在 MySQL 的 InnoDB 存储引擎中,索引不仅是加速查询的工具,更是数据组织的核心机制 。其中,聚簇索引(Clustered Index) 与 非聚簇索引(Non-Clustered Index,又称二级索引 / Secondary Index) 构成了 InnoDB 表的底层存储骨架。
一、聚簇索引(Clustered Index)
1. 定义与特性
- 聚簇索引决定了表数据的物理存储顺序。
- 在 InnoDB 中,每张表有且仅有一个聚簇索引。
- 如果表定义了
PRIMARY KEY,则其自动成为聚簇索引。 - 若无主键,InnoDB 会尝试使用第一个
UNIQUE NOT NULL列;若仍无,则隐式生成一个 6 字节的GEN_CLUST_INDEX。
2. 存储结构
- 聚簇索引的 叶子节点直接存储整行数据(Row Data)。
- 非叶子节点存储索引键值和指向下一级页的指针。
- 因此,通过聚簇索引查询可避免额外 I/O(即"索引即数据")。
3. 优势
- 主键查询极快(O(log n) 且无需回表)。
- 范围查询高效(数据物理连续,利于顺序 I/O)。
4. 总结
| 类别 | 具体表现 | 说明 / 影响 |
|---|---|---|
| 核心优势 | ||
| 数据即索引 | 叶子节点直接存储完整行数据 | 主键查询无需回表,I/O 最小化 |
| 高效范围扫描 | 数据按主键物理有序存储 | 范围查询(如 WHERE id BETWEEN 100 AND 200)可顺序读取,缓存友好 |
| 减少二级索引体积 | 二级索引只需存储主键值(而非完整行指针) | 相比其他引擎(如 MyISAM),InnoDB 二级索引更紧凑(前提是主键短) |
| 提升缓存效率 | 热点数据在物理上相邻 | Buffer Pool 更易命中连续页,提升 OLTP 性能 |
| 支持高效分页 | 基于主键的 LIMIT offset, size 可利用有序性 |
尤其在"基于游标分页"(如 WHERE id > last_id)中表现优异 |
| 主要缺点 | ||
| 每表仅一个 | 一张表只能有一个聚簇索引 | 无法为其他高频查询字段提供"数据即索引"的优势 |
| 主键变更代价高 | 修改主键值需移动整行数据(包括所有二级索引中的主键引用) | UPDATE PRIMARY KEY 是高成本操作,应避免 |
| 无序主键导致碎片 | 使用 UUID、随机字符串等无序主键 | 插入时频繁页分裂 + 空间碎片 → 降低写性能与存储效率 |
| 大主键拖累全局 | 主键过大会膨胀所有二级索引 | 因二级索引叶子节点存储主键值,主键大小直接影响全表索引体积 |
| 不适合频繁更新的列 | 若主键字段常被更新,将触发整行物理移动 | 极不推荐用业务字段(如手机号、邮箱)作主键 |
二、非聚簇索引(Secondary Index)
1. 定义与特性
- 非聚簇索引是除聚簇索引外的所有索引(如普通索引、唯一索引、联合索引等)。
- 其 叶子节点不存储完整行数据,而是存储对应行的聚簇索引键值(即主键值)。
2. 查询过程:回表(Lookup)
当通过二级索引查询非索引列时:
- 先在二级索引 B+ 树中定位到主键值;
- 再用该主键值回表(即再次访问聚簇索引)获取完整行数据。
这一过程称为 "回表查询",可能带来额外的随机 I/O,影响性能。
3. 覆盖索引优化
若查询字段全部包含在二级索引中(即满足"覆盖索引"条件),则无需回表,可显著提升性能。
4. 总结
| 类别 | 具体表现 | 说明 / 影响 |
|---|---|---|
| 核心优势 | ||
| 查询加速 | 点查非主键字段(如 WHERE email = ?) |
避免全表扫描,时间复杂度从 O(n) 降至 O(log n) |
