INTRODUCTION
我们引入了令牌合并(Token Merging,简称 ToMe),这是一种无需训练即可提高现有 ViT(Vision Transformer,视觉变换器)模型吞吐量的简便方法 。ToMe 使用一种通用的轻量化匹配算法,在变换器中逐渐结合相似的令牌 ;该算法与剪枝(pruning)速度相当,但准确率更高 。在开箱即用(Off-the-shelf)的情况下,ToMe 能够使最先进的 ViT-L @ 512 和 ViT-H @ 518 模型在图像上的吞吐量翻倍 ,并使 ViT-L 在视频上的吞吐量达到 2.2 倍,而每种情况下的准确率下降仅为 0.2-0.3% 。ToMe 也可以轻松应用于训练过程中 ,在实践中可将视频上的 MAE(Masked Autoencoders,掩码自编码器)微调训练速度提高至 2 倍 。通过 ToMe 进行训练可以进一步减少准确率损失 ,在音频 ViT-B 上实现 2 倍吞吐量的同时,mAP(mean Average Precision,平均精度均值)仅下降 0.4% 。在定性分析方面,我们发现 ToMe 能将物体部件合并为一个令牌,甚至可以跨越视频的多帧 。总体而言,ToMe 的准确率和速度在图像、视频和音频领域均具有与最先进技术(state-of-the-art)竞争的实力 。
INTRODUCTION
由 Dosovitskiy 等人(2020年)将变换器(transformers)(Vaswani 等人,2017年)从 NLP(自然语言处理)引入视觉领域而产生的视觉变换器(Vision Transformers,简称 ViTs),迅速推进了计算机视觉领域的发展 。然而,与 NLP 不同,视觉领域此后一直被领域特定的变换器混合体所主导,例如使用视觉特定注意力的 Swin(Liu 等人,2021年;Dong 等人,2022年),使用视觉特定池化的 MViT(Fan 等人,2021年;Li 等人,2022年),或者使用视觉特定卷积模块的 LeViT(Graham 等人,2021年) 。这种趋势的原因很简单:效率 。加入视觉特定的归纳偏置(inductive biases)使变换器混合体能够以更少的计算量表现得更好 。
然而,原生 ViTs 仍然具有许多吸引人的特质:它们由简单的矩阵乘法组成,这使得它们比其原始浮点运算(flop)计数所显示的更快 ;它们支持强大的自监督预训练技术,如 MAE(He 等人,2022年),这类技术在保持训练速度的同时可以达到最先进的结果 ;鉴于它们对数据缺乏假设,它们可以几乎不加修改地应用于许多模态(Feichtenhofer 等人,2022年;Huang 等人,2022年) ;并且它们在海量数据下具有良好的扩展性(Zhai 等人,2021年;Singh 等人,2022年),最近在 ImageNet 上获得了高达 90.94% 的 top-1 准确率(Wortsman 等人,2022年) 。
然而,运行这些庞大的模型可能会很麻烦,而用更快的架构重现这些结果将会很困难 。最近出现了一个极具前景的 ViTs 子领域,由于变换器具有输入无关(input-agnostic)的特性,令牌(tokens)可以在运行时被剪枝以实现更快的模型(Rao 等人,2021年;Yin 等人,2022年;Meng 等人,2022年;Liang 等人,2022年;Kong 等人,2022年) 。然而,令牌剪枝(token pruning)有几个缺点:剪枝带来的信息损失限制了你可以合理减少的令牌数量 ;当前的方法需要重新训练模型才能奏效(有些还需要额外的参数) ;大多数方法不能用于加速训练;并且有几种方法根据输入内容剪枝不同数量的令牌,使得批量推理(batched inference)变得不可行 。
