引言:为什么你的企业微调需要隐私保护?
最近和几位做金融科技的朋友聊天,他们都在头疼同一个问题:公司想用大模型优化客服系统,但聊天记录里全是客户身份证号、交易金额这些敏感信息。直接拿去微调?法务部门第一个不答应。用公有云API?数据安全更是没保障。
这其实反映了一个普遍困境:企业想用好大模型,但数据出不了门。
去年某知名券商就因为使用第三方AI服务导致客户信息泄露,被重罚数百万。随着《数据安全法》和欧盟《AI法案》落地,合规要求越来越严。医疗行业的HIPAA、金融行业的监管要求,都让"数据不出域"成为硬性约束。
但企业的需求又是真实存在的:
- 银行想用内部财报训练财务分析助手
- 医院想用脱敏病历提升诊断效率
- 律所想用案例库打造合同审查工具
好消息是,技术已经给出了解决方案。通过隐私保护微调,你可以在不暴露原始数据的前提下,让大模型学会你的业务知识。今天我就用一篇文章,带你彻底搞懂这套技术,从原理到实操,确保你能安全合规地打造自己的专属AI助手。
技术原理:三把"安全锁"的工作原理
第一把锁:差分隐私------给数据加"马赛克"
想象一下这个场景:你所在部门有100人的工资数据,现在想计算平均工资,但又不能泄露任何人的具体薪资。怎么做?
聪明的办法是:在计算时给每个人的工资加上一点随机噪声。比如张三实际工资是20000元,你报告时随机说成20150元或19880元。加的人多了,这些噪声会相互抵消,最终的平均值依然准确,但没人能反推出张三的真实工资。
这就是差分隐私 的核心思想:通过精心设计的数学噪声,保护每一个体数据。
在大模型微调中,我们主要在两个环节加噪声:
- 梯度噪声:模型学习时,会根据数据调整参数(这个过程叫"梯度下降")。我们在梯度上添加噪声,让攻击者无法从模型更新中反推原始数据。
- 输出噪声:最终模型预测时,对输出做轻微随机化处理。
有个关键参数需要理解:隐私预算ε。它衡量的是隐私保护强度:
- ε越小 → 噪声越大 → 隐私越强 → 模型准确率可能下降
- ε越大 → 噪声越小 → 隐私越弱 → 模型更准确
通常设置:
- ε=1-2:强隐私保护(医疗核心数据)
- ε=4-8:平衡模式(一般企业数据)
- ε>10:弱保护(公开数据微调)
在实际测试中,当ε=8时,模型性能损失通常控制在5%以内,这是一个很好的平衡点。
第二把锁:联邦学习------数据不动,模型动
传统微调是把数据集中到一个地方训练。联邦学习反其道而行:让模型去各个数据源"轮转学习" 。
假设某银行有北京、上海、深圳三个分行,都有本地客户数据但不能共享。联邦学习的做法是:
- 总行初始化一个基础模型,发给各分行
- 各分行用自己的本地数据训练模型(不传数据)
- 各分行只把训练后的模型参数加密上传
- 总行安全聚合所有参数,更新全局模型
- 重复这个过程直到模型收敛
这样做的好处显而易见:原始数据永远留在本地。即使某个环节被攻击,泄露的也只是模型参数片段,无法还原出原始数据。
第三把锁:LoRA微调------只改"一小部分"参数
传统微调需要调整模型所有参数(动辄数百亿个),这带来两个问题:
- 计算成本极高
- 隐私风险大(改动越多,泄露信息可能越多)
LoRA(Low-Rank Adaptation) 提供了一个巧妙的解法:只训练少量新增参数,冻结原始模型。
可以理解为:不直接修改原版教科书,而是提供一本薄薄的"补充讲义"。模型推理时,同时参考教科书和补充讲义。
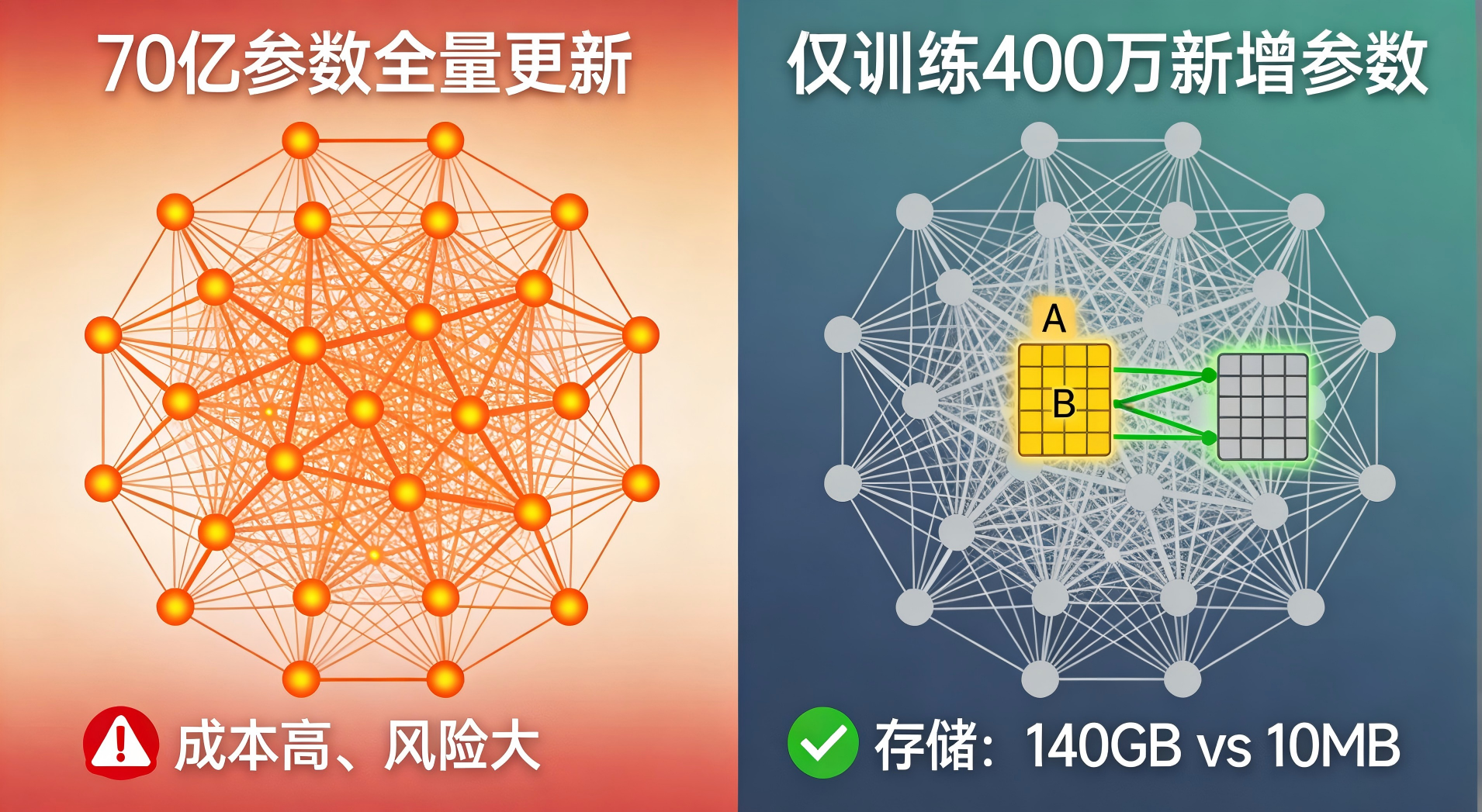
技术细节(理解即可):
- 原始大模型参数:W(维度d×d,例如4096×4096)
- LoRA引入两个小矩阵:A(d×r)和B(r×d),r远小于d
- 实际计算:输出 = (W + BA) × 输入
- 训练时只更新A和B,W保持不变
以LLaMA-7B模型为例:
- 全参数微调:需要训练70亿个参数
- LoRA微调(r=8):只需训练约400万个参数
- 存储空间:从140GB降到仅10MB
这对隐私保护意味着什么?攻击者能获取的"训练痕迹"大大减少,因为95%以上的模型参数根本没动过。
实践步骤:从零搭建隐私保护微调流水线
环境准备(10分钟搞定)
bash
# 创建专用环境(避免包冲突)
conda create -n safe-llm python=3.9 -y
conda activate safe-llm
# 安装核心库
pip install torch==2.1.0 transformers==4.35.0
pip install peft==0.7.0 # LoRA微调库
pip install opacus==1.4.0 # 差分隐私库
pip install datasets==2.14.0 # 数据集处理如果你的机器没有GPU,可以用CPU版本:
