目录
[二、REINFORCE + baseline](#二、REINFORCE + baseline)
一、Reinforce介绍
最原始的 REINFORCE 更新公式是:
其中R代表Q(S,A),也就是某个轨迹的放缩reward。Reinfore的特点就是通过蒙特卡洛采样的方法采样一个轨迹,之后得到Q(S,A)。
上述梯度计算可能方差比较大,为了降低方差,引入了baseline。
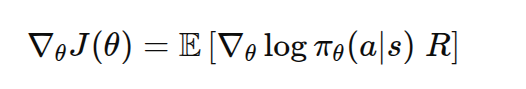
二、REINFORCE + baseline

三、证明为啥可以降低方差
对于Reinforce的这个b(s),通常取一个轨迹的滑动平均。下面证明这个取法为啥可以降低方差。
1.计算策略梯度的方差
2.先处理第二项
3.所以上述相当于找到b优化第一项
这是关于 b 的二次函数
对 b 求导
结论(最优 baseline)
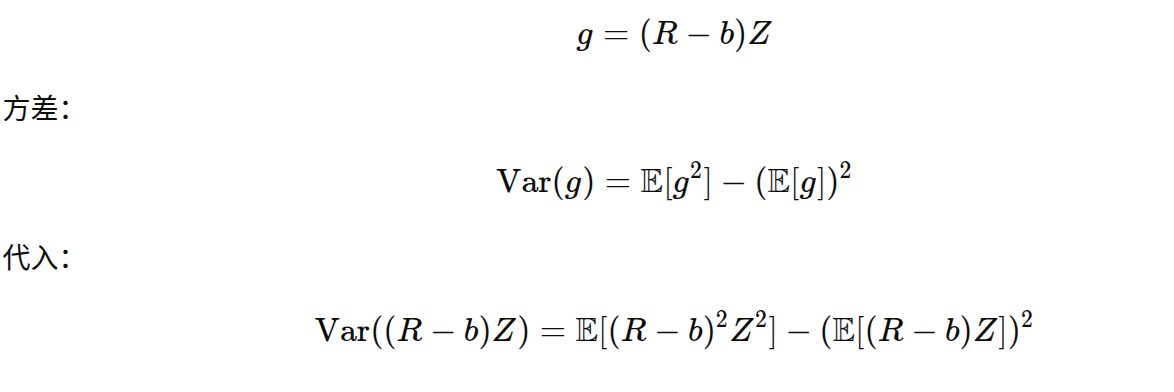


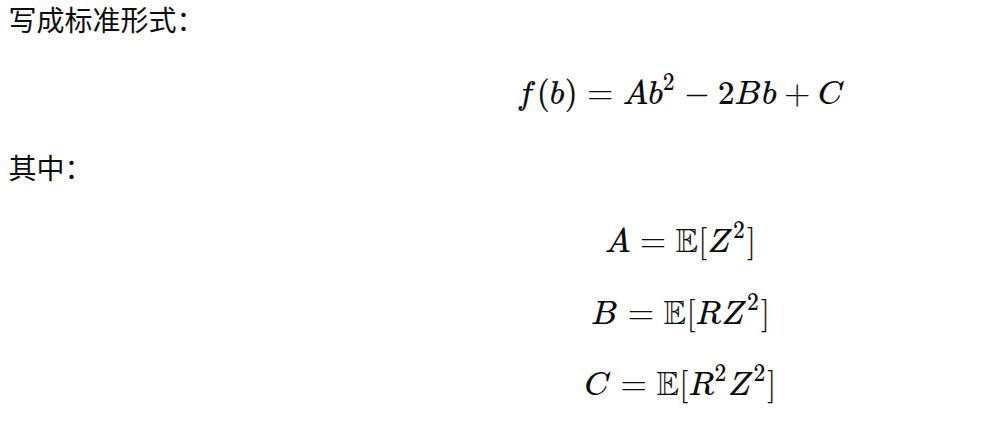
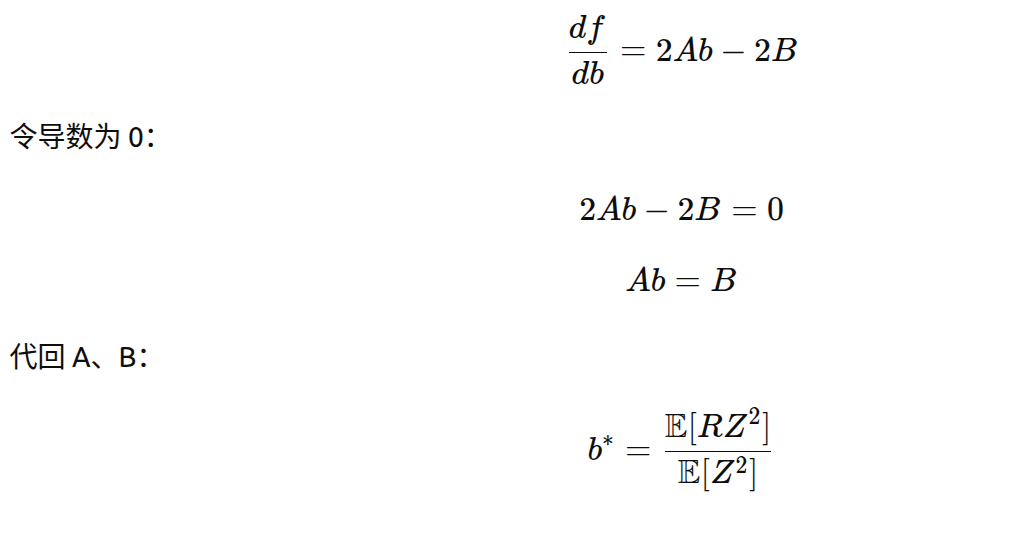

四、证明重要性质
因为梯度对参数求导,与对动作求和无关:
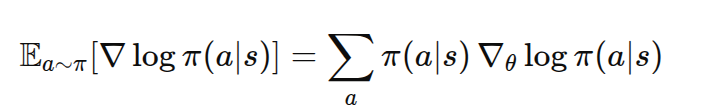
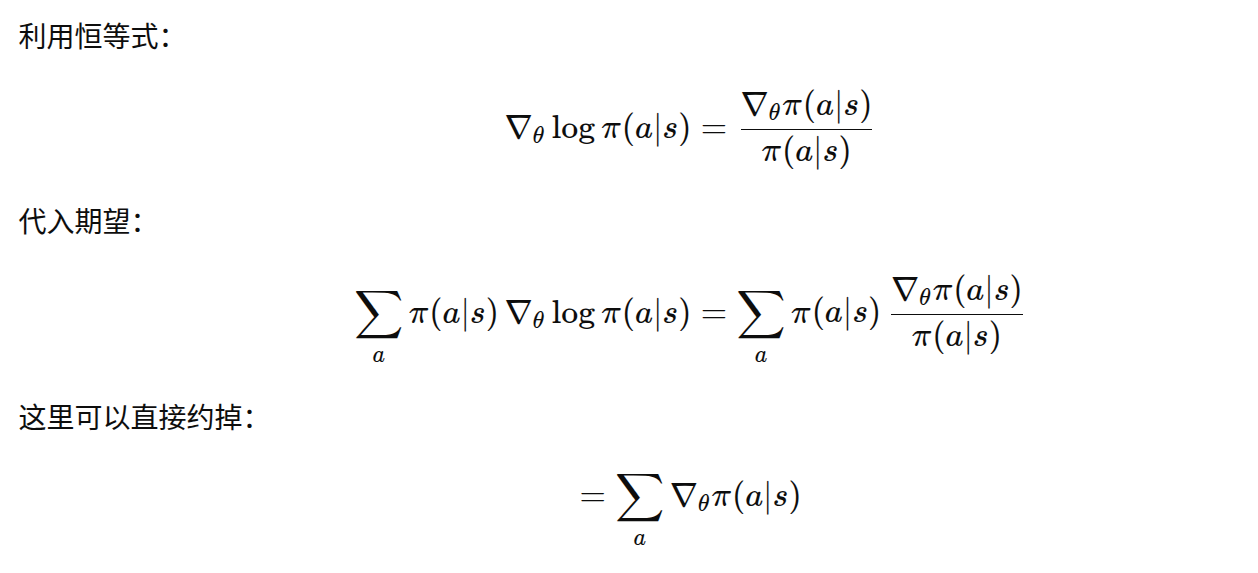
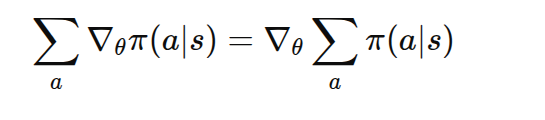
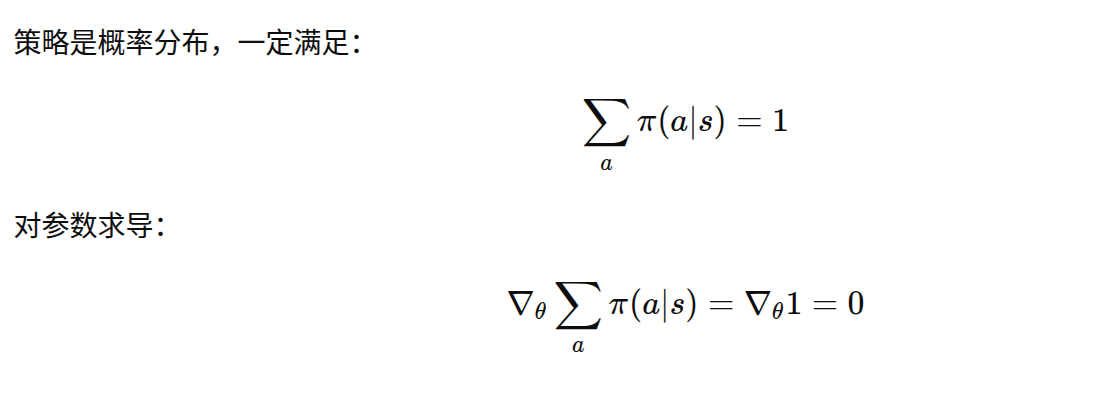
五、示例代码
1.解释
下面的代码是使用强化学习做一个任务分配的问题,机器人和任务的输入都是(x,y)的二维坐标。之后reward是-欧式距离。算法最后需要找到距离当前机器人最近的任务的策略。
2.Reinforce解释
由于在这个环境里面,一个reward就是一个轨迹,所以reward = Q(S,A)
baseline 就使用滑动平均替代。
pythonr = -torch.norm(task_xy[action] - robot_xy) / 10.0 r_item = float(r.detach().cpu().item()) baseline = (1 - beta) * baseline + beta * r_item advantage = (r - baseline).detach()
3.代码
python
import math
import random
import numpy as np
import torch
import torch.nn as nn
import os
# -------------------------
# Reproducibility
# -------------------------
seed = 42
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
device = "cuda" if torch.cuda.is_available() else "cpu"
MODEL_PATH = "reinforce_cross_attn_ckpt.pth" # RL ckpt
# -------------------------
# Model
# -------------------------
class CrossAttnChooser(nn.Module):
def __init__(self, d_model=32, hidden=64):
