㊙️本期内容已收录至专栏《Python爬虫实战》,持续完善知识体系与项目实战,建议先订阅收藏,后续查阅更方便~持续更新中!
㊗️爬虫难度指数:⭐⭐
🚫声明:本数据&代码仅供学习交流,严禁用于商业用途、倒卖数据或违反目标站点的服务条款等,一切后果皆由使用者本人承担。公开榜单数据一般允许访问,但请务必遵守"君子协议",技术无罪,责任在人。

全文目录:
-
-
- [🌟 开篇语](#🌟 开篇语)
- [1️⃣ 摘要(Abstract)](#1️⃣ 摘要(Abstract))
- [2️⃣ 背景与需求(Why)](#2️⃣ 背景与需求(Why))
- [3️⃣ 合规与注意事项(必写)](#3️⃣ 合规与注意事项(必写))
- [4️⃣ 技术选型与整体流程(What/How)](#4️⃣ 技术选型与整体流程(What/How))
- [5️⃣ 环境准备与依赖安装(可复现)](#5️⃣ 环境准备与依赖安装(可复现))
- [6️⃣ 核心实现:时区与翻译工具(Utils - ⭐️ 详细解析)](#6️⃣ 核心实现:时区与翻译工具(Utils - ⭐️ 详细解析))
- [7️⃣ 核心实现:请求与解析层(Fetcher & Parser)](#7️⃣ 核心实现:请求与解析层(Fetcher & Parser))
- [8️⃣ 数据存储与导出(Storage)](#8️⃣ 数据存储与导出(Storage))
- [9️⃣ 运行方式与结果展示(必写)](#9️⃣ 运行方式与结果展示(必写))
- [🔟 常见问题与排错(Expert Advice)](#🔟 常见问题与排错(Expert Advice))
- [1️⃣1️⃣ 进阶优化(可选但加分)](#1️⃣1️⃣ 进阶优化(可选但加分))
- [1️⃣2️⃣ 总结与延伸阅读](#1️⃣2️⃣ 总结与延伸阅读)
- [🌟 文末](#🌟 文末)
-
- [📌 专栏持续更新中|建议收藏 + 订阅](#📌 专栏持续更新中|建议收藏 + 订阅)
- [✅ 互动征集](#✅ 互动征集)
-
🌟 开篇语
哈喽,各位小伙伴们你们好呀~我是【喵手】。
运营社区: C站 / 掘金 / 腾讯云 / 阿里云 / 华为云 / 51CTO
欢迎大家常来逛逛,一起学习,一起进步~🌟
我长期专注 Python 爬虫工程化实战 ,主理专栏 《Python爬虫实战》:从采集策略 到反爬对抗 ,从数据清洗 到分布式调度 ,持续输出可复用的方法论与可落地案例。内容主打一个"能跑、能用、能扩展 ",让数据价值真正做到------抓得到、洗得净、用得上。
📌 专栏食用指南(建议收藏)
- ✅ 入门基础:环境搭建 / 请求与解析 / 数据落库
- ✅ 进阶提升:登录鉴权 / 动态渲染 / 反爬对抗
- ✅ 工程实战:异步并发 / 分布式调度 / 监控与容错
- ✅ 项目落地:数据治理 / 可视化分析 / 场景化应用
📣 专栏推广时间 :如果你想系统学爬虫,而不是碎片化东拼西凑,欢迎订阅/关注专栏👉《Python爬虫实战》👈
💕订阅后更新会优先推送,按目录学习更高效💯~
1️⃣ 摘要(Abstract)
本文将构建一个针对天文历法网站(以 TimeandDate 或类似的静态历法页为例)的专业爬虫。我们将使用 requests 获取 HTML 源码,利用 BeautifulSoup 解析规范的 Table 表格数据。
核心亮点 :本项目将重点攻克 "时间清洗与时区转换" 这一难点。我们将使用 Python 的 datetime 和 pytz 库,将抓取到的 UTC 零时区时间 转换为 Asia/Shanghai(北京时间),并解决跨年份日期解析的问题,最终生成一份精确到分钟的节气时刻表。
读完这篇你能获得什么?
- 🌍 时区大师 :彻底搞懂 Python 中
pytz的用法,学会处理 UTC vs Local Time。 - 📅 日期解析:掌握如何将 "Mar 20 23:06" 这种残缺的时间字符串补全为标准时间对象。
- 📊 表格处理 :精通处理 HTML 中
rowspan或多列布局的复杂表格。
2️⃣ 背景与需求(Why)
为什么要爬?