bash
pip install torch==2.1.0 --index-url https://download.pytorch.org/whl/cpu第一步:数据准备与脱敏
先看一个企业常见的数据格式------客服对话:
python
原始数据(需要脱敏):
{
"dialog_id": "CS20240115001",
"customer": "张*(用户ID:U123456)",
"agent": "客服工号A088",
"messages": [
{"role": "user", "content": "我的信用卡尾号3081最近有一笔5000元消费,在哪里?"},
{"role": "assistant", "content": "张先生您好,查询到2024年1月14日在**沃尔玛(北京中关村店)**消费5000元。"}
]
}
脱敏后数据:
{
"dialog_id": "CS20240115001",
"messages": [
{"role": "user", "content": "我的信用卡最近有一笔消费,在哪里?"},
{"role": "assistant", "content": "您好,查询到在**某商场**有一笔消费。"}
]
}实现自动脱敏的代码模板:
python
import re
def desensitize_text(text, language="zh"):
"""基础脱敏函数(实际项目需更完善)"""
# 移除身份证号
text = re.sub(r'\d{17}[\dXx]', '[ID_NUMBER]', text)
# 移除手机号
text = re.sub(r'1[3-9]\d{9}', '[PHONE]', text)
# 移除银行卡号(保留后4位)
text = re.sub(r'\d{12}(\d{4})', '**** **** **** \1', text)
# 移除具体金额(替换为范围)
def replace_amount(match):
amount = float(match.group())
if amount > 10000:
return "大额"
elif amount > 1000:
return "中额"
else:
return "小额"
text = re.sub(r'\d+.?\d*元', replace_amount, text)
return text重要原则:脱敏不是简单地删除,而是保留语义、去掉隐私。比如"张先生在北京协和医院就诊"可以脱敏为"用户在医疗机构就诊"。
第二步:配置隐私保护训练
这是最核心的部分。我们结合LoRA和差分隐私:
python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from opacus import PrivacyEngine
from peft import get_peft_model, LoraConfig
# 1. 加载基础模型(以ChatGLM为例)
model_name = "THUDM/chatglm-6b"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
device_map="auto", # 自动分配GPU/CPU
trust_remote_code=True
)
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
# 2. 配置LoRA(只训练0.1%的参数)
lora_config = LoraConfig(
r=8, # 矩阵秩,控制新增参数量
lora_alpha=16,
target_modules=["query_key_value"], # 只改注意力层
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
model = get_peft_model(model, lora_config)
print(f"可训练参数比例:{model.print_trainable_parameters()}")
# 3. 准备训练数据(简化示例)
def prepare_training_data():
samples = [
"用户问:如何查询账户余额?",
"回答:您可以通过手机银行或前往网点查询。",
"用户问:转账到账时间多久?",
"回答:同行实时到账,跨行通常1-2工作日。"
]
encodings = tokenizer(
samples,
max_length=512,
padding="max_length",
truncation=True,
return_tensors="pt"
)