在这项工作中,我们提出了令牌合并(Token Merging,简称 ToMe)来组合令牌,而不是剪枝它们 。由于我们的自定义匹配算法,我们的方法在与剪枝一样快的同时更加准确 。此外,我们的方法在有或没有训练的情况下都能工作,这解锁了它在准确率下降极小的巨大模型上的应用 。在训练期间使用 ToMe,我们观察到训练速度的实际提升,在某些情况下将总训练时间减少了一半 。并且我们在不对图像、视频和音频进行任何修改的情况下应用 ToMe,并发现它在所有情况下都具有与最先进技术(SotA)竞争的实力 。
我们的贡献如下:我们引入了一种技术,在有训练和无训练的情况下都能提高 ViT 模型的吞吐量和实际训练速度(第 3 节),并深入消融(ablate)了我们的设计选择(第 4.1 节) ;我们对几种 ViT 模型进行了广泛的图像实验(第 4.2 节),并与架构设计和令牌剪枝方法中的最先进技术进行了比较(第 4.3 节) ;随后我们针对视频(第 5 节)和音频(第 6 节)重复了这些实验,发现 ToMe 在各模态间均表现良好 ;我们还对结果进行了可视化,发现 ToMe 合并了图像中的物体部件(图 4)以及视频中物体整个运动范围内的部分(图 6) 。我们希望 ToMe 能够助力创建更强大、更快速的 ViT 模型 。
RELATED WORK
高效变换器。 为了提高变换器(transformers)的效率,人们已经做出了许多努力(Tay 等人,2020a)。一种流行的方法是改变注意力机制的复杂度,例如使用稀疏注意力(Child 等人,2019年;Li 等人,2019年;Beltagy 等人,2020年)、低秩近似(Wang 等人,2020年)、内核化(Choromanski 等人,2020年;Katharopoulos 等人,2020年)或基于哈希的方法(Kitaev 等人,2020年;Tay 等人,2020b)。虽然这些方法在具有极长序列长度(例如 L \> 2048)的 NLP 任务中表现出色,但由于计算开销(overhead),它们在具有中等序列长度(如视觉任务)的情况下往往无法提供实际的加速。相比之下,ToMe 通过减少令牌(tokens)数量来加速模型,这使得即使是标准注意力也能运行得更快。
视觉变换器变体。 自 ViT(Dosovitskiy 等人,2020年)问世以来,已经提出了许多变体来提高视觉任务的效率。一些方法在架构中引入了卷积(Graham 等人,2021年;Wu 等人,2021年;Yuan 等人,2021年),而另一些方法则在注意力机制中引入了层次结构(Liu 等人,2021年;Wang 等人,2021年;Fan 等人,2021年)。这些方法虽然有效,但通常需要从头开始训练,并且无法直接应用于现有的预训练 ViT 模型。与之不同,ToMe 旨在加速现有的、现成的(off-the-shelf)ViT 模型,且只需极少的额外微调或无需微调。
