数会遍历收集到的结果:
- 等待所有并行分支完成(LangGraph 自动处理此操作)
- 引用原始查询以确保答案回答了用户的问题
- 整合所有来源的信息,无冗余
3.4.总结
路由模式在以下情况下表现优异:
- 明确的垂直领域:需要专门工具和提示的独立知识领域
- 并行查询需求:那些从同时查询多个来源中获益的问题
- 合成需求:来自多个来源的结果需要被整合为一个连贯的响应
该模式包含三个阶段:分解 (分析查询并生成目标子问题)、路由 (并行执行查询)和合成(组合结果)。
何时使用路由模式 使用路由模式,当你有多个独立的知识源、需要低延迟并行查询,并希望对路由逻辑进行显式控制时。对于具有动态工具选择的简单情况,可以考虑子智能体模式。对于智能体需要按顺序与用户对话的工作流程,可以考虑交接。