# 标签就是输入(语言模型任务)
encodings["labels"] = encodings["input_ids"].clone()
return encodings
train_data = prepare_training_data()
# 4. 配置差分隐私引擎
privacy_engine = PrivacyEngine()
# 计算批次大小
batch_size = 2
sample_rate = batch_size / len(train_data["input_ids"])
# 根据隐私预算计算噪声大小
# ε=8, δ=1e-5(常用配置)
noise_multiplier = 1.1 # 噪声乘子,越大隐私越强
model, optimizer, train_loader = privacy_engine.make_private(
module=model,
optimizer=torch.optim.AdamW(model.parameters(), lr=2e-4),
data_loader=torch.utils.data.DataLoader(
list(zip(train_data["input_ids"], train_data["attention_mask"])),
batch_size=batch_size
),
noise_multiplier=noise_multiplier,
max_grad_norm=1.0, # 梯度裁剪阈值
)
# 5. 训练循环(带隐私监控)
model.train()
for epoch in range(3): # 实际需要更多轮次
total_loss = 0
for batch_idx, batch in enumerate(train_loader):
input_ids, attention_mask = batch
# 前向传播
outputs = model(
input_ids=input_ids,
attention_mask=attention_mask,
labels=input_ids # 语言建模任务
)
loss = outputs.loss
total_loss += loss.item()
# 反向传播(差分隐私自动处理)
loss.backward()
optimizer.step()
optimizer.zero_grad()
# 每10步打印隐私消耗
if batch_idx % 10 == 0:
current_epsilon = privacy_engine.get_epsilon(delta=1e-5)
print(f"步骤 {batch_idx} | 损失: {loss.item():.4f} | ε消耗: {current_epsilon:.2f}")
avg_loss = total_loss / len(train_loader)
epsilon_used = privacy_engine.get_epsilon(delta=1e-5)
print(f"轮次 {epoch}完成 | 平均损失: {avg_loss:.4f} | 总隐私成本: ε={epsilon_used:.2f}")
print("✅ 隐私保护微调完成!")第三步:模型安全部署
训练好的模型需要安全地服务业务:
python
class SecureModelServer:
def __init__(self, model, tokenizer, max_epsilon=8.0):
self.model = model
self.tokenizer = tokenizer
self.model.eval() # 切换到推理模式
# 访问控制列表(实际应从数据库读取)
self.acl = {
"user001": {"models": ["finance-assistant"], "rate_limit": 10},
"admin": {"models": ["*"], "rate_limit": 100}
}
# 审计日志
self.audit_log = []
def generate_with_guardrails(self, user_id, prompt, max_length=100):
"""带防护的生成"""
# 1. 权限检查
if user_id not in self.acl:
return {"error": "未授权访问"}
# 2. 输入过滤(防提示词攻击)
prompt = self.filter_prompt(prompt)
# 3. 推理
with torch.no_grad():
inputs = self.tokenizer(prompt, return_tensors="pt").to(self.model.device)
