目录
[一、 设计目标与核心挑战](#一、 设计目标与核心挑战)
[二、 系统架构总览(分层架构)](#二、 系统架构总览(分层架构))
[1. 客户端层](#1. 客户端层)
[2. 接入层(API Gateway)](#2. 接入层(API Gateway))
[3. 服务层(微服务架构)](#3. 服务层(微服务架构))
[4. 数据层与中间件](#4. 数据层与中间件)
[5. 外部依赖](#5. 外部依赖)
[🔄 数据流方向](#🔄 数据流方向)
[⚡ 性能优化点](#⚡ 性能优化点)
[🔒 一致性保障](#🔒 一致性保障)
[三、 核心模块设计](#三、 核心模块设计)
[1. 积分账户服务](#1. 积分账户服务)
[2. 积分规则引擎服务](#2. 积分规则引擎服务)
[3. 积分中心服务](#3. 积分中心服务)
[4. 任务调度服务](#4. 任务调度服务)
[5. 风控与防刷模块](#5. 风控与防刷模块)
[四、 核心流程与数据一致性方案](#四、 核心流程与数据一致性方案)
[1. 积分赚取流程(最终一致性典范)](#1. 积分赚取流程(最终一致性典范))
[2. 积分消费流程(TCC或预扣方案)](#2. 积分消费流程(TCC或预扣方案))
[五、 数据库与中间件设计](#五、 数据库与中间件设计)
[六、 可扩展性设计](#六、 可扩展性设计)
[七、 监控与运维](#七、 监控与运维)
高可用、可扩展、高并发的积分系统架构设计方案,需要涵盖核心思想、模块分解、技术选型与关键考量。
一、 设计目标与核心挑战
设计目标:
-
高并发与高性能:应对促销、秒杀等场景下的巨额积分操作(如写入、查询)。
-
数据一致性:确保积分变更的准确性,防止超发、少发。
-
高可用性:系统无单点故障,7x24小时稳定运行。
-
可扩展性:支持业务快速迭代,如灵活配置积分规则、扩展积分消耗场景。
-
可追溯性:所有积分变动有明细,支持对账、风控和审计。
核心挑战:
-
热点账户写入:热门用户或活动账户的积分频繁变更。
-
积分过期处理:大量用户积分的批量过期计算。
-
防刷与风控:识别和阻止机器刷分、套现等恶意行为。
-
事务一致性:积分操作常与核心业务(如订单支付、评论)耦合,需保证最终一致性。
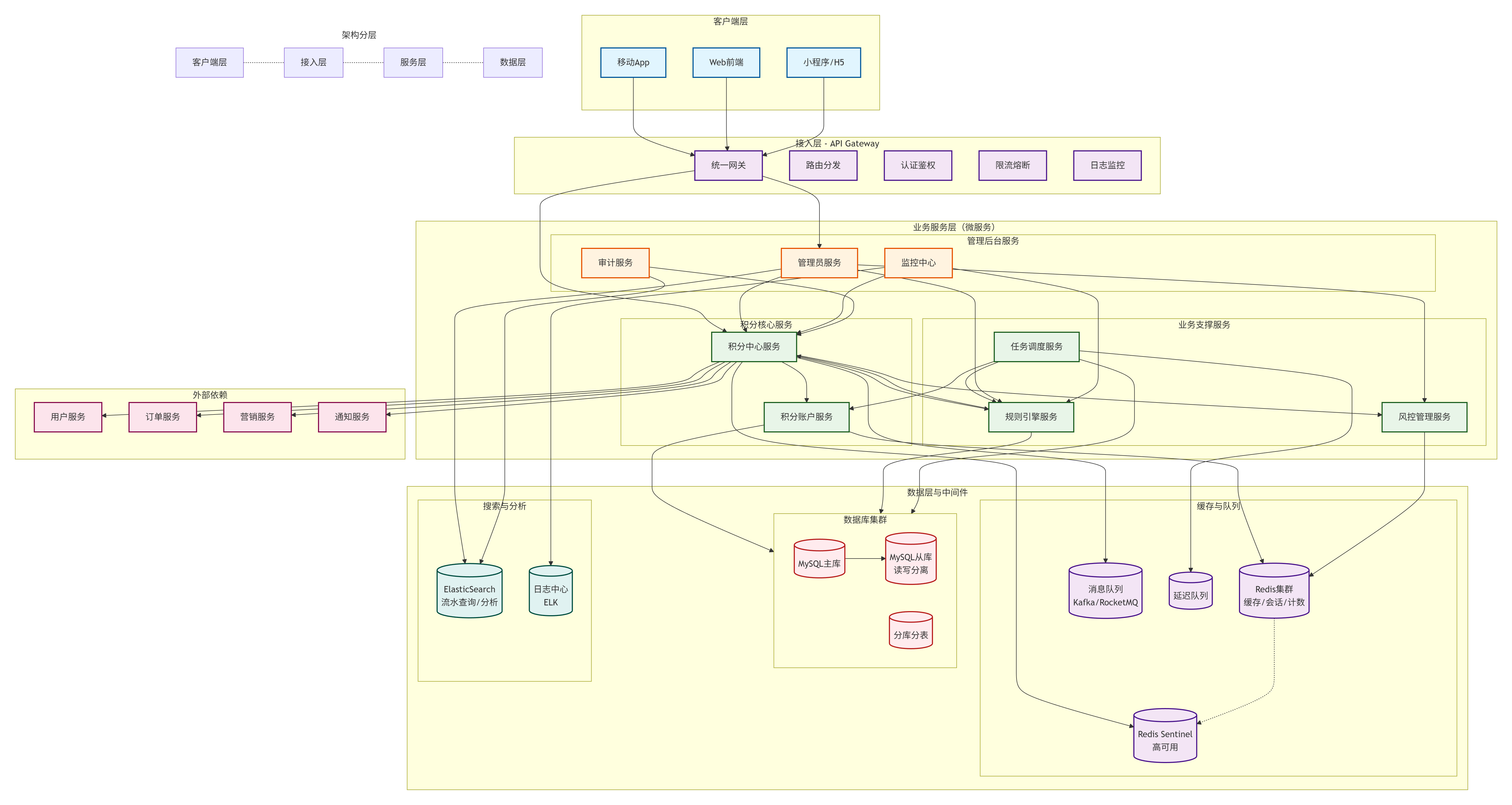
二、 系统架构总览(分层架构)
采用经典的分层微服务架构,解耦核心功能。
┌─────────────────────────────────────────────────────────────┐
│ 客户端 (App/Web) │
└───────────────────────┬─────────────────────────────────────┘
│ HTTPS/API
┌───────────────────────▼─────────────────────────────────────┐
│ 接入层 (API Gateway) │