| 覆盖索引 | 查询字段全部包含在索引中(如 SELECT status FROM orders WHERE status = 1) |
完全避免回表,性能极致优化 |
| 排序与分页 | 支持 ORDER BY 字段索引(如 ORDER BY created_at) |
利用索引有序性,避免 filesort 和临时表 |
| JOIN 性能 | 加速关联字段匹配(如 JOIN ... ON user_id) |
减少嵌套循环次数,提升多表连接效率 |
| 多维过滤 | 联合索引支持复合条件(如 WHERE status = 1 AND amount > 1000) |
单一索引服务复杂查询,替代多个单列索引 |
| 主要缺点 | ||
| 回表开销 | 查询非索引字段需回表(访问聚簇索引) | 引入额外随机 I/O,增加延迟 |
| 主键膨胀 | 二级索引叶子节点存储主键值 | 主键越大(如 UUID),所有二级索引越臃肿 |
| 写入成本 | INSERT/UPDATE/DELETE 需同步更新所有相关二级索引 |
索引越多,写入延迟越高,即写放大越严重,影响吞吐 |
| 存储开销 | 每个二级索引都是完整 B+ 树结构 | 增加磁盘占用和 Buffer Pool 压力 |
| 范围查询局限 | 虽支持范围扫描,但若需其他字段仍需回表 | 不如聚簇索引天然适合大范围连续读 |
三、聚簇索引 vs 非聚簇索引:核心对比
| 维度 | 聚簇索引(Clustered Index) | 非聚簇索引(Secondary Index) |
|---|---|---|
| 数量限制 | 每表仅 1 个 | 可创建多个 |
| 叶子节点内容 | 完整行数据 | 聚簇索引键(通常是主键) |
| 是否需要回表 | 否 | 是(除非覆盖索引) |
| 物理存储 | 数据按索引顺序存储 | 独立于数据存储 |
| 插入性能影响 | 主键无序插入会导致页分裂 | 影响较小,但维护成本随数量增加 |
| 适用场景 | 主键查询、范围扫描 | 辅助过滤、排序、连接字段 |
四、查询执行流程图
以下展示通过二级索引查询非覆盖字段的典型路径:
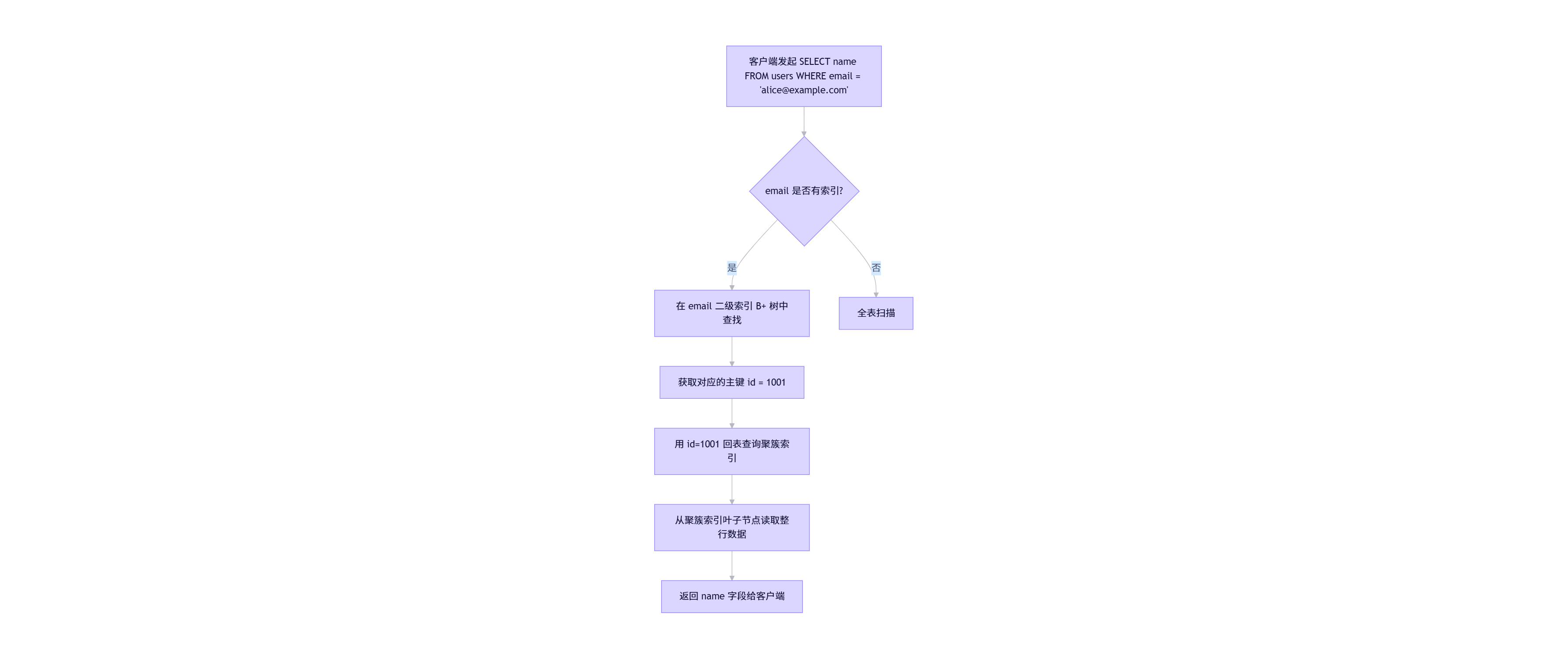
注:若查询为
SELECT email FROM users WHERE email = ...,则因
五、实践建议
1. 最佳实践
- 主键应尽量短、有序(如自增 ID),避免 UUID 导致频繁页分裂。
- 对高频查询字段建立覆盖索引,避免回表。
- 联合索引遵循最左前缀原则,并把高区分度字段放前面。
2. 避免行为
- 使用大字段(如 VARCHAR(255))作主键 → 膨胀二级索引体积。
- 忽略回表成本,在 OLTP 场景中滥用
SELECT *+ 二级索引。 - 在频繁更新的列上建索引 → 增加写放大。
六、面试题
Q1:为什么 InnoDB 表必须有聚簇索引?
答:InnoDB 以聚簇索引组织数据存储。若无显式主键,InnoDB 会隐式创建 6 字节的隐藏聚簇索引,确保数据有物理存储结构。
Q2:二级索引的叶子节点存的是什么?
答 :存的是对应行的聚簇索引键值(通常是主键)。因此主键不宜过大,否则会膨胀所有二级索引。
Q3:什么是"回表"?如何避免?
答 :回表指通过二级索引查到主键后,再查聚簇索引获取完整数据。可通过覆盖索引(查询字段全在索引中)避免。
Q4:聚簇索引的主键选择为何推荐自增 ID 而非 UUID?
答:自增 ID 保证插入顺序性,减少页分裂和碎片;UUID 无序,导致频繁 B+ 树结构调整,降低写性能。
Q5:一张表可以有多个聚簇索引吗?
答 :不可以。InnoDB 每表仅支持一个聚簇索引,由主键或隐式生成键决定。