outputs = self.model.generate(
**inputs,
max_length=max_length,
temperature=0.7,
do_sample=True,
top_p=0.9
)
response = self.tokenizer.decode(outputs[0], skip_special_tokens=True)
# 4. 输出过滤(防信息泄露)
response = self.filter_response(response)
# 5. 记录审计日志
self.log_access(user_id, prompt[:50], response[:50])
return {"response": response, "status": "success"}
def filter_prompt(self, text):
"""过滤输入中的敏感信息"""
forbidden_keywords = ["原始数据", "脱敏前", "给我看", "密码", "密钥"]
for word in forbidden_keywords:
if word in text:
text = text.replace(word, "[已过滤]")
return text
def filter_response(self, text):
"""过滤输出中的隐私泄露"""
# 检测并替换可能的隐私泄露
patterns = {
r'\d{4}-\d{2}-\d{2}': '[DATE]', # 日期
r'\d{3}-\d{4}-\d{4}': '[PHONE]', # 电话
}
for pattern, replacement in patterns.items():
text = re.sub(pattern, replacement, text)
return text
def log_access(self, user_id, prompt_preview, response_preview):
"""记录访问日志(用于合规审计)"""
log_entry = {
"timestamp": datetime.now().isoformat(),
"user_id": user_id,
"prompt_preview": prompt_preview,
"response_preview": response_preview,
"model": "privacy-tuned-model"
}
self.audit_log.append(log_entry)
# 实际应写入安全数据库
# 使用示例
server = SecureModelServer(model, tokenizer)
result = server.generate_with_guardrails(
user_id="user001",
prompt="用户问:我的账户情况如何?"
)
print(result["response"])第四步:联邦学习扩展(多分支架构)
如果你的企业有多个独立数据源(如不同子公司),可以考虑联邦学习:
python
import hashlib
import json
from typing import List, Dict
class FederatedAggregator:
"""安全聚合器(协调节点)"""
def __init__(self):
self.client_updates = [] # 存储加密的模型更新
self.weights = [] # 各节点数据量权重
def receive_update(self, encrypted_update: bytes, data_size: int):
"""接收客户端更新"""
# 这里简化处理,实际应用应使用同态加密或安全多方计算
update_id = hashlib.sha256(encrypted_update).hexdigest()[:8]
print(f"收到客户端更新 {update_id},数据量:{data_size}")
# 存储更新和权重
self.client_updates.append({
"id": update_id,
"update": encrypted_update,
"size": data_size
})
self.weights.append(data_size)
def aggregate_updates(self) -> Dict:
"""安全聚合所有更新"""
if not self.client_updates:
return {}
print(f"开始聚合 {len(self.client_updates)} 个客户端更新...")