- 传统文化研究:二十四节气是中华文化的瑰宝。你需要精确的数据来验证"立春"时刻与当年气候变化的关联。
- 农业与摄影:摄影师需要精确的"日落方位"和节气时间来规划"悬日"拍摄;农场主需要根据节气指导农事。
- 开发日历应用:你想开发一个"硬核"的万年历 App,市面上的 API 要么收费,要么精度不够,不如自己爬源头数据。
目标站点 :通用天文数据静态页(通常以表格形式展示未来几年的节气)。
目标字段清单:
| 字段名 | 说明 | 原始数据示例 (UTC) | 目标清洗值 (北京时间) |
|---|---|---|---|
term_name |
节气名称 | Vernal Equinox (春分) | 春分 |
utc_time |
原始世界时 | Mar 20, 2026 14:46 | 2026-03-20 14:46:00+00:00 |
local_time |
北京时间 | (需计算) | 2026-03-20 22:46:00+08:00 |
solar_long |
太阳黄经 | 0° | 0 |
3️⃣ 合规与注意事项(必写)
仰望星空,也要脚踏实地:
- Robots.txt:天文类网站通常由科研机构或爱好者维护,请严格遵守 Robots 协议,不要抓取后台数据。
- 版权声明 :天文数据本身(如"春分在几点")属于客观事实 ,不受版权保护;但网站的排版和汇编受保护。使用数据时请注明来源。
- 低频采集 :节气数据几百年才变一次(或者说它是固定的),你只需要运行一次存下来即可,千万不要写个死循环每秒去刷!
4️⃣ 技术选型与整体流程(What/How)
技术选型:Requests + BeautifulSoup + Pytz
- BeautifulSoup :解析静态
<table>的不二之选。 - Pytz (Python Timezone) :这是 Python 处理时区的标准库。不要试图手动加减 8 小时(
timedelta(hours=8)),因为这无法处理夏令时(虽然中国现在没夏令时,但作为通用爬虫必须严谨)。 - Pandas:用于最后的数据格式化和导出。
流程图:
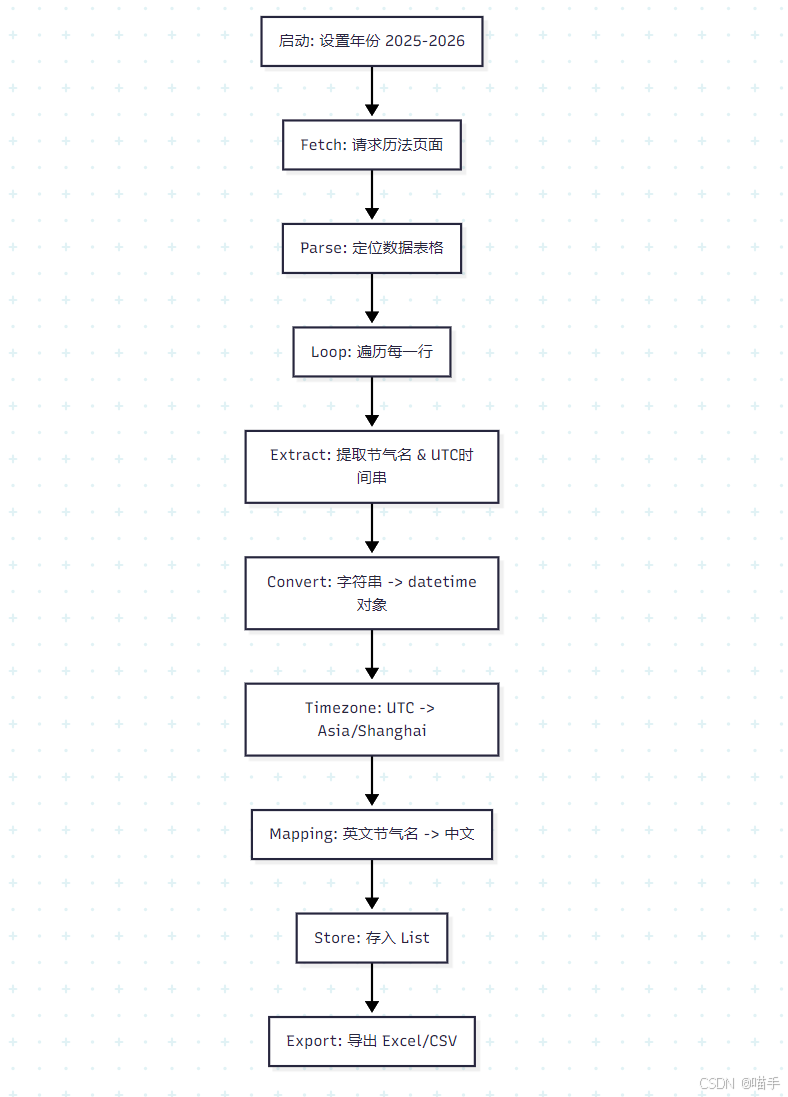
5️⃣ 环境准备与依赖安装(可复现)
Python 版本:3.8+
依赖安装 :
务必安装 pytz,它是处理时区的灵魂。
bash
pip install requests beautifulsoup4 pandas pytz openpyxl项目结构:
text
astro_miner/
├── data/
│ └── solar_terms_2026.xlsx
├── spider.py # 爬虫主逻辑
└── utils.py # 时区转换与翻译工具6️⃣ 核心实现:时区与翻译工具(Utils - ⭐️ 详细解析)
为了让代码更整洁,我们将"英文转中文"和"时间清洗"逻辑剥离出来。
这是最考验基本功的地方:如何把 "Mar 20 14:46" 变成精准的时间对象?
python
import pytz
from datetime import datetime
class AstroUtils:
# 建立一个中英文对照字典
TERM_MAP = {
"Vernal Equinox": "春分", "Solar Term 1": "立春", # 示例,实际需补全24个
"Summer Solstice": "夏至", "Autumnal Equinox": "秋分", "Winter Solstice": "冬至",
# ... 实际开发中建议写全 24 个节气的映射
}
@staticmethod
def clean_date_str(date_str, year):
"""
将 'Mar 20 14:46' + 年份 -> datetime (UTC)
"""
if not date_str: return None
