作者:来自 Elastic Iraklis Psaroudakis
探索 Elasticsearch Serverless 的无状态架构。了解如何将有状态架构转换为用于 Serverless 的无状态架构。
通过 Elastic Cloud Serverless 摆脱运维负担。自动扩展、处理负载峰值,并专注于构建------开始 14 天免费试用亲自体验!
你可以按照这些指南构建 AI-Powered 搜索体验,或在业务系统和软件之间进行搜索。
我们非常高兴地宣布 ,我们新的同行评审论文《Serverless Elasticsearch:从有状态到无状态的架构转变》已经发表,并被接收并在 2025 年 Association for Computing Machinery (ACM) Symposium on Cloud Computing (SoCC) 的工业论文轨道上进行了展示。该论文简要介绍了我们在 Elasticsearch 方面的最新创新。在 Elastic,我们始终专注于搜索的未来。从优化性能到简化运维,我们的团队始终在探索下一步的发展方向。
这篇论文不仅仅是一项学术研究。它从基础层面探索了如何为完全 serverless 的世界重新构想搜索引擎的核心。我们将 storage 与 compute 解耦:数据存储在具有几乎无限存储容量和可扩展性的云 blob store 中。这一愿景正是 Elastic Cloud Serverless 产品背后的主要驱动力:在海量数据集上实现无缝搜索,同时具备 serverless 的经济性和运维简洁性。
挑战:为云重新思考有状态搜索
几十年来,搜索引擎一直是强大的有状态系统。部署一个生产级集群(如 Elasticsearch)通常意味着:
- 配置服务器并管理存储。
- 为成本、性能和可靠性仔细调优配置。
- 当工作负载出现峰值或不可预测时,为闲置容量付费。
- 为扩展和缩减集群付出大量运维工作。
现代云平台已经让其中一些事情变得更容易,但一个根本性的矛盾仍然存在:
我们能否构建一个搜索引擎,在保持 Elasticsearch 强大能力和丰富查询功能的同时,也具备 serverless 架构的经济性和运维简洁性?
这个问题推动了我们的研究。
我们的关键贡献
论文提出了使 Elasticsearch Serverless 成为可能的具体创新:
- Object store 作为单一事实来源
- 我们将索引数据、transaction log(translog)和 cluster state 转移到云 object store。这消除了为持久性而存在的 replica shards,并使 object store 成为 indexing 与 search 之间的同步点。
- "Thin"(无状态)shards
- shards 可以在节点之间快速恢复和迁移,而无需复制大量数据。磁盘只用于缓存,而不是持久存储。
- Batched compound commits (BCC)
- 我们将 index commits 包装在自定义格式中,以降低上传成本,同时保持与 Elasticsearch 相同的 read-after-write 语义。
- Batched translog uploads
- translog 上传在节点级别进行批处理,从而降低上传成本。
- 智能垃圾回收
- 我们跟踪已上传的 BCC 和 translogs 的使用情况,并在不再使用时删除它们,以减少存储占用和保留成本。
- Autoscaling
- 系统会根据 ingestion 和 search 负载自动扩展,使客户端可以直接调用 API,而无需管理集群规模。
总结 :在我们的实验中,在相似硬件条件下,Elasticsearch Serverless 的 indexing 吞吐量最高可达到有状态 Elasticsearch 的两倍,并且通过 autoscaling 可以线性扩展以匹配 ingestion 负载。
架构可视化
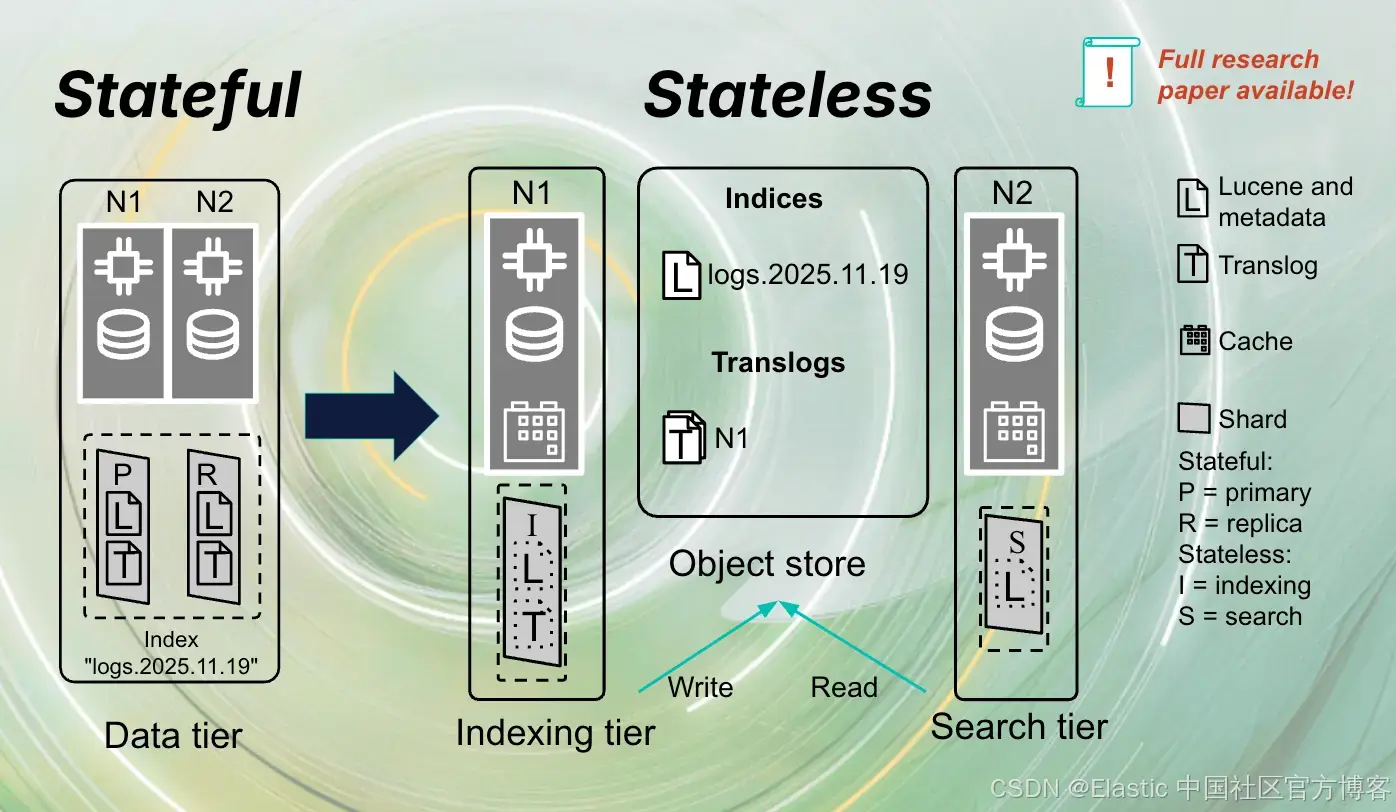