# 模拟聚合过程(实际需要解密和计算)
aggregated = {
"status": "success",
"num_clients": len(self.client_updates),
"total_data_size": sum(self.weights),
"aggregation_time": "2024-01-15 14:30:00"
}
# 清空缓存(开始下一轮)
self.client_updates = []
self.weights = []
return aggregated
# 客户端节点代码
class FederatedClient:
"""联邦学习客户端"""
def __init__(self, client_id, local_data):
self.client_id = client_id
self.local_data = local_data
self.local_model = None # 从服务器下载的全局模型
def download_global_model(self, model_weights):
"""下载全局模型"""
print(f"客户端 {self.client_id} 下载全局模型")
self.local_model = model_weights
def local_training(self, num_epochs=3):
"""本地训练(数据不出域)"""
if not self.local_model:
return None
print(f"客户端 {self.client_id} 开始本地训练...")
# 模拟训练过程(实际使用真实数据和DP-SGD)
# 这里生成模拟的模型更新
simulated_update = {
"client_id": self.client_id,
"data_size": len(self.local_data),
"training_loss": 0.25, # 模拟损失
"update_hash": f"update_{hashlib.md5(str(time.time()).encode()).hexdigest()[:8]}"
}
# 加密更新(简化版)
encrypted = json.dumps(simulated_update).encode()
return encrypted
def upload_update(self, aggregator: FederatedAggregator):
"""上传加密更新到协调节点"""
encrypted_update = self.local_training()
if encrypted_update:
aggregator.receive_update(encrypted_update, len(self.local_data))
print(f"客户端 {self.client_id} 更新已上传")
# 使用示例
if __name__ == "__main__":
# 创建协调节点
aggregator = FederatedAggregator()
# 创建三个客户端(代表三个分公司)
clients = [
FederatedClient("branch_sh", ["上海客户数据..."] * 1000),
FederatedClient("branch_bj", ["北京客户数据..."] * 800),
FederatedClient("branch_sz", ["深圳客户数据..."] * 1200),
]
# 模拟一轮联邦学习
for client in clients:
client.download_global_model({"version": "v1.0"})
client.upload_update(aggregator)
# 聚合更新
result = aggregator.aggregate_updates()
print("聚合结果:", result)看到这里你可能已经发现,完全从零搭建这套系统需要相当的工程能力。如果你希望快速验证业务效果,或者团队缺乏AI工程经验,可以考虑LLaMA-Factory Online这样的平台服务。它把上面所有复杂步骤封装成了可视化界面,你只需要:
- 上传数据(自动脱敏)
- 选择基础模型(LLaMA、ChatGLM等)
- 设置隐私等级(滑动条选择ε值)
- 点击开始训练
平台会处理所有的技术细节,最终给你一个可下载的、安全加固的模型文件。特别适合产品经理、业务分析师等非技术背景的同学,能够真正把数据"喂"进模型,产出符合业务需求的专属AI。
效果评估:如何验证你的隐私保护真的有效?