令牌剪枝与池化。 减少变换器中令牌的数量是另一种常见的加速策略。令牌剪枝(Token pruning)方法(Rao 等人,2021年;Tang 等人,2022年;Liang 等人,2022年)根据重要性分数丢弃不重要的令牌。令牌池化(Token pooling)方法(Marinescu 等人,2021年;Heo 等人,2021年)则通过局部操作(如池化或卷积)来减少令牌数量。然而,剪枝会造成不可逆的信息丢失,而池化通常局限于固定的局部窗口。ToMe 结合了这两者的优点:它像池化一样保留信息,又像剪枝一样具有全局的灵活性,且不需要通过额外的辅助网络进行重要性预测。
TOKEN MERGING
我们的目标是在现有的 ViT(Dosovitskiy et al., 2020)中插入一个令牌合并模块 。通过合并冗余令牌,我们希望在不一定需要训练的情况下提高吞吐量
策略。 在变换器的每个块中,我们每层合并令牌以减少 r个 。注意,r 是令牌的数量,而不是比例 。在网络中的 L个块上,我们逐渐合并 r*L 个令牌 。改变 r 会产生速度与准确率的权衡,因为令牌越少意味着准确率越低,但吞吐量越高 。重要的是,无论图像内容如何,我们都减少 r*L 个令牌 。一些剪枝方法会动态地改变令牌数量(例如 Kong et al. (2022))。这虽然提高了准确率,但通常是不切实际的,因为它无法进行批量推理(batched inference)或在没有填充令牌(padding tokens)的情况下进行训练 。
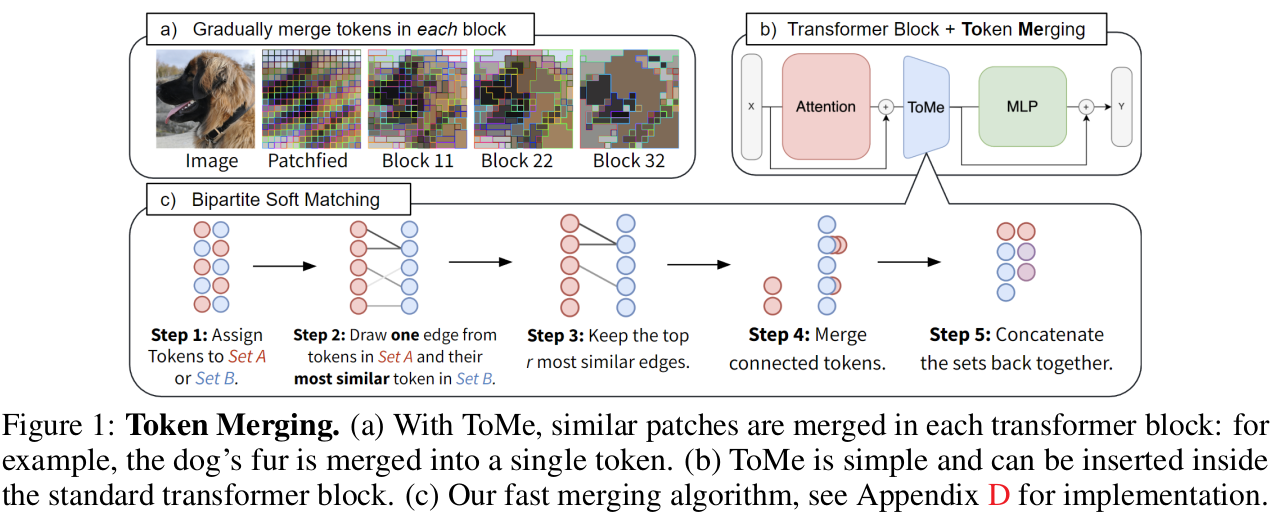
如图 1 所示,我们将令牌合并步骤应用于每个变换器块的注意力(attention)分支和 MLP 分支之间 。这也与之前的工作形成对比,之前的工作往往倾向于将减少方法放在块的开头 。我们的放置方式允许来自将被合并令牌的信息进行传播,并使我们能够使用注意力内部的特征来决定合并对象,这两者都能提高准确率(见表 1a)。
令牌相似性。 在合并相似令牌之前,我们必须首先定义什么是"相似" 。虽然像 Marin et al. (2021) 中那样,如果两个令牌的特征距离较小就称其相似可能很有诱惑力,但这并不一定是最佳的 。现代变换器中的中间特征空间是过度参数化的 。例如,ViT-B/16 具有足够的特征来完全编码每个令牌的 RGB 像素值(16 \* 16 \* 3 = 768)。这意味着中间特征有可能包含会干扰我们相似性计算的无关噪声 。
幸运的是,变换器通过 QKV 自注意力(Vaswani et al., 2017)原生解决了这个问题 。具体而言,键(K)已经总结了每个令牌中包含的信息,用于点积相似性计算 。因此,我们使用每个令牌键之间的点积相似性度量(例如余弦相似度)来确定哪些令牌包含相似信息(见表 1a, 1b)。
二分软匹配。 在定义了令牌相似性之后,我们需要一种快速的方法来确定匹配哪些令牌,以便将总数减少 r 。这个问题有几种潜在的解决方案,例如 K-means 聚类(Lloyd, 1982)或图割(graph cuts)(Boykov et al., 2001) 。但我们在网络中对可能成千上万个令牌执行 L 次这种匹配,因此其运行时间必须完全可以忽略不计 。对于大多数迭代聚类算法来说,情况并非如此 。
因此,我们提出了一种更高效的解决方案 。我们的设计目标如下:1.) 我们希望避免任何无法并行的迭代过程;2.) 我们希望合并带来的变化是渐进的 。后者是我们关注匹配(matching)而非聚类(clustering)的原因,因为聚类对一个组中可以合并多少令牌没有限制(这可能会对网络产生不利影响),而匹配则让大多数令牌保持不合并状态 。我们的算法如下(在图 1 中可视化):
-