论文中的 Figure 1 清晰地并排展示了两种架构:有状态 Elasticsearch 与新的无状态架构 Elasticsearch Serverless。
有状态 Elasticsearch(上图):熟悉的数据层级:hot、warm、cold、frozen。数据存储在本地磁盘上;primary 和 replica 分布在各个节点之间;较冷的数据层可能使用 object store 上的 searchable snapshots。
Elasticsearch Serverless(下图):只有两个层级:indexing 和 search。所有持久数据(Lucene commits、translogs、cluster state)都存储在 object store 中。indexing 节点负责写入并上传数据;search 节点从 object store 和共享缓存中读取数据,而不会在本地持久化索引数据。
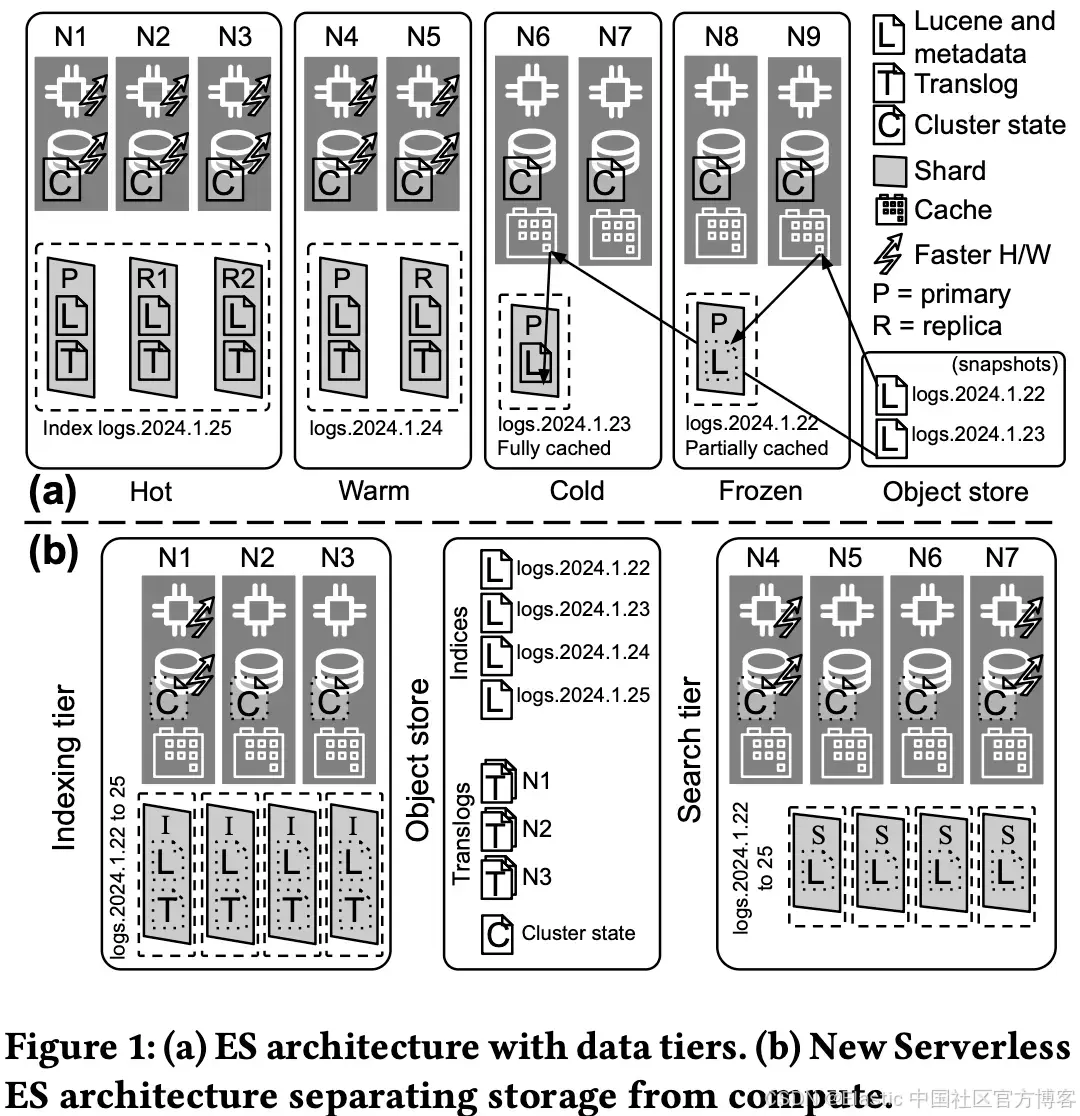 要点:用于 indexing 的资源与用于 querying 的资源完全分离。
要点:用于 indexing 的资源与用于 querying 的资源完全分离。
两种数据流路径的对比
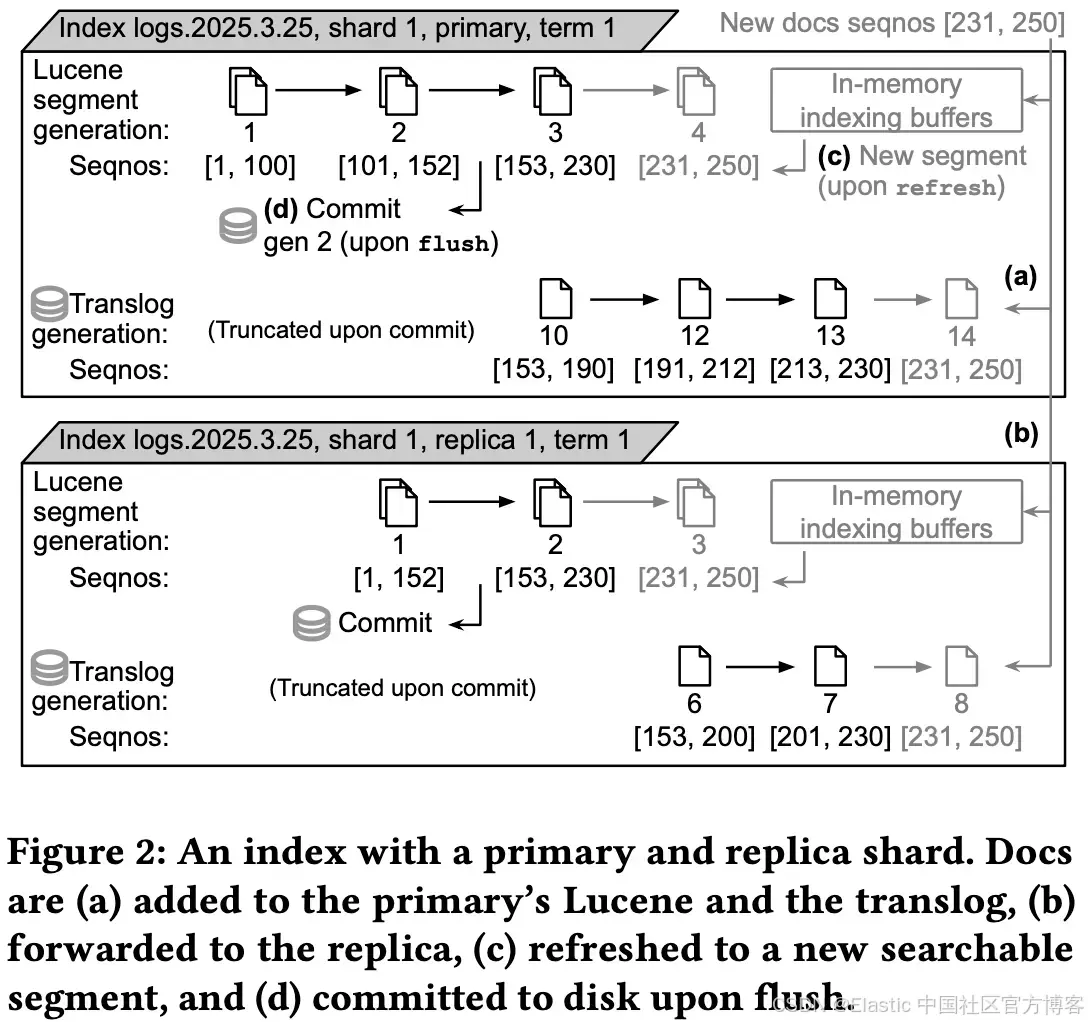
论文中的 Figure 2 和 Figure 3 对比了有状态 Elasticsearch 与 Elasticsearch Serverless 中的数据流方式。
有状态 Elasticsearch(Figure 2):
- 文档首先进入 primary shard 的 Lucene buffers 和 translog,然后复制到 replica shards。
- 在 refresh 之后,文档进入新的可搜索 segments。
- 在 flush 之后,它们被提交到磁盘。
- 因此,数据的持久性由磁盘和 replicas 提供。
Elasticsearch Serverless(Figure 3):
- 文档首先进入 indexing node 上的 Lucene 和 translog。