│ - 路由、鉴权、限流、熔断、日志 │
└───────────────────────┬─────────────────────────────────────┘
│ RPC/Dubbo/gRPC
┌───────────────────────┼─────────────────────────────────────┐
│ │ 业务服务层 (微服务) │ 管理后台服务层 │
│ │ │ │
│ ┌──────▼──────┐ ┌──────────▼──────────┐ │
│ │ 积分中心服务 │ ◄─────────► │ 规则引擎服务 │ │
│ └──────┬──────┘ RPC └──────────┬──────────┘ │
│ │ │ │
│ ┌──────▼──────┐ ┌──────────▼──────────┐ │
│ │ 积分账户服务 │ │ 任务调度服务 │ │
│ └──────┬──────┘ └────────────────────┘ │
└─────────┼───────────────────────────────────────────────────┘
│
┌─────────▼───────────────────────────────────────────────────┐
│ 数据层与中间件 │
│ ┌────────────┐ ┌────────────┐ ┌────────────┐ ┌─────────┐ │
│ │ MySQL │ │ Redis │ │ MQ │ │ Elastic│ │
│ │ (分库分表) │ │(缓存/计数) │ │(解耦/削峰) │ │ Search │ │
│ └────────────┘ └────────────┘ └────────────┘ └─────────┘ │
└─────────────────────────────────────────────────────────────┘
架构分层说明
1. 客户端层
移动App/Web前端:用户直接操作的界面
小程序/H5:轻量级接入方式
第三方接入:合作伙伴系统集成
2. 接入层(API Gateway)
统一入口:所有请求统一接入
安全防护:认证、鉴权、防刷
流量控制:限流、熔断、降级
协议转换:HTTP/REST -> 内部RPC
3. 服务层(微服务架构)
核心服务
积分中心服务:业务聚合、流程编排
积分账户服务:账户管理、余额操作
支撑服务
规则引擎服务:积分规则动态配置
任务调度服务:过期处理、对账任务
风控管理服务:反作弊、安全控制
管理服务
管理员服务:后台管理界面
监控中心:系统监控、告警
审计服务:操作日志、数据追溯
4. 数据层与中间件
存储层
MySQL集群:主从读写分离 + 分库分表
Redis集群:热点数据缓存、分布式锁
ElasticSearch:流水查询、分析统计
中间件
消息队列:业务解耦、异步处理