super().__init__()
self.robot_enc = nn.Sequential(
nn.Linear(2, hidden), nn.Tanh(),
nn.Linear(hidden, d_model),
)
self.task_enc = nn.Sequential(
nn.Linear(2, hidden), nn.Tanh(),
nn.Linear(hidden, d_model),
)
self.Wq = nn.Linear(d_model, d_model, bias=False)
self.Wk = nn.Linear(d_model, d_model, bias=False)
self.Wv = nn.Linear(d_model, d_model, bias=False)
self.post_ffn = nn.Sequential(
nn.Linear(d_model, hidden), nn.ReLU(),
nn.Linear(hidden, d_model),
)
def forward(self, robot_xy, task_xy):
hr = self.robot_enc(robot_xy) # (d,)
ht = self.task_enc(task_xy) # (N,d)
Q = self.Wq(hr) # (d,)
K = self.Wk(ht) # (N,d)
V = self.Wv(ht) # (N,d)
attn_scores = (K @ Q) / math.sqrt(K.shape[-1]) # (N,)
a = torch.softmax(attn_scores, dim=0) # (N,)
c = a @ V # (d,)
u = self.post_ffn(c) # (d,)
logits = (K @ u) / math.sqrt(K.shape[-1]) # (N,)
probs = torch.softmax(logits, dim=0) # (N,)
return logits, probs
# -------------------------
# Helpers / Env
# -------------------------
def sample_tasks(n_tasks=3, low=-10.0, high=10.0):
xy = np.random.uniform(low, high, size=(n_tasks, 2)).astype(np.float32)
return torch.tensor(xy, device=device)
def nearest_task_index(robot_xy, task_xy):
dists = torch.norm(task_xy - robot_xy[None, :], dim=1)
return torch.argmin(dists).long()
# -------------------------
# Init
# -------------------------
model = CrossAttnChooser(d_model=32, hidden=64).to(device)
# ✅ RL 训练建议更小 lr,避免 logits 直接推爆导致 probs=[1,0,0]
opt = torch.optim.Adam(model.parameters(), lr=2e-4)
robot_xy = torch.tensor([0.0, 0.0], device=device)
total_steps = 100000
