文档搜索引擎索引模块程序见下文:
本文是索引模块程序的实现细节篇。
目录
[1. 关于listFile方法](#1. 关于listFile方法)
[2. 关于展示URL与跳转URL](#2. 关于展示URL与跳转URL)
[3. 关于本地URL与在线URL](#3. 关于本地URL与在线URL)
[4. 关于正斜杠/与反斜杠\](#4. 关于正斜杠/与反斜杠)
[5. 关于去HTML页面标签](#5. 关于去HTML页面标签)
[6. 关于使用倒排索引进行查找](#6. 关于使用倒排索引进行查找)
[7. 关于关键字与文档内容的相关性](#7. 关于关键字与文档内容的相关性)
[8. 关于for each遍历](#8. 关于for each遍历)
[9. 关于索引结构的store与load](#9. 关于索引结构的store与load)
1. 关于listFile方法
File类型对象可以调用一个名为listFile的方法用于查看当前目录的内容,但该方法只能查看到当前目录的下一级目录,无法自动进行递归查看该目录的子目录的内容,为了实现对根目录的完全遍历,需手动实现递归,具体操作如下:
对当前目录调用listFile方法获取其当前子目录和文件,依次遍历:
对于文件则直接作为最终遍历结果加入到fileList中,对于目录则再次调用封装有listFile的方法;
(File类提供了判断为目录的方法:isDirectory或判断为普通文件的方法:isFile,可直接调用)
2. 关于展示URL与跳转URL

上图中,标题是一个a标签,称为跳转URL,点击可实现跳转;
在搜狗、百度等大型全站搜索引擎上,二者由于需计数点击量会有所不同,但当前无需进行区分;
3. 关于本地URL与在线URL
以ArrayList.html为例:
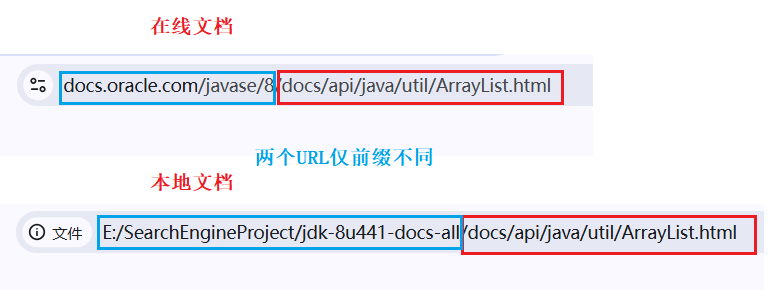
可见二者URL具有统一性,仅前缀有所不同。
由于当前搜索引擎的实现目标为:用户点击查询结果时可以跳转到对应的线上文档页面;
具体而言,即令 https://docs.oracle.com/javase/8/docs/api/ 为固定前缀,再根据当前本地文档所在路径与前缀进行拼接,从而实现本地URL到在线URL的转换;
4. 关于正斜杠/与反斜杠\
URL使用正斜杠,Windows文件路径使用反斜杠,创建TestURL测试文件:
java
import java.io.File;
public class TestURL {
private static final String INPUT_PATH="E:/SearchEngineProject/jdk-8u441-docs-all/docs/api/";
public static void main(String[] args) {
File file = new File
("E:/SearchEngineProject/jdk-8u441-docs-all/docs/api/java/util/ArrayList.html");
// 获取在线文档的固定前缀
String part1="https://docs.oracle.com/javase/8/docs/api/";
// 从本地文档获取当前查询的.html页面的后缀
String part2=file.getAbsolutePath().substring(INPUT_PATH.length());
// 拼接得到在线文档完整URL
String result=part1+part2;
System.out.println(result);
}
}运行测试文件,得到的拼接后的URL如下:
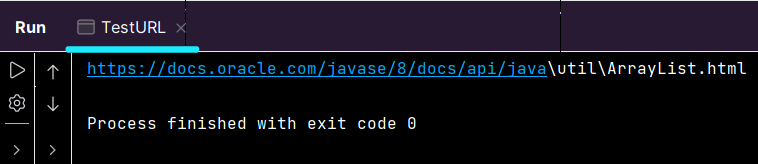
前部分为正斜杠而后部分为反斜杠,拷贝到浏览器地址栏,回车后会发现浏览器自动实现了反斜杠的转换,故而无需再额外处理;
5. 关于去HTML页面标签
一个完整的HTML页面 = HTML标签+内容(java文档),解析正文即进行HTML页面去标签操作。
(1)方法1:正则表达式(较麻烦)
正则表达式是一种计算机中进行字符串处理或匹配的常见手段,核心就是通过一些特殊符号来描述字符串的特征,再检查某个字符串是否符合这些特征;
(2)方法2:根据HTML页面标签的特点(更简单)