延迟队列:定时任务、过期处理
配置中心:动态配置管理
5. 外部依赖
用户服务:获取用户信息
订单服务:消费积分来源
营销服务:积分活动联动
通知服务:积分变动通知
关键架构特性
🔄 数据流方向
用户操作流:客户端 → 网关 → 积分中心 → 账户服务 → 数据库
异步处理流:业务事件 → 消息队列 → 消费者 → 积分处理
查询流:客户端 → 缓存 → 数据库(缓存穿透时)
管理流:管理后台 → 各服务 → 数据库/日志
⚡ 性能优化点
热点账户:Redis缓存 + 批量合并写入
查询优化:ES索引 + 缓存多层策略
写入压力:消息队列削峰填谷
🔒 一致性保障
核心交易:数据库事务 + 版本控制
最终一致:本地消息表 + 重试机制
对账补偿:定时核对 + 自动修复
三、 核心模块设计
1. 积分账户服务
-
职责:管理用户积分账户的实体,提供余额的原子性操作。
-
核心表设计:
-
points_account:积分账户表 (user_id, balance, version, status, ...)。user_id分片键。 -
points_detail:积分明细流水表 (id, user_id, order_id, change_type, change_points, balance_after, biz_id, created_at)。流水是系统真理源。
-
-
关键设计:
-
防并发更新 :通过数据库乐观锁 (
version) 或UPDATE ... WHERE条件保证余额更新的原子性。 -
余额缓存 :在Redis中缓存热点用户的余额,采用
INCRBY/DECRBY操作,异步同步回DB。需处理缓存与DB的一致性问题。
-
2. 积分规则引擎服务
-
职责:将业务规则与积分逻辑解耦,实现动态配置。
-
核心表 :
points_rule(rule_id, biz_type, trigger_condition, award_points, limits, status, ...)。 -
关键设计:
-
规则模型:定义规则的触发事件、条件(如订单金额>100)、奖励积分值、频次限制(每日/每单上限)。
-
执行引擎 :接收事件(如
order_paid),查询匹配的规则,计算应得积分,调用积分账户服务发放。
-
3. 积分中心服务
-
职责:对外暴露统一的积分操作API,协调账户服务和规则引擎,处理复杂积分事务。
-
核心接口:
-
earnPoints:赚取积分(支持多种业务来源)。 -
consumePoints:消费积分(用于兑换、抵扣)。 -
queryBalance/queryDetail:查询余额和流水。
-
-
关键设计 :异步化与最终一致性。将积分发放/消费请求发送到消息队列,由消费者异步处理,提高响应速度和解耦。
4. 任务调度服务
-
职责 :处理定时批任务,如积分过期、积分清零、对账报表。
-
关键设计:
-
过期方案:
-
扫表方案:定时扫描即将过期的积分记录。适用于数据量小,对精度要求不极端高的场景。