print_every = 1000
save_every = 2000
# running baseline (EMA)
baseline = 0.0
beta = 0.02
# logging (EMA)
reward_ema = 0.0
reward_beta = 0.02
# ✅ 探索相关:熵正则 & 温度
entropy_coef = 0.01 # 0.005~0.05 可调,越大越探索
tau = 2.0 # temperature,>1 更平滑更探索
# -------------------------
# Load checkpoint if exists
# -------------------------
start_step = 0
if os.path.exists(MODEL_PATH):
print(f"Loading checkpoint: {MODEL_PATH}")
ckpt = torch.load(MODEL_PATH, map_location=device)
model.load_state_dict(ckpt["model"])
# ✅ 切 reward / 调 lr 时,强烈建议不要 load optimizer(动量会把你推向极端)
# opt.load_state_dict(ckpt["optimizer"])
# start_step = int(ckpt.get("step", 0))
baseline = float(ckpt.get("baseline", 0.0))
reward_ema = float(ckpt.get("reward_ema", 0.0))
else:
print("No checkpoint found, training from scratch.")
def save_ckpt(step):
torch.save({
"model": model.state_dict(),
"optimizer": opt.state_dict(),
"step": step,
"baseline": baseline,
"reward_ema": reward_ema,
"seed": seed,
"tau": tau,
"entropy_coef": entropy_coef,
}, MODEL_PATH)
print(f"Checkpoint saved: step={step} -> {MODEL_PATH}")
# -------------------------
# Training (REINFORCE + baseline + entropy)
# -------------------------
for step in range(start_step + 1, total_steps + 1):
task_xy = sample_tasks(3)
logits, _ = model(robot_xy, task_xy)
# ✅ 用 logits 构造分布(数值更稳),并用 temperature 拉平
dist = torch.distributions.Categorical(logits=logits / tau)
action = dist.sample()
logp = dist.log_prob(action)
# ✅ reward:负欧式距离(建议缩放,避免 reward/advantage 过大)
r = -torch.norm(task_xy[action] - robot_xy) / 10.0
r_item = float(r.detach().cpu().item())