训练完模型后,需要从三个维度评估:
1. 性能评估(模型好不好用)
python
def evaluate_model_performance(model, tokenizer, test_samples):
"""评估模型在业务任务上的表现"""
correct = 0
total = 0
for question, expected_answer in test_samples:
# 模型生成
inputs = tokenizer(question, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_length=100)
predicted = tokenizer.decode(outputs[0], skip_special_tokens=True)
# 简单相似度计算(实际应用需更复杂的评估)
if expected_answer in predicted:
correct += 1
total += 1
accuracy = correct / total if total > 0 else 0
return {"accuracy": accuracy, "total_tests": total}
# 测试样例(业务相关)
test_cases = [
("如何开通手机银行?", "您可以通过官网或APP开通"),
("转账限额是多少?", "日累计限额5万元"),
("信用卡年费多少?", "首年免年费,消费满6次免次年"),
]
results = evaluate_model_performance(model, tokenizer, test_cases)
print(f"业务准确率:{results['accuracy']*100:.1f}%")验收标准:
- 高隐私模式(ε=2-4):准确率比基线下降不超过15%
- 平衡模式(ε=6-8):准确率下降不超过5%
- 低隐私模式(ε>10):基本无损失
2. 隐私评估(数据安不安全)
最直接的测试是成员推断攻击:攻击者试图判断某条数据是否在训练集中。
python
def membership_inference_attack(model, tokenizer, known_samples, unknown_samples):
"""模拟成员推断攻击"""
def get_loss(text):
"""计算模型在给定文本上的损失"""
inputs = tokenizer(text, return_tensors="pt").to(model.device)
with torch.no_grad():
outputs = model(**inputs, labels=inputs["input_ids"])
return outputs.loss.item()
# 已知在训练集中的样本(应该被保护)
known_losses = [get_loss(text) for text in known_samples]
# 不在训练集中的样本(对比基准)
unknown_losses = [get_loss(text) for text in unknown_samples]
# 攻击者策略:如果损失低于阈值,就认为是训练成员
threshold = (sum(known_losses) + sum(unknown_losses)) / (len(known_losses) + len(unknown_losses))
# 模拟攻击
tp = sum(1 for loss in known_losses if loss < threshold) # 正确识别成员
fp = sum(1 for loss in unknown_losses if loss < threshold) # 误判非成员
attack_accuracy = tp / len(known_losses) if len(known_losses) > 0 else 0
false_positive_rate = fp / len(unknown_losses) if len(unknown_losses) > 0 else 0
return {
"attack_success_rate": attack_accuracy,
"false_positive_rate": false_positive_rate,
"protection_score": 1 - attack_accuracy # 保护得分越高越好
}
# 测试
known_data = ["这是训练时见过的文本", "模型学过的内容"]
unknown_data = ["这是全新的文本", "模型没见过的内容"]
privacy_score = membership_inference_attack(model, tokenizer, known_data, unknown_data)
print(f"隐私保护得分:{privacy_score['protection_score']:.3f}")安全标准:
- 攻击成功率 < 10%:优秀
- 攻击成功率 10%-25%:良好
- 攻击成功率 > 25%:需要加强保护
3. 合规评估(能不能过审)
制作一个自查清单:
markdown
## 隐私保护微调合规自查表
### 数据层面
- [ ] 所有训练数据已完成脱敏处理
- [ ] 数据使用已获得必要授权
- [ ] 数据最小化原则:仅包含必要字段
- [ ] 数据存储加密(静态/传输中)
### 训练过程
- [ ] 启用差分隐私(ε值已记录)
- [ ] 梯度裁剪已配置(范数≤1.0)
- [ ] 训练日志不包含原始数据
- [ ] 模型参数已添加水印(可追踪)
### 模型部署
- [ ] 访问控制机制已就位
- [ ] 输入输出过滤已启用
- [ ] 审计日志完整记录
- [ ] 模型使用有速率限制
### 组织流程
- [ ] 数据保护官已审阅流程
- [ ] 员工隐私保护培训已完成
- [ ] 应急响应计划已制定
- [ ] 定期隐私影响评估已安排常见问题与避坑指南
Q1:加了差分隐私后模型不收敛怎么办?
原因 :噪声太大或学习率不合适。
解决方案:
- 调大隐私预算ε(比如从2调到4)
- 降低学习率(通常需要为原学习率的50%)
- 增大批次大小(减小噪声影响)
- 使用学习率预热(前10%步数从小学习率开始)
python
# 调整后的优化器配置
optimizer = torch.optim.AdamW(
model.parameters(),
lr=1e-4, # 比标准微调更小的学习率
weight_decay=0.01
)
# 学习率预热调度器
scheduler = torch.optim.lr_scheduler.LinearLR(
optimizer,
start_factor=0.01, # 从1%开始
total_iters=100 # 100步后达到设定学习率
)Q2:显存不够用怎么办?