-
延时队列方案 :在发放积分时,计算过期时间,并发送一个延迟消息。到期后消费者执行过期扣减。推荐此方案,精度高,对DB压力小。
-
-
对账任务:定期运行,核对账户总余额与流水累计值是否一致。
-
5. 风控与防刷模块
-
职责:集成在API网关或积分中心服务中。
-
策略:
-
频率限制:同一用户/IP在单位时间内获取积分次数上限。
-
行为模式分析:检测异常获取模式(如机器脚本)。
-
黑名单:对作弊用户进行降级或拦截。
-
业务规则校验:与订单、评论等业务系统联动,校验行为真实性。
-
四、 核心流程与数据一致性方案
1. 积分赚取流程(最终一致性典范)
用户下单支付成功,订单服务产生事件 `OrderPaidEvent`。
积分中心服务监听该事件,进行基础风控校验。
通过后,生成一条"待处理"的积分流水记录(状态为PROCESSING),并发送一个 `PointsEarnTask` 到消息队列。
立即向用户返回"积分发放中"。
消息消费者接收任务:
a. 查询积分规则,计算应得积分。
b. 调用账户服务,原子性地更新账户余额(+积分),并将流水记录状态更新为SUCCESS。
c. 若失败,记录日志并发出告警,由补偿Job重试或人工处理。
- 可选:发送积分到账通知。
优势:业务主链路(支付)不受积分发放延迟或失败影响,通过消息队列削峰填谷,通过本地事务表和重试保证最终一致性。
2. 积分消费流程(TCC或预扣方案)
对于积分兑换等需要强一致性的场景:
-
TCC模式:
-
Try :冻结用户部分积分(在账户表增加
frozen_balance字段)。 -
Confirm:兑换成功,扣减冻结的积分。
-
Cancel:兑换失败,解冻积分。
-
-
预扣+延时恢复:下单时预扣积分,并设置一个TTL。若订单未在规定时间完成,则恢复积分。
五、 数据库与中间件设计
-
MySQL:
-
分库分表 :以
user_id为分片键,分散热点。points_detail表按user_id+ 时间分片。 -
索引 :
points_detail表建立(user_id, created_at)联合索引,高效查询用户流水。
-
-
Redis:
-
缓存 :
user_points:{user_id}存储余额。采用写穿透+定期刷新策略。 -
计数 :
points_earn_today:{user_id}用于规则频次限制。 -
分布式锁:用于某些需要强互斥的短任务。
-
-
消息队列:
- 削峰异步:使用RocketMQ/Kafka。确保消息不丢(持久化、Confirm机制)、不重复(消费端幂等处理)。
-
Elasticsearch:
- 流水查询:将积分明细同步到ES,支持管理员多维度、复杂的流水查询与审计。
六、 可扩展性设计
-
微服务化:各模块独立部署、扩展。例如,规则引擎和风控模块可以独立伸缩。
-
配置化:积分规则、过期规则、风控规则全部配置化,无需发版即可变更。
-
多积分类型 :账户表可设计为支持不同