- 在向客户端返回确认之前,translog 会被上传到 object store。
- 在 refresh 之后,文档进入新的可搜索 segments,并在 indexing nodes 上提交到磁盘。
- 在 flush 之后,它们会被打包为 BCC 并上传到 blob object store。
- search nodes 从 object store 提供查询服务(对于尚未上传的最新数据,则直接从 indexing node 读取)。
- 因此,数据持久性来自 object store,而不是磁盘或 replicas。
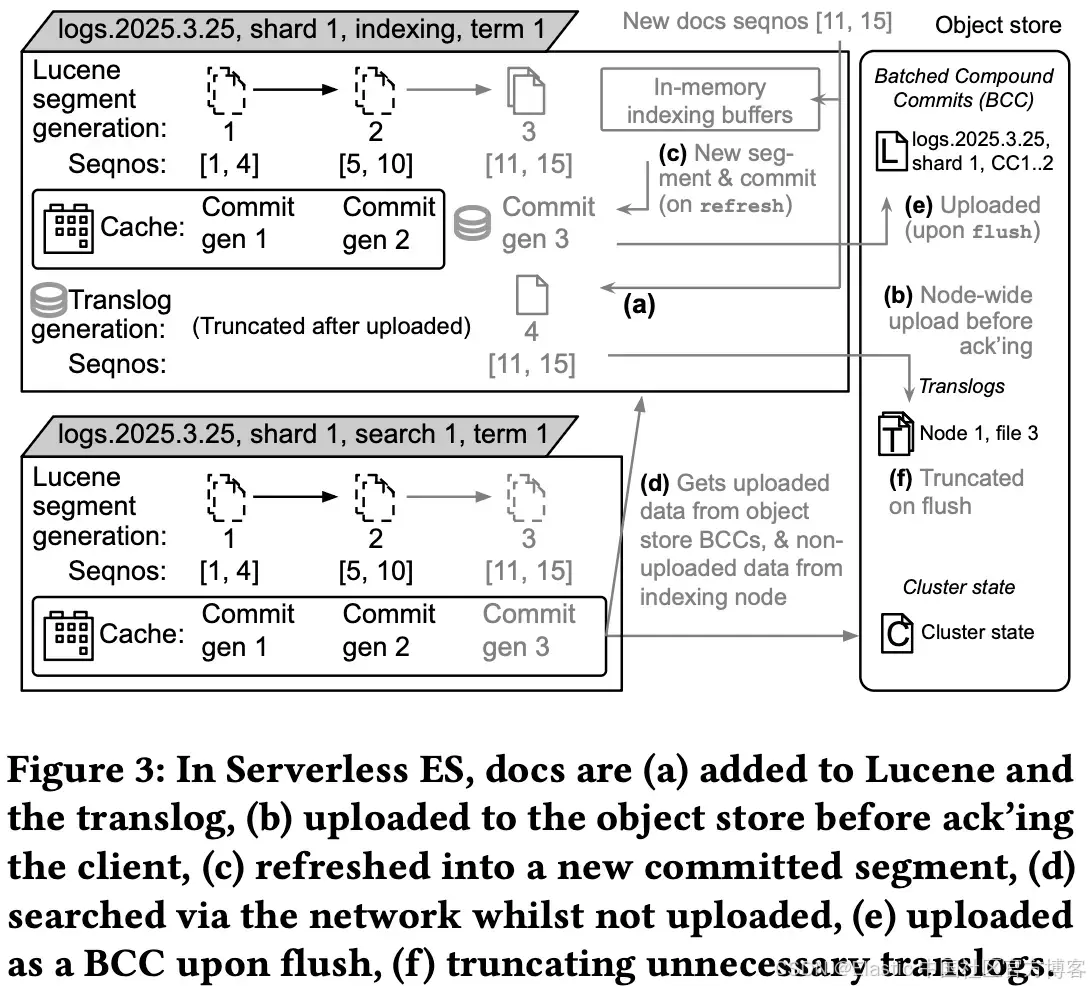
结果:indexing 路径 与 search 路径 完全解耦。
自动伸缩
论文第7节描述了 autoscaler。由于数据存储在 object store 中,重定位 shard 不需要复制完整 segment 数据;只需处理元数据,并在需要时进行缓存预热。因此,cluster 可以比 stateful Elasticsearch 更快地扩展和收缩。
工作原理:
- autoscaler 是一个外部组件,监控 Elasticsearch Serverless 的指标。
- Indexing tier:Scale-up 由内存使用量和 ingest 负载驱动(包括排队工作)。
- Search tier:Scale-up 由内存、search 负载以及用户可配置的 "search power" 驱动(决定本地缓存多少数据集)。
- 它每隔几秒轮询一次,并独立调整每个 tier。
结果:自动、基于工作负载的伸缩,让客户端可以专注于应用,而不必关注容量规划。
实验结果
论文第8节展示了实验评估。
-
微基准测试显示批处理的影响:commit 和 translog 的 object store 操作减少,但存在一定权衡。
-