baseline = (1 - beta) * baseline + beta * r_item
advantage = (r - baseline).detach()
# ✅ 熵正则:鼓励探索,防止 probs 早早变成 [1,0,0]
entropy = dist.entropy()
loss = -(logp * advantage) - entropy_coef * entropy
opt.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0) # ✅ 防止梯度爆
opt.step()
reward_ema = (1 - reward_beta) * reward_ema + reward_beta * r_item
if step % print_every == 0:
# 打印一次当前 probs(从 logits/tau 得到)
with torch.no_grad():
probs_dbg = torch.softmax(logits / tau, dim=0)
print("Probs:", probs_dbg.detach().cpu().numpy())
print(f"action={action.item()} logp={logp.item():.4f} entropy={entropy.item():.4f}")
model.eval()
with torch.no_grad():
correct = 0
trials = 1000
for _ in range(trials):
txy = sample_tasks(3)
y_true = nearest_task_index(robot_xy, txy).item()
l, _ = model(robot_xy, txy)
p = torch.softmax(l, dim=0) # 评估用 tau=1 更真实
y_pred = torch.argmax(p).item()
correct += (y_pred == y_true)
acc = correct / trials
model.train()
print(f"step={step:6d} r_ema={reward_ema:.4f} baseline={baseline:.4f} "
f"adv={advantage.item():.4f} loss={loss.item():.4f} acc={acc*100:.1f}%")
if step % save_every == 0:
save_ckpt(step)
save_ckpt(total_steps)
# -------------------------
# Test
# -------------------------
model.eval()
with torch.no_grad():
fixed_tasks = torch.tensor([[-8.0, 0.0],
[ 2.0, 0.0],
[ 7.0, 0.0]], device=device)
logits, _ = model(robot_xy, fixed_tasks)
probs = torch.softmax(logits, dim=0)
print("\nFixed tasks:", fixed_tasks.detach().cpu().numpy())
print("Probs:", probs.detach().cpu().numpy())
print("Chosen task index:", torch.argmax(probs).item())