point_type(如通用积分、活动积分),满足未来业务需求。
七、 监控与运维
-
核心监控指标:
-
服务:QPS、响应时间、错误率。
-
积分:发放/消费总量、成功率、过期数量。
-
数据库:连接数、慢查询。
-
缓存:命中率、内存使用。
-
消息队列:堆积情况。
-
-
告警:对余额不一致、发放大量失败、MQ严重堆积等情况设置告警。
-
对账平台:每日对账户总余额和流水总额,确保数据100%准确。
总结
一个健壮的积分系统,其核心在于通过异步化、消息队列、规则引擎等技术解耦复杂性,通过分库分表、缓存、柔性事务应对高性能与一致性挑战,并通过完备的监控、风控和对账保障业务的稳定与数据的准确。
本设计为一个相对完整的蓝图,在实际落地时,可根据业务规模(初创期或亿级用户)进行裁剪或增强,例如初期可去掉分库分表和ES,简化架构,快速上线。
积分发放流程优化
您提出了一个很好的问题。原流程确实有优化空间,应该在生成待处理流水记录之前先进行规则判断,这样可以避免创建无效的积分申请记录。以下是优化后的流程设计:
优化后的积分发放流程
核心优化:同步规则校验
在积分发放流程中增加同步规则校验阶段,避免无效记录的生成。
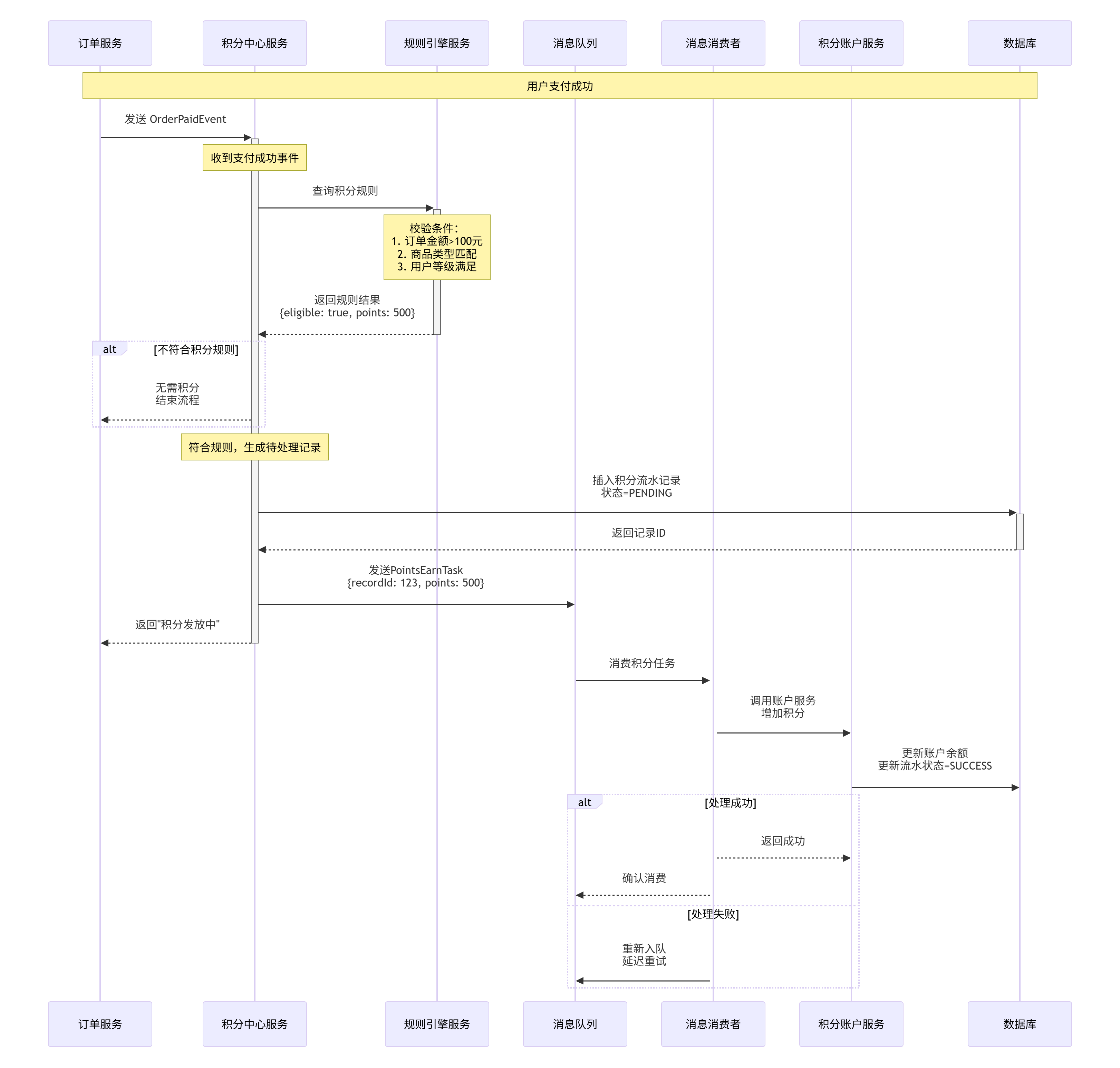
详细步骤说明
阶段一:同步校验(核心优化)
-
事件触发
-
用户下单支付成功,订单服务产生
OrderPaidEvent -
事件包含:
orderId,userId,amount,productType,paymentTime等
-
-
基础风控校验
-
校验用户状态(是否黑名单、是否异常账号)
-
校验订单有效性(是否重复支付、是否取消订单)
-
基础频率限制(同一用户/订单是否重复触发)
-
-
规则引擎校验 ⭐新增关键步骤
java// 伪代码示例 public RuleResult checkPointsRule(OrderPaidEvent event) { // 1. 查询适用的积分规则 List<PointsRule> rules = ruleEngine.getApplicableRules( event.getUserId(), event.getBizType(), event.getAmount() ); // 2. 执行规则匹配 for (PointsRule rule : rules) { if (ruleMatcher.matches(rule, event)) { // 3. 计算应得积分 int points = pointCalculator.calculate(rule, event); if (points > 0) { return RuleResult.success(points, rule.getId()); } } } return RuleResult.failed("No matching rules"); }
-
校验结果处理
-
通过:继续后续流程
-
不通过:立即返回,不创建任何记录