自动伸缩实验:随着 indexing client 数量增加,吞吐量线性增长,而 P50 和 P99 延迟保持稳定。真实场景示例显示,bulk 响应时间随着 indexing tier 根据需求扩展而改善并稳定。
Stateful Elasticsearch 与 Elasticsearch Serverless 的对比:
-
Elasticsearch Serverless 在第50百分位索引吞吐量大约是 stateful Elasticsearch 的两倍。
-
提升主要来自使用 object store 作为持久化存储,而不是将每个操作复制到 replica shard。
-
延迟仍具有竞争力。
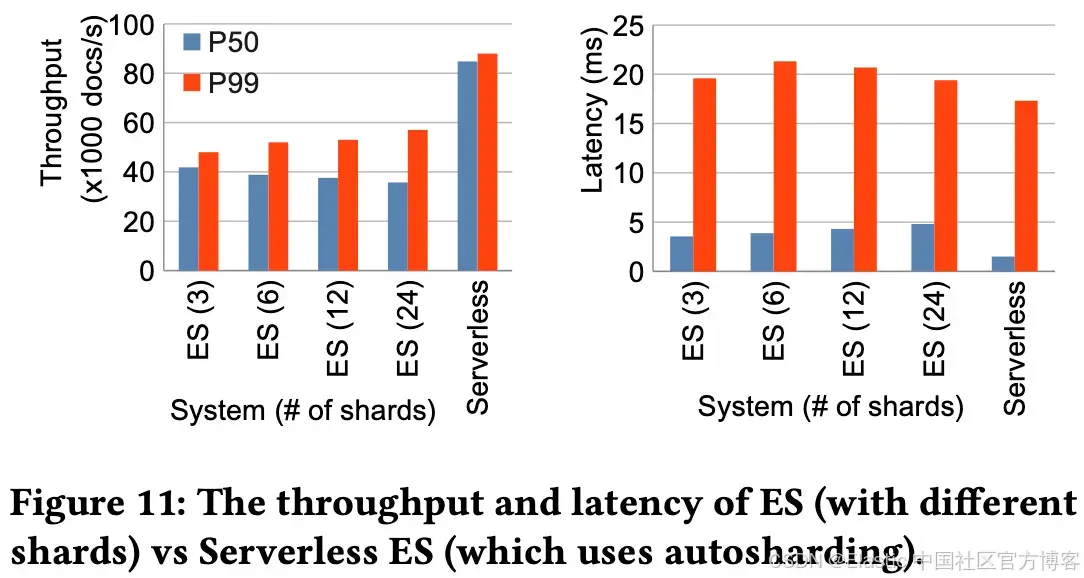
关键结论:无状态设计不仅提供了更高的峰值性能,还实现了更高效的自动伸缩。
为什么这对 Elastic 的未来很重要
无状态架构不仅是技术成就;它还是我们希望搜索在云端工作的基础。
- 按需付费:客户可以在几乎无限的数据上进行索引和搜索,无需预置 cluster、调优 tier 或管理 replica 和 snapshot。
- 自动伸缩:每个 tier 独立自动伸缩,无需容量规划。
- 频繁自动升级:更好的安全性和价值实现时间,无需对 stateful 数据进行滚动升级的运营成本。
这项工作是让强大搜索更易访问、更具成本效益和可扩展性的一个步骤。
阅读全文并参与讨论
我们相信开放研究和协作的力量能够推动技术发展。鼓励你深入了解细节。我们提供了本文的预印本,深入介绍了架构转型。
深入探索:相关博客文章
虽然论文概述了 Elasticsearch Serverless 架构,工程团队的系列深入博客文章更完整地探讨了细节和创新。这些文章提供了背景、细微差别以及具体技术深度,说明了无状态转型如何成为可能。
建议阅读以下资源,以更全面理解论文中介绍的组件和概念:
-
Stateless --- 你在 Elasticsearch 的新搜索状态 (2022) 和 通过 Serverless 提供更多服务 (2023)。介绍存储与计算解耦概念的基础文章。
-
