FFN,Feed-Forward Neural Network,中文直译「前馈神经网络」,也是大模型 / 深度学习领域的标准官方叫法
Feed 馈送,Forward(前向) 组合成前馈
在大模型(如 Transformer 架构的 LLM)中
前馈神经网络(FFN)是「特征的非线性变换与能力增强的核心」
激活函数是「让 FFN 具备非线性表达的唯一关键」
二者结合,让大模型能从原始的词向量中,层层提取、融合、抽象出复杂的语言特征(比如从单字→词语→句式→语义→逻辑),是大模型具备理解和生成语言能力的核心基础
FFN 的本质:
大模型中是 「双塔式的线性投影 + 中间非线性增强」的结构(非传统单层 FFN),核心做特征的升维扩展→精细变换→降维还原,让模型对输入特征做深度加工
激活函数的本质:为纯线性的矩阵运算注入非线性,打破「多层线性变换等价于单层」的限制,让 FFN 能拟合语言的复杂非线性规律(比如语义的关联、语境的依赖)
二者关系:FFN 是特征变换的骨架,激活函数是让骨架拥有「表达能力」的灵魂,无激活函数的 FFN 只是简单的矩阵乘法,无法支撑大模型的复杂语言理解
大模型中 FFN 的本质(和传统 FFN 完全不同)
传统机器学习中的 FFN 是「输入→单层 / 多层线性 + 激活→输出」的简单结构,但大模型(Transformer)中的 FFN 是经过极致优化的「扩张 - 变换 - 收缩」双塔结构,也是目前所有 LLM 的标配(如 GPT、BERT、LLaMA 均采用)