-
异常:记录日志,触发告警,但不阻塞主流程
-
阶段二:预处理(保证最终一致性)
-
创建待处理记录
-
生成唯一的积分流水号
-
记录关键信息:
recordId,userId,orderId,ruleId,expectedPoints,status=PENDING -
记录创建时间和过期时间(用于对账补偿)
-
-
发送异步任务
java
// 消息结构示例
{
"taskId": "TASK_20250130123456",
"recordId": 123456789,
"userId": 10001,
"expectedPoints": 500,
"source": "ORDER_PAID",
"sourceId": "ORDER_20250130001",
"ruleId": "RULE_VIP_ORDER",
"executeTime": "2025-01-30T10:30:00Z"
}-
快速响应
-
立即返回"积分发放处理中"
-
用户可立即看到提示,实际到账稍后完成
-
阶段三:异步处理
-
消息消费
-
消费者从消息队列获取任务
-
验证消息有效性(是否重复、是否过期)
-
-
二次校验(幂等性保证)
java
-- 乐观锁更新,保证幂等
UPDATE points_record
SET status = 'PROCESSING',
version = version + 1,
process_time = NOW()
WHERE id = #{recordId}
AND status = 'PENDING'
AND version = #{version}- 如果记录已被处理,直接返回成功(幂等)
- 10、执行积分发放
- 调用账户服务原子性更新余额
java
// 伪代码:原子性更新
public boolean addPoints(Long userId, Integer points, String bizId) {
// 使用乐观锁或CAS操作
int updated = accountDAO.incrementBalance(
userId,
points,
getCurrentVersion(userId)
);
if (updated > 0) {
// 更新流水状态
recordDAO.updateStatus(recordId, "SUCCESS");
return true;
}
// 处理乐观锁冲突
return handleConflict(userId, points, bizId);
}阶段四:结果处理
-
处理结果
-
成功:更新流水状态为SUCCESS,发送积分到账通知
-
失败:记录失败原因,重试策略
-
网络异常:立即重试(最多3次)
-
余额不足:标记为无效,不重试
-
系统异常:延迟重试,指数退避
-
-
-
补偿机制
-
定时任务扫描PENDING状态的记录
-
超过一定时间(如30分钟)未处理,触发告警
-
人工介入处理异常情况
-
为什么需要同步规则校验?