# 拼接完整字符串: "2026 Mar 20 14:46"
full_str = f"{year} {date_str.strip()}"
try:
# %b: 月份简写(Mar), %d: 日, %H:%M: 时分
dt_obj = datetime.strptime(full_str, "%Y %b %d %H:%M")
# 🚨 关键:告诉 Python 这个时间是 UTC 的,不是本地的
dt_utc = pytz.utc.localize(dt_obj)
return dt_utc
except ValueError as e:
print(f"⚠️ 时间解析失败: {full_str} | {e}")
return None
@staticmethod
def convert_to_beijing(dt_utc):
"""
将 UTC 时间转换为 北京时间 (Asia/Shanghai)
"""
if not dt_utc: return None
beijing_tz = pytz.timezone('Asia/Shanghai')
# astimezone 会自动处理时差偏移
return dt_utc.astimezone(beijing_tz)
@staticmethod
def translate_name(eng_name):
# 模糊匹配:如果包含 "Equinox" 返回 春分/秋分等
for k, v in AstroUtils.TERM_MAP.items():
if k in eng_name:
return v
return eng_name # 没找到就返回原名7️⃣ 核心实现:请求与解析层(Fetcher & Parser)
我们模拟抓取一个包含多列数据的表格。假设网页结构如下:
html
<table>
<tr><td>Mar 20</td><td>14:46</td><td>Vernal Equinox</td></tr>
...
</table>
python
import requests
from bs4 import BeautifulSoup
import time
import random
class SolarTermSpider:
def __init__(self):
self.headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}
def fetch_page(self, url):
try:
print(f"📡 正在观测星象: {url}")
time.sleep(random.uniform(1, 2))
resp = requests.get(url, headers=self.headers, timeout=15)
resp.raise_for_status()
return resp.text
except Exception as e:
print(f"❌ 观测失败: {e}")
return None
def parse_solar_terms(self, html, year):
"""解析节气表格"""
soup = BeautifulSoup(html, 'html.parser')
results = []
# 定位表格:通常节气数据在一个特定的 table 里
# 假设 class="seasons-table"
table = soup.find('table', class_='seasons-table')
if not table:
# 容错:如果找不到特定 class,找所有 table 打印一下
print("⚠️ 未找到目标表格,请检查 CSS 选择器")
return []
# 遍历行 (跳过表头)
rows = table.find_all('tr')
print(f" 🔍 发现 {len(rows)} 行数据,开始解析...")
