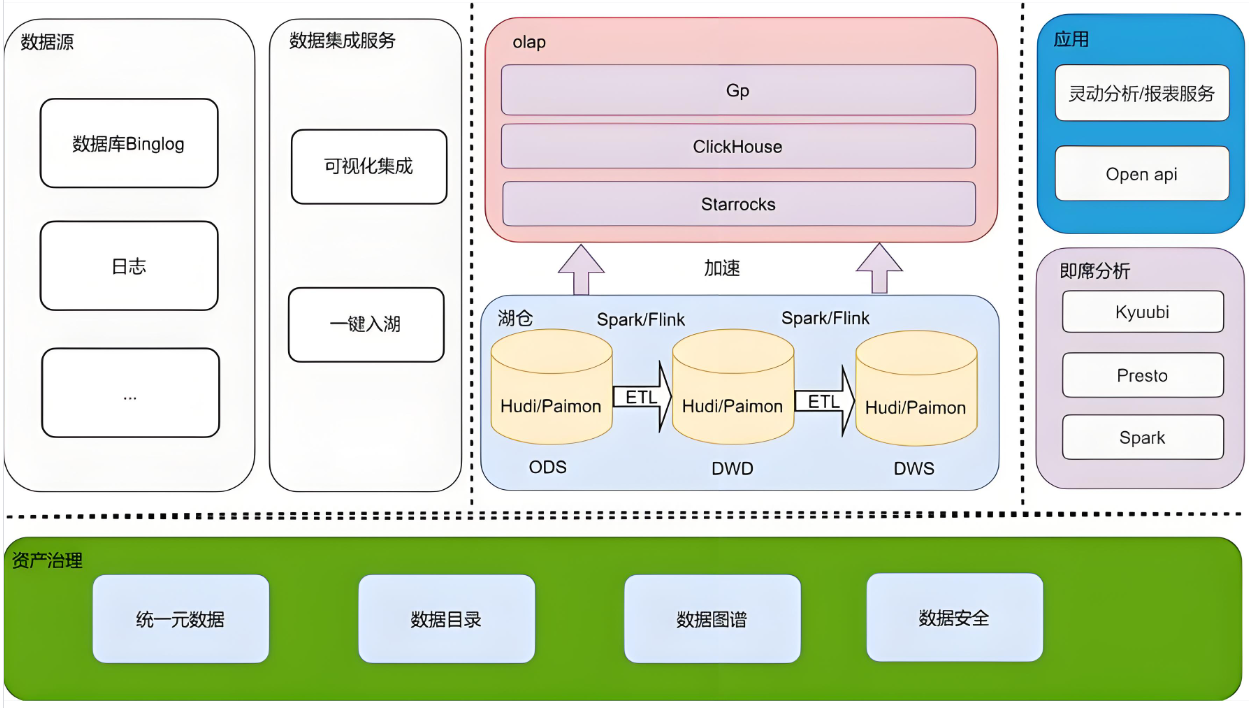
一、Paimon核心特性与架构解析
1.1 湖仓一体设计哲学
- 数据湖低成本存储:基于HDFS/S3/OSS的列式存储(ORC/Parquet),支持Schema Evolution与Time Travel历史版本查询。
- 数据库级事务能力:ACID事务保障、主键表精准更新、Z-Order排序优化数据跳过,查询性能提升3倍。
- 流批一体处理引擎:同时支持批处理(如Spark)与流处理(如Flink),通过Changelog Producer实现增量计算。
1.2 最新版本特性(0.8.0)
- Deletion Vector优化:查询速度提升50%,减少Compaction压力。
- Partial Update引擎:支持增量字段更新,降低全量写成本。
- 多引擎兼容扩展:新增与StarRocks/Doris的深度集成,支持维表点查与全增量消费。
二、Paimon操作全流程指南
2.1 环境准备与Catalog配置
-
依赖安装 :
xml`<dependency> <groupId>org.apache.paimon</groupId> <artifactId>paimon-flink-1.14</artifactId> <version>0.8.0</version> </dependency> ` -
Flink Catalog创建 :
sql`CREATE CATALOG my_catalog WITH ( 'type' = 'paimon', 'warehouse' = 's3://bucket/paimon' ); USE CATALOG my_catalog; `
2.2 表创建与数据操作
-
主键表示例 :
sql`CREATE TABLE user_behavior ( user_id BIGINT, item_id BIGINT, behavior STRING, PRIMARY KEY (user_id, item_id) NOT ENFORCED ) PARTITIONED BY (dt STRING); ` -
流式写入与查询 :
sql`INSERT INTO user_behavior SELECT * FROM kafka_source_table; -- 流式消费变更日志 SELECT * FROM user_behavior /*+ OPTIONS('changelog-producer'='full-compaction') */; `
三、性能优化与生产实践案例
3.1 关键调优参数
-
分区与分桶策略 :按时间分区(如
dt=20240101),桶数量建议为CPU核数2倍,单桶数据量控制在1GB。 -
Compaction优化 :
sql`SET 'compaction.max.size' = '128mb'; -- 减少小文件数量 SET 'target.file.size' = '1gb'; -- 优化查询并行度 ` -
内存管理 :调整
taskmanager.memory.process至70%可用内存,避免OOM。
3.2 生产环境案例
- 贝壳找房实时排序实践:利用事件时间分段与Paimon拉链表,实现全量数据实时分组排序,内存消耗降低40%。
- 蚂蚁五福活动去重:通过Partial Update引擎与Changelog,CPU使用量下降60%,Checkpoint耗时减少90%。
四、常见问题与避坑指南
4.1 典型问题处理
- 小文件过多:启用Dedicated Compaction作业,定期合并Level0文件。
- 事务冲突:主键表并发写入时,通过分桶隔离确保序列化提交。
- Schema Evolution :重命名列时使用
ALTER TABLE ... RENAME COLUMN,避免全表扫描。
4.2 未来展望
- CDC能力增强:支持更丰富的数据源同步,如MySQL Binlog实时入湖。
- 引擎生态扩展:与Hologres/MaxCompute深度集成,构建云原生湖仓架构。