σ 是希腊字母Sigma的小写形式
先把特征「放大」做精细加工,再「缩小」还原维度,全程通过线性投影做特征映射,激活函数做非线性扭曲,最终实现「在高维空间对语言特征做深度非线性变换」
特征升维扩张:高维空间能容纳更多的语言特征信息(比如一个词的语义、语境、搭配、情感等),线性升维让模型有足够的「空间」去学习复杂的特征关联
高维特征变换:在高维空间中,通过「线性投影 + 激活函数」对特征做非线性扭曲和融合,比如将「苹果」的「水果义」和「品牌义」在高维空间做不同的特征编码,让模型区分语境
特征降维还原:将加工后的高维特征映射回原始维度,保证 Transformer 各层的特征维度统一(如始终 768 维),让自注意力层和 FFN 能层层衔接,形成端到端的训练
大模型中激活函数的本质
激活函数的通用本质(所有神经网络):
为线性运算注入非线性,让模型具备拟合任意复杂非线性函数的能力
根据「万能逼近定理」,只要隐藏层足够深,带非线性激活的 FFN 能拟合任意连续函数
大模型中的激活函数,是在通用本质的基础上,做了适配语言特征的优化:
打破线性限制,让特征能「非线性关联」
线性变换的核心问题:多层线性变换的叠加,等价于「单个线性变换」(矩阵乘法的结合律)
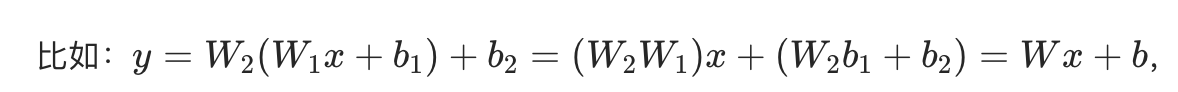
无论叠多少层,最终还是单层线性变换,无法拟合语言的非线性规律(比如「我吃饭」和「饭吃我」的语义差异,是典型的非线性关联)
激活函数的核心作用:
在线性变换后,对特征做「非线性扭曲」,让多层变换的结果不再是简单的矩阵乘积,而是能捕捉到语言的复杂非线性特征(比如语义、语序、语境依赖)
简单说:没有激活函数,大模型的 FFN 就是「无用的矩阵乘法」,所有层的叠加都失去意义
适配语言特征的「平滑非线性变换」,避免特征突变
大模型放弃了传统的 ReLU,选择GELU(高斯误差线性单元)作为标配激活函数
核心原因是:语言特征是连续、平滑的(比如「开心」和「高兴」的语义特征是渐变的,而非突变的)
GELU 的平滑非线性比 ReLU 的硬截断非线性更适配语言特征
先看 GELU 的公式和核心特点,理解大模型激活函数的设计逻辑:
GELU(x)=x⋅Φ(x)
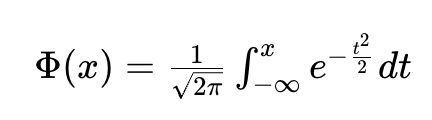
Φ 是希腊字母Phi的大写形式,标准读音为 /faɪ/(英 / 美一致)
Φ(x) 是标准正态分布的累积分布函数(简单理解:一个 0-1 之间的平滑系数,随 x 增大从 0 逐渐趋近于 1)
GELU 的输出是「输入 x」乘以「一个和 x 相关的平滑概率系数」,而非 ReLU 那样「x>0 直接输出 x,x≤0 直接置 0」的硬截断
GELU 对比 ReLU 的核心优势(大模型选择的原因)
平滑性:GELU 在整个数轴上都是平滑的(导数连续),ReLU在x=0处硬断点(导数不连续),平滑的非线性更适合捕捉语言连续语义特征
随机性:Φ(x) 理解为对 x 的随机屏蔽概率,x 越小被屏蔽的概率越高,相当于内置轻量 Dropout 正则化,提升大模型泛化能力,避免过拟合
无死亡问题:GELU 对负数输入不会直接置 0,只是输出一个极小的数值,彻底解决了 ReLU 的「死亡神经元」问题,适合大模型的超深网络训练(比如上千层的 Transformer)
大模型中激活函数的核心设计原则
平滑非线性:优先选择 GELU/Swish 等平滑激活函数,适配语言的连续特征
计算高效:无复杂的数学运算(如指数、三角函数仅少量使用),适配大模型的超大规模计算(千亿参数模型的训练 / 推理)
梯度稳定:避免梯度消失 / 爆炸(GELU 的梯度在整个数轴上都非 0 且不发散),支持大模型的深层网络训练
轻量正则化:内置一定的正则化特性(如 GELU 的随机屏蔽),减少大模型的过拟合风险
FFN + 激活函数:大模型中的「核心协作逻辑」
Transformer 大模型中,自注意力层和FFN 层是交替出现的核心模块(Transformer 的一层 = 自注意力层 + 层归一化 + FFN 层 + 层归一化)
其中:
自注意力层:核心做特征的跨位置关联(比如捕捉一句话中「主语」和「宾语」的关联,「前文」和「后文」的语境依赖),输出的是「关联后的特征向量」
FFN + 激活函数:核心做特征的深度非线性变换,对自注意力层输出的「关联特征」做精细加工(比如抽象语义、编码搭配、融合情感),输出的是「加工后的特征向量」
二者的协作流程(以 Transformer 单层为例,极简版)
输入词向量经过自注意力层,得到「语境关联后的特征向量」

大模型中 FFN 的 2 个工业级优化
为了提升大模型的训练效率和推理速度,工业界对基础 FFN 做了 2 个核心优化,本质还是「升维→激活→降维」
只是结构更高效,了解后能更贴近实际的大模型实现:
门控 FFN(Gated FFN,如 GLU/MLP-Mixer)
在基础 FFN 中加入门控机制,让模型能「自主选择」哪些特征需要加工,哪些特征需要保留:

稀疏 FFN(Sparse FFN,如 Switch Transformer)
将 FFN 隐藏层拆分为多个专家子网络(Expert),每个输入特征仅由一个/少数几个专家处理,而非全部专家,核心是用稀疏性换计算效率
让大模型能在提升隐藏层维度的同时,不显著增加计算量
目前 GPT-3、PaLM 均采用稀疏 FFN,支撑千亿 / 万亿参数的大模型训练
总结
FFN(大模型):Transformer 的特征非线性变换核心,通过「升维→激活→降维」的双塔结构,在高维空间对语言特征做深度加工,是模型抽象特征的关键
激活函数(大模型):FFN 的非线性灵魂,通过 GELU 等平滑激活函数,为线性投影注入非线性,让模型能拟合语言的复杂规律,同时适配大模型的训练稳定性
二者结合:
是大模型理解和生成语言的核心基础,与自注意力层协作,层层提取、抽象语言特征,最终让大模型具备高阶的语言能力。
简单说:
自注意力层让大模型「看到」特征的关联,FFN + 激活函数让大模型「理解」特征的含义