HTML页面中的标签都是由< >表示的,故而可以通过逐个取出HTML中每个字符再逐个判定是否为标签的方式进行去标签:从<开始至>中间的字符都不进行数据拷贝,即不放在结果中,从而实现HTML页面的去标签化;
(可设置一个布尔类型的标志位flag,标志是否进行数据拷贝)
HTML要求内容中的<使用<表示,>使用>表示,故使用这种方法,HTML页面内容也可以被正确处理。
6. 关于使用倒排索引进行查找
(1)由于实际搜索时,用户可能输入的是一句话,实际搜索过程的实现需要对这一整句话进行分词后,再根据词去查倒排索引,故使用倒排索引的方法命名为getInverted,参数为String类型的变量term,表示分词后的查找词;
(2)对于getInverted方法的返回值,不仅需要返回文档的id即docId,并且文档与关键词之间存在相关性的强弱,故创建一个Weight类,包含 ++文档id++ 与 ++文档和关键词之间的相关性++;
7. 关于关键字与文档内容的相关性
在计算相关性时,显然标题中出现关键词更能说明该文档与关键词密切相关,应将标题和内容中关键词出现的词频分开统计并计以不同权重。
实际的开发引擎中计算权重的公式非常复杂,往往与点击率等相关,并需要持续调整和反复迭代,但对于本项目中的小型站内搜索引擎,此处仅参考词频计算权重。
8. 关于for each遍历
java
for(Map.Entry<String, WordCount> entry : wordCountHashMap.entrySet())在构建倒排索引统计词频时使用到了for each进行遍历,for each遍历要求对象是可迭代的,即实现了Iterable接口,而Map主要功能是根据key查找value,其并没有实现Iterable接口,故而不能使用for each遍历一个Map。此处将Map的键值对打包在一起构成一个新类Entry,从而转换为Set再进行遍历。
但请注意Map转换为Set后,也就失去了Map根据key查value的功能。
9. 关于索引结构的store与load
索引的构建比较耗时,若索引结构存储在内存中,则服务器启动时才构建索引,比较耗时。但可以现构造索引,将构造好的索引存储在磁盘中,再令线上服务器直接加载这个构造好的索引。
将索引结构保存到文件的方法采用现将内存中的索引结构转换为一个字符串,即进行序列化,再写文件,此处采用jackson与ObjectMapper使用JSON实现序列化,直接调用writeValue方法即可将字符串写入文件:
java
// 创建两个文件分别保存正排索引和倒排索引
File forwardIndexFile = new File(INDEX_PATH+"forward.txt");
File invertedIndexFile = new File(INDEX_PATH+"inverted.txt");
try {
objectMapper.writeValue(forwardIndexFile, forwardIndex);
objectMapper.writeValue(invertedIndexFile, invertedIndex);
} catch (IOException e) {
e.printStackTrace();
}将特定字符串反向解析为结构化数据即称为反序列化,此处采用jackson提供的辅助工具类TypeReference将字符串转为ArrayLiat<DocInfo>,readValue方法就会按照该结构对文件内容进行读取与解析:
java
// 指定加载索引路径
File forwardIndexFile = new File(INDEX_PATH+"forward.txt");
File invertedIndexFile = new File(INDEX_PATH+"inverted.txt");
try{
// 创建匿名内部类(该类实现了TypeReference),再创建一个匿名内部类的实例
forwardIndex = objectMapper.readValue(forwardIndexFile, new TypeReference<ArrayList<DocInfo>>() {});
}catch (Exception e){
e.printStackTrace();
}