将令牌划分为两个大小大致相等的集合 A 和 B 。
-
从 A 中的每个令牌向其在 B 中最相似的令牌连一条边 。
-
保留 r 条最相似的边 。
-
合并仍处于连接状态的令牌(例如,通过平均它们的特征)。
-
将两个集合重新拼接在一起 。
因为这创建了一个二分图,且 A 中的每个令牌只有一条边,所以在步骤 4 中寻找连通分量是平凡(trivial)的 。此外,我们不需要计算每对令牌之间的相似性,如果我们仔细选择 A 和 B,这对于准确率来说不是问题(见表 1e)。事实上,这种"二分软匹配"几乎与随机丢弃令牌一样快(见表 2),并且只需要几行代码即可实现(见附录 D)。
追踪令牌大小。 一旦令牌被合并,它们就不再代表一个输入补丁(input patch) 。这会改变 Softmax 注意力的结果:如果我们合并两个具有相同键的令牌,该键在 Softmax 项中的作用就会减小 。我们可以通过一个简单的改变来修正这一点,称之为比例注意力(proportional attention):
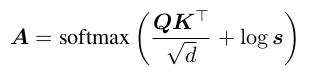
其中 s 是包含每个令牌大小(该令牌代表的补丁数量)的行向量 。这执行的操作与你拥有 s 个键的副本时相同 。每当令牌被聚合时(例如合并令牌时),我们也需要按 s 对令牌进行加权(见表 1d) 。
带合并的训练。 到目前为止,每个组件的设计初衷都是为了能够将令牌合并添加到已经训练好的 ViT 模型中 。使用 ToMe 进行训练并不是必需的,但它可能有助于减少准确率下降或提高训练速度 。为了训练,我们只需将令牌合并视为一种池化操作,并像使用平均池化一样通过合并后的令牌进行反向传播 。我们发现不需要使用任何梯度技巧,例如令牌剪枝中使用的 Gumbel Softmax (Jang et al., 2017)(例如 Kong et al. (2022)) 。事实上,我们发现用于训练原生 ViT 的相同设置在这里也是最佳的(见附录 B) 。因此,ToMe 是一个提高训练速度的掉入式(drop-in)替代方案 。
IMAGE EXPERIMENTS
我们使用四种不同方式训练的 ViT 模型在 ImageNet-1k(Deng 等人,2009年)上进行了多项实验 :AugReg(Steiner 等人,2022年)、MAE(He 等人,2022年)、SWAG(Singh 等人,2022年)以及 DeiT(Touvron 等人,2021年) 。对于所有实验,我们或是将该方法直接应用于现成的(off-the-shelf)模型,或是针对 MAE 和 DeiT,在应用该方法的情况下进行训练 。除非另有说明,所有吞吐量均是在 V100 GPU 上使用最佳批次大小(batch size)和 fp32 精度在推理期间测得的 。
4.1DESIGN CHOICES
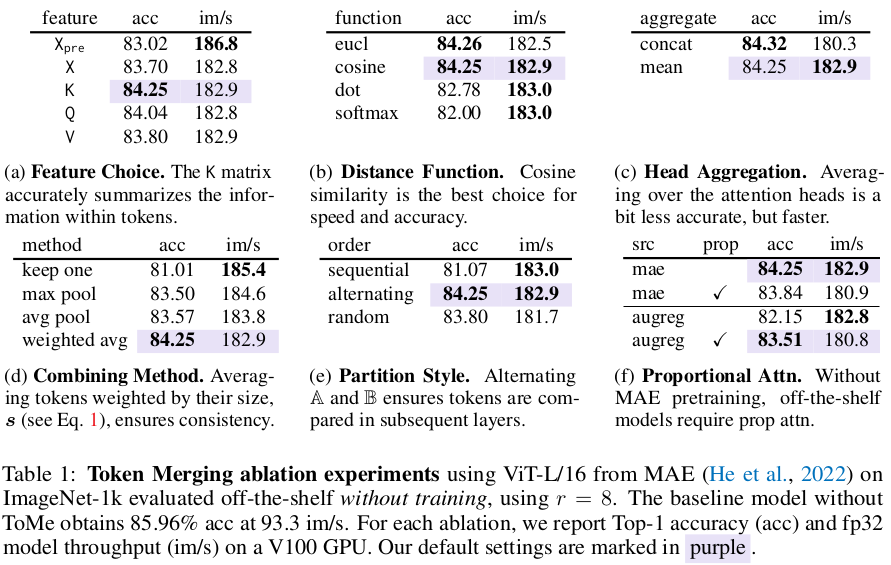
在表 1 中,我们对本方法中所做的设计选择进行了消融研究(ablate) 。对于每项消融实验,我们都从以紫色标记的默认参数开始 。除非另有说明,我们在未经训练的现成 ViT-L/16 MAE 模型(准确率:85.96%,吞吐量:93.3 im/s)上进行测试 ,并以 r = 8 进行合并,这会在网络的 24 层中逐渐移除 98% 的令牌 。