Stateless: 无状态世界中的数据安全 (2024)。了解在无本地 replica 的情况下如何实现数据持久性。
-
Elasticsearch Serverless中的数据流自动分片 (2024)。探索自动和动态数据流分片的逻辑。
-
我们如何优化 Elasticsearch Serverless 中的刷新成本 (2024)。理解降低数据可搜索成本的具体优化。
-
引入 Serverless 精简索引分片 (2024)。探索使快速迁移和恢复成为可能的 "thin" shard 创新。
-
Search tier autoscaling in Elasticsearch Serverless(2024)。深入了解驱动 search 资源自动伸缩的机制。
-
在 Elasticsearch 中实现摄取自动扩展 (2024)。了解 ingestion tier 如何自动扩展以应对波动的索引负载。
-
Elastic Cloud Serverless pricing and packaging (2025)。了解 Elastic Cloud Serverless 最初的定价和打包结构。
-
Elasticsearch 与 OpenSearch:揭开性能差距 (2023)。了解 Elasticsearch 与 OpenSearch 的性能差异和关键优化。
致谢
感谢本文所有合著者:Iraklis Psaroudakis、Pooya Salehi、Jason Bryan、Francisco Fernández Castaño、Brendan Cully、Ankita Kumar、Henning Andersen 和 Thomas Repantis。同时感谢 Elasticsearch Distributed Systems 团队的贡献,以及整个 Elasticsearch 工程团队。
原文:https://www.elastic.co/search-labs/blog/elasticsearch-serverless-stateless-architecture