避免的问题
-
无效记录累积
-
如果不校验就创建记录,大量不符合条件的订单会产生无效流水
-
增加数据库存储压力
-
增加后续处理复杂度
-
-
资源浪费
-
消息队列积压无效任务
-
消费者处理无效消息
-
增加系统负载
-
-
数据一致性
-
避免最终需要清理无效数据
-
保持数据质量
-
性能考虑
-
规则缓存优化
-
将高频规则缓存到Redis
-
规则计算结果可缓存(相同条件订单)
-
热点规则预加载
-
-
异步与同步的平衡
java
// 优化策略
if (isHighPriorityUser(userId)) {
// 高优先级用户同步处理
return processImmediately(event);
} else {
// 普通用户异步处理
return processAsync(event);
}3、超时控制
java
// 设置同步校验超时
@Timeout(value = 500, unit = TimeUnit.MILLISECONDS)
public RuleResult checkRulesWithTimeout(OrderPaidEvent event) {
return ruleEngine.check(event);
}规则引擎设计要点
规则匹配策略
java
public class RuleEngineService {
// 规则缓存
private Cache<String, List<Rule>> ruleCache;
public RuleResult check(OrderPaidEvent event) {
// 1. 获取规则(缓存优先)
List<Rule> rules = getCachedRules(event.getBizType());
// 2. 并行执行规则匹配
List<CompletableFuture<RuleMatchResult>> futures = rules.stream()
.map(rule -> matchRuleAsync(rule, event))
.collect(Collectors.toList());
// 3. 合并结果
return combineResults(futures);
}
// 异步规则匹配
private CompletableFuture<RuleMatchResult> matchRuleAsync(Rule rule, OrderPaidEvent event) {
return CompletableFuture.supplyAsync(() -> {
// 条件判断
if (!matchConditions(rule, event)) {
return RuleMatchResult.unmatched();
}
// 计算积分
int points = calculatePoints(rule, event);
return RuleMatchResult.matched(points, rule.getId());
}, ruleExecutor);
}
}规则定义示例
java
{
"ruleId": "RULE_VIP_ORDER",
"name": "VIP用户订单积分",
"conditions": [
{
"field": "userLevel",
"operator": "IN",
"values": ["VIP1", "VIP2", "VIP3"]
},
{
"field": "orderAmount",
"operator": "GTE",
"value": 100
},
{
"field": "productType",
"operator": "NOT_IN",
"values": ["VIRTUAL", "SERVICE"]
}
],
"action": {
"type": "ADD_POINTS",
"calculateType": "PERCENTAGE",
"value": 5,
"maxPoints": 1000
},
"limits": {
"perUserDaily": 3,
"perUserMonthly": 20
},
"enabled": true,
"priority": 10
}总结
优化后的流程具有以下优势:
| 方面 | 改进前 | 改进后 |
|---|---|---|
| 无效记录 | 可能产生大量无效记录 | 只创建有效记录 |
| 处理效率 | 所有订单都进队列 | 只有符合规则进队列 |
| 系统负载 | 较高 | 显著降低 |
| 数据质量 | 需要定期清理 | 质量高 |
| 响应时间 | 相同 | 略有增加但可控 |
关键设计原则:
-
尽早过滤:在流程早期排除无效请求
-
同步异步结合:轻量级操作同步,重量级操作异步
-
幂等处理:保证消息重复消费不影响结果
-
优雅降级:规则引擎故障时有限度放行
-
监控完善:全流程可观测
这种设计既保证了系统的性能,又确保了数据的准确性,是生产环境中推荐的做法。