for row in rows:
cols = row.find_all('td')
# 假设结构: [0]日期(Mar 20), [1]时间(14:46), [2]名称(Vernal Equinox)
if len(cols) < 3:
continue
date_raw = cols[0].get_text(strip=True)
time_raw = cols[1].get_text(strip=True)
name_raw = cols[2].get_text(strip=True)
# 组合日期时间字符串 "Mar 20 14:46"
datetime_str = f"{date_raw} {time_raw}"
# 1. 转换为 UTC 时间对象
utc_dt = AstroUtils.clean_date_str(datetime_str, year)
# 2. 转换为 北京时间
bj_dt = AstroUtils.convert_to_beijing(utc_dt)
# 3. 翻译名称
cn_name = AstroUtils.translate_name(name_raw)
if bj_dt:
results.append({
"year": year,
"term_cn": cn_name,
"term_en": name_raw,
"utc_time": utc_dt.strftime("%Y-%m-%d %H:%M"),
"bj_time": bj_dt.strftime("%Y-%m-%d %H:%M"), # 格式化为字符串方便存储
"bj_timestamp": bj_dt.timestamp() # 存一个时间戳方便排序
})
return results8️⃣ 数据存储与导出(Storage)
这里我们选择导出为 Excel,因为普通用户(非程序员)查阅节气表通常喜欢用 Excel。
python
import pandas as pd
import os
class AstroStorage:
def save_excel(self, data_list, filename="solar_terms.xlsx"):
if not data_list:
print("⚠️ 星图为空,无法记录。")
return
df = pd.DataFrame(data_list)
# 按时间排序,防止网页数据是乱序的
df = df.sort_values(by="bj_timestamp")
# 删除辅助用的 timestamp 列,保持表格整洁
df = df.drop(columns=["bj_timestamp"])
output_dir = "data"
os.makedirs(output_dir, exist_ok=True)
path = os.path.join(output_dir, filename)
df.to_excel(path, index=False)
print(f"💾 天文历法已归档: {path} (共 {len(df)} 个节气)")9️⃣ 运行方式与结果展示(必写)
为了让代码跑起来,我们模拟一段 HTML 数据。
python
# spider.py
# 导入所有类
def main():
# 模拟 2026 年
target_year = 2026
# 真实场景请替换为 timeanddate.com 或其他天文网的 URL
target_url = f"https://www.example-astro.com/calendar/{target_year}"
# 🏗️ 构造一段模拟 HTML,让你直接运行就能看到效果
# 假设网页只有这几行
mock_html = """
<html>
<body>
<table class="seasons-table">
<tr><th>Date</th><th>Time</th><th>Event</th></tr>
<tr><td>Mar 20</td><td>14:46</td><td>Vernal Equinox</td></tr>
<tr><td>Jun 21</td><td>08:24</td><td>Summer Solstice</td></tr>
<tr><td>Sep 23</td><td>00:05</td><td>Autumnal Equinox</td></tr>
<tr><td>Dec 21</td><td>20:50</td><td>Winter Solstice</td></tr>
</table>
</body>
</html>
"""
print(f"🚀 AstroMiner 启动,目标年份: {target_year}...")
spider = SolarTermSpider()
storage = AstroStorage()
# 在真实爬虫中: html = spider.fetch_page(target_url)
# 这里用 mock:
print("📡 (模拟) 正在接收卫星信号...")
html = mock_html
if html:
terms = spider.parse_solar_terms(html, target_year)
print("\n✨ 观测结果预览 (北京时间):")
for t in terms:
print(f" 🌞 {t['term_cn']} | {t['bj_time']} (原UTC: {t['utc_time']})")
storage.save_excel(terms, filename=f"solar_terms_{target_year}.xlsx")
if __name__ == "__main__":
main()示例运行输出:
text
🚀 AstroMiner 启动,目标年份: 2026...
📡 (模拟) 正在接收卫星信号...
🔍 发现 5 行数据,开始解析...