大模型+隐私保护确实吃显存,试试这些技巧:
python
# 技巧1:使用梯度累积(模拟大批次)
accumulation_steps = 4 # 每4步更新一次
actual_batch_size = 2 # 物理批次大小
# 训练循环中:
for step, batch in enumerate(train_loader):
loss = compute_loss(batch)
loss = loss / accumulation_steps # 梯度累积
loss.backward()
if (step + 1) % accumulation_steps == 0:
optimizer.step()
optimizer.zero_grad()
# 技巧2:混合精度训练
from torch.cuda.amp import autocast, GradScaler
scaler = GradScaler()
with autocast():
outputs = model(**batch)
loss = outputs.loss
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
# 技巧3:LoRA的秩(r值)别设太大
# r=8足够大多数任务,r=16可能更准但显存翻倍Q3:如何选择隐私预算ε?
根据业务场景决定:
| 场景 | 推荐ε值 | 理由 |
|---|---|---|
| 医疗诊断数据 | 1-3 | 受HIPAA严格保护,宁可性能低也要安全 |
| 金融交易数据 | 4-6 | 需平衡风控准确性和隐私保护 |
| 客服对话记录 | 6-10 | 相对不敏感,可偏向性能 |
| 公开数据增强 | 10+ | 几乎无隐私风险,追求最佳性能 |
实用建议:先设置ε=8.0跑一次,如果性能满足要求,再尝试ε=4.0看是否还能接受。
Q4:隐私保护会增加多少训练时间?
在我们的测试中(A100显卡):
- 标准微调:100%基准时间
- +差分隐私:增加30%-50%
- +联邦学习(3节点):增加100%-150%
- +全流程(DP+FL+安全聚合):增加150%-200%
优化建议:
- 使用LoRA减少参数量
- 梯度累积代替大批次
- 联邦学习中节点并行训练
总结与展望
核心要点回顾
- 隐私保护不是可选项,而是必选项------法规要求和商业风险双重驱动
- 三层防护最有效:差分隐私(算法层)+ 联邦学习(架构层)+ LoRA(模型层)
- 平衡的艺术:在ε=6-8的区间,通常能找到性能与隐私的最佳平衡点
- 全链路安全:从数据脱敏、安全训练到模型部署,每个环节都需要防护
行业趋势展望
未来一年,我们预计会看到:
技术发展:
- 自适应隐私保护:模型根据数据敏感度自动调整ε值
- 可验证隐私:提供数学证明的隐私保护证书
- 联合学习标准化:跨机构、跨行业的安全协作框架
产品演进:
- 一站式隐私保护平台(就像今天的LLaMA-Factory Online正在做的)
- 隐私即服务(Privacy-as-a-Service)模式
- 自动化合规检查工具
生态建设:
- 开源隐私保护数据集
- 第三方隐私审计服务
- 跨平台模型安全协议
给不同读者的行动建议
如果你是CTO/技术负责人:
- 立即启动隐私保护能力建设,不要等到合规检查
- 优先在金融、医疗、法律等高敏感场景试点
- 考虑使用成熟的平台服务降低初期成本
如果你是AI工程师:
- 掌握LoRA + 差分隐私 + 联邦学习的基本实现
- 在下一个微调项目中至少加入一项隐私保护技术
- 参与开源隐私保护项目,积累经验
如果你是产品经理/业务方:
- 理解隐私保护的技术原理和成本影响
- 与法务部门共同设计数据使用流程
- 用隐私保护作为产品差异化优势
如果你刚入门:
- 从理解差分隐私的基本概念开始
- 使用LLaMA-Factory Online这类工具亲自尝试
- 在小数据集上体验隐私-性能的权衡
最后的话
大模型时代的企业AI应用,正从"有没有"转向"安不安全"。隐私保护不再是学术论文里的概念,而是每个技术决策者必须面对的现实问题。
好消息是,技术方案已经成熟,工具生态也在完善。无论你是选择自建一套完整系统,还是借助LLaMA-Factory Online这样的平台服务,现在都是开始行动的最佳时机。
毕竟,在数据驱动的未来,最好的AI不是最聪明的那个,而是最值得信任的那个。
互动思考:
- 你的业务中,哪些数据最需要隐私保护?
- 你能接受的性能损失上限是多少?
- 除了技术方案,组织流程上还需要哪些准备?
欢迎在评论区分享你的想法和经验!