令牌相似性。 令牌的特征(X)在性能方面并非最佳(表 1a) 。将合并操作移至注意力机制之后(X 与 X_{pre} 相比)并使用注意力键(K)会显著提高准确率 。随后,如表 1b 所示,余弦相似度是衡量令牌距离的最佳选择 。最后,为了提高效率,我们将 K 在各个注意力头(attention heads)上取平均值,而不是将它们拼接(表 1c) 。
算法选择。 在决定合并哪些令牌后,我们通过按令牌大小 s 加权的平均值(见公式 1)来组合它们 。在表 1d 中,这种做法优于仅保留集合 B 中的令牌、最大池化或不加权平均池化 。随后,我们的二分匹配算法需要将输入划分为两个不相交的集合 。由于我们随后会拼接这些集合,我们发现采用交替分配(alternating)令牌的方式效果最好(表 1e) 。先填充 A 再填充 B(顺序分配,sequentially)的效果最差 。
比例注意力。 一旦合并,令牌可以代表多个输入补丁 。我们通过比例注意力(公式 1)来解决这一问题,并在表 1f 中对其进行了消融研究 。令人惊讶的是,比例注意力对于有监督模型(如 AugReg、SWAG、DeiT)是必要的,但对于 MAE 模型则不然 。由于这种差异在训练后消失,这可能是因为 MAE 在预训练期间已经移除了令牌 。尽管如此,除了现成的 MAE 模型外,我们对所有模型都使用比例注意力 。
匹配算法比较。 在表 2 中,我们将我们的二分匹配与其他令牌减少算法(包括剪枝和合并)进行了比较 。剪枝速度很快,但由于总体移除了 98% 的令牌,重要的信息会丢失 。无论是随机剪枝还是基于未被关注程度的剪枝(Kim 等人,2021年)都是如此 。相比之下,合并令牌仅在合并了不相似令牌时才会丢失信息 。因此,正确选择相似的令牌进行合并非常重要 。
起初,K-means(Lloyd,1982年)似乎是显而易见的选择,但它除了速度慢之外,效果仅略好于剪枝 。虽然它能最小化重构误差,但 K-means 允许大量令牌匹配到同一个簇(cluster),这增加了不相似令牌被合并的概率 。Marin 等人(2021年)研究了几种基于 K-means 的快速聚类算法,但在不训练的情况下,这些算法在其实验设置中无法获得优于 10% 的准确率降幅 。
相反,我们想要一种只合并最相似令牌的匹配算法 。我们可以通过贪婪地(greedily)合并最相似的一对令牌,然后在不放回的情况下重复 r 次来实现这一点 。这种方法很准确,但由于是顺序执行的,因此在 r 较大时可能会变慢 。我们的二分匹配具有这种贪婪方法的准确率和剪枝的速度,同时在运行时间上相对于 r 是常数级的 。
选择合并调度方案(Merging Schedule)。 默认情况下,我们使用恒定调度方案(constant schedule)合并令牌,即每层合并 r 个 。为了评估这一设计的优越性,我们随机采样了总计 15,000 个合并调度方案 。对于每个调度方案,我们使用现成的 AugReg ViT-B/16 模型在 ImageNet-1k 验证集上测试其准确率和 fp16 吞吐量 。在图 2 中,我们绘制了该实验的结果,发现恒定调度方案接近最优,尤其是当合并令牌的总数增加时 。我们进一步分析了最佳的随机样本(见附录 C),发现线性递减调度方案(linearly decreasing schedule)在高达 ~3 倍吞吐量的情况下表现良好 。因此,我们也定义了一个"递减"调度方案,在第一层移除 2r 个令牌,在最后一层移除 0 个令牌,其余层线性插值 。这同样移除了 rL 个令牌,但速度更快,因为更多令牌被提早移除 。