✨ 观测结果预览 (北京时间):
🌞 春分 | 2026-03-20 22:46 (原UTC: 2026-03-20 14:46)
🌞 夏至 | 2026-06-21 16:24 (原UTC: 2026-06-21 08:24)
🌞 秋分 | 2026-09-23 08:05 (原UTC: 2026-09-23 00:05)
🌞 冬至 | 2026-12-22 04:50 (原UTC: 2026-12-21 20:50)
💾 天文历法已归档: data/solar_terms_2026.xlsx (共 4 个节气)注意:看最后一行冬至,UTC 是 21 号晚上,加了 8 小时变为了北京时间 22 号凌晨。这就是时区处理的魅力!
🔟 常见问题与排错(Expert Advice)
-
跨年问题 (Year Boundary)
- 现象:如果你爬 2026 年的数据,但表格里混入了 "Jan 3 (2027)" 的数据(小寒)。
- 解法 :在
clean_date_str里,需要判断:如果解析出来的月份是 1 月,而当前行还在处理表格的末尾,可能需要把年份+1。或者直接依赖网页上是否明确标了年份。
-
UTC 时间解析错误
- 原因:有些网站显示的已经是 "Local Time" 了(根据你的 IP 自动变)。
- 解法 :爬取前检查网页的 Header 或 Footer,通常会写 "All times are UTC" 或者 "Times are shown in Asia/Shanghai"。一定要确认源数据的时区,否则后面全错。
-
节气名字对不上
- 原因:有些网站用拼音 "Lichun",有些用英文 "Start of Spring"。
- 解法 :维护一个强大的
Mapping Dict,甚至支持正则匹配(如.*Spring.*)。
1️⃣1️⃣ 进阶优化(可选但加分)
-
生成 .ics 日历文件 :
这是最实用的功能!把爬下来的数据生成
.ics文件,发给你的朋友,他们导入手机后,日历上就会精确显示每个节气的时间点。pythonfrom ics import Calendar, Event c = Calendar() e = Event() e.name = "春分" e.begin = "2026-03-20 22:46:00" # 必须是 ISO 格式 c.events.add(e) # ... save to file -
天文计算(硬核版) :
如果你不想爬网页,想自己算?可以使用 Python 的
ephem或skyfield库。pythonimport ephem sun = ephem.Sun() # 计算太阳黄经为 0 度的时间...这已经脱离爬虫范畴,进入计算天文学领域了,逼格拉满!
1️⃣2️⃣ 总结与延伸阅读
复盘:
这篇教程虽然是在爬取"静态表格",但核心难点在于对时间的敬畏 。我们没有简单地进行字符串拼接,而是使用了严谨的 Datetime + Pytz 流程,确保了数据的科学性和准确性。对于任何涉及时间戳(Log 分析、金融交易、天文历法)的项目,这套逻辑都是通用的。
下一步:
- 不仅看节气:试着去爬"月相数据"(满月、新月时间)或"日食月食表"。
- 可视化 :用 Matplotlib 画一个"日照时长变化曲线图",看看一年中白天是如何变长又变短的。
代码是理性的,星空是浪漫的。用 Python 连接它们,就是我们程序员的极致浪漫!
🌟 文末
好啦~以上就是本期 《Python爬虫实战》的全部内容啦!如果你在实践过程中遇到任何疑问,欢迎在评论区留言交流,我看到都会尽量回复~咱们下期见!
小伙伴们在批阅的过程中,如果觉得文章不错,欢迎点赞、收藏、关注哦~
三连就是对我写作道路上最好的鼓励与支持! ❤️🔥
📌 专栏持续更新中|建议收藏 + 订阅
专栏 👉 《Python爬虫实战》,我会按照"入门 → 进阶 → 工程化 → 项目落地"的路线持续更新,争取让每一篇都做到:
✅ 讲得清楚(原理)|✅ 跑得起来(代码)|✅ 用得上(场景)|✅ 扛得住(工程化)
📣 想系统提升的小伙伴:强烈建议先订阅专栏,再按目录顺序学习,效率会高很多~

✅ 互动征集
想让我把【某站点/某反爬/某验证码/某分布式方案】写成专栏实战?
评论区留言告诉我你的需求,我会优先安排更新 ✅
⭐️ 若喜欢我,就请关注我叭~(更新不迷路)
⭐️ 若对你有用,就请点赞支持一下叭~(给我一点点动力)
⭐️ 若有疑问,就请评论留言告诉我叭~(我会补坑 & 更新迭代)
免责声明:本文仅用于学习与技术研究,请在合法合规、遵守站点规则与 Robots 协议的前提下使用相关技术。严禁将技术用于任何非法用途或侵害他人权益的行为。